
Flink的并行Apriori算法设计与实现
2018-07-12 06:21倪政君夏哲雷
中国计量大学学报 2018年2期
倪政君,夏哲雷
(中国计量大学 信息工程学院,浙江 杭州 310018)
聚类、分类、关联规则等是从大量数据中发现有价值信息的数据挖掘算法.其中关联规则挖掘是数据挖掘的重要研究方向,主要研究从事务数据库、关系型数据库或数据仓库等海量数据的项集之间发现有价值的频繁出现的数据项集合[1].
关联规则挖掘拥有诸多算法,如Apriori[2]、Eclat[3]、FP-Growth[4]等,大多数的关联规则算法都是通过扫描数据用于找到频繁项集.Apriori算法会对每一个候选项集进行数据扫描判断是否是频繁项集,并通过维度数较低的k项集迭代生成维度数较高的k+1项集,最终获得所有的频繁项集.Apriori的原理和实现都较为简单,因此在数据挖掘中得到大量应用,但是当处理大数据量的数据集时,单机串行处理的Apriori算法的挖掘速度会出现下降.因此有些研究人员提出了如CD、DD和CaD等并行Apriori算法[5],并行Apriori算法同时通过多台机器进行并行计算,能够处理大数据量的数据集,但此类并行Apriori算法的实现较复杂,实现成本较高,并且有诸如同步、数据复制等问题.因此,现有的并行Apriori算法都采用一些成熟的并行计算框架和平台进行实现,如现在广泛应用的MapReduce计算框架[6],MapReduce中键值对模型和Apriori算法匹配度较高.Apriori算法的每一次迭代都可以使用键值对的形式进行数据传递,所以Apriori算法在MapReduce上进行并行计算设计会较为简单.Hadoop是实现MapReduce计算框架最佳的开源平台之一[7],具有开源、稳定性高、性能优秀等优点,因此在Hadoop上出现了如MRApriori[8]等并行Apriori算法.但是基于Hadoop平台的并行Apriori算法存在一些限制,Hadoop平台将每一次迭代后的结果都存储到基于硬盘的hdfs,然后在下一次迭代时从hdfs读取数据,如此会产生大量的I/O读写,造成算法挖掘速度的下降.而基于弹性分布式数据集架构的Spark平台[9]解决了此类问题,在每一次迭代结束时存储迭代的中间结果到内存并直接提供给下一次迭代进行读取,从而避免了硬盘的I/O消耗,使得算法的挖掘速度得到提高,如基于Spark的YAFIM算法[10].然而Spark平台中新的迭代只能在更早的迭代都执行完毕生成结果后才能执行,会造成一定的时间延迟,从而算法的挖掘速度受到限制.
Apache公司的Flink平台[11]使用完全基于流处理的结构解决了这一问题,一个新的迭代可以只获得部分结果就可以开始计算,避免了迭代延迟,并且同样使用内存对迭代的中间结果进行存储,使得算法的挖掘速度得到提高.
本文使用Flink平台对并行Apriori算法进行设计和实现,采用Flink的流处理的结构解决了算法批处理时出现的迭代延迟问题,并且将迭代后的结果存储到基于内存的缓存当中,从而降低了迭代时的I/O消耗,提高了算法并行计算下的挖掘速度.在机器集群上进行测试的结果表明,本文提出的基于Flink平台实现的并行Apriori算法对大数据处理有着良好的适应能力,并且挖掘速度得到提高.
1 Apriori算法和Flink平台
1.1 Apriori算法
Apriori算法为布尔关联规则挖掘频繁项集的原创性算法,使用一种称为逐层搜索的迭代思想,其中k项集用于探索k+1项集.Apriori算法的迭代过程如下:
若为第一次迭代,则只是扫描事务数据从中获得频繁1项集,将其存储.第一次迭代结束.
第2次迭代将频繁1项集作为输入数据,通过连接操作生成候选项集,并扫描事务数据筛选出频繁2项集.
…
第k+1次迭代,将频繁k项集作为输入数据,通过连接操作生成候选项集,并扫描事务数据筛选出频繁k+1项集.直到迭代无法再产生频繁项集,算法迭代结束.
