
基于思维进化优化BP神经网络的大豆叶片叶绿素含量高光谱反演
2018-08-01 07:53张绍良侯湖平田艳凤郝绍金
江苏农业科学 2018年13期
刘 润, 张绍良, 侯湖平, 陈 浮, 田艳凤, 郝绍金
(1.中国矿业大学环境与测绘学院,江苏徐州 221116; 2.中国矿业大学低碳能源研究院,江苏徐州 221116)
植物叶片叶绿素含量是表征植物生长状况和其光合作用能力的重要指标,是植被光合作用能力、植被生理状况的指示剂,其含量快速测定对农作物长势监测、病虫害防治及农作物估产等都有着重要意义[1-2]。
传统的实验室化学测定植物叶片叶绿素含量虽然精度较高,但其过程繁杂,而且化学试剂的使用会产生很多污染废弃物,不适用于大量样本叶绿素的快速测定。利用光谱分析方法进行植物叶绿素含量等生化成分含量测定则具有低消耗、低成本、快速及无损伤等优点,并且已经广泛应用于农业、医药、食品等多个领域。1983年,Horler等就对叶片叶绿素浓度和反射光谱间的相关关系进行了研究,并建议使用光谱数据进行叶绿素含量的反演[3]。随着高光谱技术的发展,多元统计分析方法被广泛应用于叶绿素等生化参数反演[4-5],关于植被叶绿素等生化参数与光谱反射率关系的研究也表明,叶绿素等与光谱反射率之间具有非线性关系,一般性回归方法无法达到较高精度,而神经元网络算法以其强大的容错性、自组织自学习和非线性模拟能力,在不确定两者之间关系的前提下仍然可以很好地解决非线性问题[6]。目前,利用神经元网络算法的高光谱反演技术在土壤水分、土壤有机质、矿区土地重金属含量反演等相关研究中都取得了较好成果,但关于大豆冠层叶绿素含量反演的研究相对较少。在相关指标含量估算的建模研究中人们还发现,人工神经网络集成模型的精度要优于单神经网络模型,单神经网络模型则优于多元逐步回归模型[7-8]。
本研究将利用BP(back propagation)神经网络来建立大豆叶片叶绿素反演模型,并使用遗传算法(genetic Algorithm,简称GA)和思维进化算法(mind evolutionary algorithm,简称MEA)对BP神经网络模型连接权值和阈值进行优化,并针对叶绿素和光谱反射率之间的相关关系分别建立遗传算法优化BP神经网络(GA-BP)模型和思维进化算法优化BP神经网络(MEA-BP)模型,来估算叶绿素含量,并对模型进行验证和精度比较,从而确定最佳估算模型。
1 研究方法
1.1 试验田概况
本次试验数据在中国矿业大学南湖校区试验田采集,采集时间为2014年7月16日,天气晴。试验田总规划面积为 1 000 m2(40 m×25 m),试验田应季种植大豆,结合试验田大豆实际种植情况,在田间以近“S”形取样路线均匀地选取样本点32处,并做好标记(图1)。
1.2 反射光谱测量
