
基于多尺度相似度特征的答案选择算法
2018-06-07 08:30陈柯锦侯俊安
系统工程与电子技术 2018年6期
陈柯锦, 侯俊安, 郭 智, 梁 霄
(1. 中国科学院电子学研究所, 北京 100190; 2. 中国科学院大学, 北京 100049;3. 中国科学院空间信息处理与应用系统技术重点实验室, 北京 100190;4. 中国人民解放军92269部队, 北京 100141)
0 引 言
随着互联网的发展,迎来了大数据时代,互联网已经成为人们获取信息和知识的重要途径。数据的丰富给用户带来便利的同时,也使得用户获取到真实需要信息的难度增加,亟需一种快速、准确的信息获取方法。传统的搜索引擎基于关键字匹配,采取排序算法向用户呈现相关信息,这种方法带来了大量冗余的信息,需要用户花费大量时间从中筛选答案。智能问答系统理解用户自然语言方式的提问,直接返回用户所需答案,能够更好地满足用户的需求。
近年来,随着神经网络的发展,基于深度学习的问答系统成为当前自然语言处理及相关领域的研究热点之一。基于相关技术,许多有影响力的问答系统相继诞生,比如苹果的Siri,百度的小度,微软的小冰以及IBM的Watson等等。根据问答系统依赖的数据组织形式不同,问答系统分为基于Web检索的问答系统、基于社区的问答系统以及基于知识图谱的问答系统。3种问答系统都会通过分析问题,对答案粗筛选,得到一些候选答案,而如何对候选答案排序,从中获取正确答案,这就需要答案选择技术。答案选择是问答系统中的关键技术,该任务定义为针对一个给定的问题,在众多的候选答案中选出最佳候选答案。从定义可以看出,答案选择可以归结为排序问题,目标是计算问题与候选答案的相似度,通过相似度对候选答案排序。本文重点研究检索式问答和社区问答中的答案选择任务,该类答案选择任务的候选答案通常以短文本形式给出,其示例如图1所示。

图1 答案选择示例
Fig.1 Example of question answer selection
答案选择是自然语言处理中典型的语义相似度计算任务,目前存在两大难点。第一,问题和答案的长度不对称,通常情况下,答案中冗余信息较多。答案选择中的问题长度通常较短,一般在5~15个单词,而候选答案长度往往大于问题长度,主要在20~50个字符。其主要原因在于答案通常会对问题的相关背景进行详细描述。正如图1所示,对于问题“陶渊明出生在什么朝代?”,正确答案不仅给出了陶渊明的出生朝代,还给出了陶渊明的相关介绍。传统的模型通常学习问题和答案句子级的特征向量,通过计算向量的相似度对候选答案排序。该类方法学习到的联合特征包含了大量的冗余特征,通常情况下,冗余特征的相似度较低,鉴于此,考虑问题和答案的局部相似度对消除冗余特征尤为重要。第二,候选答案之间的语义相似度较高。如图1所示,错误答案同样属于在陶渊明背景下的描述,其与正确答案的语义关联性较强,因此,基于关键字匹配或者基于词袋模型分类的方法很难解决此类问题。
本文为了解决以上难点,基于深度学习的方法,提出一种基于多尺度相似度的深度学习模型。本文将在第2部分介绍答案选择的相关工作;第3部分将详细介绍模型的具体设计;第4部分介绍答案选择的评价方法和实验结果;第5部分对全文进行总结。
1 相关工作
