
文本线局部极值区域两阶段场景文本序列识别
2018-08-15 08:24董引娣赵晓祎
计算机与生活 2018年8期
董引娣,赵晓祎
1.重庆城市管理职业学院 信息工程学院,重庆 401331
2.中国人民解放军后勤工程学院 训练部,重庆 401331
1 引言
场景文字定位与识别是非常有价值的研究方向,可帮助视障人士进行语言翻译和写作,同时可用于大型图像和视频数据库文本内容自动索引(例如谷歌街景、Flickr等)。不同于传统印刷文档的OCR(optical character recognition),现有场景文本识别方法在识别精度上无法满足应用需要,最近的ICDAR 2015大赛获奖算法也只能达到70%的识别精度,并且要求场景文本不存在透视变形或明显噪声[1]。
文本定位过程在算法中占有非常大的计算复杂度,因为对应于大小为N像素的图像会产生2N个子集。现有算法一般采用两种处理方式:
(1)借鉴其他对象的检测问题,利用滑动窗口方法对个别字符或整个词进行定位。这种方法已得到成功应用,例如文献[2]提出基于树结构模型的端到端场景文本识别;文献[3]提出集成多个字符建议的鲁棒场景文本提取方法;文献[4]提出基于窗口特征识别的鲁棒的自然场景图像文本检测方法等。这类方法的优点是对噪声和模糊性具有很强的鲁棒性,因为对于窗口兴趣区域的特征进行了充分的开发利用[5]。主要缺点是需要评估的矩形数量迅速增长时,须找到具有不同规模、方向、旋转和扭曲的文本,导致定位精度降低。
(2)使用图像的局部属性(如颜色、强度或笔划宽度)将单个字符定位为连接组件的方法。这种方法逐渐得到流行,例如文献[6]提出基于强度跟踪的多方位场景文本检测,设计了动态规划检测方法的统一框架;文献[7]提出利用智能手机处理的自适应场景文本图像二值化颜色检测方法;文献[8]提出基于笔划宽度的实时无词典场景文本定位与识别方法。这类方法的复杂性不依赖于所有字符尺度的文本参数,在OCR阶段可检测到字符分割的连通分量。最大缺点是依赖于字符是连接组件的假设,噪声的单像素改变可能会导致连接组件的大小、形状或其他属性不发生变化,从而可能影响其分类。
本文提出了终端到终端的实时文本定位和识别方法,它不依赖于任何先验知识即可实现文本检测,这与词汇为基础的方法存在明显的不同。本文方法属于第二种算法类别,因为它首先检测单个字符,然后建立更复杂的字符结构,例如字和文本线。最后,通过实验仿真对算法性能进行了测试和分析。
2 算法框架描述
近期,大多数文本局部化方法都使用连接组件方法。这些方法在个体特征检测方法上有所不同,它们可以基于边缘检测、特征能量计算或极值区域检测。虽然这些方法都非常注重个性检测,但最终分割的决策仅取决于局部特征。这种方法对噪声和模糊图像很敏感,因为它依赖于成功检测到的边缘,并且只为每个字符提供一个分割,这对OCR模块来说可能不是最好的。现有大多数方法只注重文本识别,文字位置通过人工进行设定,只有少数的端到端文本定位和识别方法能够处理嘈杂的数据,但它们的通用性受到词汇字典的限制。本文提出文本线局部极值区域两阶段场景文本序列识别方法,所要解决的便是文本的自动定位和处理方法的通用性问题。
对于一组给定的训练图像S={(Ii,Bi)}ni=1,其中Ii为图像,Bi是图像Ii中用于指定字符的位置和范围的一组边界框。文本检测算法应该能够捕捉到字符的本质子结构,并且区别于局部背景,具有相互对立关系。由于S仅提供字符级注释,需要对其字符原型进行自动识别[9-10]。
给定“发现”图像集D和“自然词语”图像集N,算法目标是在D中发现歧视其他集群的有代表性补丁集群及图像集N中可视词语。该算法输出是具有最高排名的补丁集群K和分类集C。每个集群Kj对应分类器Cj可检测到在新图像下与聚类Kj相似的补丁。本文提出端到端的实时文本定位和识别方法,不依赖于任何先验检测知识。该方法首先检测单个字符,然后建立更复杂的结构模型。通过将字符检测问题转换成一组有效的顺序极值区域(extremal regions,ER)选择问题,实现实时的检测能力,算法框架见图1所示。

