
k*-支配Skyline查询在实验数据检索中的应用
2018-05-21 07:42黄金晶
实验室研究与探索 2018年4期
黄金晶, 赵 雷
(1. 苏州工业职业技术学院 软件与服务外包学院, 江苏 苏州 215104;2. 苏州大学 计算机科学与技术学院, 江苏 苏州 215006)
0 引 言
实验通常会产生大量的实验数据。实验数据中较为“突出”的数据往往具有较高的价值。如何从大量的实验数据中检索出“突出”的数据,是一个值得研究的问题。找到这些较为“突出”的数据,常常是实验结果处理过程中需要完成的工作。当样本点数量巨大且属性众多的时候,这项任务非常具有挑战性。
利用多关键字查询技术可以帮助用户检索需要的实验数据。Skyline查询是解决多关键字查询的有效方法之一。Skyline查询是从数据集中选出不被支配的全部数据点,近年来在多目标决策、用户偏好查询、可视化等方面应用较为广泛。然而,当数据量较大时,Skyline查询响应的时间较长;当数据维度较高时,数据间较难产生支配关系,导致Skyline查询返回的结果集较大,不易给出有价值的查询结果。为解决这一问题,Chan等[14]人提出了k-支配Skyline查询,只要数据点在任意k维度上存在支配关系即可。但是k-支配Skyline查询有可能产生循环支配的问题,导致查询没有结果。
Top-k查询是应对多关键字查询的另一种常用方法。Top-k查询仅返回k个结果,可以有效解决结果集太大带来的结果有效性问题。但是,大多数top-k查询需要借助评价函数。评价函数虽然可以体现用户偏好,但是评价函数的确定具有一定的主观性,结果未必是用户满意的。因此,不恰当的评价函数对结果集的有效性同样可能产生较大的影响。
本文提出一种k*-支配Skyline查询,将其运用于实验数据检索中。该查询在传统k-支配Skyline查询中引入用户偏好的优先级,消除了k-支配存在循环支配的可能性,既能保证产生结果又能控制结果集的大小,同时查询返回的结果也更加符合用户的偏好。将用户偏好的优先级引入支配关系,是同时解决上述多个问题的关键,也是本文最主要的创新点和贡献。
1 相关研究
Skyline查询[1]由Borzsonyi等[1]于2001年引入数据查询领域,提出块嵌套循环(Block Nested Loop, BNL)算法以及分区回归(Divide-and-Conquer, DC)算法,是数据库、数据挖掘领域的经典研究问题,而后产生了很多新的高效算法。比如,Kossmann等[2]提出的近邻查询算法(Nearest Neighor, NN),给出一种基于R-树索引的计算方法;Tan等[3]提出了计算Skyline的位图算法;Papadias等[4-5]提出了一种分支界限算法(Branch and Bound Skyline, BBS);文献[6-8]中讨论了子空间的Skyline计算问题;Lian等[9]提出了在不确定的数据集上进行Skyline计算;Chen等[10]给出了索引方式的top-k空间关键字查询的方法。