
面向高考的现代文阅读材料体裁自动分类
2018-06-19 12:58苏雪峰
计算机工程与设计 2018年6期
苏雪峰,李 茹,张 虎
(1.山西大学商务学院 电子商务系,山西 太原 030031;2.山西大学 计算机与信息技术学院,山西 太原 030006;3.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引 言
高考语文试卷现代文阅读理解占有很大的比重,涉及的体裁主要有小说、散文、论文等体裁,答题系统如何准确识别阅读材料的体裁是一项关键性技术。阅读材料的体裁对于文章结构、表达方式、表现手法、修辞、语义、问句类型等具有一定的制约作用,而这些技术又是阅读理解的关键技术,体裁识别准确率的提高有助于上述技术性能的提升。本文以解决高考语文阅读理解答题系统中现代文阅读材料体裁自动识别问题为出发点,重点研究体裁分类中的特征抽取、特征选择及其分类方法,一方面探索体裁分类的研究方法,另一方面为解决高考阅读理解答题系统中的阅读材料体裁分类问题提供一个可行的解决方案。
1 相关研究综述
国外有关体裁以及语言风格的定量研究始于20世纪80年代末90年代初。Biber使用统计的方法对比研究了语料库中不同体裁文章在时态、词语的词性、从句类型等特征上的频率分布,从语言学的角度指出了不同体裁的文章在语言特征上存在显著差异,不同体裁的文章具有不同的语言学特征。Karlgren & Cutting对布朗语料库中所包含的4大类15小类体裁的语料进行了语言特征分析,统计分析的语言特征主要有动词、名词、介词、符号的使用数量,第一和第二人称的使用数量,which、that、it等代词和关系代词的使用数量,平均句长以及平均单词长度等特征。Kessler在总结和研究Biber和Karlgren工作的基础之上,提出了体裁分类的4类特征线索,结构线索、词汇线索、字符线索和派生线索,基于结构线索和词汇线索的特征需要在标注后的语料中获取,而基于字符线索的特征可直接从语料中获取,基于派生线索的特征通过其它特征求比率或计算来获取[1]。Petrenz对上述几位学者提出的体裁分类方法进行了对比研究,指出各体裁分类特征对于分类的稳定性表现各异,其中词性特征的稳定性最好,随着语料库中文档主题的不断变化,使用了词性特征的分类方法所得到的分类错误率不会有大幅度的变化[2];Petrenz还系统研究了体裁分类的特征选择问题和跨语言的体裁分类题,提出了一种半监督学习方法,讨论了体裁分类的语料库构建问题[3-5]。Salvador提出了一种独立于语言的基于词汇深层特征的特征抽取方法[6]。
