
粒子群优化混合核极限学习机的构造煤厚度预测方法
2018-08-28 08:53范君,王新,徐慧
计算机应用 2018年6期
范 君,王 新,徐 慧
(中国矿业大学计算机科学与技术学院,江苏徐州221116)
(*通信作者电子邮箱344298099@qq.com)
0 引言
构造煤是指原生结构煤在构造应力作用下,煤层物理结构甚至化学成分发生明显变化的煤体。早在19世纪20年代就有学者研究构造煤的产生和发育,至今已有研究表明煤矿瓦斯突出区域与构造煤存在着必然的联系[1-2]。变形强的构造煤储层的煤层结构及其厚度变化是影响煤与瓦斯突出的主要因素,在受到强烈流变的构造煤煤层中,煤层厚度值越大,煤层含气量越大。理论上,煤层越破碎,煤粒表面能越增加,随着煤层受到构造应力的增强,煤中大分子结构和空隙结构发生变化,从而改变了甲烷等气体的吸附能力,就会导致瓦斯压力增高,增大突出条件。事实也证明,煤体结构受到破坏的地区是瓦斯含量增高的地方,在高瓦斯矿区,顺煤层滑动构造发育的区域即是瓦斯突出区域。我国幅员辽阔,地质活动频繁,含煤地区大都经历了复杂的地质构造演化,这为我国煤层构造煤提供了发育的环境,瓦斯爆炸事故时有发生。具不完全统计,自从1950年吉林省辽源矿务局富国二矿发生我国首次有记载的瓦斯突出事故以来,我国煤矿瓦斯突出事故时有发生,人员伤亡情况严重,经济损失惨重。通过定量预测构造煤厚度来划分瓦斯突出区域,将对煤矿安全管理和煤层气的开发与利用起到至关重要的作用。传统的构造煤厚度的预测方法有煤壁观测和钻孔取芯等,其中煤壁观测法只适用于对已揭露区的构造煤进行编录,而钻孔取芯法由于其缺点明显,例如取芯率低等,也无法保证煤矿的安全生产需求[3]。
当煤层含有构造煤时,其弹性性质明显区别于正常煤层,含构造煤煤层的地震属性也明显区别于正常煤层的地震属性,因此运用地震勘探技术解决煤矿构造煤的预测成为目前解决煤矿地质问题的新方法。地震属性与煤层构造煤厚度的关系具有明显的非线性特征,而机器学习算法很适合处理这种非线性特征的相关数据[4]。极限学习机(Extreme Learning Machine,ELM)是一种单隐含层前馈神经网络,与其他神经网络算法相比,ELM有明显的优点:具有更快的学习速度;输入参数更少;可以避免局部极值问题;具有较好的泛化性能。但是由于传统的ELM算法本身存在一些问题:例如隐含层节点数量无法确定、易产生奇点问题等。针对这些问题,将核函数与传统的极限学习机相结合,提出一种核极限学习机模型,直接采用核函数代替隐含层节点的显式映射,无需给定隐含层节点数,计算速度快,泛化性能好,得到广泛应用。
本文在以上研究的基础上,将多项式核和高斯核相结合,构建混合核极限学习机(Hybrid Kernel Extreme Learning Machine,HKELM)预测模型,利用粒子群算法(Particle Swarm Optimization,PSO)较好的寻优能力,优化混合核极限学习机的核参数,并将预测模型应用至实际采区。在传统的粒子群算法[5-6]中加入模拟退火的思想、随进化次数逐渐减小的惯性权重以及基于反向学习变异操作,从而使得粒子群算法更加容易跳出局部最优,将地震属性数据运用主成分分析技术(Principal Component Analysis,PCA)降维消除相关性,然后输入构建的预测模型中,以提高采区构造煤厚度预测的精度和可靠性。
1 基本原理
1.1 粒子群算法基本原理
由于混合核参数较多,构造混合核极限学习机模型预测构造煤厚度关键的一步为优选核函数的参数。粒子群算法是一种群体智能的优化算法。
PSO算法首先在可解空间中初始化一群粒子,算法中每个粒子表示最优化问题的一个潜在解,利用位置、速度和适应度三种指标来表示一个已有粒子,其中适应度表示该粒子的优劣,其值由适应度函数计算得到[7]。粒子在解空间中运动,通过个体极值和群体极值更新个体的位置,其中个体极值是指个体所经历位置中计算所得适应度值最优位置,群体极值指的是所有粒子适应度最优的位置。粒子每更新一次位置就计算一次适应度值,并选取最优适应度的粒子更新个体极值和群体极值。
假设在一个D维的搜索空间中有个粒子组成的种群X=(X1,X2,…,Xn),其中第 i个粒子表示一个 D维向量 Xi=[Xi1,Xi2,…,XiD]T,代表寻优问题的一个潜在解。根据适应度函数初始化每一个粒子Xi对应的适应度值。设第i个粒子的速度为Vi= [Vi1,Vi2,…,ViD]T,其个体极值为Pi= [Pi1,Pi2,…,PiD]T,种群的全局极值为 Pg= [Pg1,Pg2,…,PgD]T。粒子在每一次迭代过程中更新自身的速度和位置,更新公式如式(1)~(2):