反射光谱测量采用ASD(Analytical Spectra Devices)公司生产的FieldSpec3地物光谱仪,其光谱测量范围为350~2 500 nm,其中350~1 000 nm波段分辨率为1.4 nm,1 000~2 500 nm波段分辨率为2.0 nm,大豆叶片光谱采集时间为 10:00—15:00,在风力小于3级,天气晴朗无云情况下进行。采集时保持传感器探头距离冠层1 m左右处,与地面垂直。采集期间每隔0.5 h用参考板对仪器进行优化以消除环境对仪器的影响。每个样本点重复获取10条光谱曲线取平均值作为原始光谱数据。由于光谱采集过程在室外进行,不可避免地会混入各种噪声,跳跃点如图2-a所示,因此这里通过小波去噪法滤除大部分噪声信息,最后得到较平滑的光谱曲线(图2-b)。图2-b所呈现的是比较典型的植被光谱曲线特征,在绿光波段(550 nm左右)有1个明显的反射峰,这也是绿色植物呈现为绿色的原因;在红光波段(680 nm左右)有1个吸收谷,这是因为植被光合作用须要吸收红光波段能量;由于植被叶片内部构造的原因,导致叶片在近红外波段(700~800 nm)处有一反射陡坡,形成植被的独有特征;短波红外波段(1300~2500 nm)由于植被含水量的影响,吸收率大增,反射率大大下降,其中在1 450、1 925 nm左右处均为水的吸收峰。以上特征表明,经过去噪后的光谱曲线能够满足接下来试验研究的要求。

1.3 叶绿素含量测定
在样点光谱采集完毕后立刻采集样点处叶片,将叶片用自封袋装好并做标记后带回实验室,用分光光度法测定叶绿素含量,并计算出每克干物质叶绿素含量(mg/g),对每1样本点测量30次,取其平均值作为最终模型输入的叶绿素含量,样本叶绿素含量统计结果见表1。

表1 32个样点叶绿素含量检测统计结果
1.4 BP神经网络及优化
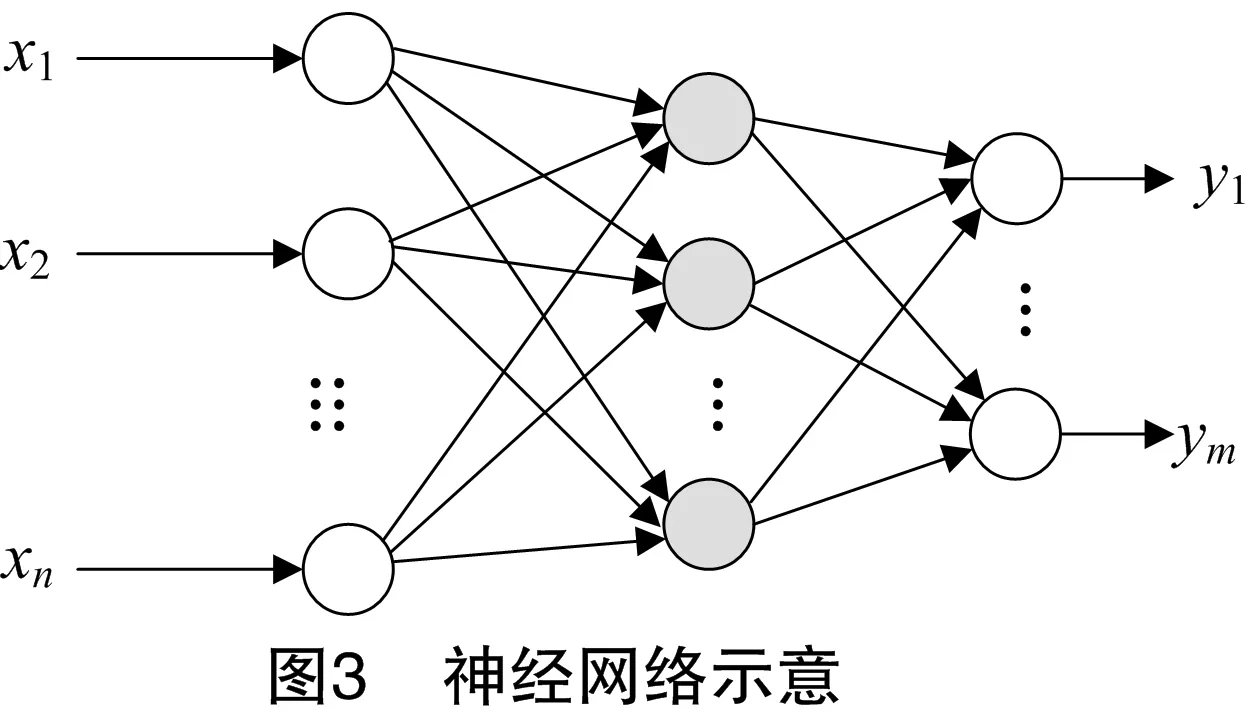
1.4.1 BP神经网络 BP神经网络是由Rnmelhart和Hinton等在20世纪80年代中期提出的一种多层前馈神经网络,该神经网络在学习和训练过程当中采用误差的逆向传播算法,因此被称为BP神经网络[9];结构上,BP神经网络主要由输入层、隐含层、输出层构成,其中隐含层数目是不确定的,可以为一层或多层,有研究已经证明在只有一层隐含层情况下的BP神经网络结构对任意非线性连续函数仍然有很好的逼近能力[10],图3为只有一层隐含层的神经网络示意图[11]。
BP神经网络的数学原理[6]描述如下:

(2)
1.4.2 GA-BP 遗传算法利用了生物的进化过程和遗传思想,不同于启发式算法、搜索算法等传统优化算法,它具有自组织、自适应、智能型等特点,在运行过程中处理的是参数编码集,而非参数本身,并且该算法在搜索过程中使用的是目标函数值的评价信息,因此搜索过程不受优化函数连续性、可导性的约束[12-13]。此外,GA擅长全局搜索,而BP神经网络擅长局部搜索,GA首先优化神经网络初始权值定位出较优的搜索空间,再通过BP神经网络在小空间搜索产生最优值,因此可以很好地表达输入量和期望输出变量之间的非线性关系,提高BP神经网络反演精度[14-15],这便是GA优化的基本原理。GA的具体步骤如下:
(1)网络初始化
初始化BP神经网络,随机产生1个种群Xm×n,其中个体X1×n代表1个神经网络初始权值分布;确定网络输入输出节点数s1、s2,隐含层数H,训练次数N,训练误差ε等参数,则个体长度即为神经网络权值个数。
