
基于优先级指数的土壤采样设计方法研究
2018-07-28 03:19王子龙陈伟杰姜秋香印玉明常广义
农业机械学报 2018年7期
王子龙 陈伟杰 付 强 姜秋香 印玉明 常广义
(东北农业大学水利与土木工程学院,哈尔滨 150030)
0 引言
土壤特性与其变异性研究必须以科学的采样策略为依托。抽样策略的本质即寻求经济投入与实验精度间的优化平衡,以最小的经济投入所换取的离散样本集来估测连续总体集的主要信息而不失其精确性[1]。建立集代表性、准确性和经济适用性为一体的土壤采样设计不但有助提高工作效率,而且也是研究的关键。采样设计一般建立在统计非全面调查的基础上,根据实际工作所研究对象的性质和相关工作的目的而采用与其相适用的方法。各种采样设计会形成各异的采样结果,由此产生的抽样误差也有较大的差别[2]。相对于实验室分析误差而言,不科学的采样设计带来的误差影响更为显著[3]。
目前,国内外土壤采样的常用方法主要包括简单随机采样、嵌套采样、分层采样、系统采样和整群采样等方法[4-8],采样点分布策略的研究主要集中在基于地统计学的插值模型对采样点空间位置和采样数目的优化[9],如李润林等[10]和李楠等[11]基于辅助变量运用克里格法进行了采样数目优化;VAT等[12]和韩宗伟等[13]通过模拟退火法对样点空间布局进行了优化,但其缺陷在于不适用于初步采样,而偏重于为多次采样和后期监测点的布置提供参考,同时,支撑其理论的初步采样数据,往往遵循随机抽样,忽略了空间相关性,在一定程度上造成了结果偏差。除传统的插值模型外,侯建花等[14]提出了MDI空间采样策略来提高采样点估算精度,但没有考虑地形和地貌的影响,其效果受到一定影响。在利用先验知识辅助采样方面,曾也鲁等[15]提出了基于NDVI先验知识的LAI地面采样方法;江雨佳等[16]利用湿度与碳通量的相关性提出了一种基于辅助因子空间分布特征的小尺度空间采样策略,在碳通量采样设计中取得较好效果;刘京等[17]基于土壤景观模型认为土壤景观越相似,其所对应的土壤越相似,提出了基于样点个体代表性的采样制图方法。此外,YANG等[18]和孙孝林等[19]运用基于土壤景观模型理论的代表性等级采样法在土壤制图方面可得到一系列代表性较好的采样点,但其存在如下缺陷:忽略了各协同因子对目标属性空间分布的影响差异;在确定代表性样本时,多协同因子的聚类会因为隶属度阈值的选择而导致有效信息的流失;协同因子局限于定量因子的范畴(如坡度、地形湿度指数、沿等高线曲率等)无法加入定性因子(如土地利用形式)。本文建立一种可赋权、信息传递完整、包容性强(可涵盖定性、定量两类协同因子)的基于优先级指数的土壤采样设计方法(简称优先级采样法)。