其中:ω为惯性权重;d=1,2,…,D;i=1,2,…,n;k为当前迭代次数;Vid为当前粒子速度;c1和c2为非负的常数,称为加速度因子;r1和r2为分布于[0,1]的随机数。为了防止粒子的盲目搜索,通常将粒子的位置和速度限制在[-Xmax,Xmax]、[- Vmax,Vmax]。
1.2 核函数
核函数方法的原理是通过一个特征映射可以将低维输入空间中的线性不可分数据映射到高维特征空间中的线性可分数据,其本质是对应于高维空间中的内积,从而与生成的高维空间的特征映射一一对应。这种对应关系不仅使待解决的问题变得线性可分,同时又避免了高维空间可能带来的维数灾难。
设x,z∈X,X属于R(n)空间,非线性函数Φ实现从输入空间X到特征空间F的映射,其中F属于R(m),n m。根据核函数理论,有:

其中:〈Φ(x),Φ(z)〉为内积;K(x,z)为核函数。从式(3)可以看出,核函数将m维高维空间的内积运算转化为n维低维输入空间的核函数计算,从而解决了在高维特征空间中维数灾难等问题。传统构造核函数是以Mercer定理为基础,满足Mercer条件的函数均可以作为核函数。目前使用较多的核函数主要有四类:
1)高斯核函数:
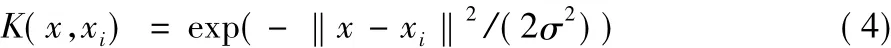
2)多项式核函数:
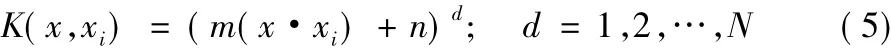
3)感知器核函数:

4)线性核函数:

此外,将简单核函数构造成复杂混合核函数仍然满足Mercer定理对核函数的要求。
1.3 HKELM的基本原理
传统的ELM是一个三层前馈神经网络,在这个网络中输入权值和隐含层阈值是随机给的,影响模型性能的输入参数是隐含层节点数,而整个模型需要训练确定的是隐含层权值,其计算过程是通过计算一个矩阵的伪逆来实现的[8-9]。
若采用(a,b)表示输入权值和隐含层阈值,样本的训练集用(x,t)表示,隐含层映射函数为g(x),输出权重为β,隐含层节点数为L,则极限学习机模型可表示为式(8):

令隐含层输出矩阵为H,则式(8)可转化为O=‖Hβ-T‖。极限学习机不断学习的过程中,误差O不断减小,当无误差学习时Hβ=T。隐含层节点数和样本数相等时,H为非奇异矩阵,β可由H的逆矩阵求出,但一般隐含层节点数要远小于样本数,H不存在逆矩阵。此时广义逆矩阵可以用于求解奇异矩阵的逆:

其中H+表示隐含层输出矩阵的广义逆矩阵[10]。
将核学习理论加入ELM模型中,隐含层将之前传统激活函数显式映射的任务交给核函数处理[11]。核函数的类型可以分为全局型核函数和局部型核函数,例如常用的高斯径向基核函数为局部型核函数,在测试点附近数据点对核函数有影响,学习能力较强但泛化能力较弱;感知器核和多项式核为全局型核函数,远离测试点的数据对核函数也有影响,泛化能力较强但学习能力较弱。
因此,本文将从两类核函数中分别选取一种核函数组合成混合核,该混合核函数将作为混合核极限学习机模型的核函数[12-13]。
2 模型优化
2.1 粒子群算法的改进
针对HKELM模型参数较多的问题,本文提出用粒子群算法进行参数寻优[14]。为了提高粒子群算法寻优能力,针对粒子群算法容易陷入局部最小的问题,对传统的粒子群算法主要作出三点改进:首先,利用模拟退火算法具有较强全局收敛性的特点,将模拟退火算法的思想引入粒子群算法,在加温、等温、冷却的过程中增强粒子的多样性,使得粒子群算法更有机会跳出局部最优的陷阱。其次,由于传统的PSO算法中,惯性权重ω表示继承先前粒子速度的能力,当ω较大时有利于算法的全局搜索能力,反之则有利于算法的局部搜索,ω值设置过大或过小容易造成PSO算法陷入局部最优或是无法真正地找出最优解。因此,加入随迭代次数减小的惯性权重,惯性权重如式(10)所示:
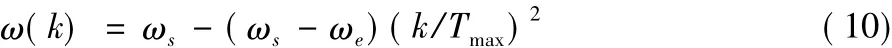
其中:ωs为初始惯性权重;ωe为迭代至最大次数时的惯性权重;k为当前迭代代数;Tmax为最大迭代代数。ω随迭代次数的增加而减小,既保证了迭代前期较强的全局搜索能力,又保证了在迭代后期粒子的局部搜索能力。最后,在粒子群算法中引入基于随机的反向学习变异操作。变异概率如式(11):

