
基于文档摘要的藏文网页消重研究
2018-07-16 12:04李加才让安见才让
电子技术与软件工程 2018年10期
文/李加才让 安见才让
1 引言
藏文网页消重的研究,目的是在互联网上大量的重复性和相似性的冗余信息中消除相同或相似的藏文网页,全面提升搜索引擎的质量并改善用户的浏览体验。所以,高精度而快捷地消除重复网页无疑是提高搜索引擎质量和改善用户体验的关键技术之一。
目前,藏文网页消重的相关文献很少。王海洪和戴玉刚在2009年提出的一种基于编码统一的藏文网页消重技术。主要思想是在藏文编码不统一情况下,无论采用哪一种消除重复页面的方法都是不可能实现的,所以在处理过程中必须首先统一编码。为了进一步探索藏文网页消重领域,本文的以Tf*IDF词频统计算法提取文本特征项,再根据特征项计算文档摘要。对文档摘要求出其信息指纹,信息指纹转换成固定位数的二进制数值并计算其Hamming Distance来求出相似度。最后根据Hamming Distance来消除重复网页和转载网页。
2 藏文网页特征提取
2.1 预处理
在对藏文网页提取特征项之前,还需要做预处理工作,具体步骤是用爬虫软件从网上下载好网页后做识别和清除网页内的噪声内容(如广告、版权信息等)的净化处理,并提取网页正文。之后对提取好的网页正文内容需要做文本分块处理。对于在原文中没有实际含义或不是关键词的停用词,如藏文中的等等做过滤处理。停用词在计算Tf*IDF时并不能用作特征项来计算,因此分词完成后和预先消除分词结果中个的停用词。对于爬虫软件下载的所有网页都执行上述预处理步骤,这样便于后续操作的高效率运行。
2.2 Tf*IDF计算
Tf*IDF(Term Frequency * Inverse Document Frequency)算法是一种用于资讯检索与资讯探勘的常用加权技术。其原理是用统计方法评估一个词条对于一个文档的重要程度。Tf*IDF算法作为一个从文档中提取能代表该文档的特征的算法,它的任务就是要将信息量小,“不重要”的词汇从特征项空间中删除,从而减少特征项的个数,降低特征项空间的维数。
Tf*IDF算法中的 Tf(Term Frequency)表示某个词条在某个藏文网页文档中出现的频率。

在公式(1)中所求的是某个词条在藏文网页文档中的Tf值,其中分子nij表示词条i在文档j中出现的次数;分母表示在文档j中出现的所有词条之和。
IDF(Inverse Document Frequency)表示如果包含某个词的藏文网页文档越少,则这个词的区分度就越大,IDF就越大。
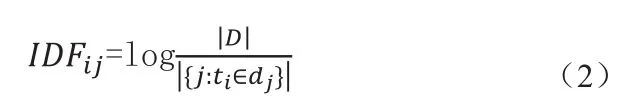
在公式(2)中所求的是藏文网页文档总数与包含词条i的藏文网页文档数的比值即IDF值,其中分子|D|表示语料库中藏文网页文档总数,分母|{j:ti∈dj}|表示包含词条ti的藏文网页文档数j的值。如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用 |{j:ti∈dj}|+1。
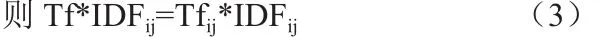
对于如何获取一个藏文网页文档的特征项,我们可以计算公式(3)得到Tf*IDF,Tf*IDF越大,则说明这个词条对这个藏文网页文档的区分度就越高,取Tf*IDF值较大的几个词条,就可以当做这个藏文网页文档的特征项集合。
3 藏文网页文档摘要自动提取
藏文自动摘要是利用计算机自动编写文摘的应用技术,能够通过藏文网页自动文摘技术将网页上较长的文本数据压缩成一段几百个字左右、能大体代表文本原意的摘要。
IBM公司的H.P. Luhn提出的提出了一种基于词频统计的自动摘要算法,其原理是利用算法找出那些包含信息最多的句子,而句子的信息量可用“关键词”来衡量。Luhn提出用"簇"(cluster)表示关键词的聚集,所谓"簇"就是包含多个关键词的句子片段。
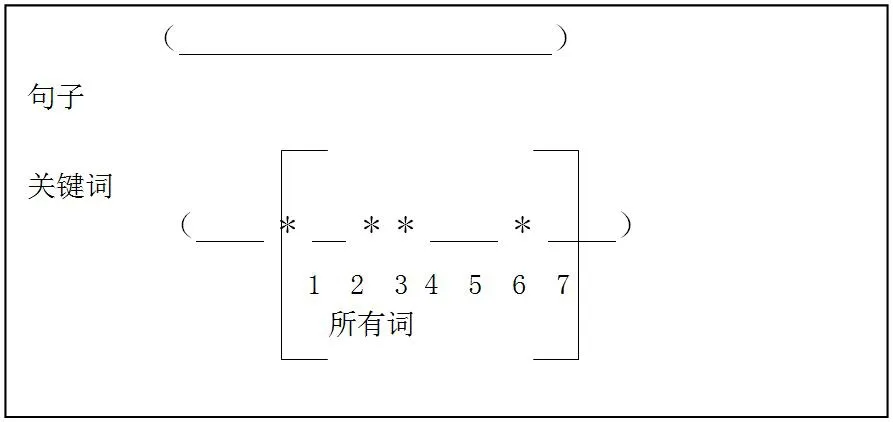
图1:“簇”图
如图1所示,被框起来的部分即为一个“簇”。“__”表示普通词条,“*”表示关键词。当在一条句子中包含了多个关键词,那么这个包含多个关键词的句子片段称之为“簇”。可设一个阈值,Luhn建议的阈值是4或5。也就是说,如果两个关键词之间有5个以上的其他词,就可以把这两个关键词分在两个簇。在本文中特用事先计算好的Tf*IDF特征项来代替关键词,这样就变成了包含特征项的句块为“簇”。
对于每个“簇”,可计算其权值。如公式(4)所示:

