
Stacking-SVM的短期光伏发电功率预测
2018-07-12 06:38张雨金周杭霞
中国计量大学学报 2018年2期
张雨金,周杭霞
(中国计量大学 信息工程学院,浙江 杭州 310018)
光伏发电是可再生能源中最普及且具有很大发展潜力的能源,目前已成为电力能源的重要组成部分.光伏发电受阳光辐照度、环境温湿度等因素影响,具有随机性、波动性和间歇性的特点,当大规模光伏系统并网后会对电网的稳定性和安全性造成严重影响.为了减少光伏电站对电网的冲击,就需要对电网进行合理调度.短期光伏发电预测可用于光伏出力平滑控制和电网的调度[1-2],有利于维护电网安全稳定和光伏电站经济运营.
目前国内外学界对光伏发电预测已有了一定的研究.气象预测法以天气预报系统预测的气象参数来预测光伏发电量[3-5].相似日法通过太阳辐照度、时间、温度、相对湿度等参数,从历史数据中选取与当前气象参数相似的数据,以相似日数据训练预测模型[6-8].机器学习法为精准分析光伏发电影响因素和提高光伏发电预测精度提供了有效途径,该方法使用BP神经网络算法[9]和支持向量机(SVM)[10]居多,已有多种组合改进模型被提出[11,12],机器学习法晴天预测误差在8%左右[13],多云误差约为26.20%,阴雨天误差约为43.05%[14].
上述研究中,气象预测法受到天气预报系统精度的限制,预测的气象参数误差较大时,会严重影响预测精度.相似日法将晴转多云、多云转雨等复杂天气类型归类到晴天、雨天、多云等少数几个简单天气类型中,在晴转多云、多云转雨等复杂气象条件下进行预测时误差较大.机器学习法使用BP神经网络面临着易于陷入局部最优和迭代收敛慢的问题,BP、SVM及其组合改进模型,本质上是基于单一学习器的预测模型,其预测精度提升有限,存在较大改进空间.
针对上述问题,本文引入集成学习的思想和方法,采用Stacking算法改进单一的SVM预测模型:首先使用多个初级SVM对预测样本进行一次预测;然后使用Kmeans算法对训练集聚类,选择与预测样本同类别的训练样本训练次级SVM;最后使用次级SVM对初级SVM预测输出进行结合得到最终预测结果.本文基于实测数据进行算例分析,验证了经Stacking算法改进后的SVM预测模型在稳定气象条件与突变气象条件下的预测精度有了明显提升.
1 预测模型算法
1.1 Stacking算法
Stacking算法是集成学习中一种智能化的基学习器结合算法,该算法使用一个学习器来结合基学习器预测输出得到最终预测值.Stacking算法中将基学习器称为初级学习器,用来结合基学习器预测结果的学习器称为次级学习器.Stacking算法使用训练好的初级学习器将原始训练集转化为次级训练集,用来训练次级学习器;在次级训练集中,初级学习器的输出值作为样本特征,原始样本的目标值仍作为训练目标值,其算法描述如下:
输入:原始训练集
dataset={(x1,y1),(x2,y2),...,(xn,yn)}
次级训练集dataset*=φ
已训练好的初级学习器h1,h2,...,hT
次级学习器算法A
次级学习器h*
过程:fori=1,2,...,ndo
fort=1,2,...,Tdo
fit=ht(xi);
end for
dataset*=dataset*∪((fi1,fi2,...,fiT),yi);
end for
训练次级学习器h*=A(dataset*);
输出:集成模型H(x)=h*(h1(x),h2(x),...,hT(x))
其中x为样本特征,y为样本训练目标;fit为初级学习器输出值.
1.2 支持向量机回归算法
SVM算法在1995年由Vapnik等人提出,该算法以统计学习理论为基础,结合结构风险最小化理论,可以解决小样本、非线性、高维数等问题.该算法性能较高,稳定性较好,本文使用SVM作为Stacking算法的初级学习器和次级学习器.支持向量机回归算法推导过程为:给定样本集dataset={(x1,y1),(x2,y2),…,(xn,yn)},其中xi∈Rd是输入值,yi∈R是目标值,i=1,2,…,n,通过线性回归函数:
f(x)=wTx+b.
(1)
来拟合样本(xi,yi),采用ε不敏感损失函数:
(2)
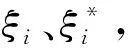
(3)
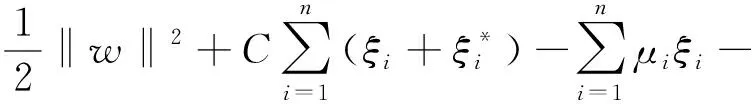
(4)
将式(4)对w求偏导,使偏导为0可得到
(5)
将式(5)代入式(1)得到回归模型
(6)
1.3 Kmeans算法
Kmeans算法是常用的一种聚类算法,该算法采用距离来衡量样本之间的相似性,能将样本集划分成K个簇,簇Ci的均值向量
(7)
为该簇的质心.Kmeans算法的目的就是寻找K个质心来最小化平方误差
(8)
平方误差E越小则表明簇内样本的相似度越高.Kmeans算法的主要过程如下:
输入:样本集dataset={X1,X2,…,Xn},K值
过程:随机初始化质心{μ1,μ2,…,μK}
repeat
fori=1,2,...ndo
forj=1,2,...kdo
计算样本Xi与质心μj之间的距离
distance=‖Xi-μj‖2;
end for
将样本Xi与它最近的质心μ归为一类;
end for
forj=1,2,...kdo