答案选择受到了学术界和工业界的广泛关注,相关研究工作主要分为两类:一类是基于特征工程,通常借助于语言工具或者其他外部资源对特征进行抽取;另一类是基于深度学习模型,使用深度学习模型生成问题和答案的分布式表示,从而计算其相似度。
1.1 基于特征工程的答案选择方法
由于最初的词袋模型无法理解深层的语义特征,因此第一类工作相继而出。第1类工作主要基于特征工程挖掘问题和答案的语法和语义特征,例如,文献[1]利用问题和答案的依存句法树(dependency parse trees,DPT)对问题和答案进行特征提取。类似的,文献[2]提出一种判别模型来计算问题和答案的句法树的编辑距离,基于编辑距离特征训练分类器,最后完成问答对的分类。文献[3]首次将WordNet引入答案选择任务中,通过挖掘语义关系完成问题和答案中词的对齐,然后使用浅层语义分析得到同义词的语义相似度,从而提升答案选择的准确率。
1.2 基于深度学习的答案选择方法
基于特征工程的答案选择方法虽然取得了较好的效果,但由于其无法挖掘问题和答案的深层次的非线性特征,再者,模型的泛化能力较差。因此,近年来,基于深度学习的答案选择方法成为学术界研究的主流方法。文献[4]首次将卷积神经网络(convolutional neural network,CNN)[5]应用到答案选择任务,模型主要通过卷积网络学习问题和答案的二元语法特征,将问题和答案的特征通过相似矩阵聚合得到相似度。文献[6]的基本思想与文献[4]相同,模型主要由全连接网络和卷积网络构成,并对全连接网络和卷积网络的连接顺序以及问答相应网络权重是否共享进行实验与分析。随着长短期记忆单元(long short-term memory,LSTM)[7]和注意力机制[8]在自然语言处理诸多任务上广泛应用,相关工作也相继涌现。文献[9]采用双向长短期记忆单元(bidirectional LSTM,BiLSTM)提取问题和答案的语义特征,并通过答案学习问题的注意力权重,显著提升了答案选择的准确率。在此之后,文献[10]提出一种CNN和LSTM的混合网络模型,并对CNN和LSTM的连接顺序以及是否引入注意力机制进行了对比实验。文献[11]为了解决以往答案选择中池化方法丢失较多信息的不足,提出一种注意力池化的方法,取得了较好的效果。
第2类方法目前的工作通常直接提取问题和答案的整句特征来计算相似度,本文则从挖掘问答各个尺度下特征的相似度出发,对生成的相似度矩阵进行学习,从局部相似度得到最终的联合相似度。
2 本文方法
2.1 方法概述
本文方法通过CNN或BiLSTM提取问题和答案各个尺度下特征,与以往直接计算问答句子级特征相似度不同,本文采用一种相似度计算方法计算问答相应尺度下特征相似度,进而得到相似度矩阵,最后通过3种不同模型对相似度矩阵学习,从局部特征相似度得到问答整体相似度。
本文模型整体框架如图2所示。
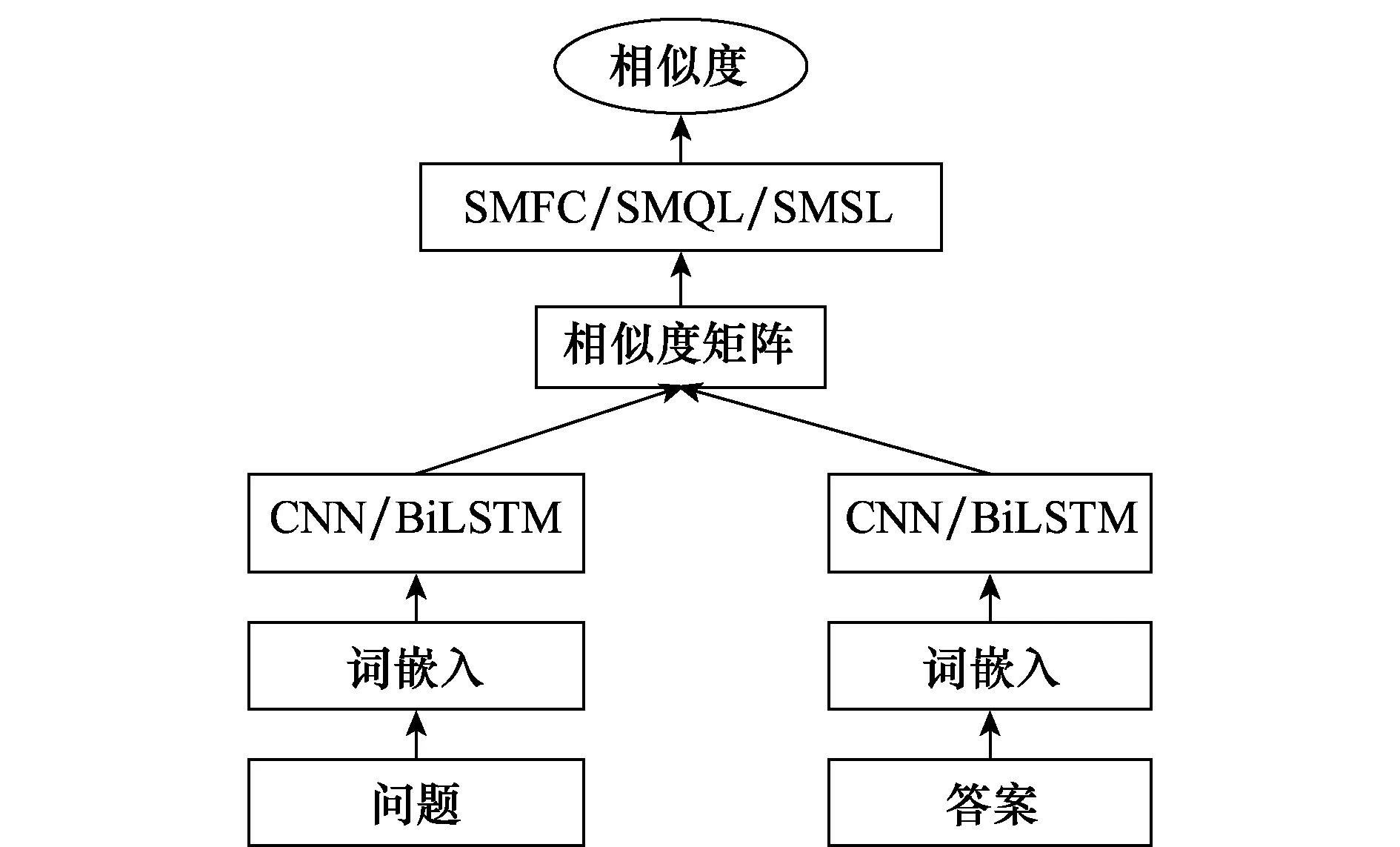
图2 模型整体框架图Fig.2 Framework of our model
2.2 卷积神经网络
传统的神经网络采用全连接的方式导致网络的训练参数过多,为了解决该问题,卷积网络采取局部连接和参数共享方式,极大减少了网络训练参数,此外,卷积神经网络更擅长于提取局部特征。
