
基于稀疏表示和拉伸变换的SAR图像目标识别
2018-05-18 05:33李廷元
电光与控制 2018年5期
李廷元
(中国民用航空飞行学院计算机学院,四川 德阳 618307)
0 引言
预处理、特征提取和分类识别是传统 SAR 图像目标识别的3大步骤,其中,特征提取步骤对最终的目标识别率影响很大。目前应用的特征提取算法普遍存在步骤繁杂、计算复杂度大、容易受背景噪声影响等缺点,为了降低噪声影响往往又需要引入新的图像预处理算法,这导致目标识别步骤增多,复杂度变大,影响了识别的实时性和有效性[1-3]。
近年来,作为一种新的信号分析工具,稀疏表示方法在信号处理领域受到了广泛关注[4-5]。稀疏表示能够将一个信号表示为字典中基本信号的稀疏线性组合,即信号能被一组基线性表示,并且该线性表示系数中只有小部分非零,在稀疏表示中该组基被称为字典,每个基即为字典中的一个原子。由于同一类信号稀疏分解后可以用一组相同的基表示,因此稀疏表示方法被逐渐引入到了模式识别领域。基于稀疏表示的目标识别本质上基于重构恢复,通过对比重构恢复的精度判断测试目标是否与训练目标同属一类,判断的标准仅仅是目标函数的取值,不依赖于提取特征的好坏,在测试图像和训练图像背景基本一致的情况下也不需要对背景噪声进行任何处理,大大省略了目标识别算法的计算步骤。
在具体应用方面,2009 年WRIGHT 等将稀疏表示理论用于人脸图像识别,证明了基于稀疏表示的目标识别方法拥有很高的识别率和较好的鲁棒性[6];ZHANG等采用联合稀疏表示方法对 SAR 图像进行目标识别,同样取得了较好效果[7-12]。但当测试图像与训练图像差异性较大时,比如不同俯仰角下的 SAR图像,利用已有的方法还难以达到满意的识别效果。这是因为:利用稀疏表示识别目标的关键问题就在于如何构造有效的字典,当测试图像与训练图像差异性较大时,则可能位于不同低维子空间,此时测试图像就很难用训练样本生成的字典进行有效表示,因而无法保证优化算法求解得到的稀疏解包含测试图像的类别信息[6],最终影响了识别的准确率。
解决上述问题的关键是如何利用训练样本生成训练图像,其与测试图像具有相同的低维子空间,进而扩充已有字典,使得测试图像能够用扩充后的字典进行有效表示,最终达到提高识别准确率的目的。本文从 SAR 图像形成机理出发,以测试图像与训练图像是不同俯仰角下获得的这种 SAR 图像中常见的差异性为对象,研究这种情况下如何扩充字典,提高基于稀疏表示的 SAR 图像目标识别准确率。
1 稀疏表示目标识别模型
1.1 稀疏表示理论
稀疏表示能够将一个信号表示为字典中基本信号的稀疏线性组合,即信号能被一组基线性表示,该线性表示系数中只有小部分非零。稀疏表示要求字典相对过完备,即基的个数远大于基的维数,对应的表示系数即信号在该过完备字典上的稀疏表示系数。
稀疏线性模型可表示为
y=Ax+n
(1)
式中:y∈Rn×1为n维输入信号;A∈Rn×m(m>n)为冗余字典;x为稀疏分解系数;n∈Rn×1为噪声模型。当输入信号y和字典A给定时,求解稀疏分解系数x的问题可以转化为
(2)
式中:‖·‖表示范数;ε表示重构误差。由于L0范数求解困难,求解时可以采用贪婪策略的算法(如匹配追踪算法、正交匹配追踪算法等)或使用L1 范数代替 L0 范数进行近似求解(如基追踪算法、同伦算法(HA)等)。
1.2 基于稀疏表示的目标识别
目标识别问题就是根据由k个类别共n幅的带标签训练图像集来对一幅测试图像进行分类,将第i类训练样本共ni个变为矩阵的形式Ai={vi,1,vi,2,…,vi,ni}∈IRm×ni,其中,每一幅w×h的训练图像表示为列向量v∈Rm,m=w×h的形式。根据稀释表示理论,同一类别的数据位于同一个低维线性子空间上,即属于第i类的测试图像y0将位于与其类标相同的训练图像张成的线性子空间上