1 研究方法
土壤景观学[20]系统论述了土壤成因与景观类型的必然关系,土壤景观学模型结合空间分析成为土壤调查方法研究的主要趋势,并在国内外相关研究中得到验证[21-24]。优先级指数采样法的基本思路是分析与目标土壤属性直接相关的协同因子的空间分布,通过赋予其权重并叠加计算优先级指数,将研究区域分割成为具有各自优先级指数的区域,优先级指数越高则越能表现研究区土壤属性变化的主要特征,而优先级指数低的点则是目标土壤属性变化特征的细化补充,在合理采样数的限定下,依照优先级指数从高到低选取采样点,即可较好地平衡采样的代表性和全局性,也可为多次采样提供依据。
1.1 协同因子选择
为保证土壤性质空间分布预测具有较高精度,将定量和定性因子相结合作为辅助变量,对于提高土壤性质空间分布预测精度有较好的效果[25]。协同因子选取的合理性直接影响分析结果的科学性和可靠性。因此,在已有研究的基础上,选取与目标土壤属性相关因子作为研究集合,通过Pearson相关性系数应用MAXTED等[26]的标准删除冗余信息,以确保相关因子都能反映一个独立的信息。由于定性协同因子无法通过Pearson相关性系数来与定量因子做相关性分析,在聚类处理后,可以借助信息熵的概念来评判两者携带信息的独立性。
1.2 优先级指数计算
为了综合考虑各协同因子对目标土壤属性空间分布的不同影响,可通过粗糙集理论予以赋权,其原理和步骤详见文献[27],或采用专家打分法等策略。在各协同因子中,通过聚类方法又可划分为多个子集,其各子集所占空间决定了其在一定空间范围内的景观类型的主要特性,由此,以信息尺度设定的栅格为单位,可通过计算各子集所占总空间面积比与其所归属协同因子的权重之积,作为其对目标土壤属性空间分布预测的贡献值。将赋有贡献值的各协同因子图层作为输入层,可叠加计算同一空间位置下栅格贡献值之和,即得到赋有采样优先级指数的报告层。其中,具有相同优先级指数的相邻栅格可进一步看作一个代表性图斑,其数值越大,即表明该图斑覆盖的地理空间位置越具备研究区空间范围内的样本特性。将该优先级指数由高到低排序,其序列的顺次,即优先级别。图层叠加原理如图1所示。图中,EA为协同因子子集的贡献值;SP为优先级指数。
