
基于农业网络信息分类的热词自动提取方法
2018-07-28 03:18段青玲刘怡然王沙沙
农业机械学报 2018年7期
段青玲 张 璐 刘怡然 王沙沙
(1.中国农业大学信息与电气工程学院,北京 100083; 2.北京农信通科技有限责任公司,北京 100081)
0 引言
随着农业网站数量的迅速增长,提取农业网络热点信息对于实时监测和分析农业舆情,引导农业产业结构,维护社会稳定具有重要意义。热词是反映一个时期内热点问题的一种词汇现象,农业热词则反映了一个时期内涉农用户群体所关注的热点事件。例如,农业热词“蒜你狠”、“糖高宗”等反映了部分农产品价格居高不下和消费者心理不满的现象。因此,通过提取农业网站热词可以及时掌握农业行业发展动向、实时监测农业网络信息动态,利于相关部门进行正确的舆论引导和分析。
近年来,热词提取方法主要有基于规则过滤的方法[1-3]、基于热词数据库构建的方法[4-5]和基于热度权值排序的方法[6-9]。基于规则过滤的方法通过选择多个过滤特征构造判定规则,去除大量无关信息,再利用词频等设计热词抽取算法,获得热点信息,该方法中过滤特征的选择和判定规则中阈值的确定比较困难。基于热词数据库构建的方法通过构建待提取热词主题数据库,结合大数据分析技术[10-12]以及维度划分技术[13],找出该主题下的热词,该方法提取出的热词很大程度上依赖于热词数据库的构建。基于热度权值排序的方法通过命名实体识别技术[14-15]或新词识别技术[16-17]获得热词候选词,再结合热词特点,进行候选词热度计算,热度值排在前列的候选词即为热词,但目前该方法中候选词提取和热度计算考虑的因素均具有单一性。
农业领域涵盖面广,涉及种植业、养殖业等多个产业,具有不同的用户群体和管理部门,现有的热词提取方法应用到农业中无法满足不同产业用户群的个性化需求。因此,本文将文本分类技术与热词自动提取技术相结合,针对每个农业产业类别分别提取热词,挖掘不同用户群体和农业管理部门所关注的信息热点,确保不同产业用户快速获取本产业信息动态。在热词自动提取方法中,针对目前该项研究中提取的热词词性单一等问题,提出基于信息熵的热词候选词提取方法和基于时间变化的热度计算方法。本文所述方法采用农业网站上的数据进行验证。
1 材料和方法