end for
until达到最大迭代次数或质心更新幅度小于阈值
输出:簇集clusterset={C1,C2,...,CK}.
2 Stacking-SVM预测模型构建
2.1 光伏发电特性分析与训练样本构成
选取晴天、雨天、多云三种天气的光伏发电功率曲线如图1,光伏发电受天气、环境等因素影响具有随机性波动性,尤其在多云、阴雨的气象条件下,一天的光伏发电功率曲线剧烈波动,产生多个峰值.从图1中截取短时间内光伏发电功率曲线如图2所示,在短时间内天气、环境等因素虽有变化,却不容易引起发电功率的剧烈波动,相邻几个时刻的光伏发电数据具有一定的相关性,可用来预测未来一段时间的光伏发电功率.

图1 全天光伏发电功率Figure 1 Full day PV power curve
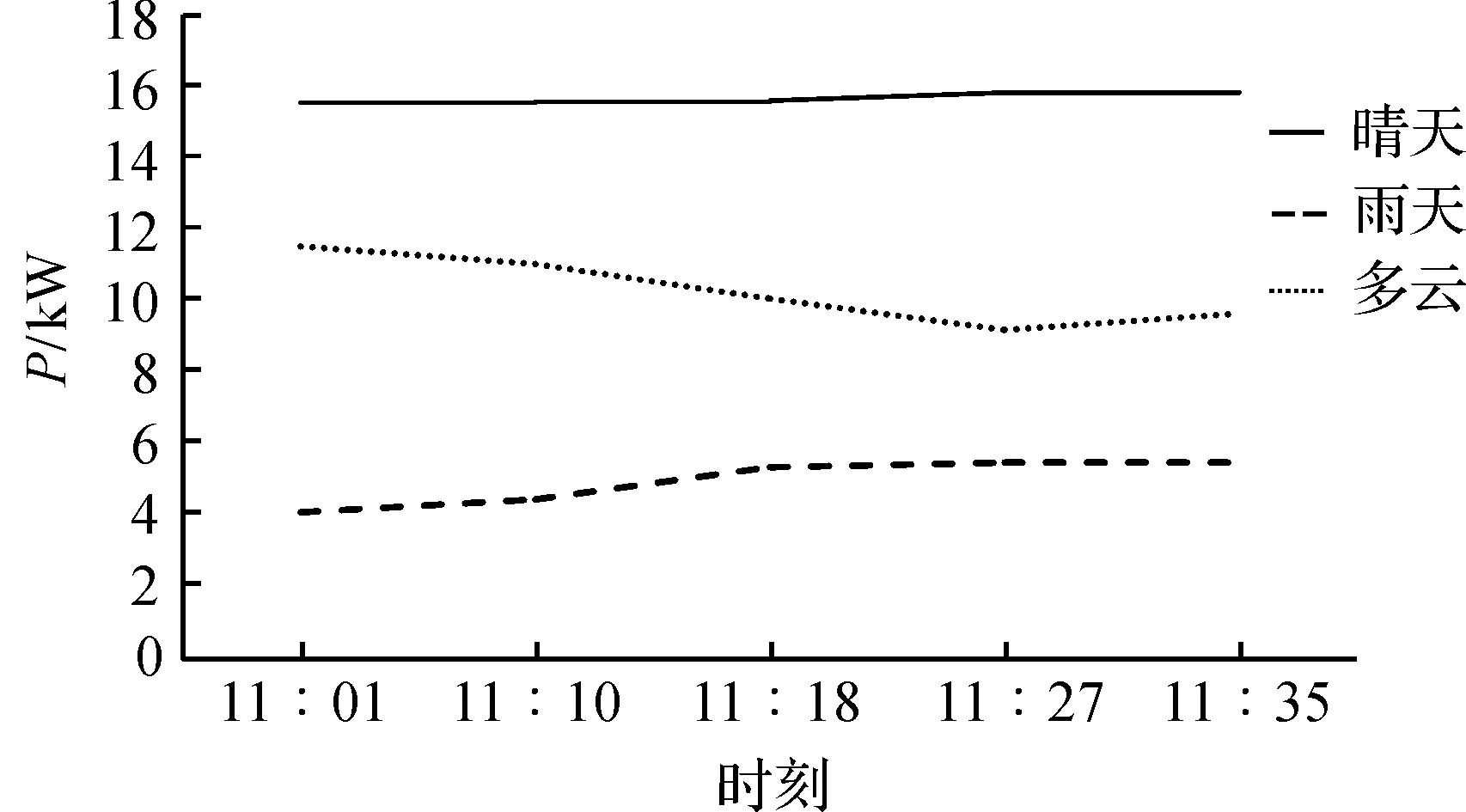
图2 短时光伏发电功率Figure 2 Short time PV power curve
目前光伏发电监控系统主要监测光伏组件输出的直流电流电压Idc、Vdc,组件温度T,逆变器输出的交流电流电压Iac、Vac,当前时刻发电功率P,当日累计发电量E.这些参数全面的表示了光伏发电系统工作状态,t时刻光伏系统工作状态可表示为
S(t)={Idc(t),Vdc(t),T(t),Iac(t),
Vac(t),P(t),E(t)}.
(9)
由上分析得到短时间内光伏发电数据具有一定的相关性,本文将历史数据中连续两个时刻的光伏系统工作状态S(t)、S(t-1)和时刻t作为样本特征,将下一时刻发电功率P(t+1)作为训练目标,t时刻的训练样本可表示为
sample(t)={[t,S(t),S(t-1)],P(t+1)}.
(10)
预测时以当前时刻t、S(t)、S(t-1)为输入来预测下一时刻的发电功率,预测模型可表示为
P(t+1)=model(t,S(t),S(t-1)).
(11)
2.2 模型训练与预测过程
本文将SVM作为Stacking算法的初级学习器和次级学习器.Stacking-SVM预测模型训练过程如图3所示.从原始训练集中随机采样,从采样得到的训练样本中随机选取特征得到初级训练集,然后训练初级SVM,上述过程循环n次得到n个不同的初级SVM.使用Kmeans算法对预测样本和原始训练集进行聚类分析,选取与预测样本同类的训练样本,将其输入已训练的n个初级SVM转化为次级训练集后进行次级SVM的训练.