Fig.1 Algorithm framework图1 算法框架
在第一阶段,利用特征计算对每个ER字符概率进行计算,这部分算法计算复杂度较低,然后选取具有局部最大概率的特征用于第二阶段,并采用复杂度更加昂贵的算法细化特征计算。利用高效聚类算法将ER处理成文本线,然后利用字符区域的标签以及OCR分类器合成字体。最后,在上下文中的每个字符的文本线已知的情况下,可实现最有可能的字符序列的快速选取,实现算法效率提升。
3 特征检测过程
3.1 极值区域
考虑图像映射I:D⊂N2→V,对于彩色图像,V为[0,255]3。图像I的信道是映射C:D→S,其中S是完全有序集合,fc:V→S是一个完全有序集的像素值投影。令A表示邻接区域A⊂D×D。本文考虑4像素情形,具有坐标(x±1,y)和(x,y±1)的像素是像素(x,y)的邻接矩阵。图像I的区域R是D的连续子集[11]:

外边界∂R相邻但不属于R像素集:
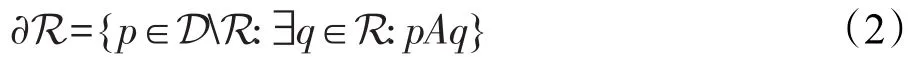
极值区域是其外边界像素具有严格高于该区域本身值的区域:
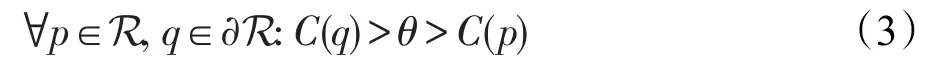
其中,θ表示极值区域的阈值。考虑RGB和HSI颜色空间和附加强度梯度通道(∇),其中每个像素通过其邻居之间的最大强度差近似进行“梯度”像素分配。

在图像中,有些字符是由较小元素或多个联合字符组成的单个元素构成的。采用高斯金字塔分解对图像进行预处理,如果字符包含多个元素,这些元素融合在一起成为单一区域,则在每级金字塔只有具有一定间隔的字符笔划宽度被放大。
3.2 描述符的增量计算
ER快速分类关键是分类器特征的区域描述符获取[12]。在阈值θ上极值区域r可构成联合区域,或在阈值θ-1上的更多极值区域。使用特殊描述符,并利用ER之间存在的包含关系,以增量计算方式进行描述。令Rθ-1表示阈值θ-1上极值区域集合,在阈值θ上极值区域r∈Rθ可利用阈值θ-1上区域像素及像素值θ联合构成:

假设阈值u∈Rθ-1上所有极值区域描述符为ϕ(u)。为计算区域r∈Rθ描述符ϕ(r),需对区域u∈Rθ-1描述符和像素{p∈D:C(p)=θ}融合,形成区域r:

其中,符号⊕表示合并区域描述符;ψ(p)表示给定像素p描述符初始化函数。这样的描述符ψ(p)和⊕存在增量计算过程,如图2所示。
可通过简单地依次增加阈值θ从0到255,实现对所有极值区域描述符的计算,在阈值θ中添加像素的计算描述符ψ,在阈值θ-1中重用区域ϕ描述符。此外,假定单个像素ψ(p)描述符计算及组合操作⊕具有固定时间复杂度,由此产生的对于N个像素的图像所有极值区域描述符的计算复杂度为O(N),每个像素只计算一次ϕ(p),那么组合函数可在最多N次计算过程中完成评估,因为极值区域数目上限为图像中的像素数。本文使用以下增量计算描述符:
(1)面积参数a,即像素数,其初始化函数是一个常数函数ψ(p)=1,组合运算⊕表示加法操作(+)。
(2)边界框(xmin,ymin,xmax,ymax),表示区域右上角和左下角。坐标为(x,y)像素p的初始化函数为(x,y,x+1,y+1),组合操作⊕为(min,min,max,max)。该区域宽度ω和高度h可计算为xmax-xmin和ymax-ymin。
(3)周长参数p,区域边界长度见图2(a)。在像素p中当阈值添加时,初始函数ψ(p)确定周长的变化:
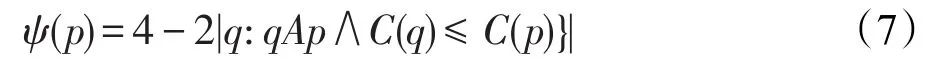
式中,ψ(p)的计算复杂度为O(1),因为每个像素最多有4个邻居像素。

