
海量数据分类中的模糊区域判定算法研究
2018-04-11 08:33欧立奇李云飞赵郁园
山东农业大学学报(自然科学版) 2018年2期
欧立奇,何 媛,李云飞,赵郁园,刘 瀚
西京学院商贸技术系,陕西 西安 710123
高精度海量数据分类是大数据信息处理的重要步骤,根据参考大数据里包含相同类别的数据特征进行聚类,以数据聚类为基准,对后期的专家系统以及大数据库存储,有着十分重要的意义。当前主要利用关联方式进行数据区域划分[1]。随着当前数据量的不断增长,在大数据环境下,初始聚类中点的选取对数据分类效率具有一定的影响。当前以关联规则为基础的聚类算法忽略了数据密度相似性以及分类远近对聚类中点检测所形成的干扰,从而使大数据模糊区域在判定的过程中精确度受到影响[2]。本文针对聚类中大数据带来的模糊区域判定困难的问题进行研究,提出一种新的方法。
1 模糊区域判定算法
1.1 大数据模糊区域状态参量的计算
大数据信息流在数据分类中,对模糊区域差异性特点的掌握,是后期聚类的基础。将掌握的相似性特征值设置成基础创建聚类检索目标函数,看进一步精确聚类过程。
大数据模糊区域特征属性集的自相关量由Ru,v代表,是数据特点向量中的互相关函数,大数据模糊区域属性集交叉分布特征值为:
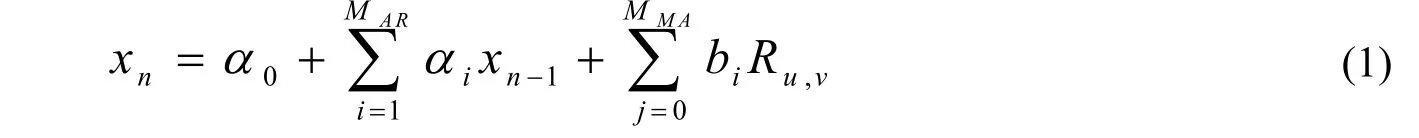
其间,初始大数据时间序列的标本幅值是α0;包含一样值和方差的大数据标量时间序列是xn-1;大数据的最有分裂属性是bj;针对大数据标量特征序列是x(t),t=0,1,…,n-1,选取动态自回归滑动时间窗口建筑多层空间模糊聚类中点,使用模糊C平均值聚类算法实施初始聚类中点检索[3],设有限特征数据集向量。
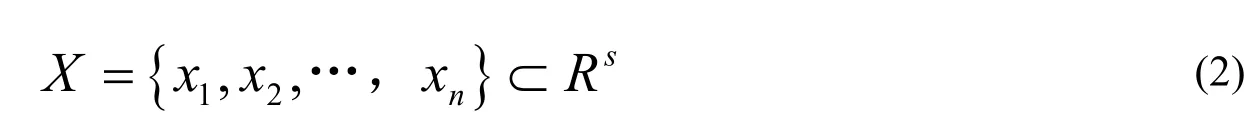
根据属性集划分[4,5],获得数据集中包括n个标本,此间,标本xi(i=1,2,…,n)的差异化特征参量为:

在以创建大数据聚类特征值的基准上,根据大数据最优聚类中点的检索,实施数据聚类算法的优化改良。
1.2 大数据模糊聚类中心的确定
在得到相关特征后,需要确定聚类中心[6],将大数据特征等信息进行整合,根据顺序σ放射至n维欧氏空间,将n设置为维特征向量T,大数据特征向量为f,f=(f1,f2,…,fn),把各个特征fi=(i=1,2,…,n)设为此向量的分量,然后将各个类型特征和特征间的联系进行定义[7]。以隶属度来确定各个数据点划分某聚类范围的聚类中心[8]。
将n个向量xi(i=1,2,…,n)划成c个模糊组,且将每组的聚类中心点估计出来,将非相似性的价值函数降至最低[9-11],达到聚类中心使用值在[0,1]中的隶属度来明确所属各组的程度值。模糊划分对应的是隶属矩阵U默认存在取值在[0,1]中的元素。经统一化整合,某数据集的隶属度的和始终等于1。

所以,聚类中心的价值函数为式(5)的常态模式。

此间,uij∈[0,1],模糊组i的聚类中心是ci,dij=‖ci-xj‖是第i个数据点中的欧几里德距离;并m∈[1,∞]为某加权指数。
1.3 基于模糊近似的区域判定聚类算法
在模糊区域判定算法设计过程中,以模糊近似聚类算法为基础[12],基于上小节大数据量模糊聚类特征和聚类中心分析结果,能够提供稳定的聚类区域判定方法。过程如下:
隶属度计算:用uij表示样本数据与聚类中心的隶属关系,可采用模糊集理论将隶属度为{0,1}的二值拓展到[0,1],其中p表示加权参数,也称平滑参数。

