
一种融合语意理解的情感倾向标签算法
2018-06-14 05:47赵禛程良伦
数字技术与应用 2018年3期
赵禛 程良伦
(
广东工业大学计算机学院,广东广州 510000)
1 引言
文本的情感倾向分析作为一个多学科交叉的研究领域,涉及包括自然语言处理、机器学习、人工智能等多个领域。情感倾向分析能够自动判断文本的情感极性类别并给出相应的置信度。能够帮助企业理解用户消费习惯,分析热点话题和危情监控,同时提供有力的决策支持。
本文针对微博内容融合语意理解的机器学习分类器进行情感倾向分析,提高情感分析方法的适用性和准确率。
2 相关理论研究
当前的情感分析方法分为基于情感词典和基于机器学习这两种。
2.1 情感分析方法研究现状
2.1.1 基于情感词典方法的研究
文献[1]中设计了一个利用结构化语言学特征实现基于词典的无监督类情感分析系统。优化在不同应用环境中的情感分析。文献[2]提出了一种基于信息增益的有监督维吾尔文分析方法,避免传统空格分词方法造成的维数灾难和特征项语义不完整等问题。文献[3]提出在传统情感分析模型基础上引入模糊数学中的“直觉模糊集(IFS)”,分别建立形容词、动词、语气词等模糊情感特征词库。魏广顺,吴开超[4]等人提出词向量叠加方法和加权词向量方法进行文本特征的提取,从而更深层次的提出短文本特征。
2.1.2 基于机器学习方法的研究
基于机器学习方法在特定领域有着比较高的准确率。刘新星[5]等人提出一种离散特征和词向量特征的开关递归神经网络模型。首先直接循环图为语句建模,采用开关递归神经网络模型完成产品属性情感分析任务,并在模型中集成离散特征和词向量特征,最后分三种任务模型完成属性提取和情感分析任务。钱凯雨等人[6]提出一种可融入习语信息的树型-长短时记忆网络模型,可以很好的对习语进行建模。文献[7]中以词向量维度、词向量训练规模、滑动窗口大小和正则化方法等作为不同模型的影响因素,设计单层卷积神经网络处理中文情感分析。秦锋王恒等人[8]提出一种结合上下文消息的情感分析方法,使用隐马尔可夫支持向量机把微博上下文语境融入到情感分析问题中,更好的分析微博情感极性。
2.2 情感分析流程
2.2.1 基于情感词典的情感分析
例举一条微博内容:“今天去看了吴京导演的新片‘战狼2’,看得有点热血沸腾,确实是一部非常优秀的好片,展现出了中华民族的气势,但是3D的电影戴眼镜的看得时间久会有点不舒服。”
目前有情感词典如下:
情感词:
positive:期待、优秀、有趣、好片、热血
negative:糟糕、失望、尴尬、伤心、不
程度词:
level1:小、有点、稍微
level2:大、非常、很
设定情感词positive词+1,negative词-1;程度词level1*1,level2*2;
那么微博内容的情感值为:1*1+1*2+1-1=2
其中正向词得分为3,负向词的得分为1,可输出结果为[review:2]或者[review:(3:1)]。
该方法的重点在于构建符合文本语意环境的情感词典。
2.2.2 基于机器学习的情感分析
通常给予机器学习的情感分析方法分为以下五个步骤:
(1)中文分词。中文预处理,常用方法:基于词典、基于规则、基于统计、基于字标注、基于人工智能。
(2)特征提取。文本中拿什么作为特征,常根据词性或者位置。
(3)特征选择。从积极的数据中按词来选择积极的所有特征
(4)分类模型。选择合适的算法训练模型并测试数据集合。
3 融合语意理解的分类算法
3.1 情感词典法文本预处理
本文选用微博数据文本集,数据文本没有标注,若进行人工标注测需要消耗大量人力成本。而微博数据集采集相对简单,所以我们首先选取部分文本,利用基本情感词典粗略估计选取文本的情感倾向性。然后选取分值较高和分值较低的文本作为人工标注的训练文本。为后续的机器学习训练做数据准备。详细过程如下:
因为给予情感词汇的分析,字典的准确性和灵活性对结果至关重要。字典选取来自知网的情感词库,原始字典按照习惯将词汇分为三大类:
(1)情感词语。积极评价词;积极情感词;消极评价词;消极情感词。
(2)程度词。从最重的level5以此降低到level1,五个等级。
