
基于R语言的关联规则应用实例
2018-04-09 01:13
福建质量管理 2018年6期
(四川大学 四川 成都 610000)
一、关联规则
关联规则是美国IBM Almaden Research Center Rakeesh Agrawal等人于1993年首先提出来的KDD研究的一个重要课题。关联规则挖掘本质是从大量的数据中或对象间抽取关联性,它可以揭示数据间的依赖关系,根据这种关联性就可以从某一数据对象的信息来推断另一个的信息。
二、关联规则在股票市场中的应用
在证券交易市场中,每天都有以交易行情为主的大量数据汇入数据库。如果把同一天股票的上升(或下降)事件看成是被放入同一个货篮的货物,那么一个时期的股票交易数据就会形成多个货篮数据。既然可以挖掘出规则:“如果一个货篮中有婴儿纸尿布,那么该货篮中有啤酒的概率是80%”,也可以挖掘出同一时期内股票上升(或下跌)的联动规则。Apriori 算法恰好是解决这类问题的有效方法,但是,由于股票行情数据是以时间序列方式存储在数据库中,无法直接用Apriori 算法进行数据挖掘;要在股票行情数据库中挖掘出根据时间而前后联动的关联规则,需要在货篮数据中多引入一个参数:时间间隔。
另外,为了提高挖掘过程的有效性,还应确定目标关联规则(即元规则)的形式。根据上面给出的用户感兴趣的规则形式:“T时间内,当A股票价格上涨时,B股票价格也会随之上涨”。所以我们主要关心的是股票交易的时间和涨跌幅,其他如开盘价、成交量等可以认为是一些无关信息。
(一)数据来源
本文从国泰君安数据库中选取从2016年8月至2017年8月所有交易日下编号靠前的部分股票作为测试样本,以探求关联规则在股票市场中的应用,剔除停盘日后初始下载样本数为52109条。
(二)数据预处理
1.导入数据
首先,我们将包含编号(gtacode)、股票名称(Title)、交易日期(accpertime)、开盘价(Opnprc_JY)、收盘价(Clsprc_JY)和涨跌幅在内的原始数据通过txt的形式导入到R语言中。
>setwd(“/Users/zhongzhong/Documents”)
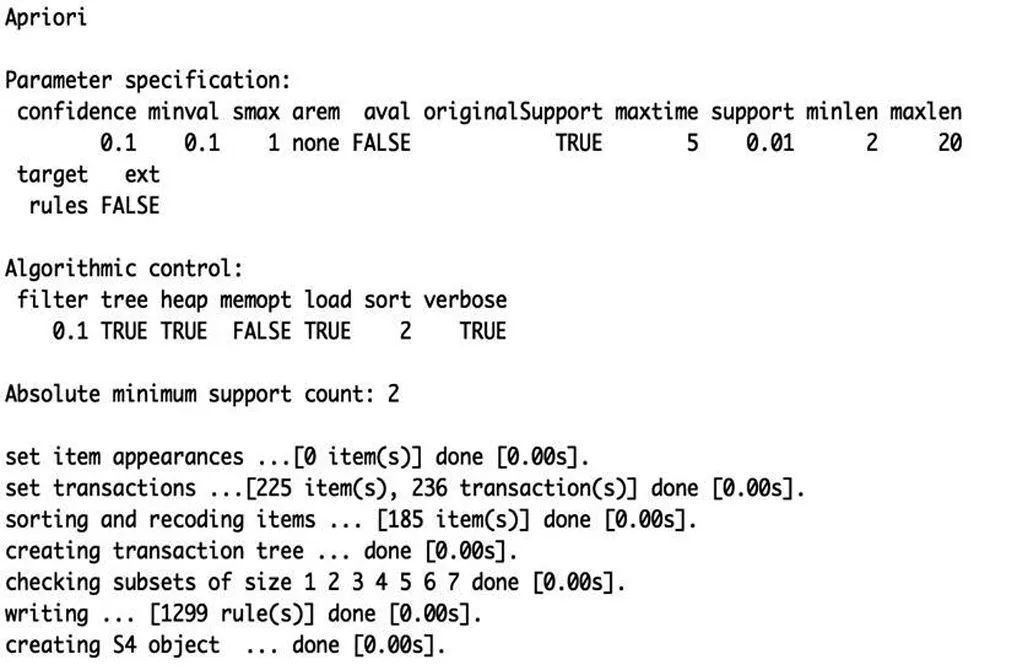
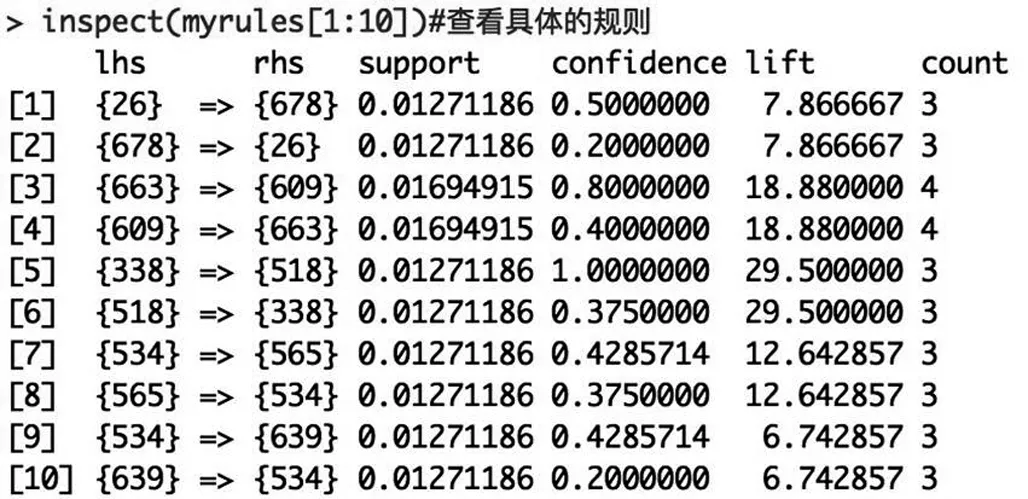
>mydata 导入数据后,使用View(mydata)将会在软件中显示出所导入的数据。 2.数据的检验 (1)缺失值 ①识别缺失值 我们首先用is.na()函数识别数据中的缺失值。 ②探究缺失值 然后我们用sum(is.na())函数计算上海这个数据框中缺失值的数目,得到为1。 (2)错误值 除了缺失值以外,我们还需要检验数据中有没有不符合实际的情况,比如涨跌幅中不可能有超过+10%和-10%的股票。经检验,没有出现这种情况。 (3)变量类型 在数据录入过程中,我们通过str()函数发现gtacode为数值型(int),Title和时间为(Factor),其余都为类别型(chr),所有在后面的数据清理当中需要进行类型的转换。 3.数据的清理 (1)缺失值的处理 通过na.omit()移除所有含有缺失值的观测,使得数据中不再含有缺失值。 (2)类型的转换 通过as.character()对Title进行转换为字符型,然后通过as.Data()对时间进行转换。 4.数据的规整 考虑到主要关键信息是股票交易的时间和涨跌幅,所以只筛选出编号、时间和涨幅三列有效数据: >mydata<-mydata[,c(1,3,6)] 为了清晰明了的挖掘出用户感兴趣的规则形式:“T时间内,当A股票价格上涨时,B股票价格也会随之上涨”,我们首先设定出一个时间间隔,同时限定最小涨幅来减少工作量。 定义1 设最小涨幅Zmin,|Zmin|<10% 定义2 设过票交易集T={T1,T2,…,Ts},其中T1=2016-08-02,Ts=2017-08-02 按最小涨幅筛选之后,可以由下图看到,之前5万多条数据骤减到了1345条,故时间段上我们将不做筛选调整,保留一年交易日的数据: >mydata1<-subset(mydata,涨跌幅>=0.05) >view(mydata1) 5.apriori算法运用 这样之后,我们将mydata1读出为txt格式,为后面读入成transactions数据格式做准备。