y0=ai,1vi,1+ai,2vi,2+…+ai,nivi,ni
(3)
式中,ai,j∈IR,j=1,2,…,ni,为线性表示系数。
这样就可以将所有k个类别的训练图像表示为矩阵形式,即
A=[A1,A2,…,Ak]=[vi,1,vi,2,…,vk,nk]
(4)
式中,A∈IRm×n,那么任意测试图像y可以表示为所有训练图像的线性组合
y=Ax0∈IRm
(5)
式中,x0=[0,…,0,αi,1,αi,2,…,αi,ni,0,…,0]T∈IR是一个稀疏向量,只有与该测试图像对应的第i类对应的系数不为 0。

可以对一个给定的测试样本y进行估计
(6)

(7)
基于稀疏表示的目标识别算法具体过程如下:
1) 输入训练样本矩阵A=[A1,A2,…,Ak]∈IRm×n,测试样本y∈IRm,误差阈值ε;
2) 对矩阵A中列向量进行归一化;
5) 计算输出类别,即identity(y)=argminiri(y)。
2 基于拉伸变换的字典扩充
根据SAR图像形成机理,即使对于同一个目标,成像条件的微弱变化都会带来目标SAR图像的变化,并且由于SAR图像具有相干斑等特点,因此利用目标已有的SAR图像准确无误地重建成像条件发生变化后的目标SAR图像目前还非常困难。尽管如此,对于一些成像条件的微弱变化,仍然可以利用SAR图像在一定条件下的某些特性,生成成像条件发生变化后的目标近似SAR图像。考虑到SAR图像中不仅包含了反映目标电磁特性和结构特性的目标图像,还包含反映目标结构与雷达成像几何的阴影图像,目标图像和阴影图像都能够用于SAR图像目标识别,为了研究利用已有训练图像扩充字典的方法,需要首先分析SAR图像中目标及阴影特性。
2.1 SAR 图像目标及阴影特性分析
与光学图像一样,SAR图像也具有阴影特性,但不同于光学图像阴影形成原理,SAR图像的阴影是由于电磁波辐射受到阻挡而形成的,因此SAR图像的阴影部分不包含目标的信息,而且内部相对平滑,还具有相对明显的轮廓特征。图1所示为阴影形成原理。

图1 SAR图像阴影形成示意图Fig.1 SAR image shadow formation
由图1可知,由于SAR系统以侧视方式对目标成像,根据成像平台与目标的几何关系,当波束俯仰角小于等于背坡倾角时,就会产生遮挡效应,反映在图像中表现为目标的一段对应阴影。因而,SAR图像包含背景区域、目标区域和目标阴影区域(简称为阴影区域),其中,背景区域目前还很少用于SAR 图像目标识别,因此这里主要分析目标区域和阴影区域特性。图中,目标区域长度由最近点N和最远点F决定,阴影区域长度由最远点F和成像平台对目标的俯仰角θ决定。并且不难推出,如果平台在不同位置具有相同俯仰角,即平台沿着俯仰角波束直线移动,阴影区域的长度始终会保持不变,而平台与目标最近点距离ON的变化将导致最近点在投影线上发生移动,即目标区域的长度会发生变化。
基于以上特性,当成像平台在同一个方位以两种不同的俯仰角对目标成像时,目标图像的目标区域和阴影区域就具有了不同的尺度特性,本文假设在俯仰角变化范围内目标相对于雷达的最远点F和最近点N不发生变化,并且俯仰角变化主要影响目标区域大小,目标区域散射点电磁散射特性基本保持不变。图2 所示为θA和θB(为了方便分析,设θA<θB)不同俯仰角下同一个目标图像中目标区域和阴影区域尺度特性,其中,目标区域图像长度分别用LAt和LBt表示,对应的阴影区域长度分别用LAs和LBs表示。

图2 不同俯仰角下目标图像与阴影图像几何关系Fig.2 Geometric relationship between target image and shadow image at different pitch angles
根据图2,有
(8)
(9)