当数据量大,数据源分布较多时,集中式环境下进行数据处理效率较低,Huang等[11]提出了分布式环境下的Skyline查询;文献[12-13]中分别给出了一种在海量数据集中使用MapReduce的高效Skyline查询处理方法。在高维数据集中,数据点之间较难产生支配关系,Chan等[14]提出了k-支配skyline查询,减少了高维空间中Skyline查询返回的数据点;此外还有一系列对k-支配算法的改进,比如文献[15]中提出了一种使用简化预排序的k-支配skyline查询算法;文献[16]中提出了一种基于索引的高效k-支配skyline算法。
上述研究成果着重解决在大数据集或高维度数据集上Skyline计算的效率问题,未能有效解决对于高维数据集上结果集较大、结果集有效性差的问题。同时,上述研究成果对用户偏好并未给予足够的关注。基于上述原因,本文的研究将着重从两个方面解决Skyline查询结果集的有效性问题,一方面既可保证产生结果集,又能控制结果集的大小,另一方面能满足用户偏好。
2 相关概念描述
本文在k-支配skyline的基础上,提出了k*-支配skyline算法,下面首先对k-支配skyline的相关概念进行描述。
定义1支配。给定一个d维的数据集D={D1,D2,…,Dd},p、q为D中的数据点,p={p1,p2,…,pd},q={q1,q2,…,qd},若p在d个维度上的取值都不比q差,且至少有一个维度上的值比q好,则称p支配q[1]。
定义2Skyline数据集。对于数据集D中的数据点p,若D中不存在能支配p的数据点,则p为D中的Skyline点。D中所有的Skyline点的集合就是Skyline数据集。
为便于展示,以2维空间举例说明Skyline数据集。在图1中,不失一般性,设数值越小越好,则b点显然支配e点。而a与b之间,尽管横坐标a
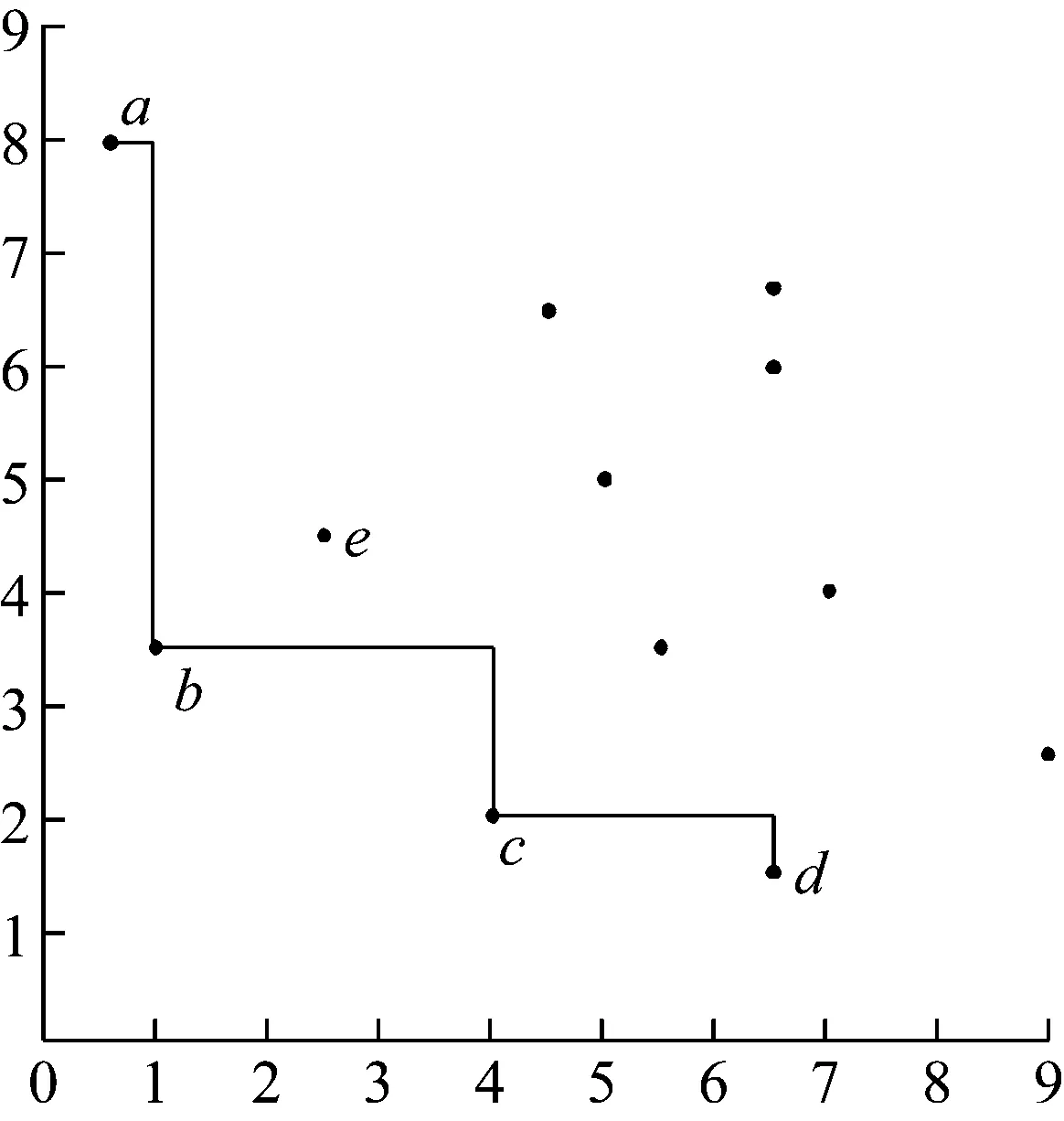
图1 skyline数据集举例
定义3k-支配。对于d维数据集D中的点p和q,若存在k个维度使得p在这k维上的值都不差于q在这k维度的值,且在这k个维度上,至少有一个维度使得p的值优于q,称p点k-支配q点[10]。
3 k*-支配Skyline查询
3.1 k*-支配Skyline定义
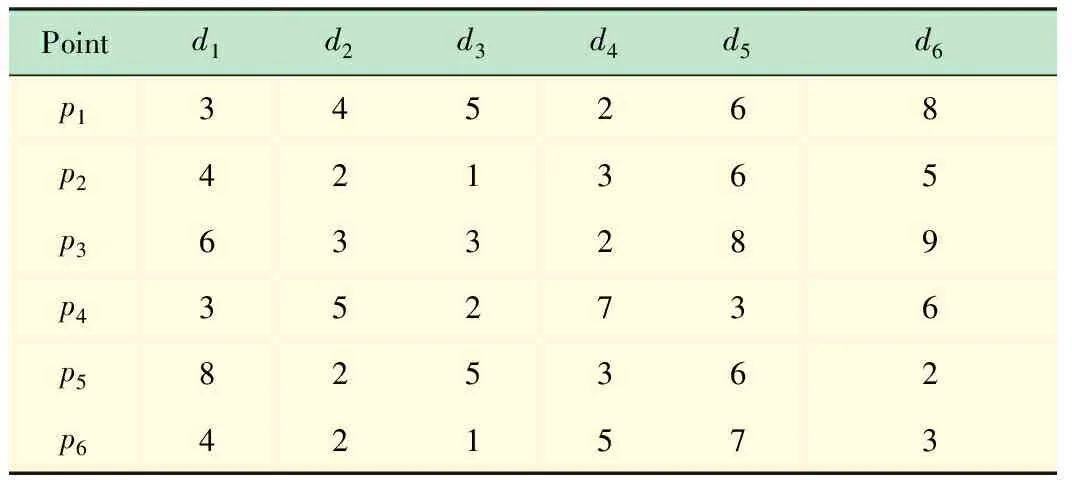
由于k-支配可能存在循环支配的现象,比如表1所示的数据点,假定在每个维度上,属性值越大越好。显然p13-支配p2,p23-支配p3,p33-支配p4,而p4在d3、d4、d5维度上的值大于p1,因而p43-支配p1。

表1 3-支配举例