(2)遗传编码
确定种群规模m、最大迭代次数T、交叉概率Pc和变异概略Pm,将网络权值和阈值按照一定顺序联起来作为一个染色体,其长度n为
n=H×(s1+s2)+H+s2。
(3)
(3)选取适应度函数
适应度函数值是种群中个体的得分和评价,可以反映个体或解的优劣性,这里将网络的误差函数E作为适应度函数来计算种群中每个个体的适应度值fi。
(4)遗传进化
该部分主要是通过迭代来求解最佳结构权值和阈值,集成选择、交叉、变异3个操作,其中,选择算子采用轮盘赌法,若第i个个体的适应度值为fi,则选中概率为
(4)
交叉即由2个个体通过线性组合产生新的个体,这里选择算术交叉法。假设以交叉概率Pc在2个个体Xi(k)、Xi+1(k)之间进行交叉操作,则交叉后产生的新个体为
(5)
式中:α为0~1之间的随机值。
变异操作选择均匀变异算子作用于群体,以变异概率Pm所对应的基因取值范围内某一随机值来替换原有值,即:
Xi=Xi(p)+s1×q+Xi(n-p-1)。
(6)
式中:q为第p+1个基因所对应阈值范围,通过遗传进化便可以利用初始父辈种群产生新一代的子种群Xt。
(5)适应度值计算
计算适应度值,判断是否满足迭代次数和精度要求,否则返回第2步。在遗传结束后,解码最优个体作为BP网络的初始权值和阈值。
1.4.3 MEA-BP 思维进化算法是在遗传算法的基础上进行改进,借鉴了遗传算法的群体进化思想,提出了趋同和异化算子,两者相互协调,并非对立关系。趋同操作针对群体中的某一部分,而异化操作则针对整个群体,因此可以提高选择效率,MEA具体步骤如下[16]:
(1)网络初始化
由于思维进化算法沿用了遗传算法的群体、进化等概念,因此网络初始化部分基本相同,这里可以借鉴遗传算法的网络初始化部分内容。
(2)子群体生成
根据适应度函数计算个体适应度值,得分最高的前M个个体选定为优胜个体,(M+1)~(M+N)个个体作为临时个体,以优胜个体和临时个体为中心,分别生成M个优胜子群体和N个临时子群体。
(3)趋同操作
各子群体内部个体进行局部竞争转变为胜者的过程,竞争过程持续到子群体成熟,即不再产生新的胜者,此时的子群体得分为最优个体的得分,并将结果粘贴到全局公告板上,直到所有子群体成熟,趋同工程才结束。
(4)异化操作
成熟子群体之间为成为胜者而进行的全局竞争,从全局公告板上比较优胜子群体和临时子群体得分,通过得分筛选出全局最优个体。异化结束后,计算最优个体适应度值,判断是否满足迭代次数和精度要求,不满足则返回网络重新进行(2)~(3)步操作。进化结束后解码最优个体作为网络结构初始权值和阈值,本研究中模型的建立和运算在Matlab环境中进行,2种优化算法的具体流程如图4所示。

1.5 模型验证
从稳定性和预测能力2个方面对模型精度进行验证,其中,稳定性用判定系数r2来衡量,预测能力使用均方根误差(root mean square error,简称RMSE)来衡量,两者计算公式如下:
(7)
(8)
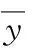
2 结果与分析
2.1 相关性分析
