
基于近义词分配的铁路扣件状态检测
2018-05-31 11:36李柏林
铁道标准设计 2018年6期
李 爽,李柏林
(西南交通大学机械工程学院,成都 610031)
轨道设施的正常工作是保障铁路运营安全的重要条件。传统的轨道检测依靠人工巡检,缺乏可靠性和实时性,难以满足铁路高速发展的形势下对轨道检测提出的新需求。近年来,在车载轨道巡检系统方面的研究取得了丰硕的成果[1-3],但铁路扣件的检测问题一直未能得到很好解决。扣件的失效很有可能引发列车脱轨等严重事故,已经引起了铁路部门的高度重视。计算机视觉技术的发展为实现铁路扣件的自动检测提供了良好的技术条件[4-6]。
“视觉词包模型”(Bag of Words, BOW)方法是目前应用最广泛的一种图像表示方法。该方法首先利用无监督聚类算法(如K-means算法)对图像的底层特征(如SIFT特征)进行聚类生成视觉词典,每个聚类中心代表一个视觉单词,然后将图像的各个底层特征向量映射至与其欧氏距离最近的视觉单词上,生成用来表示图像内容的图像-单词词频矩阵,最后,结合机器学习方法对图像进行分类。在“视觉词包模型”的基础上,文献[7]采用了一种柔性分配(Soft Assignment, SA)的方法来构建图像-单词词频矩阵,一个特征向量被分配至多个视觉单词上,每个视觉单词的权重大小与其和特征向量的欧氏距离有关。文献[8]则将柔性分配方法与潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)模型相结合,提出了一种柔性分配的LDA模型。以上基于“视觉词包模型”的方法都很好地利用了图像底层特征在特征空间中的位置关系,在将图像量化为图像-单词词频矩阵时,将底层特征映射到与其欧氏距离最近的聚类中心(视觉单词)。但是,它们在衡量视觉单词间的语义相关性时都只考虑了视觉单词在特征空间中的欧氏距离大小。由于度量空间的不同,使得特征空间中的欧氏距离与真实的语义距离之间存在一定偏差。此外,这类方法分配给每个底层特征的视觉单词数量都是固定的,使得某些具有明确语义的底层特征被强制分配到多个视觉单词上,引入了新的冗余信息。
综上所述,为了更加准确地衡量“视觉词包模型”中视觉单词间的语义相关性,且对不同语义类型的底层特征分配不同的单词数目,本文提出了一种基于近义词分配的扣件检测模型。首先,结合LDA模型和相对熵共同挖掘视觉单词间的语义相关性,然后,在语义空间和特征空间的共同约束下自适应地选择柔性分配的单词数目,生成扣件图像的词频矩阵表示,最后,利用SVM分类器实现扣件检测。实验结果表明,结合了近义词分配方法的“视觉词包模型”具有更高的分类性能。
1 基于近义词分配的扣件检测
在将底层特征向量映射为视觉单词时,结合LDA模型和条件熵分析视觉单词间的语义相关性,针对不同语义类型的底层特征自适应地选择单词的分配数目,并在此基础上提高扣件检测的精度。本文的模型框架如图1所示。其中,实线部分表示训练过程,虚线部分表示测试过程。

图1 本文扣件检测模型框架
1.1 视觉单词的语义相关性
传统“视觉词包模型”仅通过视觉单词间的欧氏距离来衡量视觉单词间的语义距离,不能准确地诠释视觉单词间的语义相关性。而通过LDA模型可以获得语义主题在某一视觉单词上的条件概率分布,从而更准确地表达单词蕴含的语义概念。下面首先介绍LDA模型,然后解释本算法如何利用该模型挖掘视觉单词间的语义相关性。
1.1.1 LDA模型
LDA模型[9]将一幅图像看作一篇文档,将文档描述为主题的分布,而主题通过视觉单词的分布来表述。LDA中一幅图像的生成步骤如下。
(1)选择θ~Dirichlet(α),其中θ是一个C×T的矩阵,行向量θi是第i幅图像的主题分布向量;
(2)对于每个图像块xi,从多项式分布θ抽样主题tk,tk~Multi(θ),以概率p(wm|tk,β)选择一个视觉单词wm,β是一个K×V的矩阵,其元素βi,j=p(wi=1|tj=1)表示视觉单词wi和主题tj同时出现的概率;
(3)重复步骤(1)、(2),反复进行图像主题的选择,通过主题产生对应的单词,直到生成一幅完整的图像。
LDA模型的学习过程是其生成模型的逆过程,采用吉布斯采样可求解出模型中参数的近似值,从而获得每幅图像的主题分布。式(1)给出各个视觉单词所属主题的全概率分布公式
(1)