为了消除循环支配,本文提出了一种新的k*-支配Skyline查询,考虑用户偏好的优先级关系,使得查询结果更加符合用户的实际需求。对于每一个用户来说,查询关键字的序列不同,偏好的重点不同,因而可以定义一个偏好优先关系R。
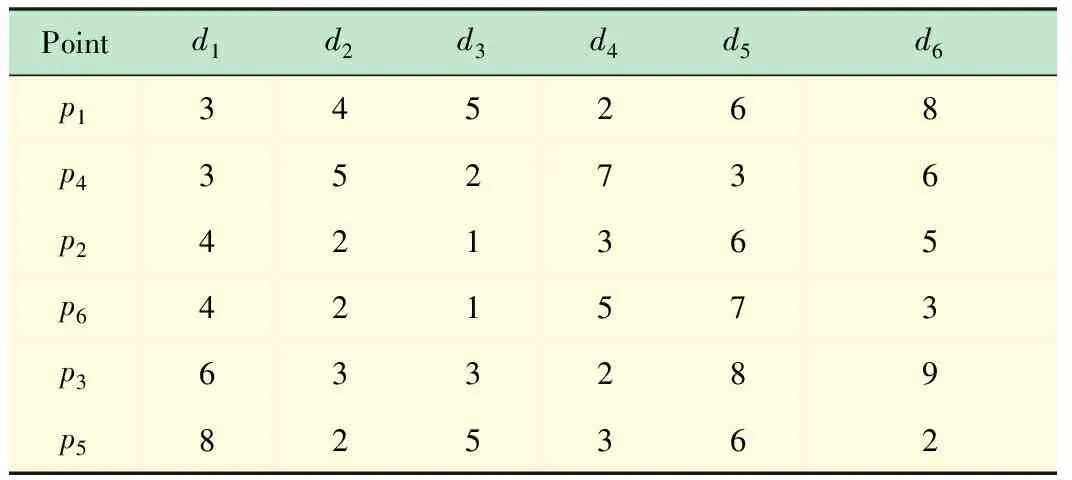
定义4R关系(偏好优先关系)。设有一个n维的数据集D={D1,D2,…,Dn},不失一般性,设属性顺序S=(D1,D2,…,Dn)。有元组x={x1,x2,…,xn}和y={y1,y2,…,yn},如关系R={ 为了更好的解释关系R,下面以实例说明。设两个不同的用户查询x和y,在相同维度上的数值x={2,1,1,1,1},y={2,1,0,1,1},当i=3时,x3>y3且x1=y1,x2=y2,则x和y满足偏好优先关系R,即x优于y。 引理1R关系具有反自反性、反对称性和传递性。 证明 (1) 反自反性。二元关系 (2) 反对称性。设 (3) 传递性。设 由上可得x1>z1,或∃k∈(1,n]有x1=z1,x2=z2,…,xk-1=zk-1,xk>zk,即说明x和z之间满足R关系,即R关系具有传递性。 证毕。 k*-支配是在k-支配中加入了偏好优先关系R。下面给出k*-支配的定义。 定义5k*-支配。在一个n维的数据集D={D1,D2,…,Dn}上,p1和p2为D上的数据点,如果p1k-支配p2且p1和p2之间满足偏好优先关系R,则称p1k*-支配p2。 定理1k*-支配不存在循环支配关系。 证明设存在一个维的数据集D={D1,D2,…,Dn},p1,p2,…,pn为D上的数据点,则不存在这样一个序列(px,1,px,2,…,px,m),当px,1k*-支配px,2,px,2k*-支配px,3,…,px,m-1k*-支配px,m时,有px,mk*-支配px,1。 根据k*-支配的定义,px,1k*-支配px,2,说明px,1k-支配px,2的同时偏好优先级大于px,2,同理,px,m-1k*-支配px,m,说明px,m-1k-支配pm的同时偏好优先级大于pm,由引理1可知,R关系具有反对称性和传递性,说明 证毕。 定义6k*-支配Skyline。k*-支配Skyline是不被任何点k*-支配的数据点所组成的集合。 计算k*-支配Skyline是在k-支配Skyline的基础上,需要引入属性的优先级关系。不同的用户,可以指定不同的属性优先级关系。在相同的数据集和相同的k值情况下,不同的属性优先级情况下会查询得到不同的结果。 3.2.1朴素算法(NA) 对数据集D中的每一个数据点n,将其与D中的其他所有数据点进行比较,如果p不能被D中的其他数据点k*-支配,则p是k*-支配Skyline数据集中的点。该算法对数据集中的每一个p元素都需要计算集合中其他元素是否能k*-支配p,因而计算量较大,称其为朴素算法(Naïve Algorithm,NA)。 