本文采用卷积网络作为特征提取的底层模型,对问题和答案的词嵌入矩阵分别采取一维卷积神经网络对特征提取,卷积核的长度等于词嵌入维度,特征提取示意图如图3所示。
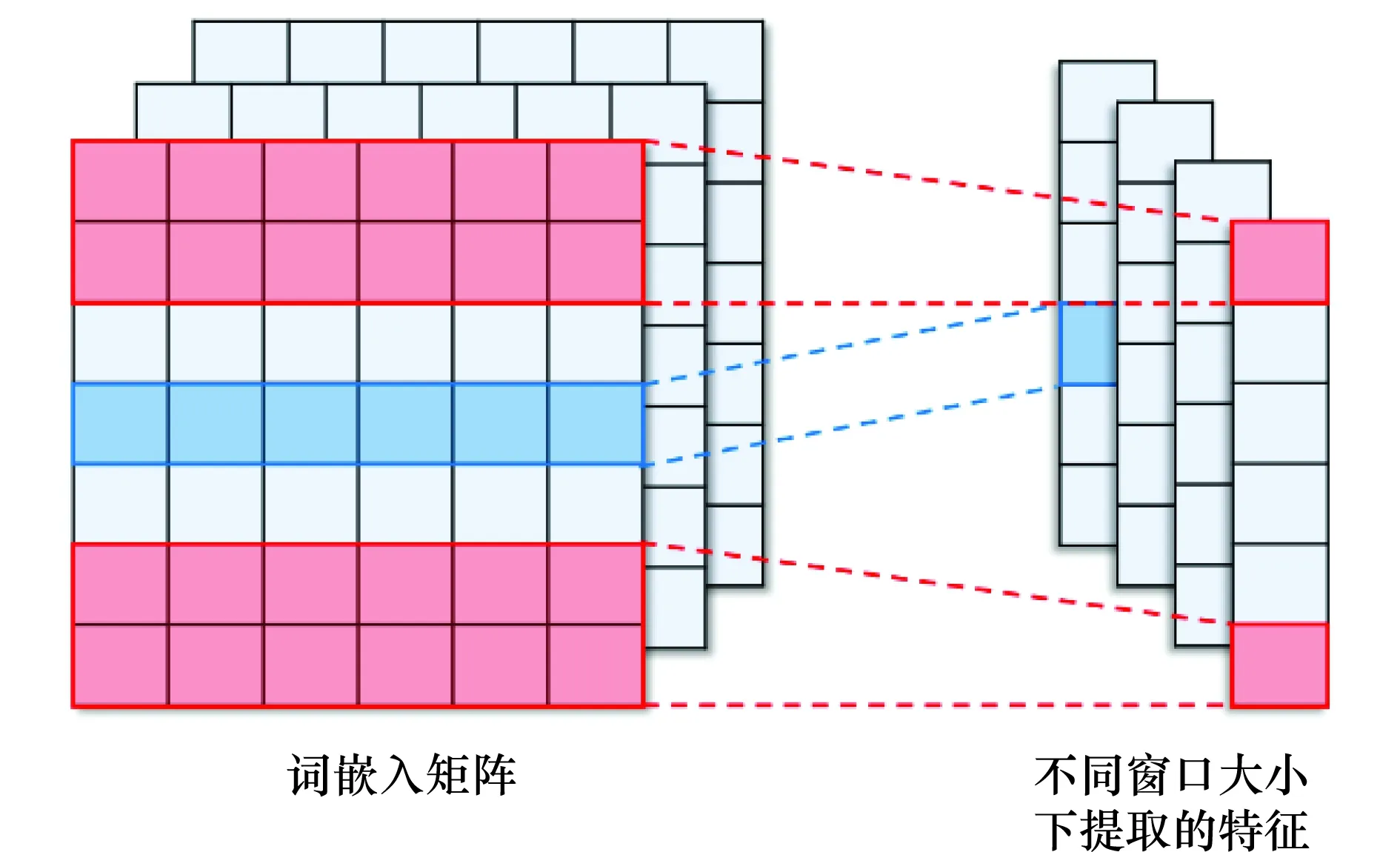
图3 不同窗口大小下卷积神经网络特征提取示意图Fig.3 Illustration of extracted features by the CNN model in different filter length
图3中左侧是对问题或答案进行词嵌入初始化后的矩阵Xn×k,其中n表示句子中单词的个数,k表示词嵌入维度。当使用卷积核Wh×k对矩阵Xn×k进行卷积操作可以得到n-h+1个特征,其具体表达式为
ci=f(Wh×k*Xi∶i+k-1+b)
(1)
式中,Wh×k表示卷积网络卷积核;h表示窗口大小;k为词嵌入维度;Xi∶i+k-1为语句中第i到i+k-1单词的词向量构成的矩阵;b为网络偏置向量;f为激活函数,本次实验中采用tanh;ci为最终提取到的特征。通过对整个特征矩阵进行卷积操作后,得到特征向量f={c1,c2,…,cn-h+1}。类似的,通过设定卷积网络的窗口大小和滤波器个数,可以得到问题和答案不同尺度下的特征向量,即
(2)
式中,j表示卷积网络窗口大小;m表示第m组滤波器。由于卷积网络窗口大小不同,所以特征的尺度也不同。本文实验中将问题各尺度特征聚合得到如式(3)所示问题特征矩阵,同理,可以得到答案特征矩阵。以往的方法通过池化对特征降维得到联合特征,最后直接计算问答联合特征的相似度,本文实验则是将问题和答案相应尺度下的特征聚合成相似度矩阵,通过对相似度矩阵学习得到最终的相似度,即
(3)
2.3 双向长短期记忆单元
对于自然语言的理解,需要关注上下文信息,循环神经网络(recurrent neural network,RNN)[12]当前时刻的输出跟其前面时刻的输出有着紧密联系,其具备一定记忆能力,能有效解决序列化问题。而LSTM则是为了解决RNN中的梯度消失的问题,由文献[13]提出改进模型。LSTM结构图如图4所示。
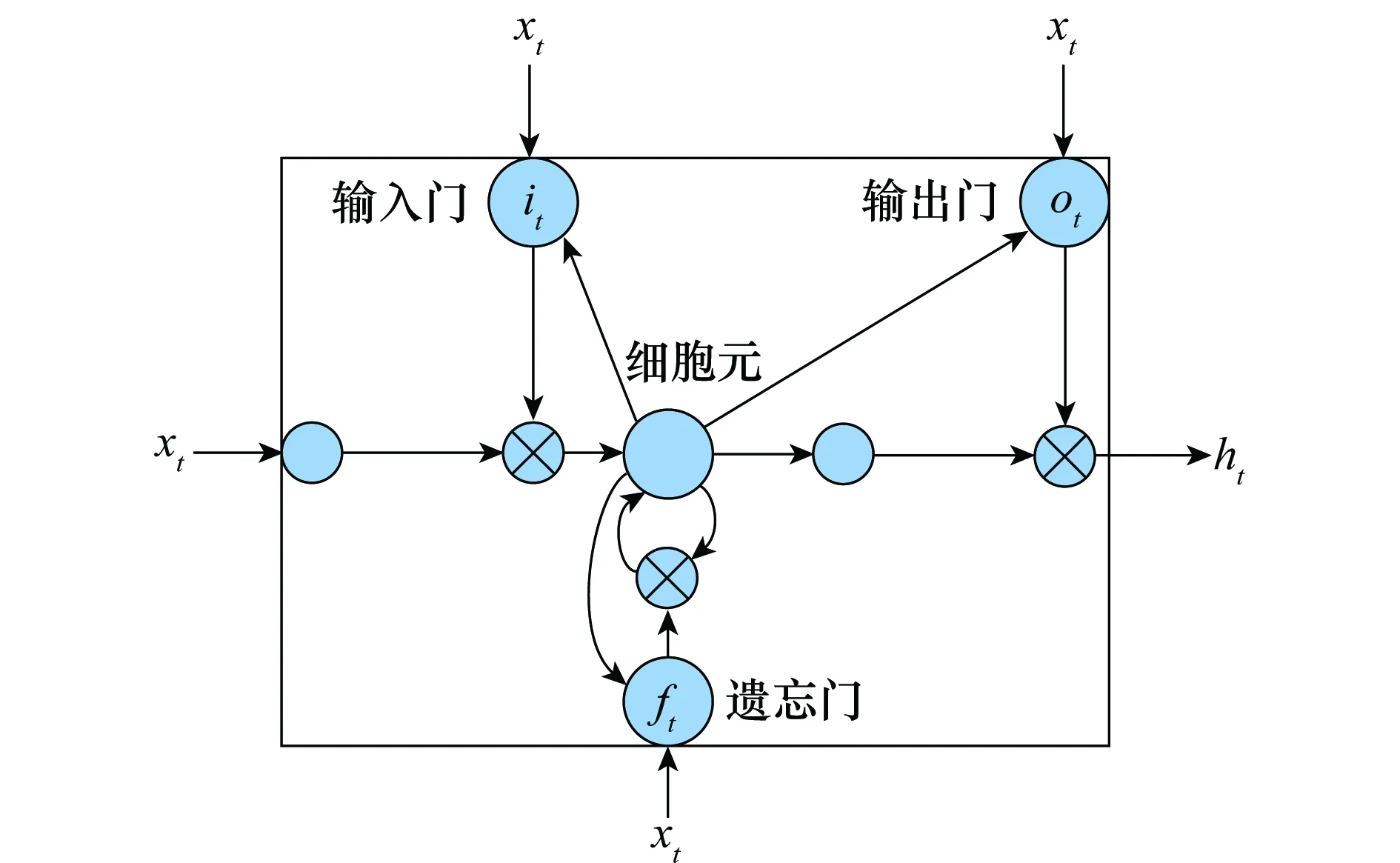
图4 LSTM结构图Fig.4 LSTM architecture
本文采用的LSTM为Graves 等[14]使用的改进模型,对于输入t时刻序列xt={x1,x2,…,xn},其在本文模型中表示为第t个单词的词嵌入向量,隐状态向量ht在t时刻的更新公式为
it=σ(Wixt+Uist-1+bi)
(4)
ft=σ(Wfxt+Ufst-1+bf)
(5)
ot=σ(Woxt+Uost-1+bo)
(6)
(7)
ht=ot*tanh(Ct)
(8)

LSTM当前时刻的输出能有效利用前面时刻的信息,为了充分利用文本上下文信息,采取双向LSTM,即对输入从正反两个方向使用LSTM学习,最后将其聚合得
(9)
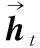
QBiLSTM=[h1,h2,…,ht]
(10)
2.4 相似度矩阵学习模型