(3)否定词。基于以上特点,否定词的存在可以用来判别是否进行词汇的极性反转,程度词的存在可以给予不同的情感词不同的分数,而情感词可以整合积极词和消极词两部分。
3.1.1 词典修改
由于知网的词典是针对所有领域,因此在微博内容词汇的划分会有失偏颇,前期采用人工的方法对辞典的三个分类进行略微调整。调整如下:
(1)积极词中删除“要,用,开通,需,向,应,欲,通,深,对,会,长,常,上,经济,主要,红,幽,灵,颖,硬,不变,是,明显,约,刚,刚刚,到,事实上,基,基部”。
(2)消极词删除了‘大’,‘怊’‘,悭’‘,悱’,‘愦’‘,胜’‘,偏’。
(3)在否定词增加了‘无’‘,不’‘,不是’。
(4)在程度词中增加了‘百分之百’‘,非常’‘,重大’‘,大幅’‘,半点’‘,小幅’。
3.1.2 文本分块
一条微博,通常由不同的部分的组成,而每个部分的重要程度不同。对于一条长微博来说,文本长度足够的情况下,给定‘K1',‘K2'这两个参数,分别代表[0:K1]句和[K2-1:]句。这两部分分数的权重(Weight)相比于中间部分[K1:K2]的权重更高。
当一条微博过短时,认为够长来进行分块,即[0:K1]∩[K2-1:]≠,此时将忽视‘K1'‘,K2'这两个参数,全文采用统一权重来计算分数。
为了减少首尾权重(Weight)对于文本整体的影响过大,以至于算法忽略文本[K1:K2]部分的分数,将首尾的部分得出的分数乘以对应的频率,即:

s(i)是每部分对应的积极或者消极的分数,p(i)是每部分积极或者消极词的频率。
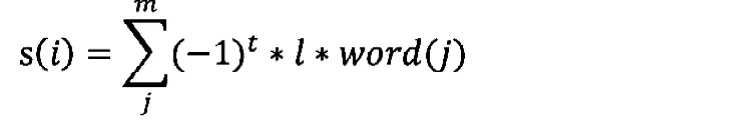
一些否定词的使用会让词语的极性反转,如‘不是’,‘不好’因此需要在词语的位置前继续搜索一到两个位置,查找是否含有否定词,然后进行极性反转。-1的指数t取决于是否进行极性反转,l表示程度词的程度值,word(j)表示词语的原始情感值。
通过对一百条微博的内容进行人工情感标注,计算每个设置权重weight选出最优weight参数,将比重设置为1.52,结果如图1所示。
从图1可见争取率最高是90%,对应的权重weight为1.52。
3.1.3 情感词典打分
至此,我们选择微博文本数据集匹配情感辞典进行打分,定义高分数据集data1分值为(10~),低分数据集data2分值区间为(-10,-5)。尽量保持两个数据集数量相同,以保证后续分类器训练。
3.2 特征选择
我们选择向量空间模型(VSM)作为特征提取,即将样本转化为向量的形式,需要一下两个步骤。
3.2.1 确定特征集
将data1和data2两个训练数据集使用分词工具Iksegment(Java)进行分词。
3.2.2 特征提取
选择文本中的特征词,构造词袋模型,统计词频,形成词频矩阵。这里选用TF-IDF来计算词苦衷最具有代表性的词。
为了选出最能区分不同情感的分词,因此这里对TF-IDF加入PMI点互信息来加强分词关联性。

pos表示文档情感,word表示分词。p(pos)*p(word)表示在pos情感同时出现word分词的概率。
3.3 分类器训练
将data1和data2数据集个分为n份,其中n-1份作为训练集,一份测试集,本文选用pathon从库sklearn中载入logisticRegression,svm进行测试,可选用多种分类器进行测试择优选用。
代码如下:
1.train_set = data[1:n,:]
2.test_set = data[n:,:]
3.train = train_set[:,1:]
4.tag = train_set[:, 0]
5.
6.import sklearn
7.from sklearn.svm
8.from sklearn.linear_model import LogisticRegression 9.clf_lr = LogisticRegression()
10.clf_lr_res = clf_lr.fit(train,tag)
11.train_pred = clf_lr_res.predict(train)
12.test_pred = clf_lr_res.predict(test_set)...
