
基于YOLO网络的行人检测方法
2018-05-30 01:26李少波陈济楠李政杰
计算机工程 2018年5期
高 宗,李少波,b,陈济楠,李政杰
(贵州大学 a.现代制造技术教育部重点实验室; b.机械工程学院,贵阳 550025)
0 概述
行人检测是目标检测领域的重要分支。近年来在视频监控、汽车辅助驾驶和智能机器人等方面得到了广泛关注。行人检测技术经过几十年的研究发展,在检测精度和速度上都取得了很大的进展。主流的行人检测模型[1]主要有可变形部件模型 (Deformable Part Models,DPM)、深度网络 (Deep Network,DN)、决策树(Decision Forest,DF)。基于这3种结构的检测方法各有特点,均可在行人检测上得到相似的最优结果。目前对于这3种模型孰优孰劣尚无论断。
传统的行人检测方法基于人工设计的特征提取器,通过提取Haar特征、方向梯度直方图(Histogram of Oriented Gradient,HOG)、局部二值模式(Local Binary Pattern,LBP)等训练分类器,以达到行人检测的目的,在行人检测任务中取得了令人瞩目成果。例如文献[2]利用HOG+LBP特征处理行人遮挡,提高检测准确率。文献[3]和文献[4]分别提出积分通道特征(Integral Channel Features,ICF)和聚合通道特征(Aggregated Channel Features,ACF),融合梯度直方图、LUV色彩特征和梯度幅值特征,获得了性能更好的行人特征表达。但人工设计的行人特征很难适应行人的大幅度变化。深度网络模型可以从图像像素中学习特征,提高行人检测器性能。文献[5]提出的卷积神经网络检测方法,运用基于卷积稀疏编码的无监督方法预训练卷积网络,用训练好的模型进行行人检测。文献[6]通过探究不同的网络深度、卷积核大小以及特征维度对行人检测结果的影响,构建了基于卷积神经网络的行人分类器,但该检测器不具备目标定位的功能。文献[7-8]提出运用深度模型学习不同身体部位特征来解决行人遮挡问题,并根据不同部位间的相互约束完成行人检测。深度网络模型也在行人检测领域得到了深入运用,随着大规模训练数据集的构建以及硬件计算能力的不断增强,深度网络结构在不同的视觉任务中取得了巨大的成功。在目标检测方面,从RCNN[9]、SPP-Net[10]、Fast-RCNN[11]、Faster-RCNN[12]到YOLO[13],目标检测的准确率和速度都达到了新的高度。其中YOLO网络是目前最优秀的目标检测架构之一,在检测实时性方面表现尤为突出。
本文借鉴目标检测领域先进的研究成果,提出将YOLO网络结构用于行人检测,聚类选取初始候选框,重组特征图,扩展横向候选框数量,构建基于YOLO网络的行人检测器YOLO-P。
1 检测方法
基于YOLO网络的检测方法将候选框提取、特征提取、目标分类、目标定位统一于一个神经网络中。神经网络直接从图像中提取候选区域,通过整幅图像特征来预测行人位置和概率。将行人检测问题转化为回归问题,真正实现端到端(end to end)的检测。
行人检测就是对输入的图像或视频,进行候选框提取,判断其中是否包含行人,若有给出其位置。而事实上,大部分的候选框中并不包含行人,如若对每个候选框都直接预测行人概率,无疑增加了网络学习的难度。在YOLO-P的检测方法中,将检测分为3个过程,即候选框的提取、待测目标检测、行人检测与定位。在待测目标检测的过程中,将部分预测框的置信度置为0,以降低网络学习的难度。
1.1 候选框的提取
将输入的图像划分为M×N个单元格,每个单元格给定B个不同规格的初始候选框,如图1所示,预测候选框经由卷积层网络提取出来,每幅图像候选框数量为M×N×B。

图1 YOLO-P行人检测过程
1.2 待测目标检测
首先对候选框进行目标检测,预测每个候选框的中存在待判别目标的置信度Conf(Object),将不存在目标物的候选框置信度置为0。