3.2.2插入排序剪枝算法(ISPA) 由于偏好优先关系具有传递性,若在遍历集合数据的过程中,对数据点按偏好优先关系R进行排序,能对NA算法进行剪枝,加快算法的运行效率。 (1) 算法思想。根据k*-支配的定义,两个数据点之间需要同时满足k-支配和偏好优先关系R才是k*-支配。算法设置k*-支配skyline的候选集C和能被k*-支配的数据点组成的排除集L,其中C中的元素按照偏好优先关系升序排列,L中的元素按照偏好优先关系降序排列。对数据集合D中的数据求k*-支配Skyline的插入排序剪枝算法(InsertionSort Pruning Algorithm,ISPA)思想如下: ① 令C=Ø,L=Ø。 ② 读取数据集合D中的元素p,若D中没有元素,则算法结束。 ③ 读取候选集C中的数据点r,如果偏好优先级r ④ 若C中已没有数据点,说明C中没有数据点能够支配p。接着扫描L,看其中的数据点(除去③新加入的)能否k*-支配p。由于L中的元素按偏好优先关系降序排列,直接扫描优先级大于p的数据点。若能支配,则将p插入L中,转入步骤②;若不能,则说明p暂时不能被k*-支配,将其按升序加入R中,转入步骤②。 (2) 实例演示。为了更好的说明上述算法,下面举例说明如何在表2所示数据集中,找出3*-支配Skyline的数据点集合。设属性顺序S=(d1,d2,d3,d4,d5,d6)。 表2 数据集 具体步骤如下: ① 令C=Ø,L=Ø。 ② 读取p1,因为C和L中没有元素,直接将p1加入C集合中。 ③ 读取p2,扫描C中的数据点,p2的偏好优先级大于p1,且p2能3-支配p1,因而将p1加入L中,扫描L中的元素,p1为新加入的元素,不重复比较,直接将p2插入C中。C中的元素为{p2},L中的元素为{p1}。 ④ 读取p3,扫描C中的数据点,p3能3*-支配p2,将p2插入L,而p3不能被L中的p13*-支配,将p3加入C中。C中的元素为{p3},L中的元素为{p2、p1}。 ⑤ 读取p4,扫描C中的数据点,p3能3*-支配p4,将p4插入L中。C中的元素为{p3},L中的元素为{p2、p4、p1}。 ⑥ 读取p5,扫描C中的数据点,p5能3*-支配p3,将p3移出C集合,插入L集合。L中的元素为{p3、p2、p4、p1}。由于C中没有元素,继续扫描L中的元素,p3为新加入的元素,不重复计算,p2的偏好优先关系小于p5,由于L是按照偏好优先关系降序排列,其后的元素不再扫描,直接将p5插入C中。C中的元素为{p5},L中的元素为{p3、p2、p4、p1}。 ⑦ 读取p6,扫描C中的数据点,p5能3*-支配p6,将p6插入L集合。C中的元素为{p5},L中的元素为{p3、p6、p2、p4、p1}。 ⑧D中已没有元素,算法结束。本例中3*-支配Skyline的结果为{p5}。 