国内关于体裁分类的研究起步较晚,研究的学者较少。方鸷飞等通过抽取文档的符号、词汇、格式、结构等特征,构建了针对政论体、科技体、诗歌体、新闻体、公文体5种体裁文档的分类特征体系,并使用SVM(support vector machine)算法进行了分类研究[7]。邓琦等使用改进的卡方和改进的df.idf方法进行体裁分类特征选择,研究了不同主题分布下的体裁分布情况,指出了主题与体裁之间存在着密切的联系,并将主题类别信息引入到体裁分类特征中,在包含旅游、生活、体育、房产、娱乐5个主题,记叙文、说明文、议论文、应用文、新闻5种体裁的语料库上进行了封闭测试,准确率在82%-93%之间[8]。在体裁分类应用方面,张书卿等研究了微博文本与政论体、公文体、科技体、文学体文本的分类问题,从体裁的角度指出了微博文本与传统文本的区别[9]。
目前国内的相关研究都是针对有明显结构特征的完整文章进行体裁识别研究,还没有查阅到专门研究高考阅读理解材料或文本片断的体裁分类的论文,也没有查阅到国内专门针对体裁分类研究的标准语料库和数据集。已有的部分研究主要是从互联网上下载相关体裁的文章,构建各自的数据集,规模偏小,没有统一标准。另外,高考语文现代文阅读所提供的材料往往是文章的节选,会丢很多结构特征,已有的方法不宜直接使用,使得针对阅读材料体裁分类的特征选择和分类识别更加困难。
2 体裁自动分类
从语言学的角度讲,体裁是文章构成的一种规格和模式,是文章内在性质的外化表现,属于文章的形式范畴。体裁是人类在社会活动过程中为了适用不同的交流目的而自然形成的对文章结构和形式的“规范”,它对文章的写作有着明显的制约和规范作用,它与文章作者的个人风格、主题思想的表达、社会历史环境等有着密切的联系。
从机器学习的角度讲,体裁识别是一种分类问题。本文研究的体裁分类不仅指文章的体裁,还包括一定长度的文本片断的体裁,称为文本体裁。文本体裁分类是文本分类的一个重要分支,文本分类主要根据文本的主题进行分类,而文本体裁分类主要根据文本的结构和形式进行分类,文本的主题和结构又密切相关。
设X为文本集合,C为体裁类别集合,文本x与类别c的关系可表示为(x,c)∈X×C,即为文本与类别之间指定一个二元值,则体裁分类就是寻找一个函数映射θ:X×C→{T,F},T表示文本x的体裁类别是c,F表示文本x的体裁类别不是c。
体裁分类的一般流程如图1所示。
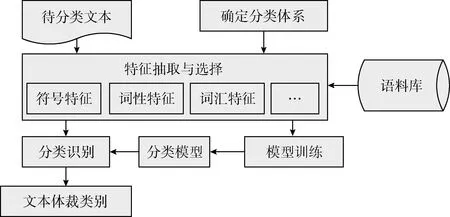
图1 文本体裁分类流程
2.1 确定分类体系
体裁分类体系的确定是研究体裁自动分类的基本问题,但由于体裁的特殊性,在不同的历史时期、不同的国家具有不同的分类体系,没有一个权威统一的划分标准。在不同的应用场景中,分类的体系也不尽相同。在我国中小学语文教学中,体裁分为一般文章和文学作品两大类,一般文章主要包括记叙文、议论文、说明文、应用文等体裁,文学作品主要包括诗歌、散文、小说、戏剧等体裁。近10年全国语文高考现代文阅读中,科技文和文学作品是必考的两类文本,其中,科技文阅读材料主要包括议论文和说明文两类体裁,文学作品主要包括小说和散文两类体裁。另外,国家863项目高考语文智能答题系统的研究主要针对北京高考,而北京高考现代文阅读只涉及科技文和文学作品两类体裁。本文重点研究高考中必考的科技文和文学作品两类文本的体裁分类问题。
2.2 特征抽取