传统的Apriori算法采用批处理的方式进行迭代,每一次迭代的输入数据都依赖于上一次迭代产生的中间结果,即频繁项集.在接收到上一次迭代完整的频繁项集之后,新的迭代采用连接操作,将频繁项集进行交叉组合并去重,产生新的候选项集,并对产生的候选项集进行支持度统计筛选出频繁项集,作为下一次迭代的输入数据.
可见,批处理的迭代方式存在迭代延迟现象.只有当上一次的迭代完成之后,才能进行新的迭代,会使得上一次迭代产生的部分中间结果处于等待的状态,无法进行下一次的迭代.
当采用流处理对迭代进行实现时,可在只接收到部分中间结果的情况下也可以进行连接产生新的候选项集,并对产生的候选项集进行实时的支持度统计筛选频繁项集.当有新的部分中间结果再次输入时,连接操作可以增量更新候选项集,从而避免了迭代延迟现象.
1.2 Flink平台
Apache公司的Flink平台是一个面向分布式数据流处理和批数据处理的开源云计算平台,针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能.其中统一的批处理和流处理系统极为重要.Flink完全基于流处理,作为流处理看待时输入数据流是无界的,而作为批处理看待时输入数据流被定义为有界的.所以当对关联规则等批处理的算法进行执行时,实际上调用的是有界输入数据流的流处理功能.而基于流处理进行迭代时,只需要上一次的迭代生成部分结果就可以进行下一次迭代,从而可以减少时间开销.
2 基于Flink的并行Apriori算法
2.1 算法设计
并行Apriori算法主要计算量集中在迭代生成频繁项集过程中,其它步骤的计算量相对较小.因此,基于Flink的并行Apriori算法的关键是实现迭代生成频繁项集过程.Apriori算法本身的迭代机制和MapReduce计算模型非常契合,并且Flink平台也支持MapReduce进行实现.因此,本文在Flink平台下使用MapReduce计算模型对并行Apriori算法进行设计.
算法的设计如图1,基于Flink的并行Apriori算法初始数据经过划分子数据之后,分别输入到各个Map当中,并生成

图1 算法设计Figure 1 Algorithm design
2.2 算法实现