其中wij表示包含特征项i的“簇”j的长度,分子中tij表示在“簇”j中包含特征项i的数量,tij的二次幂即分子。分母jlenght表示“簇”j的长度。
比如:如图1所示,“簇”1共有7个词条,其中4个为特征项。
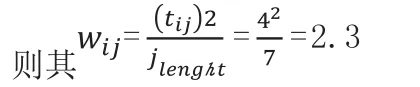
最后,找出包含权值最高的“簇”的句子(比如5句),把他们合在一起,就构成了一个文档的自动摘要。
4 摘要信息指纹计算
产生信息指纹的关键算法是伪随机数产生器算法(PRING)。最早的PRING算法是由计算机之父冯诺伊曼提出来的。他的办法非常简单,就是将一个数的平方掐头去尾,取中间的几位数。比如一个四位的二进制数 1001(相当于十进制的9),其平方为01010001(十进制的81)掐头去尾剩下中间的四位0100。当然这种方法产生的数字并不很随机,也就是说两个不同信息很有可能有同一指纹。现在常用的 MersenneTwister 算法要好得多。
本文用Visual Studio C#语言来编程,对藏文网页摘要计算的信息指纹是传统Hash计算,同过string类库的GetHash()方法得到一串伪随机数,并将该伪随机数转换为固定位数的二进制数值作为其新的信息指纹。对于二进制信息指纹则可以通过Hamming Distance来计算藏文网页文档相似度,最后可通过相似度计算来判断哪些网页是近似重复网页。
5 相似度计算
5.1 Hamming Distance计算
Hamming Distance即海明距离,两个码字的对应比特取值不同的比特数称为这两个码字的海明距离。计算海明距离可对要比较的两串信息指纹进行异或(xor)运算,并计算出异或运算结果中1的个数。例如110和011这两个位串,对它们进行异或运算,其结果是:

异或结果中含有两个1,因此110和011之间的汉明距离就等于2。
计算两篇藏文网页信息指纹的海明距离也是类似,对另个藏文网页固定位数的二进制信息指纹做异或运算,并统计出1的个数即可求得两篇藏文网页的海明距离。
5.2 藏文网页相似度计算
在求得两篇藏文网页的海明距离后,至于相似度的计算可通过公式(5)完成。

最后关于消重计算,可根据海明距离设置一个阈值。例如,当两篇网页的海明距离小于3时,可判断这两篇网页是转载的或重复的,即可处理消重工作,在数据库中只保留一篇网页。
6 结语
本文根据藏文网页的特征结构提取文档摘要,对文档摘要计算其信息指纹并将其转换成固定位数的二进制数值,对二进制数值计算海明距离。根据海明距离可计算相似度,又可设置阈值判断该藏文网页是否重复或转载网页。经测试,本文研究的消重算法虽然准确率差强人意,还需进一步探索研究。但是算法整体简捷快速,时间复杂度较低,查全率较高。适用于在处理复杂的搜索引擎工作时粗略地计算网页消重工作,对搜索引擎的整体运算而言在不拖延计算时间的同时却又能显著的提高其性能。
猜你喜欢
小学生学习指导(高年级)(2022年3期)2022-03-29
布达拉(2020年3期)2020-04-13
西夏学(2019年1期)2019-02-10
西藏大学学报(自然科学版)(2016年1期)2016-11-15
知识经济·中国直销(2016年5期)2016-11-07
知识经济·中国直销(2016年4期)2016-11-07
新闻传播(2016年17期)2016-07-19
知识经济·中国直销(2016年10期)2016-02-27
故事林(2015年5期)2015-05-14
故事林(2015年3期)2015-05-14