本文研究目标是根据农业用户的个性化需求,有针对性地为各用户提供农业网络热点信息。基于该领域现有的研究过程,本文提出基于农业网络信息分类的热词自动提取方法,流程如图1所示。

图1 基于农业网络信息分类的热词自动提取方法流程Fig.1 Automatic extraction process of hot words based on agricultural network information classification
首先采用信息自动抽取技术获取网页上的农业文本信息;其次根据用户需求设定分类类别,采用多标记分类方法进行文本语料分类;再采用基于信息熵的方法针对各类别分别提取热词候选词,并进行单日词频统计;为从候选词中挑选出热词,最后提出基于时间变化的方法计算候选词热度,将热度排在前列的候选词作为该类别的热词。
1.1 文本语料采集
本文通过信息自动抽取技术从中国农业信息网、搜猪网、中国农资网、中国三农网、中国水产养殖网、中国农机网、中国棉花交易网等农业网站获取2017年6月9—16日的农业文本信息作为实验语料。
1.2 文本语料分类
对采集到的农业文本语料采用多标记分类算法进行分类,再针对每个类别分别提取热词。多标记分类[18-20]是指一个对象可以同时划分到多个类别中。例如,一个介绍西红柿的文本,可以同时划分到种植业和农产品市场两个类别中。对农业文本信息进行多标记分类,符合信息同时具有多个标记的实际情况,利于相关行业人员查询更为完整的信息资源。
农业文本多标记分类的处理流程主要包括:文本语料预处理和分类词库构建阶段、模型训练阶段以及测试阶段,如图2所示。
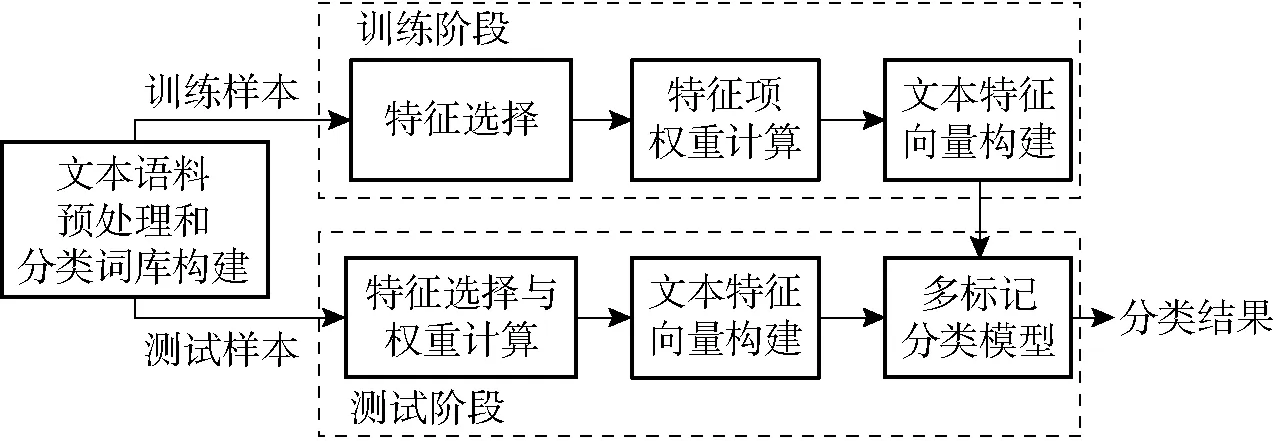
图2 农业文本多标记分类流程Fig.2 Multi-label classification process for agricultural texts
1.2.1文本语料预处理和分类词库构建
中文文本的预处理包括分词、词性标注、去停用词3个步骤。采用NLPIR汉语分词系统包(参考http:∥ictclas.nlpir.org/downloads)对实验语料进行分词[21],同时标注出词性[22]。停用词[23]主要是指使用十分广泛但实际意义不大的词,本文根据停用词表去除停用词。根据《国民经济行业分类与代码》[24]构建农业分类词库。