本文提出了使用Flink平台来实现Apriori算法,使用Flink的内存缓存和流结构的批处理等方法,解决了用Hadoop平台实现存在的I/O消耗大和用Spark平台实现存在的迭代延迟问题.Flink实现Apriori有两个步骤.
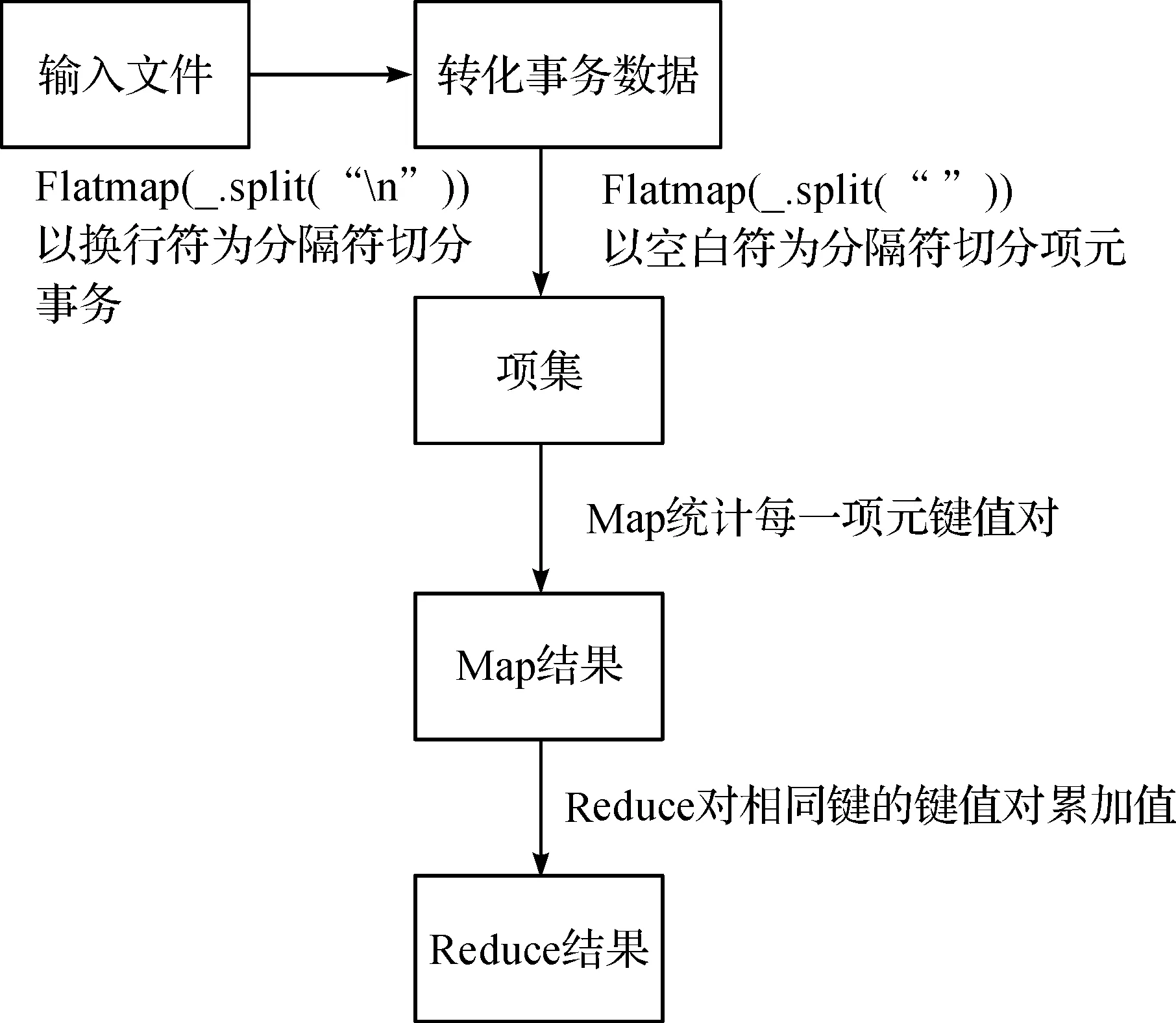
图2 频繁1项集生成Figure 2 1-frequent itemset generation
步骤一实现过程如图2:首先从分布式文件系统拿到输入文件,一般是以文本文件的格式输入.将文本中的数据先后用换行符和空白符进行分割,得到适合算法进行迭代的数据格式.下一步按照MapReduce的过程进行执行,最终可以得到所有的频繁1项集.最后将得到的所有频繁1项集依然以键值对的形式进行存储,在Flink中可以存储到Flink缓存当中,而Flink的缓存是基于内存的,故而在步骤二中读取输入数据时可以节省一定的I/O开销.
步骤二实现过程如图3:首先从从缓存中拿到键值对形式的频繁1项集,然后进行连接操作生成候选项集,并建立哈希索引树用于查询候选项集是否在事务数据当中.若在事务数据当中,则输出Map结果

图3 算法迭代Figure 3 Algorithm iteration
本文提出的Flink平台下并行Apriori算法的实现,使用MapReduce计算框架对算法进行设计,避免了并行算法的实现复杂度,使得算法在大数据环境下有着良好的适应能力.并且,在算法实现过程中使用Flink内存缓存迭代结果和Flink流处理结构避免了I/O消耗过大和迭代延迟等问题,使得在迭代次数较多和迭代输出结果较多的情况下,算法的挖掘速度得到提高.
3 实验分析
3.1 实验环境搭建
本文搭建了三台机器的Flink集群进行实验,其中有一个master节点和2个slave节点,每个节点都是CPU为I5 4590,8 G内存的机器,并且是操作系统为Centos6.4和Flink版本为0.9.1的软件环境.
实验用的数据集是FIMI存储库(http://fimi.ua.ac.be/data/)提供的webdocks事务数据集,此数据集是爬虫抓取的并经过处理后公开的网页文档数据.数据集事务条数为169万.本文在此数据集的基础上将此数据集分割成50 MB、100 MB、150 MB、200 MB、250 MB、300 MB、500 MB等块数据集.