本文提出3种相似度矩阵学习模型,分别为相似度矩阵特征聚合(similarity matrix feature concatenating,SMFC)模型,相似度矩阵特征分开学习(similarity matrix separate learning,SMSL)模型,相似度矩阵问题特征学习(similarity matrix question learning,SMQL)模型,3种模型对相似度矩阵学习得到联合相似度,相似度矩阵的计算方法如式(11)~式(14)所示,其物理意义为问题和答案各尺度特征的余弦相似度矩阵,相似度矩阵的行向代表问题特征,列向代表答案特征,矩阵元素大小代表该行问题特征和该列答案特征的余弦相似度大小。
Qsum=row_sum(Q⊙Q)
(11)
Asum=col_sum(A⊙A)
(12)
Pqa=element_max(QsumAsum,ε)
(13)
SIMQA=element_div(QAT,Pqa)
(14)
式中,Q代表问题特征矩阵;A为答案特征矩阵,当特征提取层为CNN时,特征矩阵如式(3)所示;当特征提取层为BiLSTM时,特征矩阵如式(10)所示。ε为精度矩阵,防止式(14)中出现运算异常情况,col_sum表示对矩阵列向求和得到行向量,row_sum表示对矩阵行向求和得到列向量,element_max为矩阵与矩阵之间对应元素取最大值运算,element_div为矩阵与矩阵之间对应元素相除,SIMQA为相似度矩阵,其中Pqa、SIMQA和QAT的维度为n×n,n为式(3)或式(10)中特征矩阵的特征向量总数。
2.4.1 相似度矩阵特征聚合模型
该模型的基本结构是对相似度矩阵分别进行列向最大池化和行向最大池化,然后聚合得到联合特征,最后将其送入全连接层学习得到相似度。本文采取3种方法对特征聚合,其分别为向量对应相加(sum)、向量对应相乘(mul)和向量拼接(concat),其方法如式(15)~式(19)所示,SMFC模型如图5所示。
x1={a0,a1,…,an}
(15)
x2={b0,b1,…,bn}
(16)
sum(x1,x2)={a0+b0,a1+b1,…,an+bn}
(17)
mul(x1,x2)={a0×b0,a1×b1,…,an×bn}
(18)
concat(x1,x2)={a0,a1,…,an,b0,…,bn}
(19)
对相似度矩阵做行向最大池化,可以得到问题特征在答案中的最大相似度。同理,列向量最大池化可以得到答案中特征在问题中的最大相似度。相似度的大小直接反映了该局部特征的匹配程度,通过对局部特征的最大相似度学习可以有效抑制冗余特征,得到更为准确的联合相似度,这是一种从局部相似度解决全局相似度的学习模型。
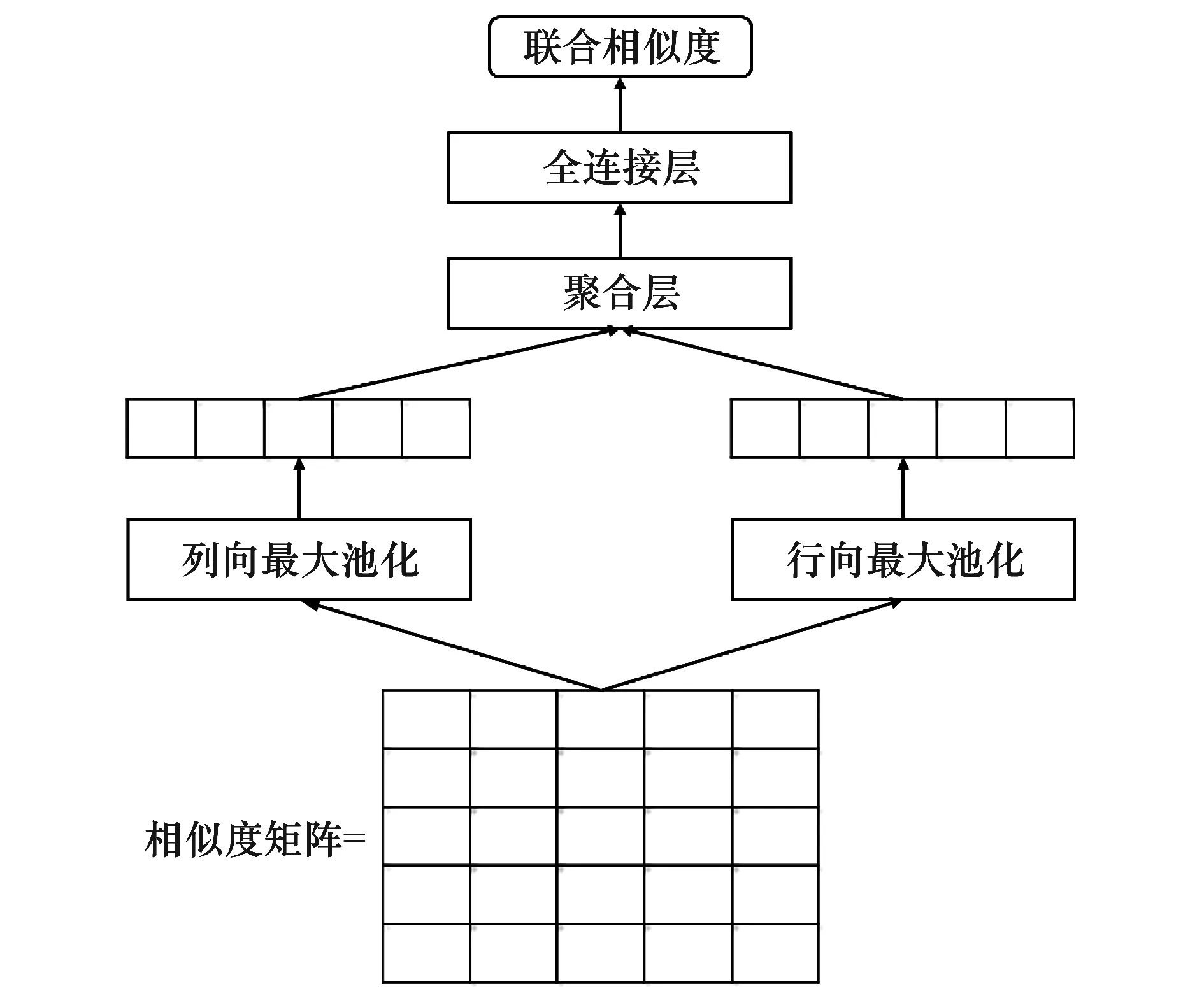
图5 相似度矩阵特征聚合模型Fig.5 SMFC model
2.4.2 相似度矩阵特征分开学习模型
SMFC中采用最大池化方法得到局部特征的最大相似度,该方法忽略了局部特征出现的频次。如图6所示,“F-35”在答案中出现次数为两次,而“战斗机”出现次数为一次,通常频次较高的特征对问答相似度计算的重要程度更高。基于上述问题,本模型使用卷积网络代替最大池化,对相似特征矩阵和转置后的相似特征矩阵分别进行卷积神经网络学习,得到问题和答案的相似度分布特征,然后放入全连接网络得到最终特征,最后通过GESD计算特征相似度,GESD为文献[6]提出的相似度计算方法,如式(20)所示,SMSL模型结构如图7所示。