体裁分类不同于主题分类,体裁和主题是文章的两种固有属性,体裁主要强调形式,主题主要强调内容,二者在特征选择上具有较大差别,主题分类以字、词特征为主,而体裁分类以形式、结构等特征为主。目前关于体裁分类的研究中特征选取仍以浅层特征为主,本文根据高考阅读材料的特点,从符号、词性和词汇3个方面进行分类特征的抽取。
2.2.1 符号特征
科技文语法规范,多用陈述句,少用疑问句,基本不用感叹句和祈使句。文学作品句型种类丰富,陈述句、感叹句、疑问句都要使用。各类句型的使用情况可通过统计标点符号的使用频率来描述,句号、感叹号、问号的使用频率反映了陈述句、感叹句、疑问句使用的多少。
通过对3100篇文档构成的科技文和文学作品语料库中句号、感叹号、问号、省略号4种标点符号的平均使用频率的统计,生成了图2所示的标点符号频率分布条形图,其中标点符号pun在语料库i类文档中的平均分布频率计算公式为
其中,countk(pun)为标点符号pun在文档k中出现的频数,total_pun(k)为文档k中包含的标点符号总数,Ni为语料库中i类文档的总数。
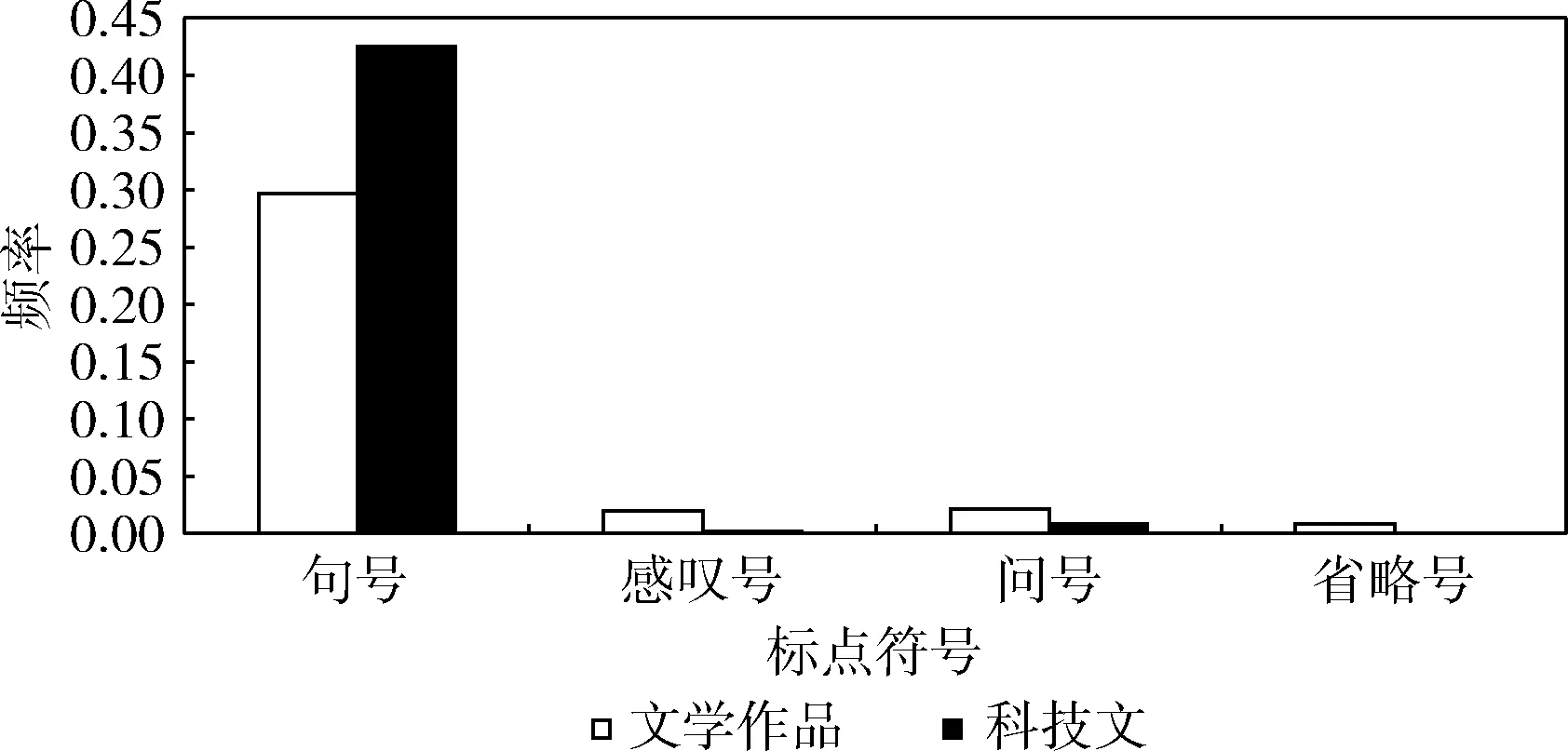
图2 科技文、文学作品标点符号平均频率分布
如图2所示,文学作品中使用句号的平均频率低于科技文中的使用频率,而感叹号、问号、省略号的平均使用频率高于在科技文中的使用频率。另外,省略号在散文中使用频率较高,表达某种不精确、不完整的表达;而在科技文中很少使用省略号,一定程度上反映出了科技文表达规范、平实、准确的特征。初步的分析结果表明标点符号的频率分布与各种句型在科技文、文学作品中的使用情况是一致的,所以将标点符号特征用来反映句型特征并作为文学作品、科技文分类特征是合理的。
2.2.2 词性特征
科技文用来说明具体事物或事理,介绍科技、文化、地理、人文等知识,表明作者的观点和态度,主要使用议论和说明的表达方式,较多使用外来词和科技术语,语言平实简洁,逻辑性强,少用形象性、描绘性的词语。文学作品用来描写对社会、人生、自然界的感悟,塑造人物形象,主要使用叙述、描写、抒情的表达方式,使用词语较为广泛,较多使用描绘性、情感性、形象性词语。
由于科技文和文学作品存在上述特征,而这些特征能通过文章中使用的各类词的词性频率分布来反映,为了验证词性特征作为分类特征的合理性,进行了初步的统计分析,生成了各类词性分布的条形图(如图3所示)。图3中列出的是在语料库中平均分布频率较高的21类词性的分布情况,语料库采用863词性标注集进行标注(共28种标记),其中词性标记pos在语料库第i类文档中的平均分布频率计算公式为
countk(pos)为词性标记pos在文档k中出现的频数,total_word(k)为文档k包含的词语总数,Ni为语料库中i类文档的总数。
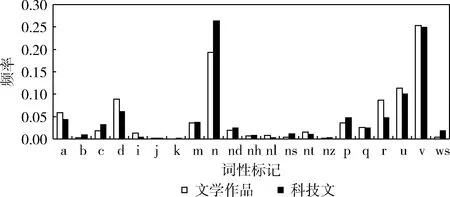
图3 科技文、文学作品词性频率分布条形图