1.2.2特征选择与权重计算
文本特征选择是指从文本中选取代表性的特征项来表示整个文本信息。本文采用基于分类词库的方法进行文本特征选择。首先通过计算文档频率进行特征选择,然后通过分类词库对特征集合进行扩充。文档频率DF(Document frequency)的计算公式[25]为
(1)
式中TF(Fj)——特征词Fj在语料集上的频率
A——语料集的总样本数
本文根据构建的农业分类词库对特征集合进行扩充。如:特征词“绿豆”含有关键词库中的关键词“豆”,则将“绿豆”加入到特征集合中。通过基于分类词库扩充的方法进行特征选择,避免对分类有效的低频率词语不能入选特征词的问题。图3为文本特征选择结果。第一条记录“首都”为特征词,“/n”表示该特征词为名词,“5.681877639268151”为文档频率。

图3 文本特征选择结果Fig.3 Results of text feature selection
权重计算是指以数字形式表示特征词在文本中的重要程度。本文提出基于改进TF-IDF(Term frequency-inverse document frequency)方法进行特征项权重计算。该方法不仅考虑特征词在整个语料集中的重要程度,而且考虑特征词在各个类别之间以及各个类别内的差异性。计算公式为
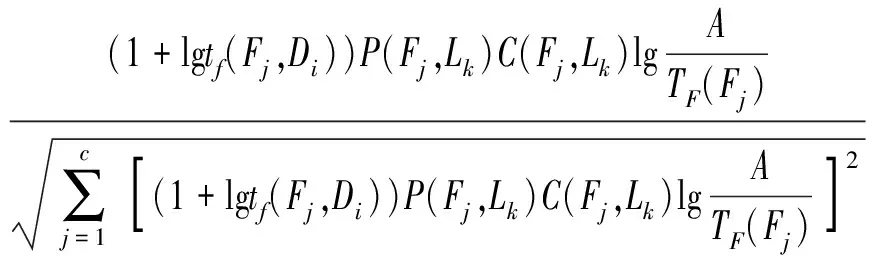
(2)
其中
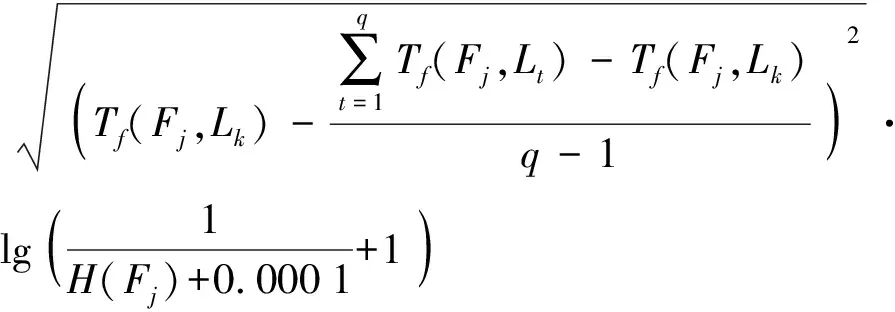
(3)
(4)
式中W(Fj,Di)——特征词Fj在文本Di中的权重
tf(Fj,Di)——特征词Fj在文本Di中的频率
c——特征词的个数
P(Fj,Lk)——特征词Fj的类间区分程度
C(Fj,Lk)——特征词Fj在类别k中分布的均匀程度
Tf(Fj,Lk)——特征词Fj在类别k上的频率
q——类别数
H(Fj)——特征词Fj的信息熵[26]
Ak——类别k的样本数