(4)欧拉数η。欧拉数是一个二元图像的拓扑特征,其计算形式为:其中,C1、C2和C3分别表示图像中二进制像素数。初始化函数值ψ(p)可通过对给定阈值C(p)像素p由0到1变化所确定:
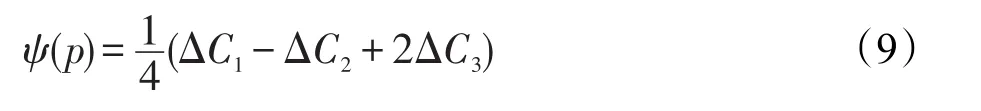
3.3 顺序分类
在本文方法中,每个信道分别进行高斯金字塔处理,然后检测ER。为减少高误报率和高冗余的ER检测器,顺序分类只对独特ER对应的字符进行选择。
步骤1阈值从0逐渐增加到255,对极值区域r的描述符增量计算复杂度为O(1),这些描述符作为分类器的特征,用于对类的条件概率p(character|r)的计算,只选择具有最大概率的极值区域进行第二步计算,如图3所示。

Fig.3 Conditional probability computation of a class图3 类的条件概率计算
采用AdaBoost分类器顺序分类,采用的字符特征有:纵横比ω/h、紧性、孔数(1-η)、水平通道特征,作用是在水平投影中估计字符笔划数。只对c的固定大小子集采样,获得固定复杂度计算过程。利用Logistic修正,对分类器输出进行概率函数p(character|r)校准。通过实验,设置参数pmin=0.2,Δmin=0.1。
步骤2通过步骤1筛选的极值区域进行字符和非字符类别划分,但对这些特征进行操作的计算复杂度也很高。本文采用支持向量机(support vector machine,SVM)和RBF(radial basis function)核函数进行操作。该步骤中利用步骤1所有特征,并增加如下特征:开孔面积比ah/a,其中ah表示区域孔的像素数;凸壳比率ac/a,其中ac表示区域凸包的面积;外边界拐点数κ,表示区域边界周围像素之间的凹凸角变化次数。
4 算法计算步骤
4.1 文本行构建
令R表示在前一阶段中检测到的所有通道和尺度区域(字符候选)集。搜索所有序列空间,及其对应的子字符序列。利用底线估计和附加的外形限制进行集群个体距离测量。基于穷举算法进行初始文本线候选,如算法1所示。
算法1初始文本线候选
输入:区域集R。
输出:三元组集T。