(20)
式中,x和y分别表示SMSL模型中两个全连接层输出的特征向量,其分别代表问题和答案的相似度分布特征;γ和c分别为公式超参,实验中γ和c都设置为1。

图6 采用不同颜色表示问答局部相似特征
Fig.6 Different colors indicate the local similarity degree between the question and answers
2.4.3 相似度矩阵问题特征学习模型
答案选择中,对于判断答案是否是该问题的正确匹配,人们通常会关注问题的特征在答案中是否有相似特征,而对于答案中的冗余信息并不关注。例如,在图6的问题中“F-35”“战斗机”和“多少”此类局部特征的相似度的大小对整体相似度的影响远远大于答案中“美国”“洛希德·马丁”等特征,所以只对相似度矩阵的问题相似度学习,可以减少冗余,消除噪声,与此同时,简化了模型,降低了模型复杂度。
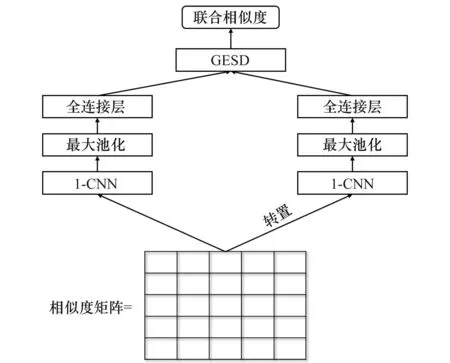
图7 相似度矩阵特征分开学习模型Fig.7 SMSL model
本文采用3种方式对问题相似度学习,分别为最大池化、平均池化和CNN模型,最后将其接入全连接层学习,其模型结构如图8所示。
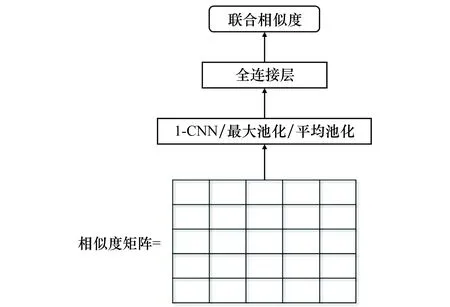
图8 相似度矩阵问题特征学习模型Fig.8 SMQL model
2.5 模型训练方法与损失函数
本文采取噪声对比估计方法对模型进行训练,其方法描述如下:对给定问题Q,在训练中选取正确答案A+和错误答案A-,应用本文模型分别计算(Q,A+)和(Q,A-)的相似度得到S+和S-,本文模型的训练的目标是使得正确问答对的相似值大于错误问答对的相似值,因此本文将问答相似度的距离与间隔M比较,得到如式(24)所示的损失函数,当S+-S->M时,不更新网络参数,反之采用随机梯度下降法更新。
S+=sim(Q,A+)
(21)
S-=sim(Q,A-)
(22)
(23)
Loss=max(0,M-S++S-)
(24)
对于间隔M,与以往采取固定间隔的方法不同,本文采取如式(23)所示的方法,其中α、β为模型超参。该方法使得间隔M与相似度的距离有关,当S+-S->β时,间隔M随着S+-S-的增大而快速减小,与此同时,训练误差也相应减小,而当S+-S-≤β时,M值最大,模型得到较大的训练误差。
3 实验结果与分析
3.1 实验数据
本次实验采用百度的公开数据集WebQA[15]。WebQA是一个大规模的中文人工标注问答数据集,其来源主要为百度知道。所有问题的候选答案由搜索引擎对问题检索的前3页结果清洗得到,最后通过人工将候选答案标注为正确答案和错误答案。本次实验对WebQA数据集进一步清洗,主要清洗工作为纠正错误标注,最终形成如表1所示规模的训练数据集。

表1 WebQA数据集
其中验证集是训练数据集随机抽取10% 获得,测试集为WebQA数据集的Test_lr清洗得到,Test_lr为WebQA人工标注测试集,其候选答案包含正确答案和同等语义背景下的错误答案。图1为WebQA数据集示例。
3.2 实验评价指标