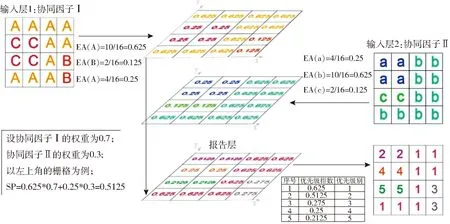
图1 各协同因子图层叠加原理图Fig.1 Layers overlapping principle sketch of synergistic factors
1.3 采样点布设
采样点布设一般遵循以下原则:①根据图斑的优先级别设置采样点,优先在优先级别高的图斑内布设。②根据路网缓冲区级别设置采样点,在具有相同优先级别的图斑间决定取舍时,优先在具有较高级别路网缓冲区的图斑内布设。③每个图斑内的样本容量可以是一个或者多个,也可以为零,根据采样点缓冲区半径、合理采样数和采样预算来决定。
路网缓冲区级别是在报告层上叠加各级路网图,根据实际采样需求,沿国道、省道、县道、乡道对应生成具有一定半径的Ⅰ、Ⅱ、Ⅲ、Ⅳ级缓冲区。为使采样点尽可能地分散布置,需要设定采样点的缓冲区,以避免采样点集聚造成局部信息冗余。设研究区面积为M,采样点的缓冲区半径为
(1)
式中,N为合理采样数,可通过Cochran公式初步计算,具体算法可参照文献[28]。
2 实例
以嫩江县土壤饱和导水率空间变异性研究的采样方案为例,验证基于优先级指数的土壤采样设计方法的实用性及采样点的代表性。
2.1 研究区概况与数据来源
嫩江县地处松嫩平原黑土区嫩江流域上游,隶属黑龙江省黑河市,共辖8镇6乡,总面积达1.51×104km2,约占松嫩平原黑土区的1/8,如图2所示。嫩江县属中温带半湿润大陆季风气候,多年平均气温-1.4~0.8℃,无霜期80~130 d,土壤多为壤土,速效氮质量比平均为220.7 mg/kg,速效磷质量比平均为61.9 mg/kg,速效钾质量比平均为172.7 mg/kg,饱和导水率在3.88~86.27 cm/min之间,均值为23.15 cm/min,标准差11.27 cm/min。土壤养分丰富,保水、保肥力强,适合多种作物的生长,是重要的商品粮基地。
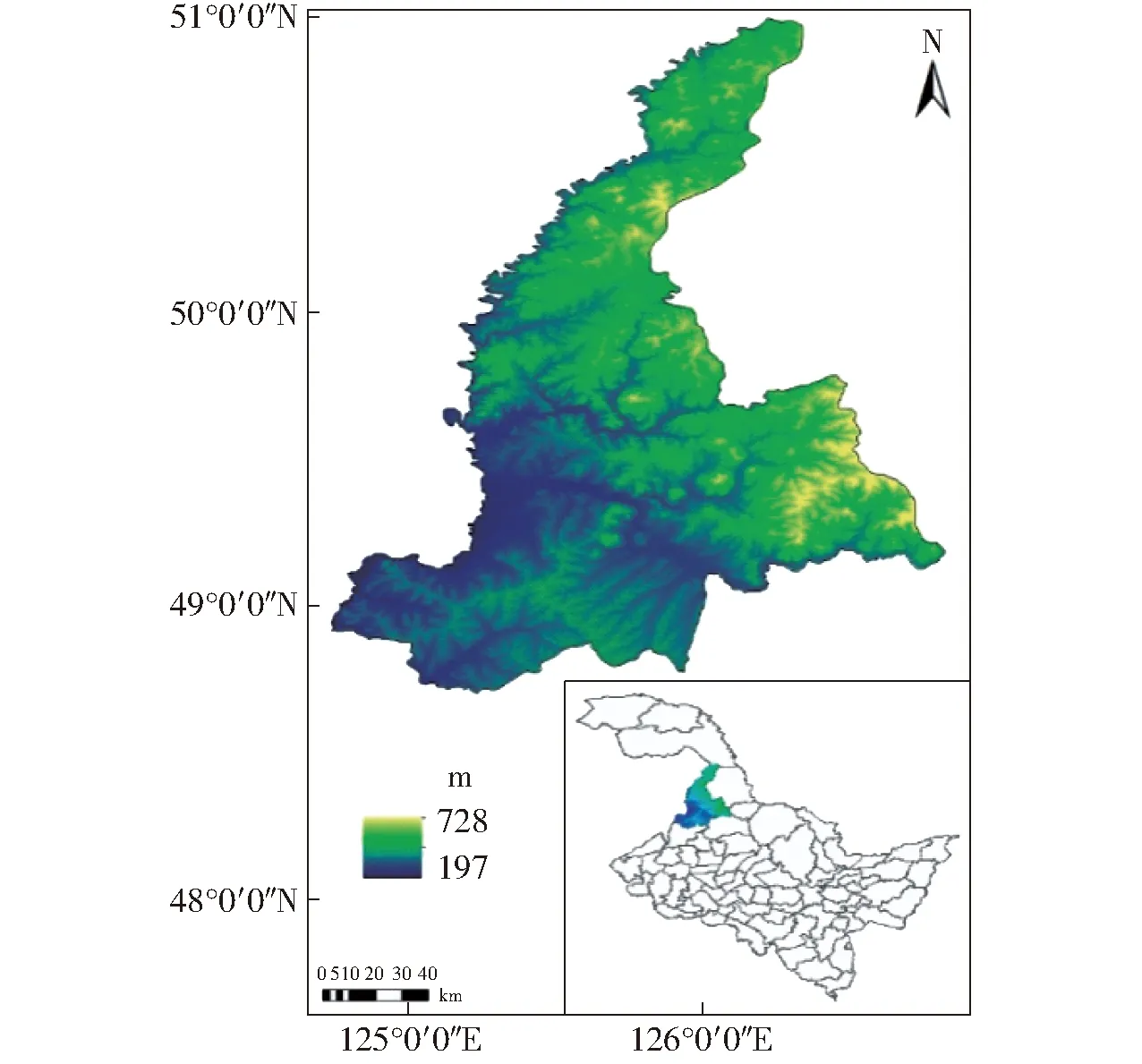
图2 研究区地理位置Fig.2 Geographical location of study area