然后使用read.transactions函数转换成事务型数据,可以利用dim(trans)和summary(trans)来查看数据集的基本情况。 图1 apriori算法代码展示 上图得到前五个item的支持度分别为0.10169492、0.10169492、0.09322034、0.08898305、0.08898305。 这里我们所做的是在生成规则:知道了频繁项集,过滤掉非频繁项集,并找出第一步的频繁项集中的规则: >sum(itemFreq) >trans[size(trans)>1] >myrules=apriori(trans,parameter=list(support=0.01,confidence=0.1,minlen=2,maxlen=20,target=“rules”)) 接下来我开始使用apriori算法生成一条关联规则myrules如上图:支持度为0.01,置信度为0.1,这里的minlen和maxlen是指规则的LHS+RHS的并集的元素个数,具体的规则显示在下图中。 图2 apriori算法显示 从返回结果中看,可以看到总共有1299条规则生成。同时,有236条交易记录的transaction,225个商品item等信息。然后使用summary(myrules)可以查看规则汇总信息如下,包括每个篮子(交易)中含有的股票数目以及支持度、置信度的最小值、最大值和中位数等信息。 图3 规则汇总信息 第一部分:规则的长度分布:就是minlen到maxlen之间的分布。如上例,len=2有492条规则,len=3有372条规则… 第二部分:quality measure的统计信息 第三部分:挖掘的相关信息。 了解了这些信息以后,我们所最关心的就是具体规则了,使用inspect()函数进行查看具体的规则,下面我们先展现前十条规则: 图4规则的具体展示 本文选择了国泰安数据库中的部分股票进行关联规则的应用实验分析,得到了许多有意义的规则。如上图,在支持度为1%,置信度为10%的条件下,代码为000026和000678的两只股票有同时上涨的趋势,在上述挖掘结果的基础上,我们可以进行二次挖掘,进一步分析各支股票之间趋势变化的周期性和多维相似性等,得到更多有用的结果。 【参考文献】 [1]Usama Fayyad,Gregpru Oatesdu-Shapiro,Padhraic Smyth,RAMASACY UTHURU SAMYMY,ETAL.Advances in Knowledge Discovery and Data Mining[M].AAAI Press/The MIT Press,1996. [2]Gregory Piatesdy-Shapiro,Willam J Frawley,Editors.Knowledge Discovery in Databases[M].AAAI Press,1991. [3]陆丽娜,陈亚萍,扬麦顺,等.挖掘关联规则算法的优化处理[J].计算机工程与应用,2000,(8):99~102. [4]郑朝霞,刘延建.关联规则在股票分析中的应用[J].成都大学学报,2002,(12),46-49.

三、相关结果
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
当代陕西(2019年15期)2019-09-02
家庭影院技术(2019年8期)2019-08-27
传媒评论(2018年5期)2018-07-09
学苑创造·A版(2018年11期)2018-02-01
成长·读写月刊(2017年4期)2017-05-16
读者(2017年5期)2017-02-15
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年22期)2016-12-27
股市动态分析(2016年7期)2016-09-29