语料库中各类词的频率分布表明科技文和文学作品使用的词语在词性分布上存在较大差别。形容词(标记为a)、副词(标记为d)、成语(标记为i)、方位名词(标记为nl)、时间名词(标记为nt)在文学作品中的平均分布频率高于在科技文中的分布频率,体现了文学作品较多使用描绘性、情感性、形象性词语的特征。名词(标记为n)、外来词(标记为ws)、连词(标记为c)、介词(标记为p)、其它名词修饰词(标记为b)等在科技文中的平均分布频率高于在文学作品中的分布频率,体现了科技文较多使用外来词和科技术语,语言平实简洁的特征。
2.2.3 词汇特征
科技文的主要表达方式是议论和说明,文章逻辑性强,较多使用联结词表示文章的层次结构,如“首先、其次、再次、此外、总之”等词语;常使用举例子、做比较、打比方、列数字等说明方法,较多使用如“比如、譬如、如图、如表、对比、相比”等词语。文学作品的主要表达方式是叙述、描写,也会用到抒情和议论的表达方式,描述细致,富有情感,较多使用情感词和拟声词,如“愁、怒、悲、怕、忧、喜欢、爱”等情感词。文学作品常用比喻修辞手法,较多使用比喻词,如“仿佛、像、好像”等。科技文和文学作品在人称的使用上也有一定的差异,科技文较少使用第一人称。
此外,通过对语料库的统计分析发现,科技文和文学作品在动词的使用上也具有较大差别,除了通用高频词“是、会、能、让”等词外,文学作品中大量使用表示行为的单字词(如看、走、听等)、表示心理活动(如想、爱、怕、喜欢等)和表示趋向的动词(如上、下、回、来等)。科技文较多使用表示发展、变化和双字行为动词,如“研究、进行、发展、演变、出现、调查、显示、使用”等。
词汇特征可分为逻辑联结词、说明方法词、人称代词、情感词、比喻词、高频动词6类,其中人称代词又分为第一人称、第二人称、第三人称3类;情感词分为程度词、负面评价词、正面评价词、负面情感词、正面情感词、主张词6类;高频动词分为科技文高频动词和文学作品高频动词两类。逻辑联结词、说明方法词、人称代词、比喻词词表根据相关语言知识进行手工构建,情感词词表使用hownet情感词典。高频动词词表使用χ2统计法进行筛选[7],公式为
其中,A表示语料库中体裁类别c和动词t同时再现的次数;B表示t出现c不出现的次数;C为t不出现c出现的次数;D为t和c均未出现的次数。n为语料库中文本的数量。χ2(t,c)值越大,t和c的相关性越强。每一类通过设置一个阈值选择χ2(t,c)较大的动词构成高频动词表。
逻辑联结词、说明方法词、比喻词在文本中的分布频率,人称代词、情感词、高频动词中每一子类在文本中的分布比例对于区分科技文和文学品具有一定的作用。所以,本文将逻辑联结词、说明方法词、比喻词在文本中的分布频率作为3个分类特征,分布频率的量化方法为词频与文本长度的比值;人称代词、情感词、高频动词每一子类在文本中的分布比例作为分类特征,第i个子类的分布比例量化方法为
其中,sc为某一类词,sci为其第i个子类,count(sci)表示文本中包含的sci类词的数量,N表示sc类词的子类数。