饱和导水率反映了水在土壤中流动的阻碍作用。影响饱和导水率的因素较多,目前已有诸多文献对此进行了研究[29-34]。基于前人研究结论及先验知识的可获取性,本研究协同因子涵盖有机质含量、碎石含量、粉粒含量、沙粒含量、粘粒含量、土壤容重、土地利用情况、坡度。其中,土地利用数据来源于Earth Science Data Interface (ESDI),坡度数据来源于地理空间数据云,其余数据均来源于联合国粮农组织(FAO)和维也纳国际应用系统研究所(IIASA)所构建的世界土壤数据库(Harmonized World Soil Database version 1.1)中第2次全国土地调查南京土壤所提供的1∶1 000 000土壤数据。
2.2 协同因子选择
由相关性分析可知(表1),沙粒与粉粒(相关系数-0.935)、粘粒(相关系数-0.791)、土壤容重(相关系数0.939)的信息重叠程度以及土壤容重与粉粒(相关系数-0.773)、粘粒(相关系数-0.926)的信息重叠度均达到了筛选标准(相关系数绝对值大于0.75),则从协同因子中剔除沙粒与土壤容重。
由土地利用方式信息熵(2.170 4)和协同因子坡度、碎石、粉粒、粘粒、有机质信息熵1.999 8、1.958 2、1.989 2、1.978 0、1.756 9得到联合熵与K值如表2所示,可知土地利用方式与坡度、碎石、粉粒、粘粒、有机质之间相关性弱,具有极好的信息独立性。最终,确定坡度、碎石、粉粒、粘粒、有机质及土地利用方式为协同因子。

表1 协同因子相关性分析(N=258)Tab.1 Correlation analysis between synergistic factors (N=258)
注:** 表示显著水平为P<0.01;*表示显著水平P<0.05。
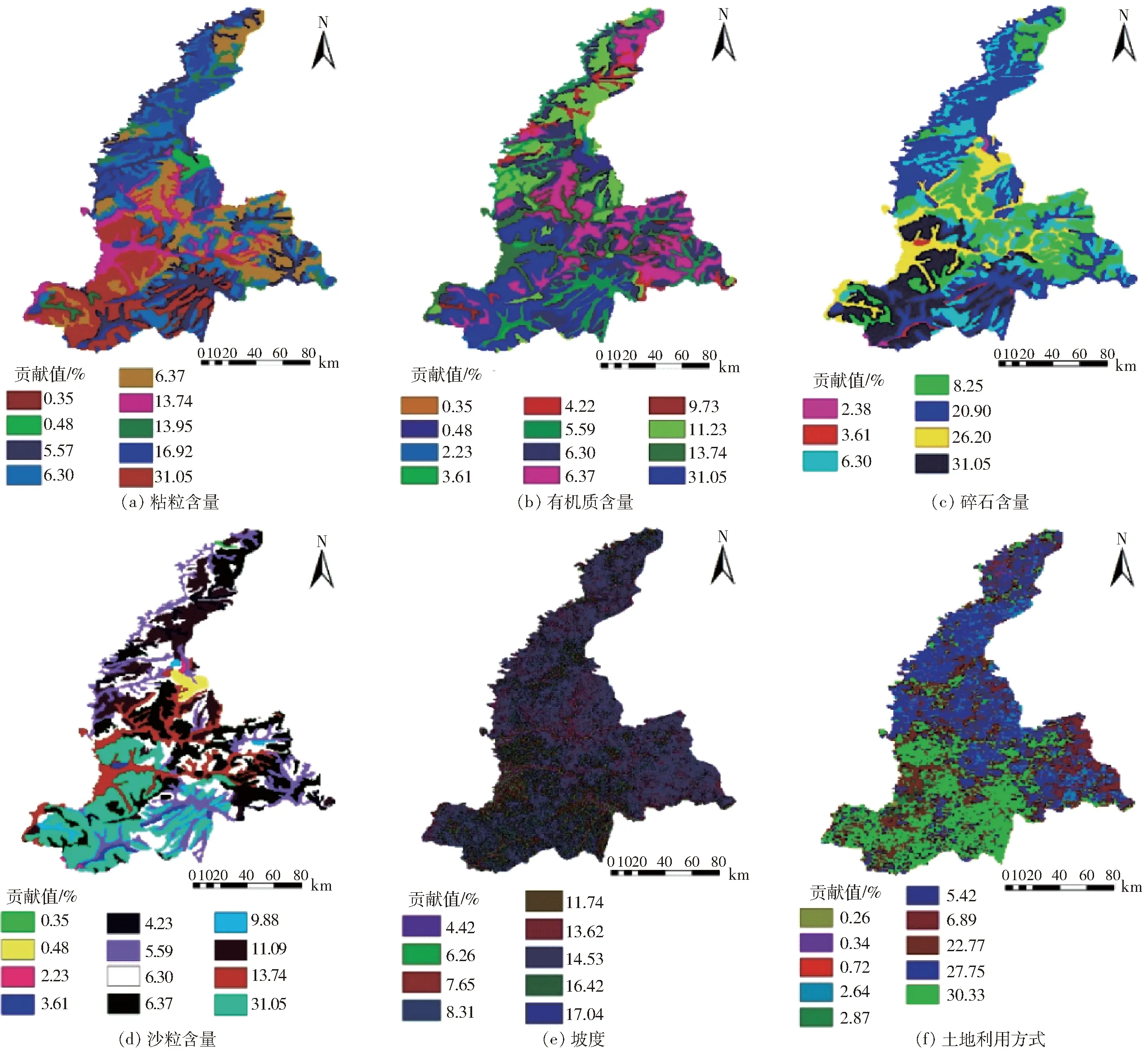
图3 各协同因子输入层图Fig.3 Input layer diagrams of synergistic factors

表2 土地利用方式与协同因子联合熵与K值Tab.2 United entropy and K-value of land use patterns and collaborative factor
2.3 代表性等级计算
基于先验知识的图层栅格均为30″(纬度差)×30″(经度差),故而设定栅格大小为1 km×1 km,以此作为后续运算的基本单元。由于土壤属性的先验知识来源于第2次全国土地调查南京土壤所提供的1∶1 000 000土壤数据,其数据并不完全连续,因此可根据数据集中的几个区间进行聚类。通过ArcGIS分别计算各协同因子的输入层,如图3所示。