通过式(3)、(4)分别计算特征词对于各个类别的类间区分度和类内均匀度,计算结果如图4所示。图4中c1表示种植业,c2表示种业,c3表示畜牧业,c4表示兽医,c5表示渔业,c6表示农垦,c7表示农机,c8表示农产品质量安全,c9表示农村经营管理,c10表示科教,c11表示农产品市场。第1条记录中的“0.24815460223223648”表示对于种植业类中语料来说,特征词“流域”的类间区分程度,“0.01020408163265306”表示特征词“流域”在种植业中的均匀度。
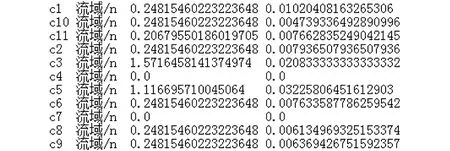
图4 特征词类别区分度计算结果Fig.4 Results of feature word category distinction calculation
1.2.3文本特征向量构建
本文特征项权重计算方法考虑了特征词的类别区分度,对处于不同类别中的同一样本分别计算权重,对同一样本进行特征项权重融合,构建文本特征向量,即
(5)
式中U(Fj,k)——对于特征词Fj,样本Di在类别k中的权重
Yik=1表示样本Di划分到类别k中。
构建文本特征向量后,采用RAKEL (Random k-labelsets)多标记分类[27]算法训练农业文本多标记分类模型。在测试阶段,通过构建文本特征向量,利用训练好的分类模型实现农业文本自动分类。最后根据多标记分类的结果,按分类类别构建语料库。
1.3 候选词提取和词频统计
农业热词反映了一个时期内农业用户群体所关注的热点事件,具有一定的概括性。从文本语料方面来说,只有体现文本重点内容的词语才有可能成为热词。因此,本文采用基于信息熵的方法提取文本关键词,将其作为农业热词候选词,包括名词、动词、形容词等。
基于信息熵的关键词提取方法在采用常用的TF-IDF特征外,还将词的信息熵、词的空间局部性和词所在句子的位置作为非常重要的因素加入到词的权重中[28]。
词语w的信息熵E(w)表示[26]为
E(w)=-∑p(x)lgp(x)
(6)
式中p(x)——字符x在所有字符中出现的概率
设L={l1,l2,…,ln}为词语w的左邻接集合[28],R={r1,r2,…,rm}为词语w的右邻接集合[28],其中li和rj分别为词语w的左邻字符串和右邻字符串。设li、rj的出现频次分别为ni和mj,左邻接集合和右邻集合中字符串的频次总和分别为Ni和Mj。词语w左信息熵El(w)和右信息熵Er(w)的公式[28]为
(7)
(8)