在体裁自动分类特征抽取的研究中,除了上述3类特征,一些统计特征和结构特征也是比较普遍使用的特征。如平均句长、平均段、条文句的频次、段首序码频次等特征研究诗歌体、政论体、新闻体、公文体和科技体的体裁分类问题。通过对语料的分析,科技文和文学作品没有类似公文、科技论文和新闻体明显的统计和结构特征,平均句长、段长并没有明显的差异,条文句和段首序号等结构特征也不存在,所以本文没有选择统计和结构特征作为分类特征。
2.3 特征选择
特征抽取阶段对每一特征进行了量化,并采用条形图的方法对特征进行了定性分析。显然,每一个特征对分类的贡献能力是不同的,有必要应用定量的方法度量每一个特征的重要性,并从中选取最重要的特征,剔除不重要的特征。
特征选择的方法主要有信息增益(IG)、互信息(MI)、卡方统计(CHI)等[10,11],这些方法的一般思想是通过计算特征与类别的相关程度确定特征的重要性,特征与类别相关度越高重要性越大,就越有可能作为分类特征。上述方法将特征选择与特征取值的计算看作是两个过程,如文本分类中使用IG选择特征,使用TF-IDF计算特征的取值。特征与类别的相关度一般不能直接作为特征的取值,同样特征的取值也不能直接用来计算特征与类别的相关程度。本文使用基于类内离差和类间离差的方法进行特征选择,该方法直接使用特征的取值评价特征的重要性,提高特征选择的效率。
一般地,一个特征在不同类模式中的分布重叠越小,可分性就越强。特征的取值在不同类间的离差越大,在同一类中取值越密集,重叠就越小。所以可以将特征的类间离差与类内离差的比值作为评价特征的函数。
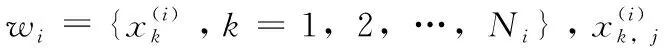
设Pi为wi类的先验概率,由Pi=Ni/N得到,N为各模式类总的训练样本数,则定义在第j个特征上的总的类内离差为
设mj为第j个特征上的总平均值,定义在第j个特征上的总的类间离差为
第j个特征总的类间离差越大,且总的类内离差越小,区分能力越强,则可定义特征j的评价函数为
D_ratioj=SBj/SWj
D_ratioj就是我们评价特征的指标值,一个特征的D_ratioj值越大越好,在特征选取过程中,保留D_ratioj较大的特征,去除D_ratioj较小的特征。表1列出了D_ratioj值大于1的词性特征的评价值、总类内离差和总类间离差。
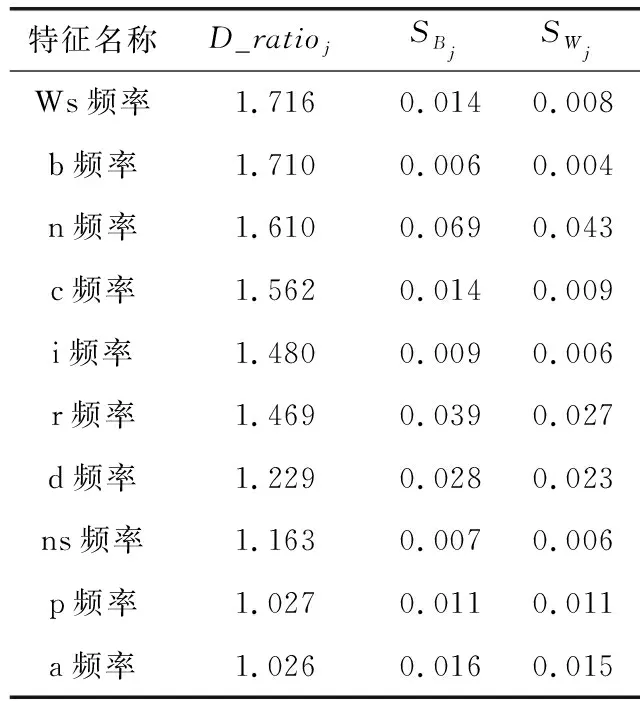
表1 部分词性特征的评价值
表1所示的对记性标记的评价结果与图3的条形图分析结果基本一致,表明基于离差的特征评价方法能比较有效地反映特征的区别能力,对于特征选择具有重要指导作用。
2.4 分类算法
目前国内外有关体裁分类的研究主要是基于浅层特征的,分类算法大多是基于SVM的方法,区别主要表现在特征选择和体裁分类体系的不同上。SVM分类方法在处理高维、小样本数据集中具有较好的整体性能,其基本思想是在特征空间中寻找最优超平面,以该平面为分类面实现对文本的分类。本文中的各类特征的特征值都进行了规范化处理,每一个文本都表示成了实数向量,适合使用SVM方法训练分类器。
3 实验及结果分析