3.2 算法实现分析
本文采用加速比、数据伸缩率和扩展率对实验结果进行评价.其中加速比代表着当算法采用机器集群实现时,相比较于算法单机实现的时性能提高速率,等于算法单台机器的串行处理时间除以机器集群的并行处理时间,当加速比呈现线性增长时代表着该算法拥有较好的并行计算性能;数据伸缩率代表着随着数据规模的变大,并行算法处理相应规模数据所花费时间的变化情况,当数据伸缩率呈现线性时,代表着算法可以随着数据规模的变化,依然具有较好的计算能力;扩展率用来查看随着机器规模增加时,并行算法处理能力的变化情况.
加速比分析:算法的加速比实验结果如图4,图4中横坐标是数据集大小,采用50 MB到500 MB的区间,纵坐标是算法在单机情况和3台机器的集群情况下的加速比.从图4可以看出算法的加速比总体上是接近线性的.因为Flink集群的启动和通信需要一定时间,所以当数据集较小的时候,并行Apriori算法启动时间占总时间的比例较大,此时算法的加速比性能不是很好.而当数据集规模变大,算法的加速比性能越来越好,并呈现线性增长,说明基于Flink实现的并行Apriori算法具有良好的加速比,算法的运行性能有良好的提升空间.

图4 加速比Figure 4 Acceleration ratio