熵反映了信息的不确定性,而左信息熵和右信息熵则反映了词语w邻接字符串的不确定性。左信息熵和右信息熵越大,表明邻接字符串的不确定性越大,则词语w的使用越灵活,其成为关键词的概率也越大。
采用上述算法不仅提取出“黑狼犬”这样的单候选词,而且包括“蔬菜价格”这样的组合候选词。针对“蔬菜价格”,普通分词时会将其分为“蔬菜”和“价格”两个词,从而在对“蔬菜价格”进行词频统计时,该词词频为零。为了避免这种情况,将候选词集加入到分词词典中,则在分词时不会出现组合候选词被分割的情况。在此分词基础上按类别分别进行单日候选词词频统计。图5为普通分词与加入候选词集分词的结果对比。图5a中将“蔬菜价格”分割为“蔬菜”和“价格”两个词;图5b中“蔬菜价格”为一个词。

图5 分词结果对比Fig.5 Comparison of segmentation results
1.4 候选词热度计算
热词候选词具有一定的农业网络关注度,但是各候选词的受关注程度不一致,只有达到较高关注度的候选词才能称之为热词,因此本文通过计算候选词热度,挑选热度排在前列的候选词作为热词。针对农业热词单日词频高、历史波动大的特点,提出基于时间变化的热度计算方法。该方法考虑候选词的基础词频和历史波动2个因素,分别记为基础权值和波动权值。
基础词频是指候选词的单日词频。为了避免单日文本数不同对基础权值的影响,故进行平滑处理。基础权值B的计算公式[6]为
B=lg(1+lg(1+lg(tf+1)))
(9)
式中tf——候选词的单日词频
历史波动采用基础权值的整体波动性、长期变化和短期变化表示。本文提出基础权值的整体波动性V、长期变化L和短期变化S的计算方法分别为
(10)
(11)
(12)
式中t——实验数据周期
Bi——候选词第i天的基础词频
波动权值反映候选词在一段时间内的频率波动情况。本文定义波动权值F的计算公式为
F=0.4V+0.4L+0.2S
(13)
候选词的基础权值和波动权值分别体现农业热词的特点。因此提出热度权值H的计算公式为
H=0.5B+0.5F
(14)
式(13)和式(14)中权重系数的确定通过多组实验得出。具体方法为,将权重系数以0.1为间距,分别对公式中涉及到的因素赋予权重,进行实验,最终得出。对于式(13),当整体波动性V和长期变化L的权重系数分别设置为0.4,短期变化S的权重系数设置为0.2时,实验效果最佳;对于式(14),当基础权值B和波动权值F的权重系数均设置为0.5时,实验效果最佳。
