
样本增强的人脸识别算法研究
2018-07-12 06:38章东平
中国计量大学学报 2018年2期
张 坤,章东平,杨 力
(中国计量大学 信息工程学院,浙江 杭州 310018)
基于深度卷积神经网络的人脸识别算法的性能在最近几年已经得到了很大的提高.这些提高一方面来源于新的以及改进的网络结构设计,而另一方面则来源于规模越来越大的人脸数据集.
当研究者认识到通过增加训练数据可以为卷积神经网络带来性能的提升后,很多研究者和研究机构开始收集和标注大量的人脸图像作为训练数据.Facebook的研究人员[1]标注了4.4百万的人脸去训练他们的人脸识别模型,牛津大学的研究团队[2]使用了2.6百万的人脸图像,Face++[3]在5百万标注好的人脸数据上训练他们的模型.值得注意的是,谷歌的FaceNet[4]人脸识别模型则使用了200百万的有标注人脸图像.
然而收集并且标注大量的用于训练的人脸数据并不是一件轻松的事情,它需要花费大量的人力物力去下载、处理和标注数以百万计的人脸图像,并且要求在标注时保证很高的可信度.因此,只有较大的商业公司才有能力收集标注百万量级的人脸数据,并且,这些商业公司标注好的人脸数据并不会公开给其他研究团队使用.就目前的情况来看,CASIA-WebFace[5]是当前公开的最大的免费人脸识别数据集.CASIA-WebFace数据集包含10 575个人的共约49.5万的人脸图像,然而和上文提到的几个人脸识别数据集相比,在规模上还是有很大差距.并且,对于基于深度学习的人脸识别算法,需要的训练人脸数据,不仅要求其类别数达到一定规模,而且还要其每个类别中人脸图片具有多样性,这对数据收集来说又是一个很棘手的问题.
为充分利用有限的人脸识别数据资源,本文尝试通过两种样本增强的方式来解决上述提到的样本不足的问题.一是根据单张人脸图像生成该人不同姿态的人脸图像,二是为每张人脸图像戴上不同的眼镜.
1 多姿态人脸图像生成
1.1 多姿态人脸图像生成原理
为了通过单张人脸图像生成其对应的各个姿态人脸图像,本文借助Patrik Huber等人[6]在2016年提出的三维可形变人脸模型(3DMM)来实现.三维可形变人脸模型基于人脸的三维网格,一张人脸由一个包含形状的x,y和z分量的向量SεR∂N和一个包含每个顶点RGB颜色信息的向量表示TεR∂N,N是网格顶点的数量.三维可形变模型由两个PCA模型组成,一个用于形状,另一个用于颜色信息.
构建该三维可形变人脸模型共使用了169个人的三维人脸扫描图像,其中19岁以下的有9个人,20~29岁的有106个人,30~44岁的有33个人,45~59岁的有13个人,大于60岁的只有8个人.
通过单张人脸图像重建其三维人脸模型有以下几个关键步骤:1)姿态估计;2)形状拟合;3)纹理重建.
1)姿态估计.这里的姿态估计也是指求解摄像机矩阵(camera matrix),获得二维图像与三维图像间的对应关系.根据在二维人脸图像上检测到的关键点与三维人脸图像上与其对应的关键点的坐标信息,求得摄像机矩阵.求解方法使用Hartley和Zisserman在2004年提出的Gold Standard算法.
2)形状拟合.为找到PCA形状模型中最合适的系数,通过最小化E来求解得到
(1)

3)纹理重建.通过1)、2)得到摄像机矩阵和形状系数后,则输入人脸图像和三维网格间的对应关系可以得到.之后,可将二维人脸图像重映射到三维人脸模型上,最终得到完整的三维人脸.
1.2 多姿态人脸图像生成结果
应用上节所述方法,我们对CASIA-WebFace数据集进行了姿态方面的数据增强.对于单张人脸图像,我们分别生成了其偏航角±30°,±45°,俯仰角±30°,±45°的人脸图像.效果如图1.