1.1.2 基于相对熵的语义距离衡量
相对熵[10](relative entropy)能够用来衡量两个概率分布之间的相似程度。因此,在利用LDA模型得到主题z在单词w下条件概率分布后,本文引入相对熵来度量视觉单词wi和wj之间的语义距离,如式(2)所示
dis(wi,wj)=KL(p(z|wi)∥p(z|wj))=

(2)
然而,相对熵并不是一个对称量,即dis(wi,wj)≠dis(wj,wi)。为此,将式(2)进行改造,使其成为一个具有对称性的度量,如式(3)所示

(3)
利用式(1)~式(3)便可以计算两个视觉单词的语义距离,获取语义相关的近义词,并在此基础上结合柔性分配方法生成图像-单词词频矩阵,更有效地克服单词的同义性和歧义性对分类性能的不利影响。
1.2 近义词分配生成图像-单词词频矩阵
传统“视觉词包模型”的视觉单词分配方法对每个局部特征分配的单词数目都是相同的,并没有考虑不同底层特征间的差异性,这样的分配方法存在较大的量化误差。比如,当某一底层特征s与视觉单词w1的距离较近,且与其他视觉单词的距离均较远时,若将其强制分配到多个视觉单词上,则会引入新的冗余信息;同理,当s与多个视觉单词的距离都很近时,则可能需要为其分配比预设数量更多的视觉单词,才能充分表达其语义内容。鉴于此,本文在由LDA模型和相对熵分析得到单词的语义相关性后,针对不同语义类型的底层特征采用不同的单词分配策略,自适应地将其映射到一定数量的近义单词上。算法的具体流程如下所示。
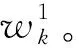

(3)分别计算si与m个单词间的欧氏距离,按从小到大的顺序对单词进行排序,即x={x1,x2,…,xj,…,xn},其中xj表示与si相距第j近的视觉单词。

直观上,改进后的单词分配方法既包含了特征向量与单词间的空间位置信息,即特征向量到视觉单词的欧氏距离,又考虑了各个单词间的语义相关性。比如,当某一视觉单词w1与特征向量s最邻近的视觉单词w2间的语义距离较小时,即使s在特征空间内与w1的欧氏距离较大,语义近似约束依然使其划分到w1;反之亦然。不难看出本文算法在一定程度上解决了单词的同义和歧义问题,减小了特征向量与单词映射时的量化误差。
2 实验与分析
2.1 实验设置与性能评价
实验样本采用本文创建的样本库。从采集的扣件图像中选取共800幅作为实验数据,其中正常、断裂、丢失以及被遮挡的4类扣件图像各200幅,均为120像素×180像素的灰度图像。训练集为每种状态的扣件图像各100幅,共400幅图像,余下的作为测试集。训练集与测试集的大小均为400。部分实验样本如图2所示。分类器采用台大林智仁教授的支持向量机库[11](Library for Support Vector Machine, LIBSVM),其核函数为径向基核函数,实验结果为10折交叉验证(cross-validation)的平均值。实验PC处理器为AMD Sempron X2 190 Processor 2.5 GHz,内存4.0GB,在Matlab2014b环境下进行实验。扣件分类性能评价指标为误检率和漏检率,其定义如下

(4)

(5)
其中,丢失、断裂、被遮挡的扣件均被视为失效扣件。检测结果首先要求准确判断出失效扣件,降低漏检;其次是降低误检,减少浪费。

图2 不同状态的实验样本
2.2 实验结果及分析
(1)实验1
为评估文中基于LDA模型的近义词柔性分配方法在扣件语义表达上的性能,将其与传统的柔性分配方法[12](SA)、传统“视觉词包模型”[13](BOW)相比较,分别选择SIFT[14](Scale Invariant Feature Transform)和HOG[15](Histogram of Oriented Gradient)作为底层特征进行扣件检测。实验参数设置均为优化值,不在文中赘述。检测结果如表1所示。
实验1、2、3表明,在HOG特征下,相比于传统“视觉词包模型”和传统的柔性分配方法,本文方法虽然由于模型复杂度提高,从而使检测耗时在一定程度上增加,但漏检率和误检率显著降低。一方面,改进了视觉单词的分配方式,既考虑了特征向量到视觉单词的欧氏距离,又考虑了视觉单词之间的语义相关性,在一定程度上克服了单词的同义和歧义问题;另一方面,考虑了不同底层特征间的差异性,针对不同语义类型的底层特征自适应地选择分配单词的数目,进一步降低了特征向量与单词映射时的量化误差。实验4、5、6表明,在SIFT特征下,本文方法同样能够降低“视觉词包模型”的漏检率和误检率。

表1 不同语义方法的扣件检测结果
(2)实验2
通过将本文方法与文献[16]中的主成分分析方法、文献[17]中的方向场(directional field,DF)方法以及文献[18]中的HOG+SVM方法这几种主要的扣件检测方法对比,以综合评估本文方法的扣件检测性能。文献[16-18]中各方法的参数设置均与原文献保持一致。各方法的检测结果如表2所示。