对于实验语料中种植业类的热词候选词“花球”和“水利”,通过上述热度计算方法得出“花球”的热度权值为0.680 039 128 501 011 3,“水利”的热度权值为0.281 568 874 380 245 75,在该类候选词中,“花球”的热度排第4位,“水利”的热度排第3 437位,因此,“花球”属于热词,“水利”不是热词。另一方面,从“花球”和“水利”的频率变化图也可以得出相同的答案,如图6所示,“水利”一词每天的频率都很高,但是前后期波动不大;而“花球”一词前期频率一直为零,后期突然上升,前后期波动很大,所以说“花球”是热词,“水利”不是热词。
对候选词进行热度计算后,按照权值进行热度排序,得到各类别在指定时间段内的热词。
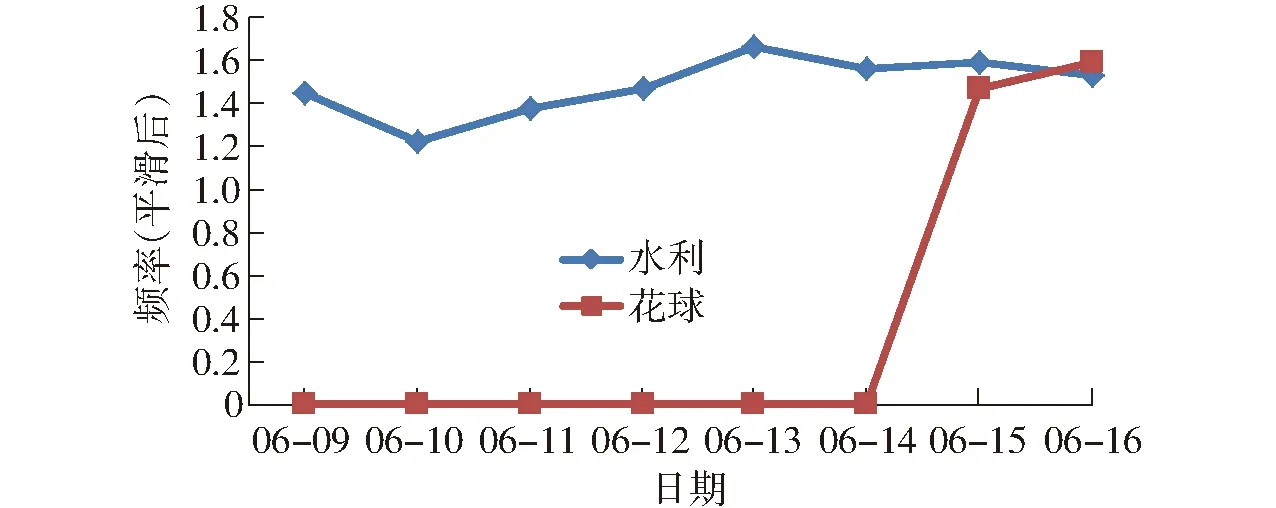
图6 候选词频率变化曲线Fig.6 Frequency variation curves of candidate words
2 结果与分析
本文获取了中国农业信息网、搜猪网、中国农资网、中国三农网、中国水产养殖网、中国农机网、中国棉花交易网等农业网站2017年6月9—16日的农业信息,共15 354条。采用本文所述方法自动提取6月16日的农业热词。表1为单日实验文本数统计表。

表1 实验语料统计Tab.1 Experimental corpus statistics
本文编码环境为MyEclipse 2014。文本分词和农业热词候选词提取通过调用NLPIR汉语分词系统包中的分词函数和关键词提取函数实现。
针对热词提取的结果,采用前N个返回结果的准确率和二元偏好值来衡量本文热词提取方法的性能[29-30]。
前N个返回结果的准确率(P@N)即计算在返回的前N个最优结果的准确率,计算公式为
(15)
式中T——返回的前N个结果中正确结果的个数
二元偏好值Bpref(Binary preference)用以评价返回结果中,正确结果与非正确结果的相对位置,主要体现方法能否将热词在非热词之前返回。计算公式为
(16)
式中R——对每个主题,已判定结果中正确结果个数