由式(8)可知,阴影区域长度仅由俯仰角θA和θB决定,而由式(9)可知,要计算目标区域长度LAt和LBt,还需要知道φA和φB,通过图2可知,φA和φB是由成像平台高度以及与目标水平距离决定的,即成像平台位置A和位置B。图3给出了平台B位置不动,平台A沿俯仰角方向移动过程中LAt和LBt的几何关系。
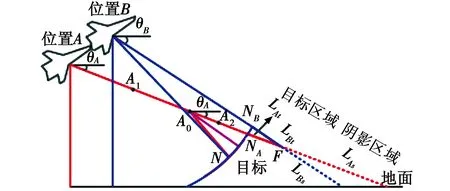
图3 平台A移动对L的影响Fig.3 Impact of platform A’s movement on L
由图3可知,设NNB与AF交点NA,平台A移动对LAt和LBt的影响包含3种情况:1) 当平台A位于近点N与终点垂直平分线上A0点,此时两种俯仰角下目标区域长度相等,即有LAt=LBt成立;2) 当平台A位于A0点左侧,比如图中A1点,此时LAt>LBt,并且距离A0点越远,LAt越大;3) 当平台A位于A0点右侧,比如图中A2点,此时LAt>LBt,并且距离A0点越远,LAt越小。
在上述条件下,根据不同俯仰角下SAR 图像中目标区域和阴影区域的比例关系,就能够通过拉伸已知俯仰角下的目标SAR 图像生成与已知俯仰角接近的未知俯仰角下的目标近似SAR 图像,利用生成的近似SAR 图像扩充字典,使得测试样本集与训练样本集位于同一维线性子空间,最终达到提高稀疏表示方法识别SAR 图像准确率的目的。
2.2 拉伸变换数学描述及变换方法
根据2.1节分析,不同俯仰角下的阴影区域存在式(8)所示的比例关系,而目标区域之间的比例关系则随平台A与A0点的位置关系不同而变化。利用这种比例关系,分别定义两种拉伸变换,对目标和阴影区域按对应的比例进行拉伸。图4为拉伸变换示意图,目标和阴影的拉伸方向由成像平台与目标的相对位置决定,为方便后续操作,将拉伸变换分解为垂直方向和水平方向2个分量,且满足三角函数关系。

图4 拉伸变换示意图Fig.4 Schematic diagram of stretching transformation
假设目标部分为A,A构成的最小矩形记为A′,大小为l×k,经过拉伸变换后的目标部分记为AL,大小为l′×k′;阴影区域为B,B构成的最小矩形记为B′,大小为h′×s′,经过拉伸变换后的目标部分记为BL,大小为h×s;针对目标部分和阴影部分的拉伸变换分别定义为LT(·)和LS(·),拉伸变化的数学描述可以记为
(10)
式中,ε为目标区域的比例拉伸系数,该系数与角度φA和φB有关。理想条件下,当训练图像和样本图像成像参数已知时,可求解出φA和φB,进而可确定唯一的目标区域比例拉伸系数。但由于多方面原因,很多情况下测试图像与训练图像的成像参数是不完整的,无法求解出φA和φB的具体值,因此,在此情况下只能根据先验知识给出目标区域比例拉伸系数的可能区间,并将会生成多幅目标近似SAR 图像。
3 基于SR-S 的高分辨SAR 图像目标识别方法
文献[12]和2节分析结果都表明,综合利用SAR图像中的目标区域图像和阴影区域图像能够更丰富地描述SAR 图像目标特性,因此,本文提出一种基于稀疏表示和拉伸变换(Sparse Representation and Stretch Transform,SR-S)的高分辨SAR 图像目标识别方法,该方法综合考虑SAR 图像目标部分与阴影部分对识别的影响,结合2.1节中对目标及阴影区域的特性分析,采用拉伸变换的字典扩充方法,分别对目标图像和阴影图像构造独立的过完备字典,并通过联合稀疏表示的方法对SAR 图像目标进行识别。
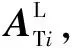
(11)
综上所述,给出基于SR-S的高分辨SAR图像目标识别方法的步骤。
1) 根据测试图像俯仰角,通过式(8)、式(9)计算训练图像的阴影区及目标区比例系数。