由粗糙集理论可得到有机质含量、碎石体积含量、粉粒含量、粘粒含量、坡度、土地利用方式的权重分别为0.129、0.185、0.089、0.096、0.217、0.284。为探究不同权重设定对采样方案的影响,同时考虑到该法涉及种别差异的定性因子,故而另外采用专家打分法计算权重进行对比,由收集到的20份调查问卷结果可得有机质含量、碎石体积含量、粉粒含量、粘粒含量、坡度、土地利用方式的权重分别为0.146、0.246、0.200、0.216、0.077、0.114。
将各协同因子的输入层通过ArcGIS的栅格计算器按各自权重叠加计算即可得到对应的报告层,将优先级指数从高到低排序,依次赋予其优先级别,如图4所示。对研究区域栅格化处理后,其栅格总量可视为样本总量。根据所适用的不同合理采样数计算公式,Cochran采样数法、由样本方差替代总体方差条件下的Cochran采样数法、小样本平均极差替代标准差条件下的Cochran采样数法、小样本均值替代总体均值条件下的Cochran采样数法分别得合理采样数计算结果为86、31、44、82个。其中,Cochran采样数法与小样本均值替代总体均值条件下的Cochran采样数法所得的合理采样数较为接近,综合考虑采样尺度和范围的条件下,选取Cochran采样数为最终合理采样数。
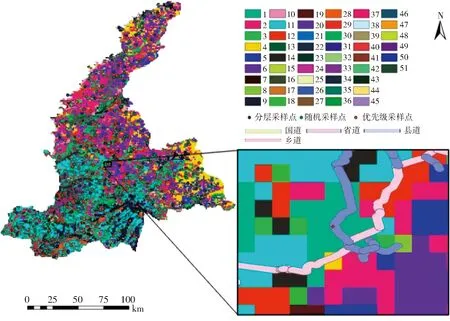
图4 优先级别及采样点分布图Fig.4 Priority and sampling points distribution
2.4 采样点布设
由式(1)可计算得,嫩江县采样点的缓冲区半径为7.47 km,与王卫华等[35]提出的饱和导水率采用间距7.14 km较为契合。叠加嫩江县范围内的国道、省道、县道和乡道后,综合考虑采样所选用的交通工具及人力可及程度,自主选择半径生成Ⅰ、Ⅱ、Ⅲ、Ⅳ级缓冲区,并遵循前文提及的采样原则进行布点。以基于粗糙集理论的优先级指数采样法为例,最后得到的采样点分布如图4所示。
3 代表性验证
本研究采用普通克里格法作为饱和导水率空间插值算法,并通过独立验证以均方根误差作为评价指标。本文在研究区范围内随机选取20个点作为独立样本。此外,该方法所需的饱和导水率均以第2次全国土地调查南京土壤所提供土壤数据为基础由Campbell土壤转换函数计算所得。