表2 与现有检测方法的比较
从表2可以看出,文献[16]的主成分分析方法和文献[18]的HOG+SVM方法虽然耗时比本文方法更短,但误检率和漏检率均过高。文献[17]的方向场方法虽对失效扣件检测效果较好,但误检率过高,且耗时较长。综合考虑可知,本文方法相比其他现有方法能更加有效地检测扣件状态。
3 结语
通过引入LDA模型和相对熵挖掘视觉单词之间的语义相关性,并根据不同语义类别的底层特征自适应地选择单词分配数目,从而完成底层特征与若干近义单词间的映射匹配。在4类扣件数据集上的实验结果证明了本文模型在一定程度上减小了底层特征与视觉单词之间的量化误差,进而提高了铁路扣件的检测精度。下一步的研究工作是如何更加有效地度量底层特征与视觉单词间的语义距离,使其更加接近真实的语义距离。
[1] Marino F, Distante A, Mazzeo P L, et al. A real-time visual inspection system for railway maintenance: Automatic hexagonal-headed bolts detection[J]. Systems Man & Cybernetics Part C Applications & Reviews IEEE Transactions on, 2007,37(3):418-428.
[2] Singh M, Singh S, Jaiswal J, et al. Autonomous rail track inspection using vision based system[C]∥IEEE International Conference on Computational Intelligence for Homeland Security and Personal Safety. IEEE Xplore, 2006:56-59.
[3] Yella S, Dougherty M, Gupta N K. Fuzzy logic approach for automating visual condition monitoring of railway sleepers[C]∥Indian International Conference on Artificial Intelligence, 2007:941-956.
[4] Xia Yiqi, Xie Fengying, Jiang Zhiguo. Broken railway fastener detection based on adaboost algorithm[C]∥International Conference on Optoelectronics and Image Processing. IEEE Xplore, 2010:313-316.
[5] Li Ying, Otto C, Haas N, et al. Component-based track inspection using machine-vision technology[C]∥International Conference on Multimedia Retrieval, ICMR 2011, Trento, Italy, April. DBLP, 2011:60.
[6] 吴禄慎,万超,陈华伟,等.一种改进的十字交叉轨道扣件定位方法[J].铁道标准设计,2016,60(12):49-53.
[7] Gemert J C V, Veenman C J, Smeulders A W M, et al. Visual Word Ambiguity[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2010,32(7):1271-1283.
[8] Weinshall D, Hanukaev D, Levi G. LDA topic model with soft assignment of descriptors to words[C]∥International Conference on Machine Learning, 2013:711-719.
[9] 狄仕磊,刘甲甲,罗建桥,等.基于潜在语义主题融合的铁路扣件状态检测[J].传感器与微系统,2016,35(7):19-21.
[10] 贺晓霞,鲍学英,王起才.基于组合方法计算权重的绿色铁路客站综合评估[J].铁道标准设计,2016(4):103-107.
[11] Chang Chih-chung, Lin Chih-jen. LIBSVM: A library for support vector machine[J]. ACM Transaction on Intelligent Systems and Technology, 2011,2(3):27.
[12] 赵永威,周苑,李弼程,等.基于近义词自适应软分配和卡方模型的图像目标分类方法[J].电子学报,2016,44(9):2181-2188.
[13] 於敏,于凤芹,陈莹.超像素词包模型与SVM分类的图像标注[J].传感器与微系统,2016,35(12):63-65.
[14] 朱力强,白彪,王耀东,等.基于特征分析的地铁隧道裂缝识别算法[J].铁道学报,2015,37(5):64-70.
[15] 韩烨,刘志刚,耿肖,等.基于HOG特征与二维Gabor小波变换的高铁接触网支撑装置耳片断裂故障检测[J].铁道学报,2017,39(2):52-57.
[16] 王凌,张冰,陈锡爱.基于计算机视觉的钢轨扣件螺母缺失检测系统[J].计算机工程与设计,2011,32(12):4147-4150.
[17] Yang Jinfeng, Tao Wei, Liu Manhua, et al. An efficient direction field-based method for the detection of fasteners on high-speed railways[J]. Sensors, 2011,11(8):7364-7381.
[18] Dou Yunguang, Huang Yaping, Li Qingyong, et al. A fast template matching-based algorithm for railway bolts detection[J]. International Journal of Machine Learning and Cybernetics, 2014,5(6):835-844.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军民两用技术与产品(2022年2期)2022-06-01
铁道建筑(2022年4期)2022-05-10
铁道勘察(2022年2期)2022-04-19
铁道学报(2021年8期)2021-09-09
铁道建筑技术(2020年11期)2020-05-22
开放教育研究(2020年2期)2020-03-31
中国修辞(2017年0期)2017-01-31
长江学术(2016年4期)2016-03-11
小说林(2014年5期)2014-02-28