本文实验评价指标采用信息检索中的平均准确率均值(mean average precision,MAP)和平均倒数排名(mean reciprocal rank,MRR),在本文实验中,MAP代表问答对相似度排序中准确率的均值,其计算方法如式(25)所示。MRR代表的是问答对相似度排序中的第一个正确答案的位置得分平均值,即关注系统返回正确答案的位置,位置越靠前评分越高,位置的倒数为单个评分值,最后统计求和,其计算方法为
(25)
(26)
式中,n为问题总数;qi为第i个问题;prec(qi)为第i个问题的候选答案相似度排序的准确率,正确答案排在第一位则得分为1,否则为0。rank(qi)为第i个问题的候选答案排序结果中正确答案的排名。
3.3 实验设计
本文在整理后的WebQA数据集上,应用文献[6]提出的CNN模型和文献[9]提出的BiLSTM方法作为实验的基线模型,并在此基础上分别添加SMFC,SMSL和SMQL方法作对比验证实验。对于SMFC方法,本文采用向量求和,向量拼接和向量相乘3种聚合方法,而对于SMQL的方法采取CNN、最大池化和平均池化3种方法对相似度矩阵进行特征提取。
3.4 实验结果
本次实验的实验环境为GeForce GTX 1080、Intel Core i7-6700k 4.0GHZ、内存16G的PC。本文模型词向量采用WebQA中已训练好的词向量初始化,该词向量是通过五元语法的神经语言模型[16]训练得到,词向量维度为64维。本次实验网络学习采用随机梯度下降法(stochastic gradient descent,SGD),其初始学习率设置为lr=0.1,网络训练的批大小设置为100,问题截取长度设置为50,答案截取长度设置为50。网络迭代次数设置为200,采取早停止(early-stop)[17]策略。最后相似度计算公式采用GESD,文献[6]在之前实验已经证明,采用GESD作为相似度计算公式的实验结果优于其他相似度计算公式。
本实验将CNN作为底层特征提取的实验结果如表2所示,其中CNN使用的是一维的卷积网络,其窗口大小设置为1、2、3和5,滤波器个数设置为500,激活函数使用tanh。对于SMQL中相似度特征学习的1-CNN网络参数设置,本文将窗口大小设置为1,滤波器个数200。SMSL中对相似度特征学习的CNN参数设置与SMQL相同,但网络参数不共享。SMQL和SMFC的全连接网络采用dropout机制,dropout设置为0.5,网络的激活函数设置为tanh。
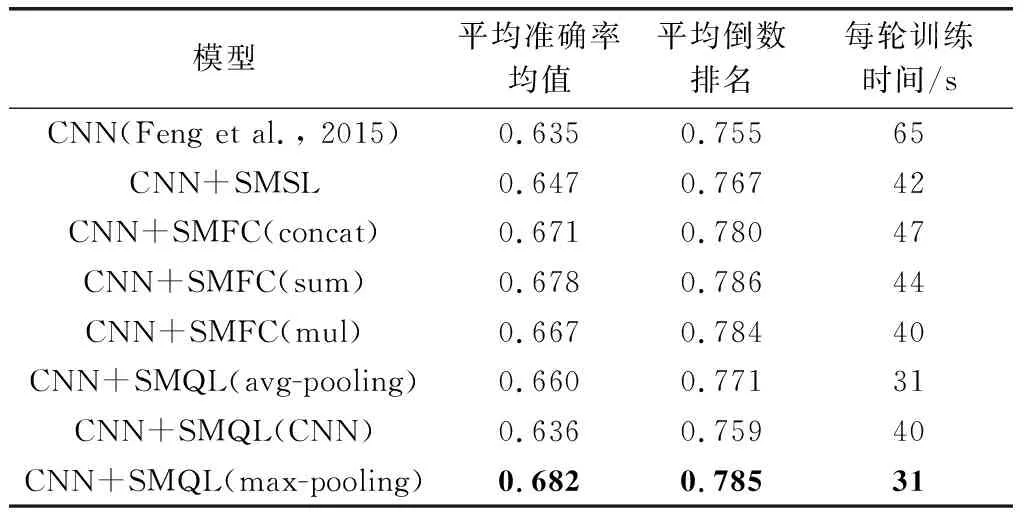
表2 基于CNN的相似特征学习模型实验结果
实验结果表明,添加了相似度特征学习方法有效地提升了实验结果,其中采用SMQL和SMFC方法提升明显,相比于基线模型,其MAP值提升了3.2%~4.7%,SMFC采取向量对应相加聚合(sum)方式优于其他聚合方式,其MAP值提升了4.3%,SMQL采取最大池化方法对问题的相似度特征学习得到了本次实验的最优结果,MAP值提升了4.7%,这也证实了问答相似度矩阵中问题的相似度特征的重要性,抽取问题特征实质为一种粗糙的特征筛选,能够防止模型过拟合,除此之外,相比与本文其他方法,SMQL训练周期也较短,模型复杂度更低。
为了进一步验证相似度特征学习方法的有效性,本文将BiLSTM作为底层特征抽取,添加相似度特征学习方法进行对比实验。实验中LSTM的隐层维度设置为141,添加dropout机制,dropout设置为0.5。实验结果如表3所示。