3.2.3预排序剪枝算法(Pre-sortingPruningAlgorithm,PSPA) 在ISPA算法中,候选集C和移除集L中的元素是按插入排序的方法进行排序的,因而时间复杂度为O(n2)。由于偏好优先关系R具有传递性,可以将数据集D按照偏好的优先关系进行升序排序,即排在前面的数据点优先级小于等于后面的数据点,根据k*-支配的定义,排在前面的数据点一定不可能k*-支配后面的数据点。整个数据集中最后一个数据点的偏好优先关系最高,不可能被其他数据点支配,所以k*-支配Skyline一定存在结果集。在对数据进行预排序时,可以使用堆排序、快速排序等方法,减小排序的时间复杂度。 令为k*-支配skyline的结果集,PSPA算法的细节如下: 1. 令C=Ø; 2. forD中的每个元素pdo 3. flag=0; 4. forC中的每个元素rdo 5. ifr被pk*支配 then 6. 将r移出C; 7. else ifp与r相等 then 8. flag=1; 9. end for 10. if (flag==0) 11. 将p加入到C中; 12. end for 13. returnC; 当数据集中存在两个完全相同的数据点时,由于偏好优先关系不具有自反性,因而两个相同点之间不存在k*-支配关系,根据算法该点不重复加入结果集。 使用改进算法对表2中的数据集D求3*-支配skyline数据点集合。首先对D集合进行预排序,结果如表3所示。设属性顺序S=(d1,d2,d3,d4,d5,d6)。 具体步骤如下: ①C=Ø; ② 读p1取,C集合中没有元素,直接将p1加入C集合中; ③ 读取p4,C集合中有一个元素p1,p4能3*-支 表3 预排序后的数据集 {p4}; ④ 读取p2,依次扫描C集合中的元素,p2不能3*-支配p4,因而将p2加入C集合,C={p4,p2}; ⑤ 读取p6,依次扫描C集合中的元素,p6不能3*-支配p4,能3*-支配p2,因而将p2移除C集合,将p6加入C集合,C={p4,p6}; ⑥ 读取p3,p3能3*-支配C集合中全部的元素,因而p4、p6全部被移出C集合,再将p3加入C中,C={p3}; ⑦ 读取p5,p5能3*-支配p3,将p3移出C集合,将p3加入C集合,C={p5}; ⑧ 此时D′中已经没有数据,算法结束,3*-支配Skyline的结果为{p5},与前述算法求得的结果相同。 为验证算法的正确性和有效性,并研究其效率与各可变因素之间的关系,本文在Windows平台上实现了上述算法。计算环境所用计算机的配置为8 GB内存、3.2 GHz主频、i5-3470处理器。实验使用正相关分布数据、独立分布数据、反相关分布数据分别对算法进行了验证,并通过改变相关的参数来进行算法的评估。设k表示k*-支配skyline中的k值,size表示数据集大小,d代表数据集D的维度。 (1) 参数k变化。