图5 基于不同采样方法的饱和导水率插值结果比较Fig.5 Comparison of saturated hydraulic conductivity interpolation between different sampling methods
本研究采用包含600个样点的总集通过GS+7.0选择半方差函数,将基于粗糙集理论的优先级指数采样法、基于专家打分法的优先级指数采样法、分层采样法和随机采样法得到的点集分别作为已知数据,通过ArcGIS中的Geostatistics模块进行克里格插值来预测独立样本点的数据,并与独立样本值作比较,如图5所示。由结果可知,基于粗糙集理论的优先级指数采样法、基于专家打分法的优先级指数采样法、分层采样法、随机采样法得到的预测值相对于独立样本而言,其均方根误差分别为51.930、46.901、54.772、55.980 cm/min。
由表3的对应点均方根误差均值及标准差可知,优先级指数采样法相对于分层采样法和随机采样法均最小,即优先级指数采样法插值得到的预测值与独立样本值最接近。就空间分布而言,由图6可知,优先级指数采样法在一定程度上比分层采样和随机采样更加接近样点总集。基于粗糙集优先级采样法与基于专家打分法在空间分布上较随机采样法和分层采样法更为接近,由图6可知,基于专家打分法得到的空间分布信息比基于粗糙集优先级采样法得到的信息略为丰富。在表3中对应点均方根误差的统计信息可知,基于专家采样优先级采样法最接近真实值,其变异系数最小,即得到的数据集最为收敛。

表3 基于不同采样方法的独立验证点统计参数对比Tab.3 Comparison of statistical parameter of independent verification point based on different sampling methods
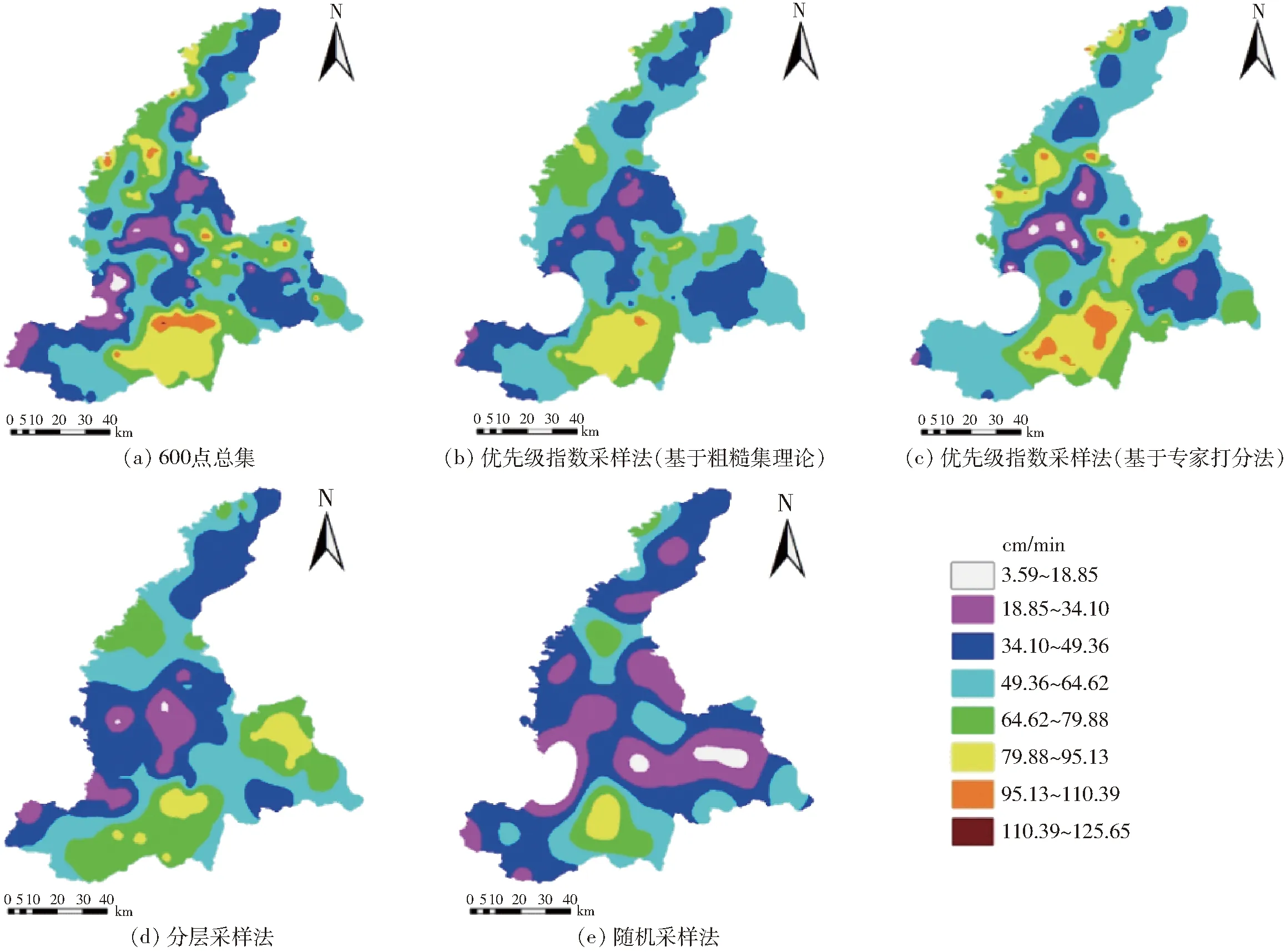
图6 基于不同采样方法的空间分布对比Fig.6 Comparison diagrams of spatial distribution between different sampling methods
4 讨论