1.3 行人检测与定位
对存在目标物的候选框进行行人判别,设预测目标物是行人的条件概率为Pr(Person|Object),则候选框中包含行人的置信度Conf:
对每个候选框预测其中包含行人的概率以及边界框的位置,则每个候选框输出的预测值为:
[X,Y,W,H,Conf(Object),Conf]
其中,X、Y为预测框中心相对于单元格边界的偏移,W、H为预测框宽高相对于整幅图像之比。对于输入的每幅图片,最终网络输出为向量:
M×N×B×[X,Y,W,H,Conf(Object),Conf]
2 网络架构
本文网络以YOLO网络为原型,其采用区域建议网络(Regions Proposal Network,RPN)的思想,去掉全连接层,采用卷积层来预测目标框的偏移和置信度。对特征图中的每个位置预测这些偏移和置信度,以得到行人目标的概率和位置。
2.1 多级特征图融合
行人特征在深度学习网络中展现出结构性,高层的特征抽象程度高,表达出行人的整体特征,中层的特征相对具体,表达出行人的局部特征。结合不同细粒度特征,可以增加行人检测的鲁棒性。为提高对小目标的检测,融合多级特征图,让不同细粒度的特征参与行人检测,构成YOLOv2[14]网络,结构如图2所示。
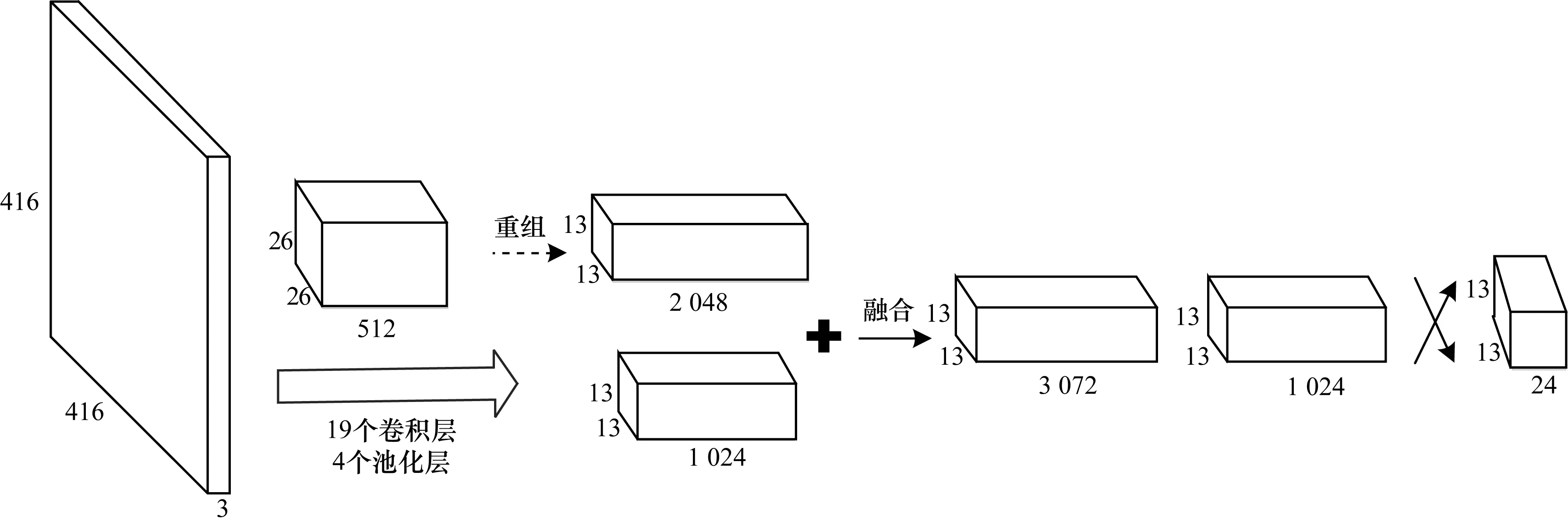
图2 YOLOv2网络结构
2.2 横向候选框扩展
在YOLO检测方法中,图像被分成S×S的网格。候选框在X和Y轴上同等密度分布,对人群进行检测时,漏检率较高。实际上,行人在图像中呈现X轴上分布更密集,Y轴上分布相对稀疏的特点,如图3所示。针对这一问题,本文提出在网络中增加一个reorg层,重组特征图,增加候选框在X轴方向的密度,同时减少Y轴方向候选框密度,构成YOLO-P网络(如图4所示)。

图3 行人在图像中分布情况
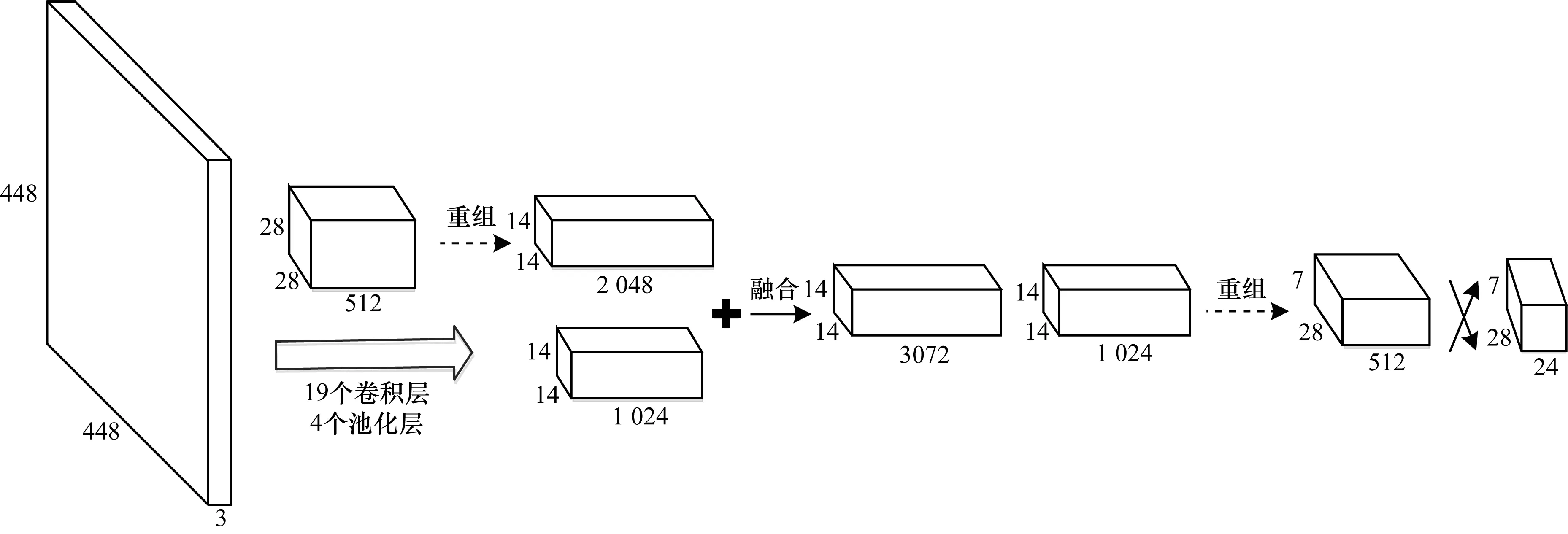
图4 YOLO-P网络结构
用于行人检测的YOLO-P网络模型,输入图像分辨率为448像素×448像素,若为每个网格选定4个初始候选框,则YOLO-P网络输出是大小为28×7×24的一组向量。
3 网络训练
以开源的神经网络框架Darknet为基础,以YOLO-P网络结构为模型,训练行人检测器。为加快训练速度和防止过拟合,选用的冲量常数0.9,权值衰减系数为0.000 5。学习率采用多分步策略。
3.1 预训练
为减少训练时间,以Darknet19网络模型训练得到的网络参数初始化卷积层网络。该预训练模型由图2中的前23层网络后接一个平均池化层和一个全连接层构成,在ImageNet1000数据集训练10个循环(epoch)后得到预训练参数。
3.2 训练集
基于卷积神经网络的行人检测方法需要从大量样本中学习行人特征,若样本集不具有代表性,很难选择出好的特征。本文以INRIA行人检测数据集作为训练和测试数据集。
INRIA行人检测数据集是目前使用最广泛的静态行人检测数据库之一,分为训练数据集和测试数据集。训练数据集包含正样本图像614张,行人数目为1 237个;测试数据集包含正样本图像288张,行人数目为589个。图像光照变化明显,目标尺度变化大、行人姿态丰富、外观服饰变化多、背景复杂且有不同程度的遮挡。
3.3 初始候选框
在训练网络时,需要预设候选框的初始规格及数量。随着迭代次数不断增加,网络学习到行人特征,预测框参数不断调整,最终接近真实框。为加快收敛速度,提高行人检测的位置精度,分析图像中行人的宽高特点,用K-means方法进行聚类,得到与图像中行人边界最相近的初始候选框参数。
一般K-means聚类采用欧式距离衡量两点之间的距离。本文对候选框宽高与单位网格长度之比进行聚类。预测框和真实框的交并比(Intersection-Over-Union,IOU)是反映预测框与真实框差异的重要指标,IOU值越大,表明两者差异越小,“距离”越近。聚类的目标函数为:
其中,i为聚类的类别数,j为样本集数量,Box[i]表示聚类得到的预测框i的规格,规格在数值上表示为一组数值:(预测框宽/图像宽,预测框高/图像框高),Truth[j]表示样本j中行人定位框规格。
4 实验结果及分析
本文实验环境为:Intel Xeon CPU E5-1620 V3 3.5 GHz,16 GB内存,Nvidia Geforce GTX1080,Ubuntu16.04,64位操作系统。在该实验环境下,YOLO-P检测器的检测速度达到25 frame/s,满足实时性要求。
4.1 聚类选取初始候选框的有效性验证
为验证聚类选取初始候选框的规格和数量对行人检测器的影响,选择INRIA的训练和测试数据作为实验数据,以YOLOv2网络训练行人检测器。
1)对INRIA的行人数据的真实框以3.3节中所述K-means方法聚类,聚类类别数量B分别设定为3、4、5、6,聚类值为行人真实框宽高分别与图像宽高之比。将聚类的结果(如表1所示)作为网络训练候选框的初始规格。

表1 INRIA数据集上行人真实框聚类结果
2)每组实验均选用YOLOv2网络作为训练行人检测器的网络,以排除其他因素的干扰。
3)每组实验均选用INRIA数据集进行训练和检测。检测结果如图5所示,以平均每张图片误检数(False Positive Per Image,FPPI)作为横坐标,漏检率(Miss-rate)作为纵坐标。

图5 不同聚类数量对检测器的影响
从图5可以看出,通过聚类选取初始候选框后,检测器的漏检得到了明显改善。其中,将B=4的聚类结果作为初始候选框,训练得到的检测器得到了最好的检测结果。但需要注意该聚类结果仅反映的是INRIA数据集上行人的宽高特点,对其他数据集可能并不适用。
4.2 横轴候选框扩展的有效性验证
为验证本文提出的增加横轴方向候选框数量可以提高检测器性能的有效性。以INRIA数据集作为实验数据,比较YOLOv2网络和YOLO-P网络所训练的检测器的效果。
从图6可以看出,在FPPI相同时,YOLO-P检测器的漏检率明显低于YOLOv2检测器。当FPPI为0.1时,YOLO-P检测器的漏检率为8.7%,较YOLOv2检测器降低了2.5%。

图6 YOLOv2与YOLO-P检测结果对比
4.3 结果对比
与当前具有代表性的行人检测方法[15-18]进行比较,验证YOLO-P检测方法的有效性。所有检测结果均在INRIA数据集上训练测试得到。检测器的优劣可以通过LAMR[19](Log-Average Miss Rate)指标评判。LAMR反映的是FPPI在[10-2,102]上的总体漏检情况。
从图7可以看出,YOLO-P检测方法在LAMR指标评价中取得了最好的结果。在FPPI小于0.1时,漏检率较其他检测方法显著降低。原因在于大多检测方法采用的是人工设计的特征提取器(如HOG、LBP特征提取),行人特征表达不够充分,在进行行人检测时,“虚警”更多;而YOLO-P检测方法由卷积网络自学习行人特征,对行人特征表达更优秀。
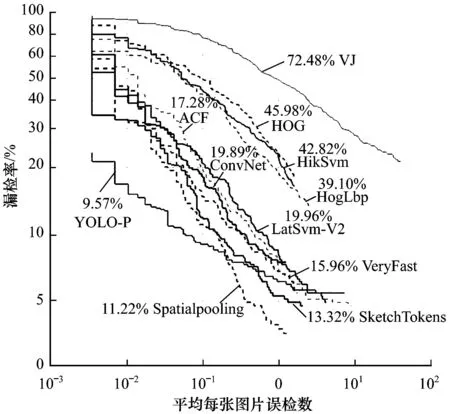
图7 各检测方法在INRIA数据集上测试结果对比
真实框与预测框的交并比(IOU)是反映行人检测定位准确性的重要指标,值越大,表明定位准确性越高。比较各检测方法预测结果的平均交并比(Average_IOU),如图8所示,YOLO-P检测器表现出了最好的定位准确性。

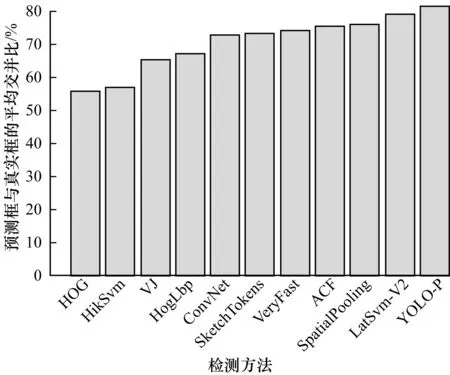
图8 各检测方法的平均交并比对比
5 结束语
本文提出将YOLO网络架构用于行人检测,分析行人在图像中的分布特点,改进网络后得到YOLO-P结构,以达到行人目标实时检测的目的。实验结果表明,该检测方法具有较好的检测准确率和定位准确性。但是,该检测方法在Caltech[20]行人数据集上的检测效果并不理想。主要原因是:检测方法仅将静态图片的信息作为检测依据,信息来源较为单一;将行人检测看作二值分类问题,对行人动态变化的检测具有较大局限性。近年来,很多学者努力提取更多信息辅助检测,如光流信息、环境信息等,提高特征表达能力,这是行人检测发展的重要方向,也是下一步的研究重点。