随着参数k的变化,算法在正相关分布、独立分布和反相关分布数据中的性能如图2所示,其中size为默认值300k,d为默认值15,k从9变化到14。 (2) 数据集size变化。随着数据集大小的变化,算法在正相关分布、独立分布和反相关分布数据中的性能如图3所示,其中k为默认值11,d为默认值15。 (3) 维度d和参数k变化。图4所示的是参数k和维度d变化时,算法的执行效率。 (a) 正相关分布 图2 参数k变化时算法运行时间 (a) 正相关分布 图3 数据集size变化时算法运行时间 由图2可见,当size和d确定时,k对运行时间有显著影响。同时可以看出,相对于正相关分布的数据集而言,k对独立分布和反相关分布的数据集上运行时间的影响更显著。由图3可见,当d和k确定时,size对运行时间的影响,在3种不同分布的数据集上大时,算法的运行效率会迅速下降。当k与d相同时,k*-支配Skyline查询会退化成普通的Skyline查询。综上可以看出,k*-支配查询中,k对算法效率的影响是最显著的。对于维度较多的数据集而言,选取一个合适的且较小的k,既可以得到相对有效性更高的小结果集,同时也可以使查询的时间大大缩短。而且,k*-支配关系不会成环,查询结果一定不为空集。 (a) 正相关分布 (b) 独立分布 (c) 反相关分布 图4 维度d和参数k变化时算法运行时间 在实验数据检索中,使用传统Skyline查询,由于数据点之间较难产生支配关系,因而返回的数据点较多。在Skyline查询的基础上改进形成的k-支配Skyline查询,有可能会产生循环支配。本文提出了一种新的k*-支配Skyline查询,在满足k-支配的条件下还需满足偏好优先关系,使得数据点之间不存在循环支配。将k*-支配Skyline查询用于实验数据的信息检索,能有效的返回用户的偏好数据,本文通过实验证明了算法的可行性。 参考文献(References): [1] Borzsonyi S, Kossmann D, Stocker K. The Skyline operator[C]∥ICDE. Heidelberg:IEEE, 2001:421-430. [2] Kossmann D, Ramsak F, Rost S. Shooting stars in the sky: An online algorithm for Skyline queries[C]∥Proceedings of the 28th International Conference on Very Large Data Bases. Hong Kong:Springer, 2002:275-286. [3] Tan K L, Eng P K, Ooi B C. Efficient progressive Skyline computation[C]∥Proceedings