相对于传统采样法而言,优先级指数采样法能够较好地捕捉研究区土壤信息的主要特征,在允许条件下,可以多批次增加采样密度,满足于灵活变更采样计划对研究区细部信息进行补充。目前采样点分布策略多运用克里格插值、模拟退火法等模型进行优化,该方法需要在随机抽样等传统方法为初步采样的基础上进行,目的更偏重于后期监控点布设,相比之下,优先级指数采样法在协同因子可获得的情况下,能满足初步采样设计和后期监测点布置的任务需求,其所花费的人力物力在一定程度上性价比更高。相对于土壤景观理论的代表性等级采样法,优先级指数采样法具有可赋权、信息传递完整及包容性强的特点。
优先级指数采样法旨在利用有效协同因子的情况下灵活把握研究区的整体属性分布特征,优先级指数较高的区域对研究区整体特征的把握能力较好,而优先级指数较低的区域则更能反映局部特性的细节,随着优先级指数从高到低依次增加采样点,采样精度会在一定程度上有逐步上升的过程。但由于优先级指数较低的点位对全局的代表性相对较小,在一定程度上仅能表征局部范围的空间分布特性,若以采样精度变化量和采样成本变化量之比来定义采样效益,那么样点数随着优先级指数从高到低依次增加,对整体采样效益而言在一定程度上会有逐步上升达到峰值又转而回落的过程,该峰值所对应的采样数,在经济效益上能够为合理采样数目进一步的确定提供一定程度指导。
5 结论
(1)优先级指数采样法考虑了各协同因子对目标属性空间分布的影响差异,同时能够容纳多种定性定量因子;在确定优先级别时,不会因为聚类数的选择而导致有效信息的流失。
(2)相比于传统随机采样和分层采样法,优先级指数采样法能够在一定程度上避免局部最优,能更好的反映研究区的主要信息。此外,在兼顾样点布设均匀性和随机性的同时,与路网相关联能够极大地改善实际采样的便捷性,为采样路线的设计提供一定的依据。
(3)协同因子的权重对优先级指数采样法的结果在空间分布及预测的准确性上都有一定程度的影响。相比于传统的分层采样和随机采样,基于不同权重优先级指数采样法得到的结果较为接近。
猜你喜欢
西北林学院学报(2022年5期)2022-10-04
北京航空航天大学学报(2022年6期)2022-07-02
新班主任(2022年4期)2022-04-27
红领巾·探索(2021年2期)2021-08-26
科学大众(2020年23期)2021-01-18
中等数学(2020年1期)2020-08-24
学生天地(2020年34期)2020-06-09
军事文摘·科学少年(2020年2期)2020-03-19
文化创新比较研究(2020年8期)2020-01-02
当代陕西(2019年11期)2019-06-24