图3 训练过程Figure 3 Training process
Stacking-SVM预测过程如图4所示.将预测样本输入n个初级SVM,使用次级SVM对初级SVM的预测输出进行结合,得出最终预测结果.

图4 预测过程Figure 4 Forecasting process
2.3 数据归一化与模型评价指标
训练样本包含时刻、直流电流电压、交流电流电压、温度、发电量和发电功率八种参数,这些参数单位不同,数量级也相差甚远,因此需要进行归一化处理,本文采用以下归一化方法
(12)

本文采用平均绝对百分比误差MAPE和均方根误差RMSE来评价模型的预测能力.
(13)
(14)
其中:xmodel为模型预测值,xactual为实测值.
3 算例分析
本文数据为浙江绍兴地区某20 kW光伏电站监控数据,该电站监控系统每隔8分钟记录光伏发电系统的工作状态.选用2015年4—6月和2016年4—6月的数据来训练预测模型,考察该模型在2017年5月的晴天、雨天、多云3种气象条件下的表现.
晴天云量较少,光照、温度等气象条件相对稳定,因此光伏发电功率波动较小.图5给出了本文基于Stacking-SVM模型和SVM模型在晴天的预测结果对比,本文模型晴天发电功率预测曲线十分贴近实测值,与SVM相比,两者没有明显差异.图6给出了二者在晴天的预测误差对比,本文模型在开始发电和结束发电的短时间内预测误差偏高,其他时段与SVM相近,综合来看本文模型与SVM模型在晴天的预测性能差距不大.