从实验结果可以看到,添加了相似度特征学习方法同样适用于BiLSTM模型,基于相似度特征学习的BiLSTM模型的MAP值相比于基线模型都有提升,SMFC采取向量拼接方式聚合特征的实验结果最好,相比于基线模型提升了1.9%,这也证实了本文模型的有效性。
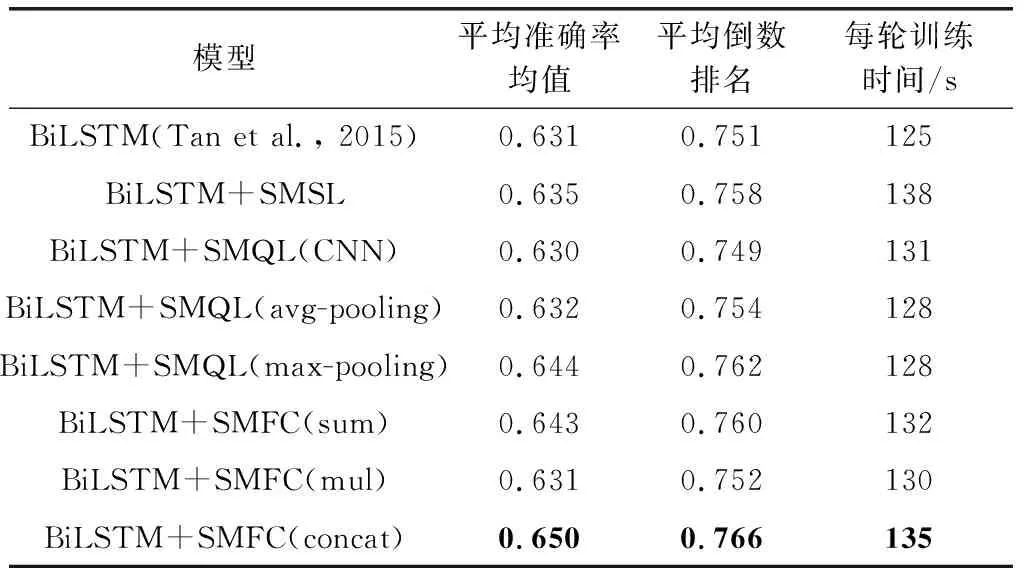
表3 基于BiLSTM的相似特征学习模型实验结果
4 结 论
答案选择是问答系统中的关键技术,本文提出了一种基于相似度特征的深度学习模型。该方法相比于传统的深度学习模型,不仅对问题和答案的特征进行提取,而且对各个尺度的特征的相似度进行训练,从局部相似度得到联合相似度。从特征学习、特征聚合和特征筛选3个方面出发,本文提出了3种相似度特征训练模型,其分别为SMSL模型、SMFC模型和SMQL模型。实验证明,本文方法在CNN和BiLSTM模型的基础上都有明显提升,其中CNN模型采用SMQL方法得到68.2%的MAP值,相比于基线模型提升了4.7%。
参考文献:
[1] WANG M, SMITH N A. What is the jeopardy model? a quasi-synchronous grammar for QA[C]∥Proc.of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2007: 22-32.
[2] HEILMAN M, SMITH N A. Tree edit models for recognizing textual entailments, paraphrases, and answers to questions[C]∥Proc.of the Annual Conference of the North American Chapter of the Association for Computational Linguistics, 2010: 1011-1019.
[3] YIH W, CHANG M W, MEEK C, et al. Question answering using enhanced lexical semantic models[C]∥Proc.of the 51st Annual Meeting of the Association for Computational Linguistics, 2013: 1744-1753.
[4] YU L, HERMANN K M, BLUNSOM P, et al. Deep learning for answer sentence selection[J]. Computer Science, 2014.
[5] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[6] FENG M, XIANG B, GLASS M R, et al. Applying deep learning to answer selection: A study and an open task[C]∥Proc.of the IEEE Automatic Speech Recognition and Understanding, 2015: 813-820.