在图1中,(a)为原始人脸图像;(b)为与(a)对应偏航角为+30°的人脸图像;(c)为与(a)对应偏航角为+45°的人脸图像;(d)为与(a)对应偏航角为-30°的人脸图像;(e)为与(a)对应偏航角为-45°的人脸图像;(f)为与(a)对应俯仰角为-30°的人脸图像;(g)为与(a)对应俯仰角为-45°的人脸图像;(h)为与(a)对应俯仰角为+30°的人脸图像;(i)为与(a)对应俯仰角为+45°的人脸图像原始CASIA-WebFace数据集包含494 414张人脸图像,其中有一些人脸图像因无法检测到人脸和人脸关键点,无法完成多姿态人脸的生成.最终,原始数据与进行姿态增强后的数据共有1 281 005张人脸图像.

图1 多姿态人脸生成效果图Figure 1 Multi-pose face generation
2 戴眼镜人脸图像生成
2.1 戴眼镜人脸图像生成方法
根据原始人脸图像,生成其对应的“戴眼镜”人脸图像,需要使用到人脸检测,人脸关键点定位技术.本文使用开源的MTCNN[7]算法进行人脸检测和人脸关键点定位.下面给出具体的操作步骤.
1)使用MTCNN算法检测目标人脸在原始图像中的位置.
2)使用MTCNN算法定位目标人脸的五个关键点.这五个关键点分别为(左眼中心,右眼中心,鼻尖,左嘴角,右嘴角),设其对应坐标分别为(x1,y1),(x2,y2),(x3,y3),(x4,y4),(x5,y5).
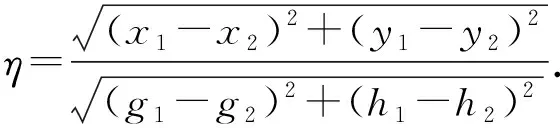

5)将4)得到的经过缩放旋转后的眼镜图片与原始人脸图片进行叠加(对齐眼镜中心位置),即可得到“戴眼镜”后的人脸图像.
2.2 戴眼镜人脸图像生成结果
本文收集了四种眼镜样本,对CASIA-WebFace数据集进行数据增强.效果如图2.在图2中,(a)为原始人脸图像,(b)、(c)、(d)、(e)分别为戴不同眼镜生成的人脸图像.
3 实验验证
3.1 实验数据集
CASIA-WebFace数据集[5].CASIA-WebFace数据集是由中科院自动化研究所的李子青团队在2014年收集整理完成的,它包含10 575个人的494 414张人脸图像.

图2 戴眼镜人脸图像生成效果Figure 2 Face generation with glasses
LFW数据集[8].LFW为英文Labeled Faces in the Wild的缩写,该数据集包含5 749个人的13 233张人脸图像.为了方便公正的在LFW数据集上比较不同人脸识别算法的优劣,有两种较为常用的评比规则.1)标准规则.5 749个人的13 233张人脸图像被随机组成了6 000对人脸图像对,其中3 000对由相同人组成,剩余3 000对为不同人组成.评测时,计算准确率.2)BLUFR规则[9],BLUFR为英文Benchmark of Large-scale Unconstrained Face Recognition的缩写.BLUFR评测准则充分利用了LFW数据集的13 233张人脸图像,将其划分为了十个部分,每一部分包含156 915对相同人样本对,46 960 863对不同人样本对.另外,BLUFR规则,可以同时提供验证和开集识别测试指标.为后文行文方便,记标准规则为准则一,记BLUFR规则为准则二.
YTF数据集[10].YTF为英文YouTube Faces的缩写.YTF数据集包含1 595个人的3 425段视频,这些视频全部来自国外视频网站YouTube,平均每个人有两段视频.在这些视频片段中,最短的只有48帧,最长的为6 070帧,平均每段视频为181.3帧.为了方便测试,YTF数据集将所有数据有重叠的划分为十个部分.每部分由250个正样本对,250个负样本对组成.因为存在运动模糊以及高压缩率的原因,YTF数据中的人脸质量低于上述两个人脸数据集中的人脸质量.