数据伸缩率分析:算法的数据伸缩率实验结果如图5,图5中横坐标是数据集与最小数据集的比值,纵坐标是数据集处理时间与最小数据集的处理时间的比值.从图5可以看出,在Flink集群上的Apriori算法的执行时间是随着数据集的规模同时增加的,说明算法可以有效应用于大规模数据处理.
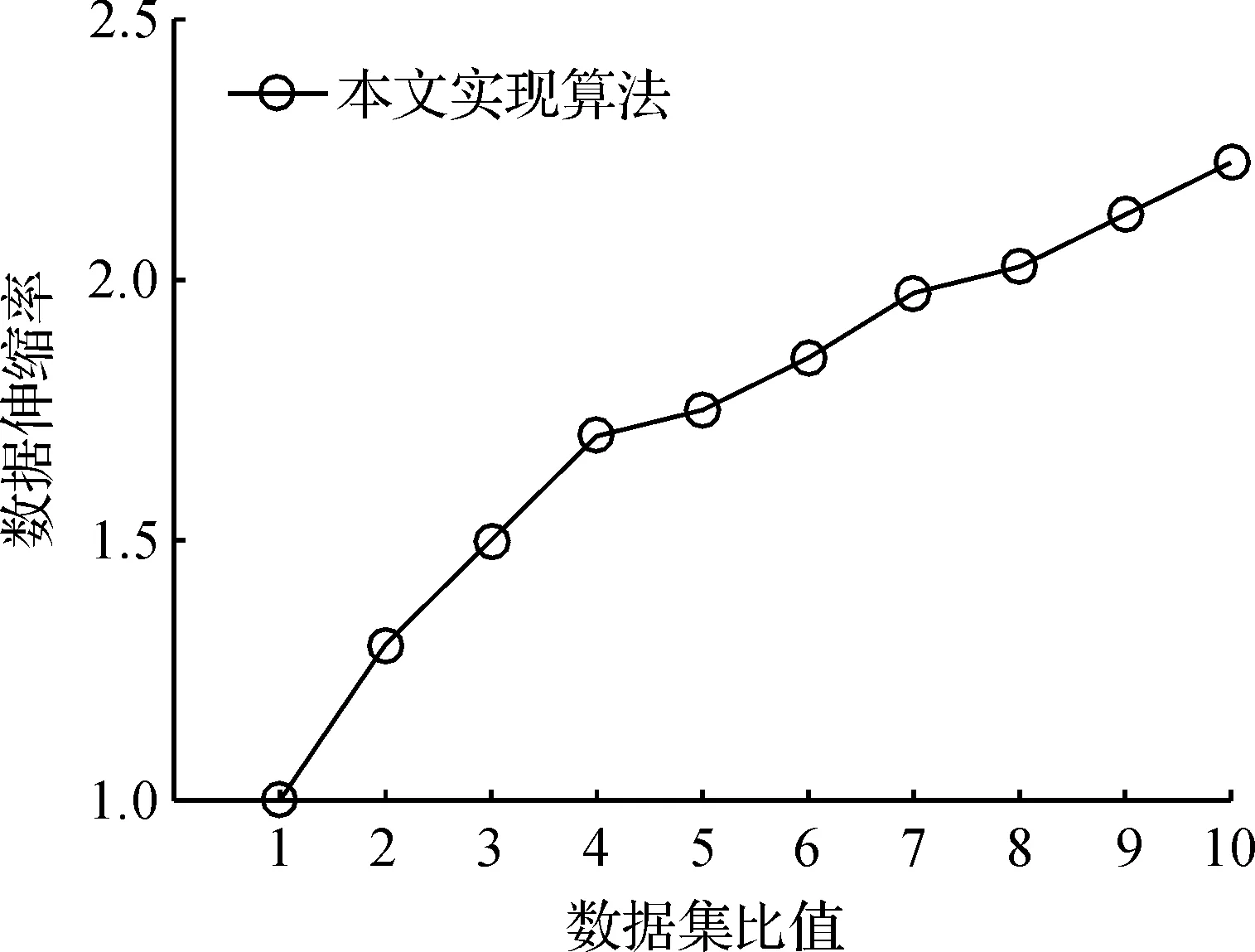
图5 数据伸缩率Figure 5 Data scalability
扩展率分析:算法的扩展率实验结果如图6,图6中横坐标是集群的机器台数,纵坐标是加速比.从图6可以看出,在Flink集群上的Apriori算法随着集群机器台数的增加,加速比也呈现线性增长,可以看出机器台数的增加能够明显提高挖掘效率,体现了并行算法良好的扩展性.
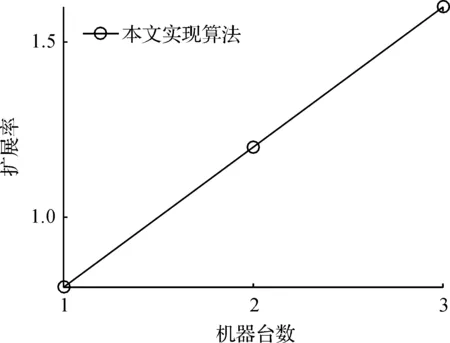
图6 扩展率Figure 6 Expansion rate
由以上实验可以看出,本文基于Flink平台实现的Apriori算法具有良好的性能提升空间和扩展能力,能够适应大数据量的挖掘.
3.3 算法性能对比
本文将基于Flink实现的并行Apriori算法和在Spark平台上的YAFIM算法在webdocks数据集上进行速度性能评估,支持度设为0.25,算法在此支持度上需要进行迭代的次数较多并且将生成较多的迭代结果.