3.1 实验准备
在实验中,从网上下载了科技文和文学作品共3100篇文档,其中2600篇作为训练数据集,500篇作为测试数据集1;同时还收集了2004-2016年全国各省高考真题,以及部分省份的模拟试题科技文和文学作品阅读材料共450篇作为测试数据集2。实验数据集的分布情况见表2。
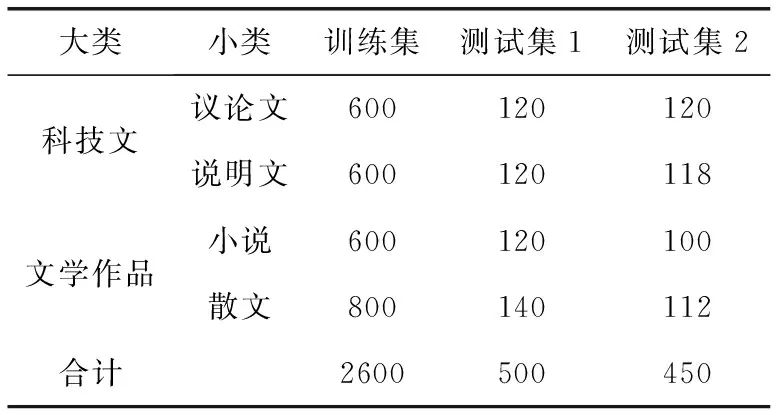
表2 数据集统计情况
所有文本统一使用哈工大IR实验室提供的LTP接口进行文本分词处理,词性标注采用863标注集。在预处理阶段对文本的词性特征和符号特征进行了统计,在统计词汇特征之前需要构建各类词的词表,高频动词词表采用卡方法进行自动构建,其它类词表包含的词数量少,由人工构建,根据这些词表统计词性特征;最后按照文中2.2节的方法计算每一个特征的特征值。
对高考答题系统而言,预测一篇现代文阅读材料是文学作品还是科技文同等重要,所以分类器的评价指标采用分类中普遍使用的准确率(precision)、召回率(recall)和F1值(F1-measure)评价每一类的分类性能,并使用三类指标的宏平均考察整体的分类性能[11]。
3.2 实验结果
实验结果表明,在动词大小为160,特征个数为25的情况下,SVM算法在线性核、规则化参数C=10,回归精度epsilon=0.1时具有良好的性能,实验的运行结果评价见表3。
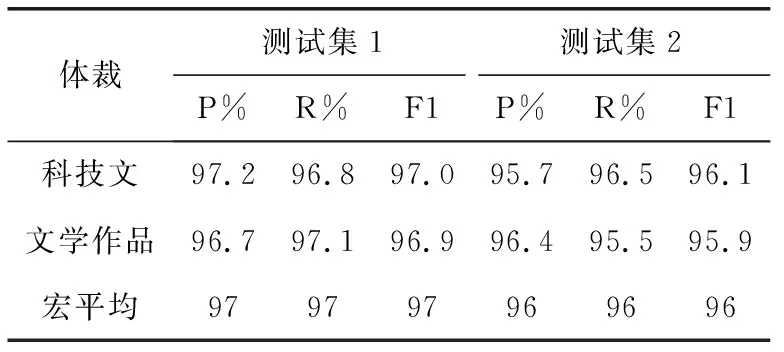
表3 分类性能评价
实验结果表明,本文提出的基于词性特征、符号特征和词汇特征的特征抽取方法和基于类内和类间离差的特征选择方法能描述科技文和文学作品在体裁上的本质特征,通过SVM分类算法能训练出的分类器性能较好,两类的准确率较为接近,平均准确率达到了96%。
分类器在测试集1上的分类性能较优是由于测试集1和训练集都是从同一数据集中随机选取的,来自于同一总体,各类特征的分布较为接近,识别的准确率较高;测试集2为高考阅读材料,来源广泛,文章的主题、风格各异,而且都是节选,加之训练数据集在覆盖面上的局限性,使得分类器在测试集2中的性能与在测试集1性能相比有所下降,但幅度不大,表明本文提出的方法具有良好的稳定性。
3.3 参数的设置
在词汇特征的抽取过程中需要用到各类词表,情感词表使用了hownet情感词表,动词词表使用卡方法进行自动选择,其它词表规模较小,都为手工构建。动词词表的大小对分类性能具有一定的影响,为了确定最优的词表,实验根据卡方值的大小对词表进行了降序排序,然后选择排序靠前的N个词作为动词词表。根据不同的N值在训练集上进行了10折交叉验证,计算平均准确率,N的大小对分类性能的影响如图4所示。
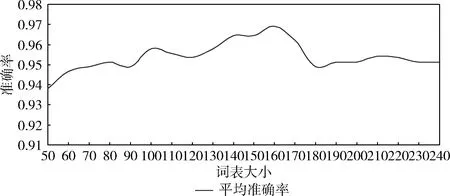
图4 动词词表大小对准确率的影响