r——正确结果项
b——前R个不正确结果集合的子集
|b|——当前正确结果项之前不正确的结果个数
2.1 文本语料分类结果
用户可以根据需求设定分类类别,对文本语料分类。本文设定为11个类别:种植业、种业、畜牧业、兽医、渔业、农垦、农机、农产品质量安全、农村经营管理、科教和农产品市场。这11个类别的内容范围不是完全独立的,各类别之间有些信息是共同涉及的。为了保证各类别信息的完整性,采用多标记分类算法对8 d的语料分别进行分类。分类结果如表2所示。
由文献[31]中的多标记分类评价指标对分类结果进行评价,得出准确率为92.54%,汉明损失为0.056 4,一类错误为0.063 6,覆盖率为1.597 3,排序损失为0.046 5。
2.2 候选词提取与词频统计结果
实验将6月9—16日作为一个周期,通过分析此周期内热词候选词的频率变化情况来提取6月16日的农业热词。首先从6月16日的11个类别的文本语料分别提取热词候选词;然后将候选词集加入到分词词典中,对8 d的文本语料分别进行分词;最后进行候选词单日词频统计。各类别候选词个数统计结果如表3所示,部分候选词单日词频统计结果如表4所示。热词候选词单日词频统计结果是为计算候选词热度做准备的。
2.3 候选词热度计算结果
对11个类别中的热词候选词分别计算热度。表5列出了各类别中部分候选词的热度计算结果。
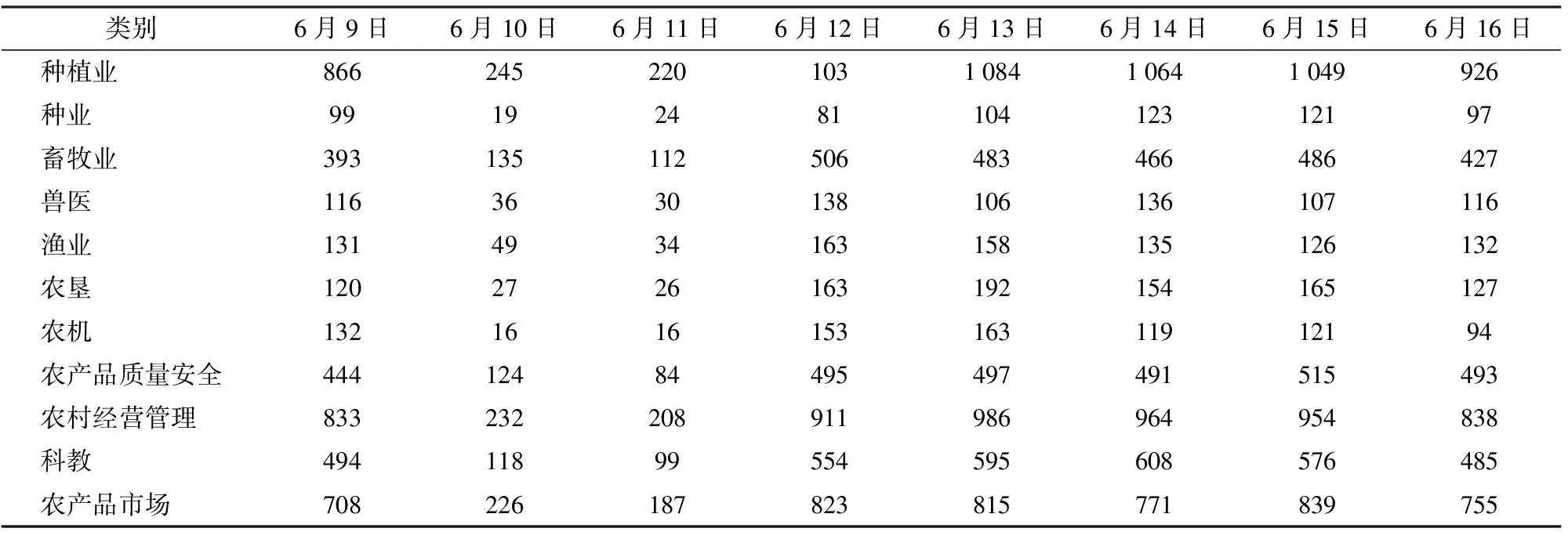
表2 多标记分类结果Tab.2 Results of multi-label classification

表3 候选词个数统计结果Tab.3 Statistics of number of candidate words
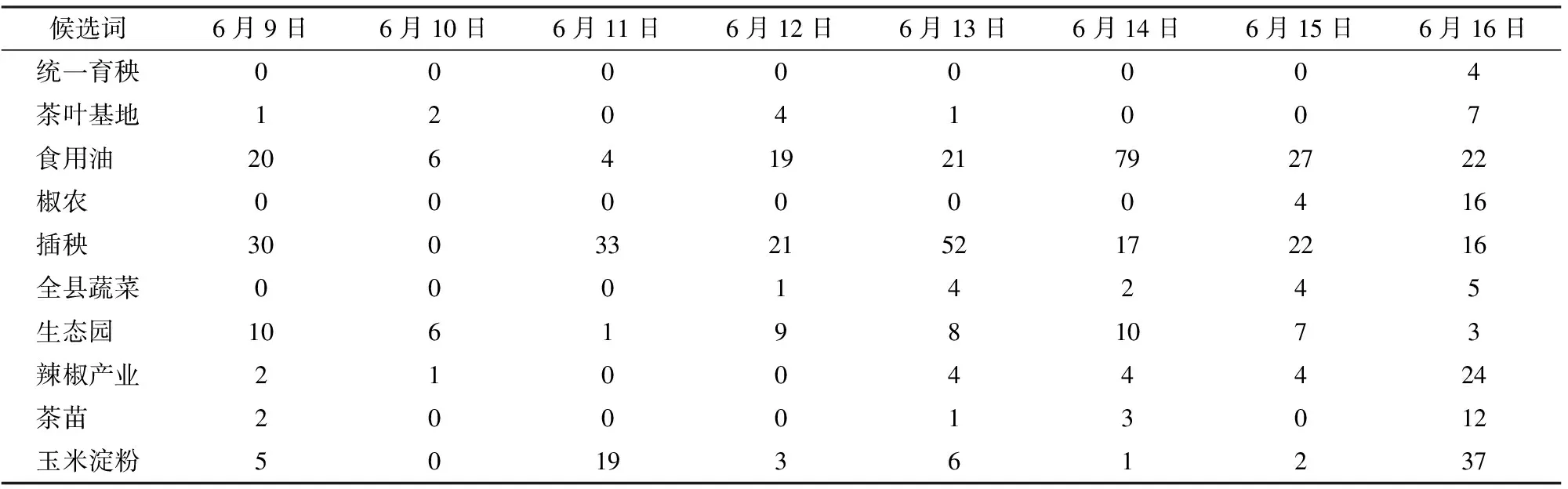
表4 种植业部分候选词词频统计结果Tab.4 Statistics of word frequency of part candidate words in crop farming
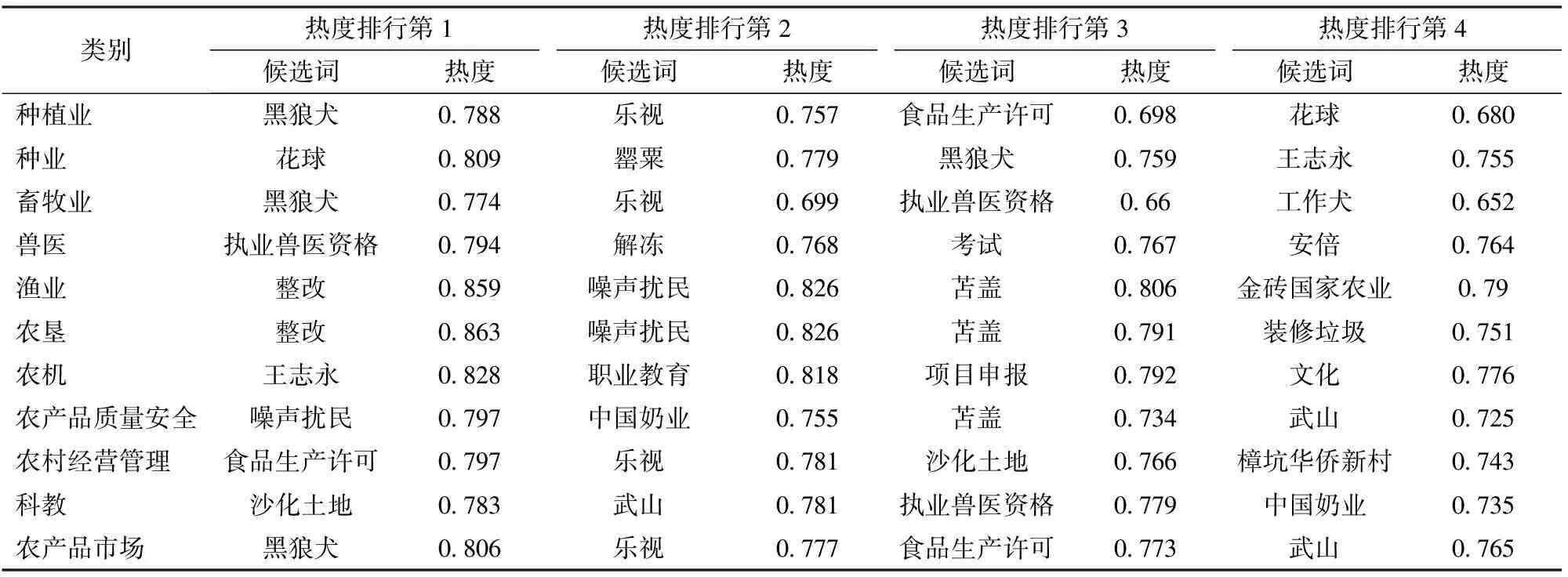
表5 候选词热度计算结果Tab.5 Heat calculation results of candidate words