2) 利用已有的SAR图像阴影分割方法,将训练样本和测试样本SAR图像目标区域和阴影区域分开。由于本文重点不是最优分割方法设计,因此直接采用分割性能较好的基于马尔可夫随机场的迭代条件模式(Iterative Conditional Mode,ICM)算法[13]对SAR图像进行分割。分割后运用形态学滤波先开后闭去除分割区域孤立点,获得目标图像与阴影图像,并获得两区域的图像像素坐标。
3) 将训练样本目标图像和阴影图像的像素坐标输入支持向量机(Support Vector Machine,SVM)寻找目标与阴影的最优分类线,得到拉伸变换方向角β。
4) 按照1)比例系数,利用式(8)分别拉伸目标图像与阴影图像。
5) 利用4)经拉伸变换后得到的目标图像和阴影图像分别构造字典AT,AS。
6) 利用字典AT,AS按1.2节中算法步骤及式(9)求解联合稀疏表示。

4 实验与结果分析
为了验证本文所提方法性能,采用MSTAR实测数据进行实验,对比本文提出的联合稀疏表示和尺度变换的SAR图像目标识别方法识别性能与直接采用稀疏表示的SAR图像目标识别方法性能。
MSTAR数据是DARPA和AFRL 利用X波段聚束式SAR实测得到地面静止目标数据。实测图像像素大小为128×128,分辨率为0.3 m×0.3 m。该数据集包含了俯仰角分别为15°和17°的3类目标共7种型号,并使用17°俯仰角下的图像作为训练样本,15°俯仰角下的图像作为测试样本,这也与本文引言中提到的待识别SAR成像目标特点相吻合。表1所示为数据集的详细情况。

表1 数据集各类目标和型号图像个数统计
首先按照2节提出的图像合成算法,利用17°俯仰角的训练样本合成15°俯仰角的测试样本,由于MSTAR数据集中的目标均位于图像中心,故可省略3节中的步骤2)操作。图5所示为一幅T72目标SAR图像经过分割、形态学滤波、SVM分类和最后拉伸变化得到的处理结果(为了便于对比,图5按照纵向排列各步骤得到的SAR图像)。其中,步骤2)应用的ICM分割算法设定分割类别为2,最大迭代次数为50,能量系数设为0.6。SVM寻找最优分类线时使用Matlab自带的SVM工具箱,参数均设为默认。
首先应用全部训练样本和测试样本进行实验,并将本文算法(SR-S)与只使用训练样本集构造字典的稀疏表示算法(SR)以及SVM算法进行性能比较。其中,SVM算法的识别率参考文献[11],SR和SR-S的目标识别算法采用1节给出的步骤进行,SR算法对输入图像进行随机投影降至500维构造字典,SR-S算法均将目标图像和阴影图像通过随机投影降至500维构造字典。对式(2)统一采用同伦算法(HA)[15]进行优化求解。HA算法的最大迭代次数设为5000。表2所示为应用全部训练样本和测试样本时不同算法识别率结果对比。
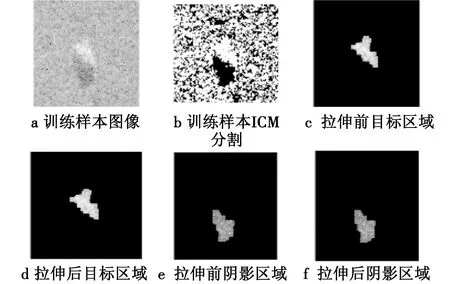
图5 T72 目标 SAR 图像及拉伸变换前后的目标区域和阴影区域Fig.5 T72 target SAR image and the target area and shadow area before and after the stretching transformation
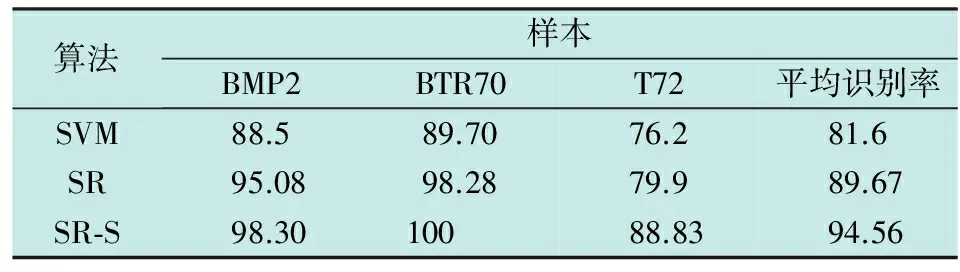
算法样本BMP2BTR70T72平均识别率SVM88.589.7076.281.6SR95.0898.2879.989.67SR⁃S98.3010088.8394.56
由表2可以看出:纵向对比可知,由于BTR70目标训练样本与测试样本型号完全相同,而BMP2目标和T72目标都只有1个型号的训练样本,测试样本都有3个型号,因此SVM算法、SR算法以及本文提出的SR-S算法对BTR70目标的识别率都明显高于BMP2目标和T72目标;横向对比可知,SR算法的识别率明显高于SVM算法,而基于SR算法的SR-S算法由于用合成的15°俯仰角训练样本扩充了字典,进一步提高了SR算法的识别率。实验结果表明,本文算法能够以较高的识别率识别SAR图像目标。