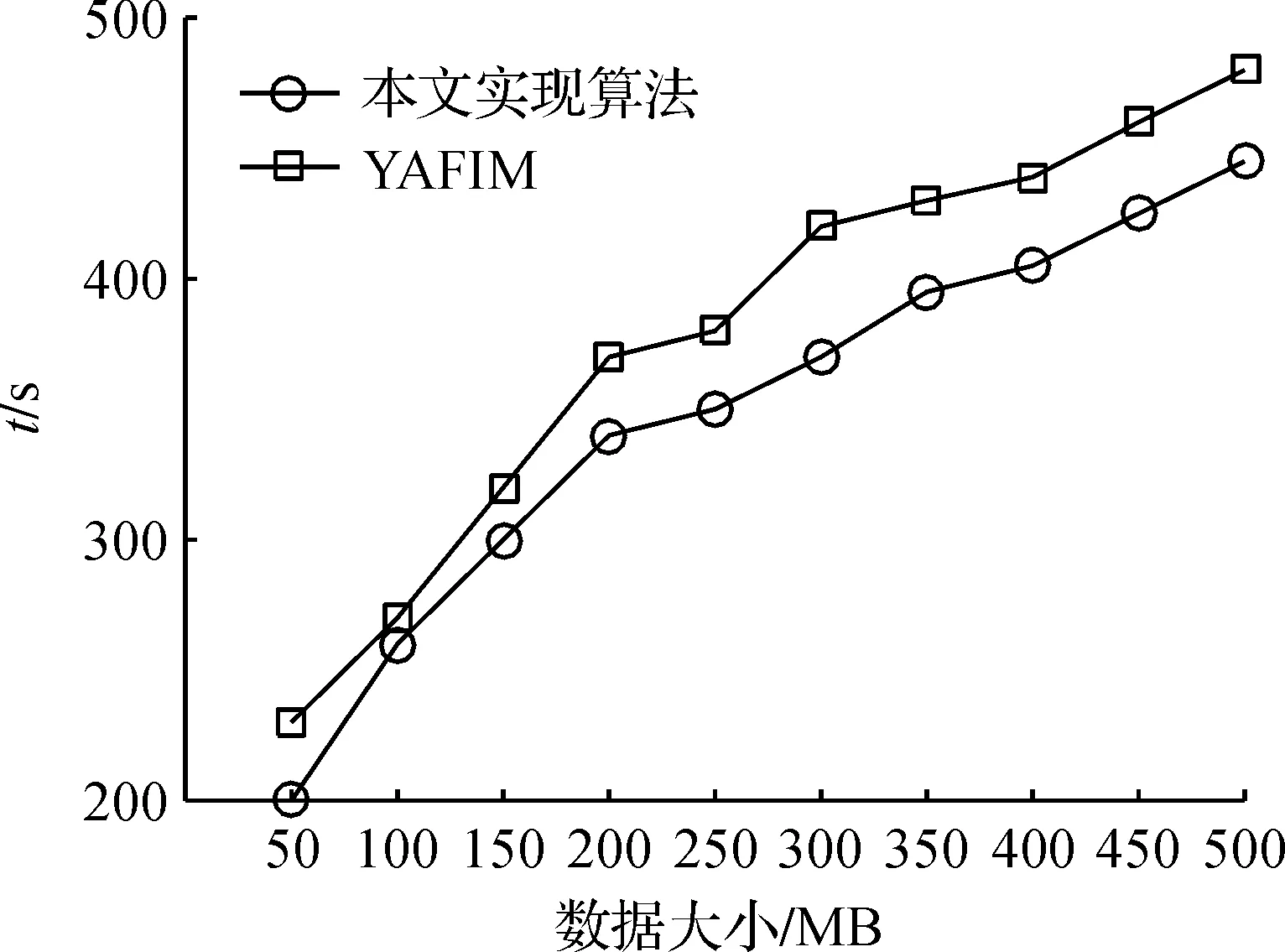
图7 算法性能对比Figure 7 Algorithm performance comparison
从图7可以看出,在数据集较小的情况下,两个算法的挖掘速度相差不多,是因为数据集较小时,所需要迭代的次数和时间都较少,而随着数据集数量的增长,迭代次数和迭代时间也随之增长,此时本文基于Flink平台的算法的挖掘效率得到提高,在迭代次数和迭代结果较多的情况下挖掘速度要快于基于Spark平台的YAFIM算法.可见,基于Flink平台实现的并行Apriori算法的挖掘速度得到提高.
4 结 语
本文基于Flink平台对并行Apriori算法进行设计和实现,通过MapReduce计算框架进行设计,并采用Flink流处理结构和内存缓存提高了算法挖掘速度.通过实验可见本文实现的算法能够适应大数据量的挖掘,并且拥有较快的挖掘速度.
猜你喜欢
科学导报·学术(2020年84期)2020-11-08
电脑爱好者(2020年18期)2020-09-26
电脑爱好者(2019年1期)2019-10-30
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
电脑爱好者(2017年18期)2017-11-03
电脑爱好者(2017年9期)2017-06-01
计算机与数字工程(2017年2期)2017-03-02
网络与信息(2009年9期)2009-10-30
计算机应用文摘·触控(2009年15期)2009-09-27