其中:P 为变异概率,且当P > 0.3时,P=0.5;Ps和Pe为常数,实验中取 Ps=0.35,Pe=0.1。变异概率随迭代次数先增大后减小,从而在一定程度上保留优秀粒子的同时增强粒子多样性。变异公式为基于随机的反向学习公式,如式(12)所示:
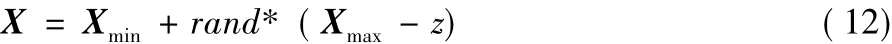
其中z为全局最佳粒子。
2.2 混合核极限学习机
极限学习机的核函数按照对数据的影响可以分为两大类,局部型核函数和全局型核函数。局部型核函数学习能力强,但泛化性能相对弱;全局型核函数学习能力一般,但泛化性能强[15]。将局部核和全局核混合成为的混合核函数具备较强的学习能力,同时又有良好的泛化能力。
通常将局部的高斯径向基核函数与全局的多项式核函数混合生成混合核构建的HKELM模型既具有较强的学习能力,又具有不错的泛化性能,因此本文在此基础上构建预测构造煤厚度的预测模型。高斯径向基核函数具有较强的学习能力,能够很容易地将训练样本在特征空间中线性分开,并能够对相距一定范围内的样本准确预测,但对超过一定范围的样本则无法准确预测。
如图1 所示,以X=0.4为测试点,分别取σ为0.1、0.2、0.3、0.4。径向基核函数具有局部特性,体现在它只对测试点附近的值产生影响,且离测试点越近的点影响越大,由此可知,局部性核函数学习能力较强,泛化能力较弱。
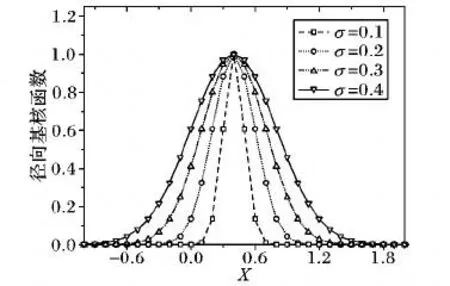
图1 径向基核函数曲线Fig.1 Radial basis kernel function curve
多项式核函数具有较强的泛化能力,对即使相距很远的样本点也能产生影响,但对局部的样本能力较弱[16]。
如图2所示,以X=0.4为测试点,m=1,n=1,分别取d为1、2、3、4。多项式核函数的全局性特性体现在与测试点相距较远的样本点也能对函数值产生一定的影响,具有较强的泛化能力,学习能力较弱[16]。

图2 多项式核函数曲线Fig.2 Polynomial kernel function curve
将多项式核函数与径向基核函数结合,得到混合核函数:

如图3 所示,以 X=0.4 为测试点,分别取 λ 为0.2、0.3、0.4、0.5,σ取值为0.1,d为2。由图3可以看出,混合核函数不仅对测试点附近的样本具有一定的影响,并且当样本点远离测试点时,仍能产生影响。因此,混合核函数结合了多项式核函数和高斯径向基核函数的特点,有效地弥补了单核核函数的缺点,从而提高了拟合能力。
此外,为了防止模型复杂度过高引起过拟合现象,在核函数的基础上加入L2正则项,有效地避免了噪声和异常点对模型泛化性能的影响。