由于本文算法的创新在于用已知俯仰角的训练图像合成不同俯仰角的测试图像以增加训练样本集,下面对比不同大小训练样本集对不同算法识别性能的影响,其中,SR-S算法的字典全部使用合成的15°俯仰角图像来构造。SR-S算法与SR算法全部采用相同随机投影矩阵降至500维,样本集大小范围设定为[600,800,1000,1200,1400]。实验结果对比如图6所示。
通过图6可以看出,随着训练样本集的增加,3种识别算法识别率都明显提高,3种算法识别率大小依次为SR-S>SR>SVM。本文提出的SR-S算法即使全部采用拉伸变换生成的15°俯仰角图像构造字典,仍能够获取比SR算法更高的识别率,这也进一步验证了本文基于拉伸变换的字典扩充算法的有效性。只采用拉伸变换图像构造字典的识别率不及表2中采用全部训练样本构造字典的识别率,主要是因为字典相对而言不够完备。
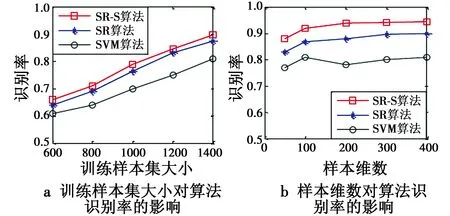
图6 3种识别算法的识别率对比Fig.6 Comparison of three recognition methods on recognition rate
对比样本维数对算法识别率的影响。图6b给出了利用随机投影降维算法进行不同维数降维后的算法识别率结果。可以看出,本文提出的SR-S算法在各种降维维度下均获得了最高识别率,在样本维数相同的情况下,3种算法识别率大小依次为SR-S>SR>SVM,识别率都随样本维数的增加呈现上升趋势,基于稀疏表示的SR和SR-S算法识别率对样本维数并不敏感,这也表明了基于稀疏表示的SAR图像目标识别算法相比传统方法鲁棒性更好。
综上分析,本文提出的基于SR-S算法的SAR图像目标识别算法充分利用了基于稀疏表示识别目标方法的优越性能,并且通过增加样本库进一步提高了基于稀疏表示的SAR图像目标识别方法的识别率。
5 结论
针对合成孔径雷达(SAR)图像目标识别中已有的基于稀疏表示的识别算法识别率不高的问题,将SAR图像中目标区域和阴影区域特性相结合,本文提出了一种基于稀疏表示和拉伸变换的SAR图像目标识别算法。通过将训练样本图像进行拉伸变换生成新的训练样本图像,在此基础上构造稀疏字典,并通过求解目标区域和阴影区域的联合稀疏表示,根据重构误差最小准则完成了SAR图像目标识别。实验结果表明,使用本文提出的算法对SAR图像的识别率高于已有算法,验证了本文算法的有效性。
参 考 文 献
[1] YE X M,GAO W,WANG Y,et al.Research on SAR images recognition based on ART2 neural network [C]//The 7th IEEE Conference on Industrial Electronics and Applications(ICIEA),2012:1888-1891.
[2] CAO Z J,CUI Z Y,FAN Y.SAR automatic target recognition using a hierarchical multi feature fusion strategy [C]//GC’12 Workshop:Radar and Sonar Networks, 2012:1450-1454.
[3] TANG T,SU Y.Object recognition based on feature match-ing of scattering centers in SAR imagery [C]//The 5th International Congress on Image and Signal Processing (CISP 2012),2012:1073-1076.