实验结果表明,N的取值在140-170范围内,分类的准确率最高;N值小于140时,随着N的增大,准确率不断提高,存在较大的振荡;N值大于170时准确率有所下降,但下降曲线较为平缓。从N值对准确率影响的曲线上可以说明,当词表达到一定规模时,基本覆盖了常用词,准确率达到了一定水平,而且相对比较稳定;此时再增加一些非常用词来扩充词表,准确率会有所下降,但下降较为平稳。在最终的分类模型中,选择N=160训练分类器。
特征的个数对分类的性能也具有重要影响,实验按照2.3中提出的特征评价方法计算每一个特征的评价值,并按照评价值对特征集进行降序排序,采用逐步向前选择的方法加入特征,在训练集上进行10折交叉验证,计算平均准确率,特征个数对分类性能的影响如图5所示。
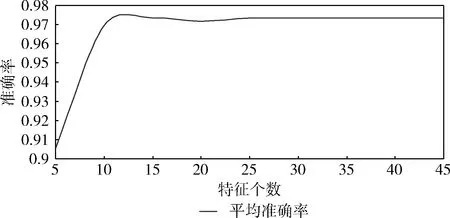
图5 特征个数对准确率的影响
实验结果表明,特征个数小于15时,随着特征个数的增加,准确率不断提高;特征个数为15时,准确率已达到最优,但特征个数在线15-25之间时,准确率出现小幅振荡,当特征个数大于25时,准确率趋于稳定。在最终的分类模型中,选择了25个特征训练分类器,其中符号特征3个,词性特征14个,词汇特征8个。
实验结果表明,基于“词性特征+符号特征+词汇特征”的特征构建方法和基于离差的特征选择方法能有效抽取体裁分类的重要特征,使用这些特征训练的线性核SVM分类器在动词词表大小为160,特征个数为25时表现出了良好的性能,在测试集1和测试集2上的平均准确率分别为97%和96%。
4 结束语
本文以解决高考答题系统中科技文和文学作品阅读理解中的体裁识别问题为出发点,从体裁分类的浅层特征入手,使用统计分析的方法分析了词性特征、符号特征、词汇特征在两类体裁中的差异,提出了基于频率分布的特征量化方法和基于类间和类内离差的特征选择方法。使用这些特征训练的SVM分类器表现较为稳定,识别准确率较高,能较好地解决高考智能答题系统阅读材料的体裁识别问题。另外,文中提出的“词汇特征+符号特征+词汇特征”的体裁分类方法提供了从特征分析、特征量化、特征抽取、特征选择、到模型训练与评价一套完整的方法体系,能为解决不同应用场景下的文本体裁分类问题提供有益的指导。
本文的研究主要是为了解决高考机器人针对的北京高考现代文阅读材料中涉及的两类体裁的自动分类问题,没有研究更细粒度的体裁类别,还有改进的空间。一方面加大训练样本集的多样性和覆盖面,构建更加完整的有针对性的语料库,为更细粒度的体裁分类识别研究做准备;另一方面研究和加入深层特征,如主题、修辞、表达方式等特征,使分类器能识别更细粒度的文本体裁,通过以上两个方面的改进,解决面向全国高考的现代文阅读材料体裁自动分类问题。
参考文献:
[1]Brett Kessler,Geoffery Nunberg,Hinrieh Schutze.Automa-tic detection of text genre[C]//Proceedings of 35th Annual Meeting of Association for Computational Linguistics.New York:ACM,1997:32-38.