原始光谱数据含有2 150个波段,若全部用于估算模型建立,模型的结算将会耗费大量时间,并且原始数据中混有不可修正的噪声信息,若全波段建模也会降低模型最终估算精度。因此,本研究通过分析光谱反射率数据和叶绿素含量之间的相关性来提取特征波段用作模型输入数据,分析结果如图5所示。
本研究特征波段选取有意避开噪声集中区,根据相关性分析选取412、705、934、1 421、2 157 nm 5个波段作为特征波段,特征波段对应的反射率作为模型自变量输入参数。本研究共选取32个实测样本,选取其中22个样本作为网络训练数据,剩余10个样本用于网络验证。

2.2 模型估算结果
估算试验以选取的特征波段反射率作为模型自变量,对应叶绿素含量作为因变量。分别运用单BP神经网络,基于遗传算法优化的BP神经网络和基于思维进化算法优化的BP神经网络进行建模估算。由于神经网络运行时是随机产生初始权值,因此进行反复试验,通过‘save filename net’命令保存精度较高的网络。
从图6以及表2中的统计结果可以看出,通过思维进化算法优化BP神经网络估算的叶绿素含量与实测值吻合程度最高(图6-d),遗传算法优化BP神经网络次之,单BP神经网络和经过遗传算法优化的BP神经网络得到的估测值相比实测值波动较大,这也与表2的统计结果相匹配;基于思维进化算法优化BP神经网的决定系数为0.861,均方根误差为3.234 7,从模型稳定性和模型的预测能力来说,思维进化算法优化BP神经网络都要优于其他2种方法。

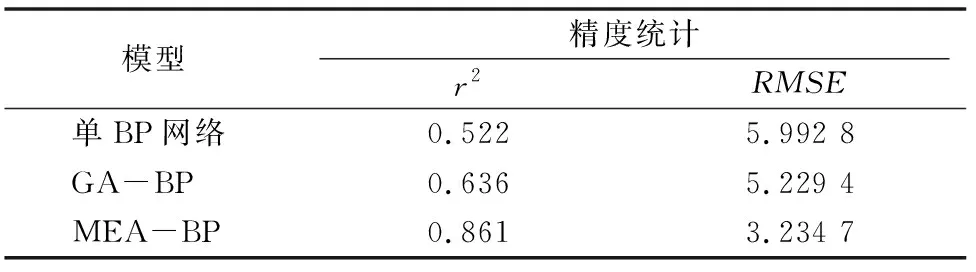
表2 不同模型精度统计
3 结论
对降噪后的原始光谱数据进行相关性分析,从而筛选出相关性较大的特征波段对应的反射率作为模型自变量用于叶绿素含量估算,并分别使用单BP神经网络、基于遗传算法优化的BP神经网络、基于思维进化算法优化的BP神经网络进行叶绿素含量估算建模。大量对比试验结果表明,基于思维进化算法优化BP神经网络模型的稳定性(r2=0.861)及预测能力(RMSE=3.234 7)相比于其他2种方法更好,可以为其他相关反演研究提供一定的借鉴作用;与经过优化后BP神经网络相比,单BP神经网络获得了最低精度的估算结果,这也说明,通过其他优化算法与神经网络的组合建模能够有效提高模型反演精度;虽然思维进化算法优化BP神经网络取得了较好的叶绿素估算精度,但由于实测数据量较少,在运行该神经网络的过程中存在不稳定因素,估算过程中可能会存在一定偏差。
猜你喜欢
阅读(科学探秘)(2020年8期)2020-11-06
中国果业信息(2019年1期)2019-01-05
石油地球物理勘探(2017年2期)2017-11-23
生物学教学(2017年9期)2017-08-20
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
高师理科学刊(2016年8期)2016-06-15
智能系统学报(2015年4期)2015-12-27
西藏科技(2015年4期)2015-09-26
河北北方学院学报(自然科学版)(2014年2期)2014-05-30