[7] GERS F A, SCHMIDHUBER J, CUMMINS F. Learning to forget: continual prediction with LSTM[J]. Neural Computation, 2000, 12(10): 2451-71.
[8] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[J]. Computer Science, 2014.
[9] TAN M, SANTOS C D, XIANG B, et al. LSTM-based deep learning models for non-factoid answer selection[J]. Computer Science, 2015.
[10] TAN M, DOS SANTOS C, XIANG B, et al. Improved representation learning for question answer matching[C]∥Proc.of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
[11] DOS SANTOS C N, TAN M, XIANG B, et al. Attentive pooling networks[J]. CoRR, abs/1602.03609, 2016, 2(3): 4.
[12] MEDSKER L, JAIN L. Recurrent neural networks[J]. Design and Applications, 2001.
[13] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[14] GRAVES A. Generating sequences with recurrent neural networks[J]. Computer Science, 2014.
[15] LI P, LI W, HE Z, et al. Dataset and neural recurrent sequence labeling model for open-domain factoid question answering[J]. arXiv Preprint arXiv:160706275,2016.
[16] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model[J]. Journal of machine learning research, 2003, 3(2): 1137-1155.
[17] PRECHELT L. Early stopping-but when?[M]. Berlin Heidelberg: Springer,1998: 55-69.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
南都周刊(2015年4期)2015-09-10