通过测试集重复测试多次,使用交叉验证测试分类器的准确度,比较不同分类器的准确率,选出最优分类器。
4 实验测试
4.1 实验环境和数据集
实验使用pc机,内存16g,硬盘250g。实验中的微博数据来自于新浪微博一万条微博内容。
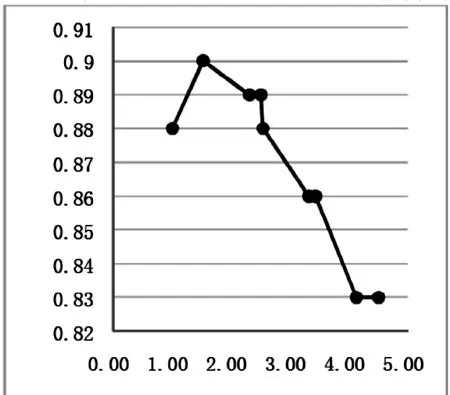
图1 权重选择折线图

图2 算法效果对比图
4.2 实验结果对比
本实验选择三种常用的分类器logistic Regression,朴素贝叶斯(Naive Bayes),支持向量机(SVM)等方法进行测试,结果显示如下:
1. GaussianNB `s accuracy is 0.760000
2. LogisticRegression`s accuracy is 0.810000
3. SVM`s accuracy is 0.8000
4.3 评估标准
我们来评测分类器效果时使用准确率(Accuracy),精确率(Precision)和召回率(Recall)来判断。准确率反映了分类器统对整个样本的判定能力——能将正的判定为正负的判定为负。精确率反应了被分类器判定的正例中真正的正例样本的比重。召回率反应了被正确判定的正例占总的正例的比重。公式如下:
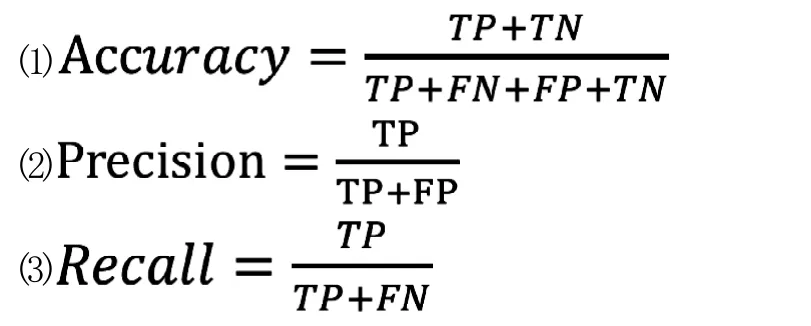
(1)真正类(True Positive,TP):被模型预测为正类的正样本。
(2)假正类(False Positive,FP):被模型预测为正类的负样本。
(3)假负类(False Negative,FN):被模型预测为负类的正样本。
(4)真负类(True Negative,TN):被模型预测为负类的负样本。测试结果如图2显示。
由实验结果与三种机器学习单独进行对比显示,融合语意词典方法的机器学习分类器效果更胜一筹,而且适合在不同领域中的应用,大量减少了人工标注消耗。
5 结语
通过实验结果可知,ben问题出的融合语义理解的机器学习情感分析算法在情感分析中具有一定的优势。本文针对现在单一的情感分析手段进行了融合优化,结合语意理解情感词的强关联性和机器学习分类算法的高效准确性,从而改善了单一方法的应用领域局限性。在后续的研究中,我们将针对分词器效率优化继续更加深入的研究。
[1]苏育挺,王慧晶.利用结构化特征解决面向社交媒体信息情感分析的研究[J].小型微型计算机系统,2017,(12):2625-2629.
[2]魏志远,岳振军.基于直觉模糊集的情感分析研究方法[J].通信技术,2017,(12):2692-2697.
[3]伊尔夏提·吐尔贡,吾守尔·斯拉木,热西旦木·吐尔洪太.基于有监督分词方法的维吾尔文情感分析[J].计算机工程与设计,2017,(11):3143-3146,3178.
[4]魏广顺,吴开超.基于词向量模型的情感分析[J].计算机系统应用,2017,(3):182-186.
[5]刘新星,姬东鸿,任亚峰.基于神经网络模型的产品属性情感分析[J].计算机应用,2017,(6):1735-1740.
[6]钱凯雨,郭立鹏.融入习语信息的网络评论情感分析研究[J].小型微型计算机系统,2017,(6):1273-1277.
[7]王盛玉,曾碧卿,胡翩翩.基于卷积神经网络参数优化的中文情感分析[J].计算机工程,2017,43(8):200-207.
[8]秦锋,王恒,郑啸,等.基于上下文语境的微博情感分析[J].计算机工程,2017,(3):241-246,252.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
电子测试(2018年1期)2018-04-18
疯狂英语(双语世界)(2017年3期)2018-01-19
疯狂英语(双语世界)(2017年1期)2017-07-01
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
当代修辞学(2013年4期)2013-01-23
外语学刊(2011年3期)2011-01-22