[2]Philipp Petrenz,Bonnie Webber.Stable classification of text genres[J].Computational Linguistics,2011,37(2):385-393.
[3]Philipp Petrenz.Cross-lingual genre classification[C]//Proceedings of the Student Research Workshop at EACL.France:Association for Computational Linguistics,2012.
[4]Philipp Petrenz.Cross-lingual genre classification[D].Edinburgh:University of Edinburgh,2014:30-34.
[5]Philipp Petrenz,Bonnie Webber.Robust cross-lingual genre classication through comparable corpora[C]//The Procee-dings of the 5th Workshop on Building and Using Comparable Corpora.New York:ACM,2014.
[6]Llorens-Salvador M,Delany S J.Deep level lexical features for cross-lingual authorship attribution[C]//ECIR Workshop on Modeling,Learning and Mining for Cross/Multilinguality.German:Springer,2016:16-25.
[7]FANG Zhifei,LIN Hongfei,YANG Zhihao,et al.Automatic classification of Chinese text genre[J].Journal of Chinese Information Processing,2005,20(2):20-32(in Chinese).[方鸷飞,林鸿飞,杨志豪,等.中文文本体裁的自动分类机制[J].中文信息学报,2005,20(2):20-32.]
[8]DENG Qi,SU Yidan,CAO Bo,et al.Research on feature selection in Chinese text genre classification[J].Computer Engineering,2008,34(23):89-91(in Chinese).[邓琦,苏一丹,曹波,等.中文文本体裁分类中特征选择的研究[J].计算机工程,2008,34(23):89-91.]
[9]ZHANG Shuqing,ZHOU Wen,OUYANG Chunping,et al.Comparison of genre features between micro-blog text and traditional text[J].Journal of University of South China(Science and Technology),2015,29(2):89-90(in Chinese).[张书卿,周文,欧阳纯萍,等.微博文本和传统文本体裁特征对比[J].南华大学学报(自然科学版),2015,29(2):89-90.]
[10]YANG Jieming.The research of text representation and feature selection in text categorization[D].Changchun:Jilin University,2013(in Chinese).[杨杰明.文本分类中文本表示模型与特征选择算法研究[D].长春:吉林大学,2013.]
[11]LIU Haifeng,LIU Shousheng,SONG Aling.Improved method of IG feature selection based on word frequency distribution[J].Computer Engineering and Applications,2017,53(4):113-117(in Chinese).[刘海峰,刘守生,宋阿羚.基于词频分布信息的优化IG特征选择方法[J].计算机工程与应用,2017,53(4):113-117.]
猜你喜欢
英语世界(2021年13期)2021-01-12
疯狂英语·初中天地(2020年11期)2020-12-28
传媒评论(2019年3期)2019-06-18
电子制作(2017年23期)2017-02-02
第二课堂(课外活动版)(2016年2期)2016-10-21
国家图书馆学刊(2016年2期)2016-10-09
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
振动工程学报(2014年4期)2014-03-01
图书馆建设(2012年3期)2012-10-23