算法1中,对r1∈R进行穷举操作,利用其邻居r2∈N(r1)和r3∈N(r2)。r2∈N(r1)指相距K=5以内的r2与r1,该距离表示两区域质心距离。通过限制集合r2∈N(r1)到区域r2方式,按照自左到右方向强制执行文本,其质心在r1质心右边,即cx(r2)>cx(r1),其中cx(r)表示该区域r的质心x的坐标。
在穷举搜索中,区域对(r1,r2)和(r2,r3)及(r1,r2,r3)可利用约束v进行修剪,目的是降低穷举操作复杂度。在本文方法中,二进制约束v使用高度比和区域距离宽度归一化值作为特征,而三元约束v′采用文本行高度和区域质心角度归一化距离底线作为特征。实验中,AdaBoost分类器事先利用ICDAR 2013训练集进行训练。
算法2构建文本行,每个三元组变成长度为3的文本行,利用最小二乘法估计初始基线方向b。横框中包含所有的行文本区域计算,并保存坐标(左)、(右)和(高)。查找行l和l′的最小距离dist(l,l′)。两部分区域合并,基于合并文本行区域集可实现对新底线方向和包围盒坐标更新。最小相互距离dist(l,l′)定义如下:
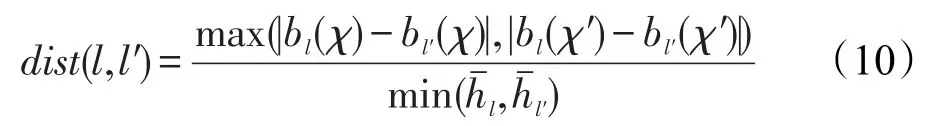
算法2文本线构建
输入:三元组集T。
输出:文本线集L。


4.2 基于序列选择的字符识别
令表示所有文本行区域的集合,即:

每个候选区域r∈利用Unicode码对最近邻分类器进行标记。区域r标签集r∈定义为:
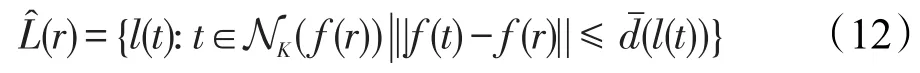
其中,l(t)表示训练样本t的标签;NK(f(r))表示字符特征空间f中区域r的K近邻;是标签l的最大距离;A是支持Unicode字符集。
首先将区域归一化到固定大小为35×35像素的矩阵,保留该区域的质心和纵横比。训练集由白色背景上的黑色字母图像组成,共有5 580个训练样本。最近邻分类器NK由近似最近邻分类器实现,K设定为11。为计算每个类别估计的值,每个特征表示为训练集的交叉验证乘以β的公差因子,这里选取β=2.5。
考虑将字表示为字符序列,在文本线中给定区域r1和r2,如果r1和r2是相同文本行一部分,r1为r2前身,即字符序列中与r1相关联的字符紧接在与r2相关联字符之前。可引入有向连接图G对其进行表达,从而使节点对应于标记区域:
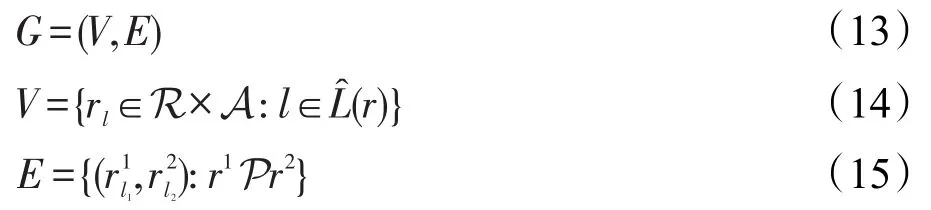
其中,rl表示具有标签l∈A的区域r。没有由字符分类器分配任何标签的区域不是文本行图的一部分。每个节点rl和边具有关联的权值s(rl)和,计算形式分别为:
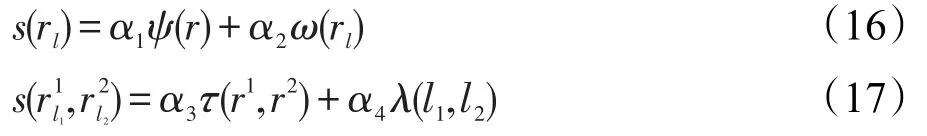
其中,权重α1、α2、α3、α4可由训练阶段确定。
字符识别置信度ω(rl)表示通过分类器区域r具有字符标签l的概率。利用标签为l的训练集对K近邻模板进行计算,获得字符特征空间中的距离和,并利用最近模板的距离进行归一化:

阈值重叠区间τ(r1,r2)是区域r1和r2间隔的交集;转移概率λ(l1,l2)表示给定语言模型中,标签l1跟随l2的估计概率。本文算法最后一步,为每个节点和边缘分配分数,实现有向图构造。该过程中与每个文本行关联的单词序列作为算法的最终输出。则本文算法计算复杂度为O(pN),其中p为所采用的通道数,N为图像的像素数。
5 实验分析
硬件设置:CPU-AMD 7650K 3.30 GHz,内存为8 GB ddr4-2400k,系统为Win10旗舰版。参数设置:极值区域的阈值θ∈[0,255]逐渐增加,pmin=0.2,Δmin=0.1,间距K=5,公差因子β=2.5,归一化区域的固定大小35×35像素,其余参数b、、、在算法开始节点进行自动估计,见算法2。
对比算法选取文献[13-16],其中文献[13]是一种考虑纹理特征和图像矩的自然场景文本识别算法;文献[14]利用边界聚类、笔划分割和字符串片段分类实现对场景图像中的文本局部化操作;文献[15]是基于文本嵌入式分割的场景文本有效图切割识别算法;文献[16]也是一种局部化操作的场景文本识别算法。测试对象选取USTB-SV1K数据库,其场景文本具有多方向特征,如图4所示。
该数据库是具有500幅图像的多方向场景文本数据库。图片平均尺寸是1 600×1 200像素。场景图像采集通过浏览器直接在亚马逊网站上复制,并通过人工注释,特定图像与特定文本,例如企业标志和名称只能处于水平方向。评价指标为:识别精度(precision)、召回率(recall)、F-score以及计算时间。前3项指标定义如下:


Fig.4 USTB-SV1K database multi-direction features(partial images)图4 USTB-SV1K数据库多方向特征(部分图像)
式中,TP表示正确划分为正例个数;FP表示错误划分为正例个数;FN表示错误划分为负例个数。实验结果如表1所示。

Table 1 Comparison of experimental data表1 实验对比数据
根据表1数据,在recall指标上,几种对比算法性能相差不大,均分布在0.61~0.63之间。在precision指标上,本文算法精度为0.72,相对于选取的几种算法,具有较为明显的优势,对比算法识别精度分布在0.61~0.67之间。而在计算时间上,本文算法计算时间为5.2 s,在上述几种算法中,计算时间是最少的。对比算法中,文献[14]和文献[16]也都采用了局部化操作方法,因此其计算时间也相对较少,分别为6.3s和6.5s。
图5所示为文献[13-16]以及本文算法的场景文本识别效果,实验对象选自USTB-SV1K数据库。从图5结果可知,从分割效果上看,本文算法要明显优于选取的文献[13-16]对比算法。文献[13]算法和文献[14]算法在HOWARD字符识别上效果不理想,存在较大区域的黑化现象。文献[16]算法在REDBACK、HOWARD和LITTER字符上的识别效果不好,存在白化现象。文献[15]算法在上述实验对象上的识别效果总体还可以,但是噪声问题比较严重,识别图像不够清晰。上述实验结果验证了本文算法的性能优势。

Fig.5 Image localization segmentation effect图5 图像局部化分割效果
6 结束语
本文提出了一种基于文本线局部极值区域两阶段场景文本序列识别方法,采用两个阶段进行场景文本的识别,将第一阶段的最大概率的局部特征作为第二阶段的输入,然后利用文本线处理方式和顺序分类算法实现场景文本的有效识别。实验结果验证了算法性能优势。今后研究主要集中在以下三点:(1)采用更复杂和数量更大的数据库对算法性能进行测试;(2)对应用系统开发进行研究,并考虑建立与真实字符系统的接口;(3)对算法性能进行优化,实现更佳的识别性能和更快速的计算。
猜你喜欢
新世纪智能(数学备考)(2021年10期)2021-12-21
新世纪智能(数学备考)(2021年10期)2021-12-21
新世纪智能(数学备考)(2020年10期)2021-01-04
语数外学习·高中版中旬(2020年10期)2020-09-10
汉字汉语研究(2020年2期)2020-08-13
计算机应用与软件(2020年6期)2020-06-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
速读·下旬(2019年11期)2019-09-10