根据热词的定义,人工为每个类别标注出100个热词,采用前N个返回结果的准确率和二元偏好值对本文提出的热词提取方法的性能进行评价。对于P@N,主要考虑P@4、P@20、P@50、P@100这4个指标。对于Bpref的计算,选取R=100。表6是本文热词提取方法返回结果的评价。
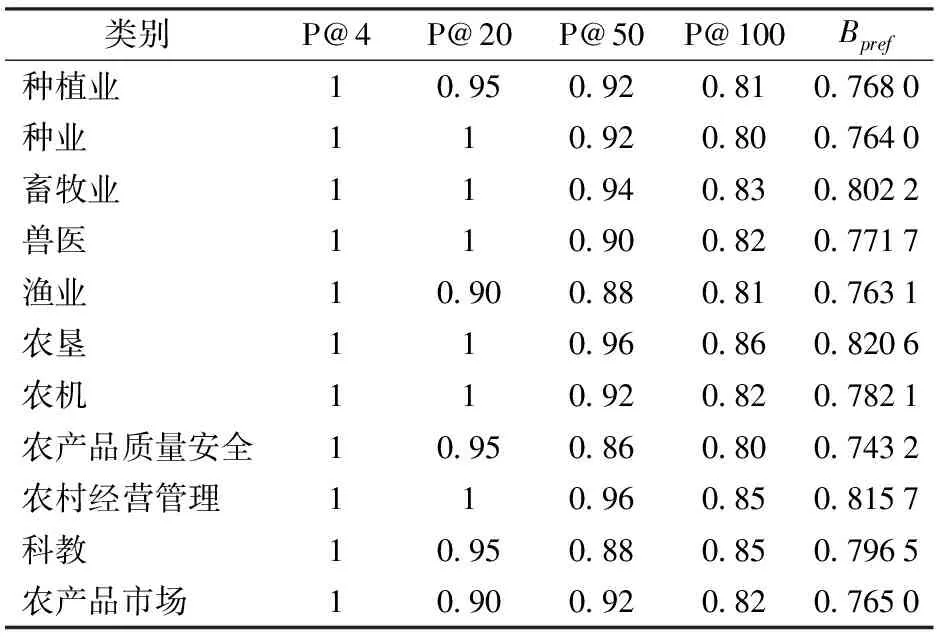
表6 热词返回结果评价Tab.6 Evaluation of returned results of hot words
注:P@4指前4个返回结果的准确率。
本文针对不同农业产业分别提取热词,得出各类别的热点关注,便于不同农业产业的用户群监测本产业动向。由表6可知,各类别中P@4的值均为1,表明在各类别中热度排在前4的候选词均是该类别的热词,验证了本文热词提取方法的正确性。P@4的结果优于P@20,P@20的结果优于P@50,P@50的结果优于P@100,表明返回结果数越少,准确率越高。Bpref表明在热词返回结果中,非热词在热词之前出现的次数情况。该值越大,表明非热词在热词之前出现的次数越少,算法效果越好。由表6可知,各类别中Bpref值稳定在0.8左右,实验效果较好。
从表5中各类别的热词可以看出,有些热词在多个类别中出现。如热词“食品生产许可”在种植业、农村经营管理和农产品市场3个类别中都出现。这是由于采用多标记分类算法对文本语料进行分类,保留了文本的多样性特点,保证了用户查找行业信息的完整性。种植业、农村经营管理和农产品市场3个产业的用户在查找本产业信息时都可以通过热词“食品生产许可”获取到与之相关的新闻。
3 结论
(1)将农业文本分类技术与热词提取技术结合,提出了一种基于农业网络信息分类的热词自动提取方法。根据用户需求,设定分类类别,针对每个类别分别提取热词,挖掘出不同用户群体和农业管理部门所关注的信息热点,实现不同产业用户群快速获取产业动态,进行分析和决策的功能。采用前N个返回结果的准确率对实验结果进行评价,当N取值为20时,其准确率达到0.9以上。
(2)针对目前研究中提取的热词词性单一等问题,提出基于信息熵的热词候选词提取方法;结合热词特点,提出基于时间变化的候选词热度计算方法,有效衡量了热词候选词的受关注程度,实现农业热词的准确提取。