3.2 网络模型与数据预处理
本文实验所采用的网络模型为开源的Face-ResNet[11],其包含27个卷积层,两个全连接层,使用PReLU[12]作为激活函数.为了检测到图像中的人脸以及准确定位到人脸中的关键点,本文使用上MTCNN算法.在一些图片中,MTCNN算法可能无法成功检测到人脸.对于这些人脸图像,我们丢弃不用,但是这种处理方法,仅限于在训练集中的图片.如果在LFW或者YTF数据集中出现这样的图片,则进行人工标定处理.之后,根据成功定位到的人脸关键点,我们使用上文提到的人脸对齐方法将其矫正为144×144大小的灰度图.最后,在送入网络进行训练时,每个像素值先减去127.5,再除以127.5.
3.3 生成多姿态人脸图像对人脸识别模型性能的影响
我们使用Face-ResNet网络模型训练两个人脸识别模型,分别为Model-Aw,Model-Awp.其区别在于Model-Aw使用原始CASAI-WebFace数据集,Model-Awp使用CASIA-WebFace-pose数据集.
表1使用原始CASIA-WebFace数据集以及经过姿态增强的CASIA-WebFace数据集训练的Face-ResNet模型在LFW数据集上使用测试准则一得到的结果.表2显示了它们使用测试准则二得到的结果.从表1和表2可以看出,经过使用经过姿态增强的训练数据得到的人脸识别模型在LFW数据集上的测试结果均高于使用原始CASIA-WebFace训练的人脸识别模型.
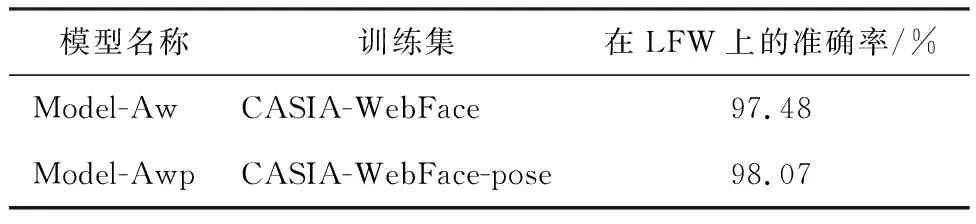
表1 Model-Aw与Model-Awp在LFW上的测试结果(准则一)Table 1 the performance of Model-Aw and Model-Awp on LFW(protocol 1)
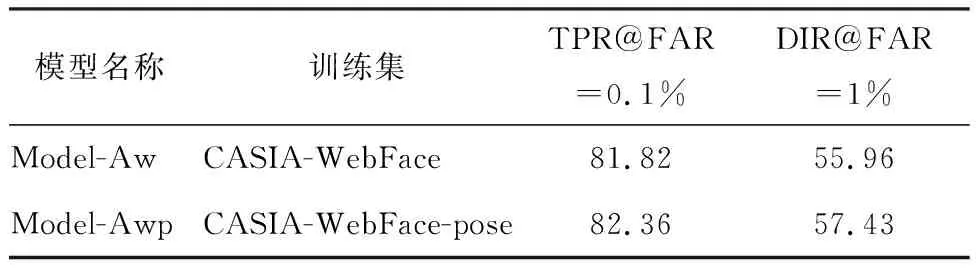
表2 Model-Aw与Model-Awp在LFW上的测试结果(准则二)Table 2 the performance of Model-Aw and Model-Awp on LFW(protocol 2) %

表3 Model-Aw与Model-Awp在YTF上的测试结果Table 3 the performance of Model-Aw and Model-Awp on YTF
表3给出了使用不同训练数据训练的人脸识别模型在YTF数据集上的测试结果,可以看出模型Model-Awp在YTF数据集上的准确率较Model-Aw高0.48%.