[4] THIAGARAJAN J J,RAMAMURTH Y K N,KNEE P.Sparse representations for automatic target classification in SAR ima-ges [C]//The 4th International Symposium on Communications,Control and Signal Processing (ISCCSP),2010:1-4.
[5] THIAGARAJAN J J.Dictionary learning algorithms for shift-invariant representation and classification[D].Phoenix:Arizona State University,2008.
[6] WRIGHT J,YANG A Y,GANESH A,et al.Robust face recognition via sparse representation [J].IEEE Transa-ctions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[7] ZHANG H C,NASRABADIC N M,ZHANG Y,et al.Multi-view automatic target recognition using joint sparse representation [J].IEEE Transactions on Aerospace and Electronic Systems,2012,48(3):2481-2497.
[8] 殷飞.基于稀疏学习的图像维数约简和目标识别方法研究[D].西安:西安电子科技大学,2013.
[9] 殷飞,焦李成.基于旋转扩展和稀疏表示的鲁棒遥感图像目标识别[J].模式识别与人工智能,2012,25(1):89-95.
[10] 程健,黎兰,王海旭.稀疏表示框架下的 SAR 目标识别[J].电子科技大学学报,2014,43(4):524-529.
[11] 丁军,刘宏伟,王英华.基于非负稀疏表示的 SAR 图像目标识别方法[J].电子与信息学报,2014,36(9):2194-2200.
[12] 丁军,刘宏伟,王英华,等.一种联合阴影和目标区域图像的 SAR 目标识别方法[J].电子与信息学报,2015,37(3):594-600.
[13] 张斌,马国锐,林立宇,等.基于分层 MRF 模型的 POLSAR 图像分类算法[J].系统工程与电子技术,2011,33(11):2413-2417.
[14] BARANIUK R G,WAKIN M B.Random projections of smooth manifolds [J].Foundations of Computational Ma-thematics,2009,9(1):51-77.
[15] 王则柯,高堂安.同伦方法引论[M].重庆:重庆出版社,1990:84-104.
猜你喜欢
计算机工程(2020年3期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
小学阅读指南·低年级版(2019年11期)2019-07-01
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
创新作文(小学版)(2016年19期)2016-08-22
系统工程与电子技术(2016年7期)2016-08-21
读者(2016年14期)2016-06-29