图5 晴天发电功率预测曲线Figure 5 Forecast curve in sun day
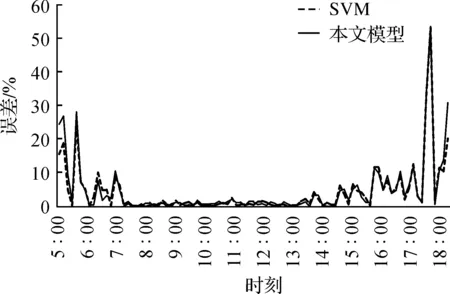
图6 晴天预测误差曲线Figure 6 Forecast error curve in sun day
雨天的光照、温度等气象条件频繁剧烈变化,导致光伏发电功率剧烈波动产生多个尖峰.图7给出了本文模型与SVM模型在雨天的预测结果对比,本文模型能有效的预测光伏发电功率的变化趋势,部分时段预测结果优于SVM.图8给出了二者在雨天的预测误差对比,SVM在上午和傍晚的预测误差明显高于本文模型.
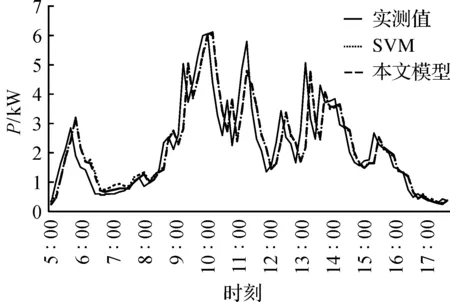
图7 雨天发电功率预测曲线Figure 7 Forecast curve in rainy day

图8 雨天预测误差曲线Figure 8 Forecast error curve in rainy day
多云条件下光照成为影响光伏发电的主要因素,受风力的作用,云层的厚度及位置在不断变动,导致光伏发电功率产生波动.图9给出了本文模型与SVM模型在多云的预测结果对比,本文模型能够很好的预测多云天气的发电功率和变化趋势,SVM在下午的预测曲线不够贴近实测值.图10给出了二者在多云的预测误差对比,SVM在下午的预测误差明显大于本文模型.

图9 多云发电功率预测曲线Figure 9 Forecast curve in cloudy day

图10 多云预测误差曲线Figure 10 Forecast error curve in cloudy day
表1给出了SVM、小波-SVM、Kmeans-SVM和本文模型在晴天、雨天、多云气象条件下预测的平均绝对百分比误差MAPE对比,表2给出了四个模型均方根误差RMSE对比.
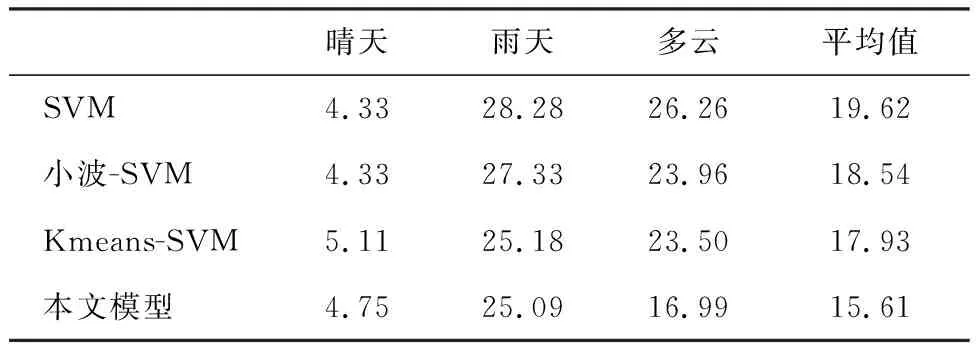
表1 四种模型MAPE值

表2 四种模型RMSE值
从表1对比可知:本文Stacking-SVM模型在多云情况下预测性能突出,其MAPE比SVM降低约9%,比小波-SVM和Kmeans-SVM降低约6%;Stacking-SVM模型在雨天的MAPE也有一定程度的降低;Stacking-SVM模型在晴天的MAPE与SVM和小波-SVM相差0.42%,晴天的预测精度较高,本文模型与其他模型的差距并不明显.从表1四个模型的MAPE平均值对比和表2四个模型的RMSE平均值对比可看出,本文Stacking-SVM模型优于其他三个模型.
综合上述对比得出,本文Stacking-SVM模型在气象环境小幅波动的多云条件下预测性能较为突出,在气象环境剧烈波动的雨天有明显优势,在气象环境稳定的晴天与其他预测模型差距不大.
4 结 语
进行光伏发电预测对维护电网安全稳定,协调可再生能源与化石能源的使用有着重要的意义.本文借鉴集成学习的思想和方法,使用Stacking算法对单一SVM模型进行改进.使用Kmeans算法对训练样本聚类,减少其他类别样本训练次级学习器对预测精度的影响.通过实际数据验证,分别在平稳和突变气象条件下分析光伏发电功率预测情况,结果表明本文提出的预测方法明显优于传统的预测方法,具有一定的工程应用潜力.
猜你喜欢
环球时报(2022-06-15)2022-06-15
疯狂英语·新读写(2021年8期)2021-11-05
科学大众(2021年9期)2021-07-16
科学家(2021年24期)2021-04-25
作文周刊·小学一年级版(2020年20期)2020-09-02
作文小学中年级(2018年6期)2018-06-28
小学生作文·小学低年级适用(2016年4期)2017-01-16
小朋友·聪明学堂(2009年10期)2009-10-20