of the 27th International Conference on Very Large Data Bases. Roma:Springer, 2001:301-310. [4] Papadias D, Tao Y, Fu G,etal. An optimal and progressive algorithm for Skyline queries[C]∥Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data. San Diego: ACM Press, 2003: 467-478. [5] Papadias D, Tao Y, Fu G,etal. Progressive Skyline computation in database systems[J]. ACM Transactions on Database Systems, 2005, 30(1): 41-82. [6] Lee J, Hwang S. Toward efficient multidimensional subspace Skyline computation[J].The VLDB Journal, 2014, 23(1): 129-145. [7] Li Y, Li Z, Dong M,etal. Efficient subspace Skyline query based on user preference using map reduce[J]. Ad Hoc Networks, 2015, 35:105-115. [8] Zhao L, Yang Y, Zhou X. Continuous probabilistic subspace Skyline query processing using grid projections[J]. Journal of Computer Science Technology, 2014, 29(2):332-344. [9] Lian X, Chen L. Efficient processing of probabilistic group subspace Skyline queries in uncertain databases[J].Information System, 2013,38(3):265-285. [10] Chen L, Cong G, Jensen C S,etal. Spatial Keyword query processing: An experimental evaluation[J]. PVLDB, 2013, 6(3): 217-228. [11] Huang Z, Zhang J, Liu Z,etal.Skyline recommendation