确定模糊聚类数:通常用熵来表示原子的不规则分布,而海量数据的分布与原子分布的情况类似。本文采用熵的方法,可以在算法的迭代过程中,对模糊聚类区域判定结果进行主动修正,保证每一个经过模糊聚类后的聚类数,都与一个新的隶属矩阵U相对应[13],且每个U中都含有不同的平均信息熵。当模糊聚类数对应的平均信息熵最小时,其所对应聚类数为最优解,用公式(13)来表示与隶属矩阵对应的平均信息熵:

公式(7)中样本j属于聚类i的隶属度为uij,最佳聚类系数是当平均信息熵H最小时的M。
1.4 算法实现过程
输入:海量数据集,极值ε,本文算法的最大迭代次数以及比例规模N。
输出:模糊聚类结果C,M。
步骤描述:
步骤1:确定分类数目[14],分类数目m=n/N≤M(n为样本总数,N为规模比例),用{Z1,Z2,…,ZM}表示初始质心;
步骤3:对步骤(2)中新质心之间距离实施计算,搜索与Zi的相似上近似集合Si;
步骤6:根据公式(2)计算H(h),若出现H(h)<H(h+1),则模糊聚类数M=M+1并返回步骤2;反之,最佳模拟聚类数为M,算法结束。
2 实验分析
2.1 聚类效果分析
实验利用加州大学厄文分校机器学习库中提取的海量数据集为实验数据,实验数据共含有150种的不同种类信息,每50种数据种类均从三种数据库中选取[15]。对以上聚集进行数据特征聚类,聚类结果如表1所示。
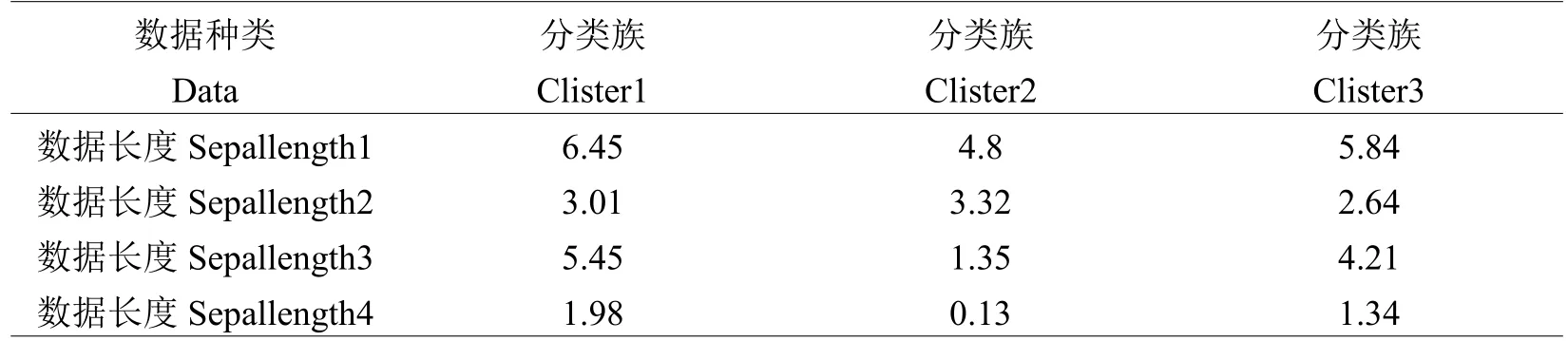
表1 特征聚类结果Table 1 Clustering results
利用本文方法计算该组数据集的实际模糊聚类中心位置是:Z1=6.58,2.97,5.55,2.02,Z2=5.00,3.42,1.46,0.24,Z3=5.93,2.77,4.26,1.32。计算数据中心差异化分类结果如表2所示:

表2 差异分布结果Table 2 Difference distribution results
从表2差异分布结果可以看出,本文算法模糊聚类中心聚类正确比例达到98.6%,模糊聚类正确结果较高。
2.2 不同算法的对比试验
在上文分类结果的基础上,为验证本文基于海量数据分类的模糊区域判定算法的有效性,以UCI标准数据集和实际项目为实验数据,实验数据共包括4部分,第一部分为UCI-IRIS数据分为三类共150个样本;第二部分为UCI-Wisconsin Breast Cancer数据其中良性样本和恶性样本分别为458和241条,且该两组数据均无缺失;实验设备采用计算机为DELL.760,内存为4G,运行环境为MATLAB.1环境下进行,为精确获取不同模糊聚类算法的有效性,以基于欧氏距离、DTW距离的模糊聚类算法为对比实验,分析不同算法对特征差异平衡数据的聚类结果。表3为不同算法对平衡数据聚类结果。
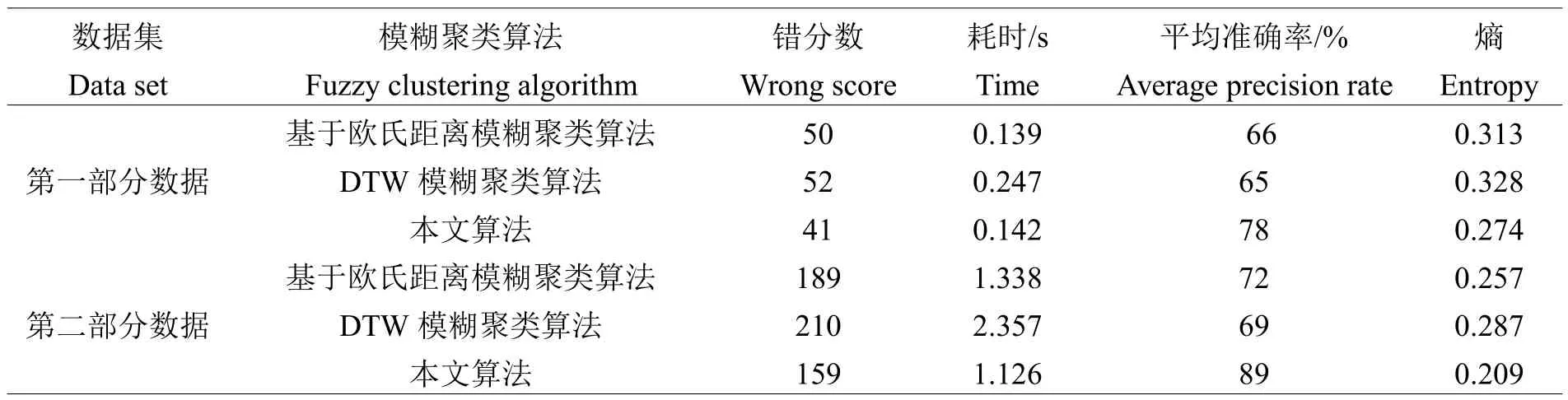
表3 不同算法对平衡数据聚类结果Table 3 Clustering results of different algorithms for balanced data
从表3数据聚类结果可以得出,在特征平衡数据中应用基于欧氏距离模糊算法、DTW模糊聚类算法和本文算法的聚类效果不同,本文算法在聚类正确率和平均正确率的结果均优于另外两种算法,可见本文算法可用于特征平衡数据下的模糊区域判定中,且聚类结果的有效性较高,主要因为特征平衡数据差异较小,在聚类中存在较大困难,而本文方法很好的解决了这问题。
3 结论
本文提出海量数据分类中的模糊区域判定算法,可以对具有不同特征的海量数据进行模糊聚类,提高模糊聚类效果和效率。
[1]周双,冯勇,吴文渊,等.一种基于模糊C均值聚类小数据量计算最大Lyapunov指数的新方法[J].物理学报,2016,65(2):42-48
[2]Roghanchi P,Kallu R,Thareja R.Use of fuzzy set theory to rmr classification for weak and very weak rock masses[J].International Journal of Earth Sciences&Engineering,2014,7(3):997-1003
[3]Gabriel Filho LRA,Putti FF,Cremasco CP,etal.Software to assess beef cattle body mass through the fuzzy body mass index[J].Engenharia Agricola,2016,36(1):179-193
[4]王永贵,李鸿绪,宋 晓.Map Reduce模型下的模糊C均值算法研究[J].计算机工程,2014,40(10):47-51
[5]王宇凡,梁工谦,张淑娟.基于相似度量的模糊支持向量机算法研究[J].微电子学与计算机,2014(4):112-116
[6]陈池梅,张 林.基于贝叶斯网络的海量数据多维分类学习方法研究[J].计算机应用研究,2016,33(3):689-692
[7]Jasmine JSL,Safana A.Possibilistic fuzzy c means algorithm for mass classificaion in digital mammogram[J]. International Journal of Engineering Research&Applications,2014,4(12):337-346
[8]翟皓,袁占良,黄祥志,等.一种面向海量遥感数据分类应用的并行解决方案[J].计算机工程与科学,2016,38(12):2450-2455
[9]周治平,朱书伟,张道文.分类数据的多目标模糊中心点聚类算法[J].计算机研究与发展,2016,53(11):2594-2606
[10]刘光敏,陈庆奎,王海峰.海量数据流的提升小波变换并行算法研究[J].小型微型计算机系统,2015,36(2):343-348
[11]高见文,薛行贵,罗 杰,等.基于迭代式Map Reducede的海量数据并行聚类算法研究[J].中国科技论文,2016,11(14):1626-1631
[12]桂 勋.基于递推算法的海量COMTRADE数据计算并行化[J].电力系统自动化,2014(1):86-91
[13]李方一,肖夕林,刘思佳.基于网络搜索数据的区域经济预警研究[J].华东经济管理,2016,30(8):60-66
[14]高 凯,刘 琳,张松树.海量电网数据管理与挖掘系统的功能设计与实现[J].电网技术,2014,38(s1):67-70
[15]刘绍毓,周 杰,李弼程,等.基于多分类SVM-KNN的实体关系抽取方法[J].数据采集与处理,2015,30(1):202-210
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
数学小灵通(1-2年级)(2021年4期)2021-06-09
铁道通信信号(2019年6期)2019-10-08
当代陕西(2019年14期)2019-08-26
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
雷达学报(2017年6期)2017-03-26
中学数学杂志(初中版)(2016年5期)2016-11-01
互联网天地(2016年1期)2016-05-04