3.4 戴眼镜人脸图像对人脸识别模型性能的影响
本节为验证生成的戴眼镜人脸图像对人脸识别模型性能的影响,分别使用不同数据集使用Face-ResNet网络模型训练出得到不同的人脸识别模型.使用原始CASIA-WebFace训练得到的人脸识别模型记为Model-Aw,使用经过“戴眼镜”的人脸识别数据集训练得到的人脸识别模型记为Model-Awg.为验证生成的戴眼镜人脸图像对人脸识别模型性能的影响,我们在公开的LFW数据集、YTF数据集上进行评测.
表4给出了Model-Aw和Model-Awg在LFW测试准则一下的测试结果,表5给出了Model-Aw和Model-Awg在LFW测试准则二下的测试结.表6给出了Model-Aw和Model-Awg在YTF数据集上的表现.

表4 Model-Aw与Model-Awg在LFW上的测试结果(准则一)Table 4 the performance of Model-Aw and Model-Awg on LFW(protocol 1)
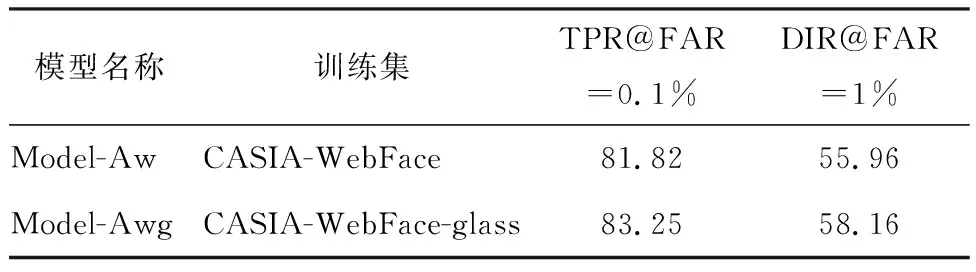
表5 Model-Aw与Model-Awg在LFW上的测试结果(准则二)Table 5 the performance of Model-Aw and Model-Awg on LFW(protocol 2) %
从表4和表5可以看出,对于LFW数据集,无论是测试准则一还是测试准则二,使用CASIA-WebFace-glass数据集训练得到的模型均可得到一定程度上性能的提升.
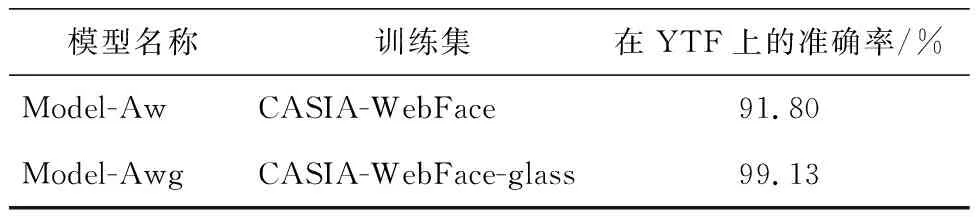
表6 Model-Aw与Model-Awg在YTF上的测试结果Table 6 the performance of Model-Aw and Model-Awg on YTF
从表6中可以看出,使用经过姿态增强的到的CASIA-WebFace-glass数据集作为训练数据,Model-Awg在YTF上的准确率有1.33%的提高.
4 结 语
本文通过两种不同的样本生成方式,扩充了原始CASIA-WebFace数据集.通过公开人脸测试集验证了样本增强的效果.实验结果表明,不同的人脸样本增强方式均会对人脸识别模型的效果有所提升.
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年31期)2020-06-01
文苑(2019年20期)2019-11-16
电子制作(2019年14期)2019-08-20
故事会(蓝版)(2019年6期)2019-06-20
动漫星空(2018年9期)2018-10-26
中国眼镜科技杂志(2017年10期)2017-07-10
电子制作(2017年1期)2017-05-17