in distributed networks[J]. The International Arab Journal of Information Technology, 2017,14(3):372-379. [12] Park Y, Min J, Shim K, Efficient processing of Skyline queries using map reduce[J].IEEE Transactions on Knowledge and Data Engineering, 2017,29(5):1031-1044. [13] Song B, Liu A, Ding L. Efficient top-k Skyline computation in map reduce[C]∥Proceedings of the12thWeb Information System and Application Conference. Jinan: IEEE,2015:67-70. [14] Chan C Y, Jagadish H V, Tan K L. Finding k-dominant Skylines in high dimensional space[C]∥Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data. Chicago:ACM, 2006:503-514. [15] 黄荣跃,赵雷.一种使用简化预排序的k-支配Skyline查询算法[J].小型微型计算机系统,2013,34(5):1054-1059. [16] 印鉴,姚树宇,薛少锷,等.一种基于索引的高效k-支配Skyline算法[J].计算机学报,2010,33(7):1236-1245.3.2 k*-支配Skyline算法
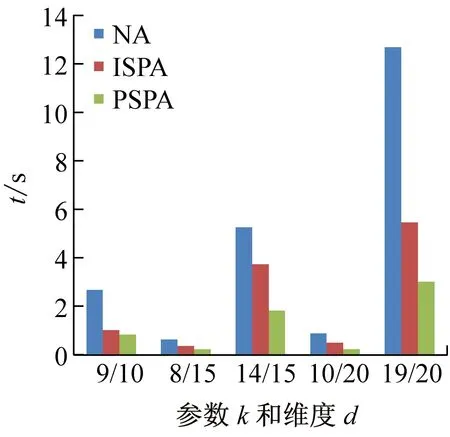
4 实验及结果分析


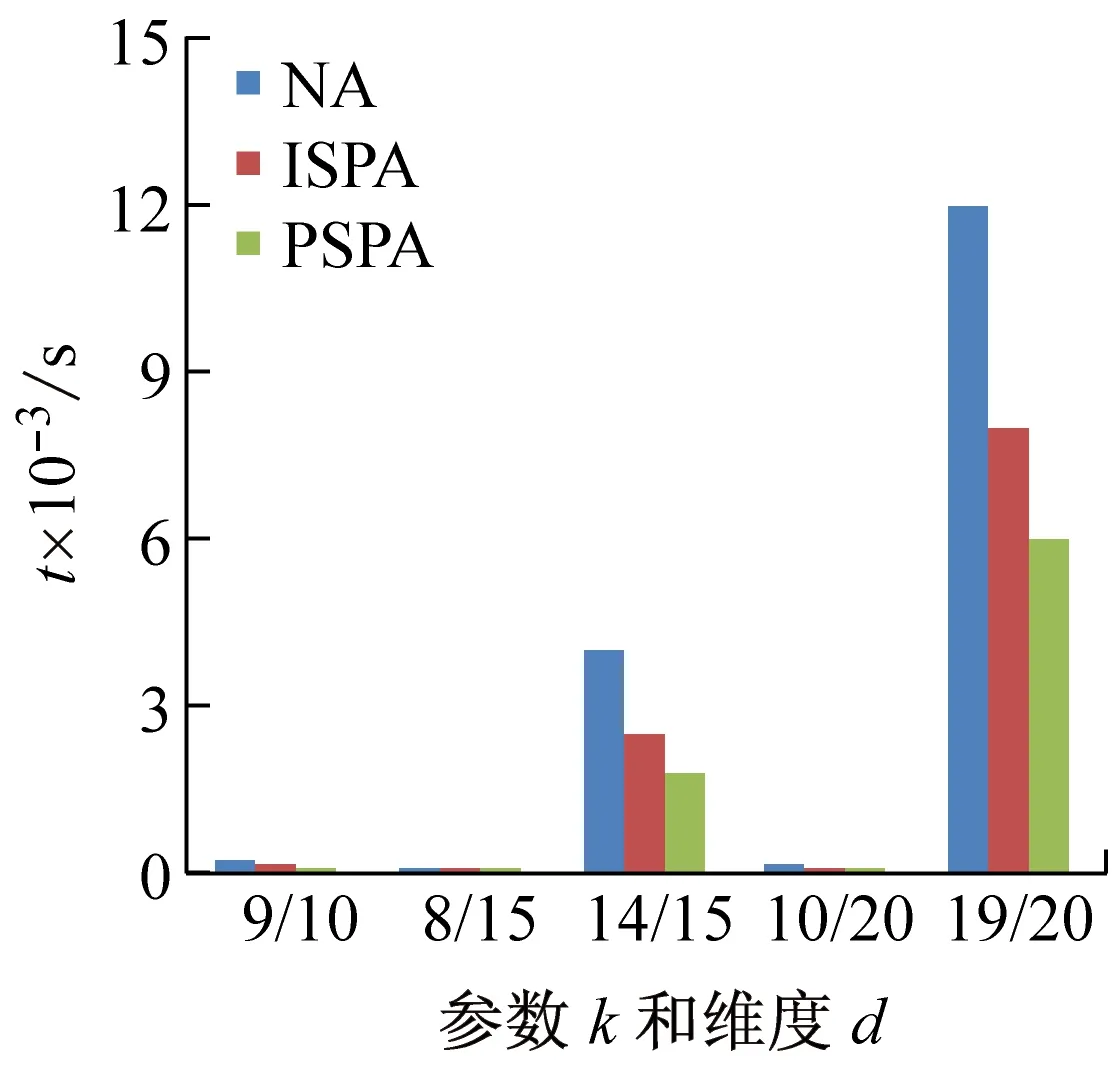
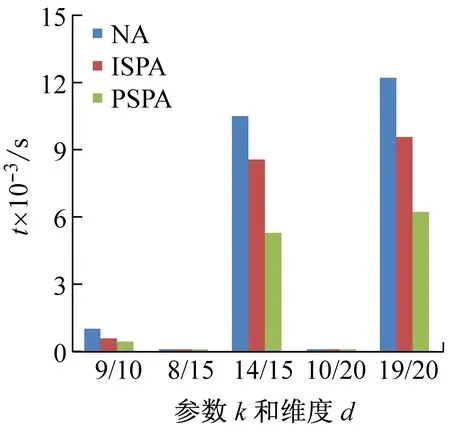
5 结 语
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
意林(2021年9期)2021-05-28
科普童话·学霸日记(2020年1期)2020-05-08
时代英语·高一(2019年1期)2019-03-13
小天使·一年级语数英综合(2019年2期)2019-01-10
商周刊(2018年25期)2019-01-08
传媒评论(2018年5期)2018-07-09
自动化学报(2017年2期)2017-04-04
中国卫生(2016年12期)2016-11-23
Coco薇(2016年8期)2016-10-09