[1] BENENSON R,OMRAN M,HOSANG J,et al.Ten years of pedestrian detection,what have we learned?[J].Computer Vision,2014,8926:613-627.
[2] WANG Xiaoyu,HAN T X,YAN Shuicheng.An HOG-LBP human detector with partial occlusion handling[C]//Proceedings of IEEE International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2009:32-39.
[4] DOLLAR P,APPEL R,BELONGIE S,et al.Fast feature pyramids for object detection[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2014,36(8):1532-1545.
[5] SERMANET P,KAVUKCUOGLU K,CHINTALA S,et al.Pedestrian detection with unsupervised multi-stage feature learning[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.[S.1.]:IEEE Computer Society,2013:3626-3633.
[6] 芮 挺,费建超,周 遊,等.基于深度卷积神经网络的行人检测[J].计算机工程与应用,2016,52(13):162-166.
[7] WANG Xiaogang,OUYANG Wanli.A discriminative deep model for pedestrian detection with occlusion handling[C]//Proceedings of IEEE International Conference Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2012:3258-3265.
[8] WANG Xiaogang,OUYANG Wanli.Joint deep learning for pedestrian detection[C]//Proceedings of IEEE International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2013:2056-2063.
[9] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[EB/OL].[2013-11-11].https://arxiv.org/abs/1311.2524.
[10] HE Kaiming,ZHANG Xianyu,REN Shaoqing,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2014,37(9):1904-1916.
[11] GIRSHICK R.Fast R-CNN[C]//Proceedings of IEEE International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2015:1440-1448.
[12] REN Shaoqing,HE Kaiming,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2015:1-1.
[13] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:unified,real-time object detection[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Computer Society:2016:779-788.
[14] REDMON J,FARHADI A.YOLO9000:better,faster,stronger[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Computer Society,2017:6517-6525.
[15] DALAL N,TRIGGS B.Histograms of oriented gradients for human detection[C]//Proceedings of Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2005:886-893.
[16] FELZENSZWALB P,MCALLESTER D,RAMANAN D.A discriminatively trained,multiscale,deformable part model[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2008:1-8.
[17] CHEN Guang,DING Yuanyuan,XIAO Jing,et al.Detection evolution with multi-order contextual co-occurrence[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Computer Society,2013:1798-1805.
[18] ZHANG Shanshan,BENENSON R,OMRAN M,et al.How far are we from solving pedestrian detection[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Computer Society,2016:1259-1267.
[19] WOJEK C,DOLLAR P,SCHIELE B,et al.Pedestrian detection:an evaluation of the state of the art[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2012,34(4):743-761.
[20] DOLLAR P,WOJEK C,SCHIELE B,et al.Pedestrian detection:a benchmark[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2009:304-311.
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
意林(2021年5期)2021-04-18
计算机技术与发展(2020年2期)2020-04-15
扬子江(2019年1期)2019-03-08
火力与指挥控制(2018年10期)2018-11-13
火力与指挥控制(2018年3期)2018-04-19
小天使·一年级语数英综合(2017年6期)2017-06-07
中国交通信息化(2017年9期)2017-06-06
电子制作(2017年10期)2017-04-18