图3 混合核函数曲线Fig.3 Hybrid kernel function curve
2.3 算法描述
改进PSO优化混合核极限学习机参数的算法具体过程如下:1)数据标准化,进行主成分分析处理,保存结果集备用;2)将σ、m、n、λ设为粒子(d=2),随机初始化粒子的位置和速度;
3)根据式(13)计算训练集隐含层节点的输出,并加入L2正则项;
4)计算隐含层输出权值矩阵;
5)计算验证集隐含层节点的输出,并根据隐含层节点输出计算得到测试集的预测值;
6)将均方误差mse作为粒子适应度,计算个体极值和种群极值;
7)根据更新公式更新粒子位置和速度;
8)根据变异概率进行粒子变异;
9)计算更新后粒子的适应度,更新个体极值和种群极值,若未满足最大迭代次数,则返回7),否则继续10);
10)保存种群最优适应度对应的粒子,即最佳混合核函数参数,将参数代入HKELM模型,获得预测构造煤厚度的预测模型,并用测试集进行测试。
由于混合核极限学习机参数较多,而用传统的粒子群算法优化混合核极限学习机无法找出最优参数下的预测模型,加入随迭代次数逐渐减小的惯性权重、模拟退火思想以及基于反向学习的变异公式使得PSO在寻优能力和收敛速度上都有了改善。相比传统ELM激活函数的显示映射,混合核函数在较优的参数下,兼顾了数据的局部性和全局性,既具有较强的学习能力,又具有较好的泛化性能。因此,通过改进PSO寻找到最优的核函数参数,获得最优核参数下的HKELM模型,理论上可以作为预测构造煤厚度的预测模型。
2.4 预测模型建立
2.4.1 测试数据
为了建立适合构造煤厚度预测的HKELM模型,首先建立了构造煤模型如图4所示,煤层的顶底板参数为最薄处为0 m,最厚处为10 m;原生煤最薄处为0 m,最厚处也为10 m;直接顶/底是厚度为2 m的泥岩,老顶/底为砂岩。根据褶积模型,利用主频为50 Hz的Ricker子波进行正演模拟,获得其对应的正演地震剖面。利用图4所示的构造煤模型正演地震剖面如图5所示,分别提取出剖面中的正负相位的地震属性。
利用图4、图5建立的模型,以所提取出的负相位地震属性为例,分别进行有噪声与无噪声数据进行测试。地震属性维数较大,为去除属性中的相关属性,实验使用PCA对地震属性进行降维去噪,取累计贡献率大于95%的主成分并求其主成分得分作为实验数据进行后续的实验分析。

图4 构造煤模型Fig.4 Tectonic coal model
2.4.2 参数设置
在运用改进的粒子群算法优化混合核极限学习机构建的构造煤厚度预测模型中,学习因子c1、c2均设置为2,最大迭代数MAXGEN=300,种群粒子数SIZEPOP=20,模拟退火算法初始温度T=100,退火常数L=0.25,初始惯性权重ωs为1.2,迭代至最大次数时的惯性权重ωe为0.4,核极限学习机中核函数的参数由改进粒子群算法寻优得到。此外,为了探究本文提出改进的模型预测性能,将改进后的模型与传统的BP神经网络和用K折交叉验证方法优化参数的支持向量机(Support Vector Machines,SVM)进行预测结果对比。其中BP神经网络采用Matlab自带函数newff()建立模型,输入层神经元为9,输出层神经元设为1,隐含层神经元数设为10,输入层和隐含层、隐含层和输出层之间的传递函数分别选择tansig和logsig函数,最大训练次数设为500,学习速率为0.1,训练算法设置为 LM算法,动量因子为0.9,期望误差设置为10-3,性能函数采用均方误差函数(Mean Squared Error,MSE)和决定系数(Coefficient of Correlation)记为R2。利用Libsvm工具箱建立SVM预测模型,交叉验证数的参数v设置为5,即参数c和参数g由5折交叉验证得出,其中搜索空间为[-30,30],步长设为0.5,核函数类型参数t设置为2,即采用径向基函数作为核函数,支持向量机的类型参数s设置为3,即使用εSVR类型,即ε-支持向量机回归算法,εSVR中损失值 ε 设置为0.1。
2.4.3 测试结果
无噪声数据提取出26个地震属性,通过PCA属性降维获得7个线性不相关属性。含噪声数据获得11个地震属性,进行属性降维获得9个线性不相关属性。两种数据集分别取98个样本进行实验并随机抽取其70%作为训练集,剩余30%作为测试集测试改进PSO-HKELM模型。预测结果如图6所示。
图6预测结果显示,在无噪声数据集下,改进的粒子群算法优化混合核极限学习机构建的构造煤厚度预测模型有很好的拟合效果,拟合度可以达到0.989,均方误差为0.0041971;而含噪声数据集的预测结果比无噪声数据集的预测结果要差,拟合度为0.9293,均方误差为0.0195,但在噪声数据的影响下,同样体现了较好的拟合效果。

图6 模拟不同数据预测结果Fig.6 Prediction results of simulating different data
目前国内外已有利用智能算法预测构造煤厚度的研究[17],为进一步验证模型的优劣,在当前学者研究的基础上,将改进的粒子群算法优化混合核极限学习机构建的构造煤厚度预测模型分别与用K折交叉验证方法优化参数的SVM模型以及BP神经网络进行实验比较[18]。取98个含噪声数据集样本进行实验构建模型,每个模型分别运行10次,且每次均随机抽取其70%作为训练集,剩余30%作为测试集,预测结果如图7所示。

图7 不同算法预测结果比较Fig.7 Comparison of prediction results of different algorithms
由图7可以看出,采用的改进PSO-HKELM模型的预测准确率明显高于另两个模型预测准确率。在10次实验中,改进PSO-HKELM模型的平均预测准确度达到90%以上。此外,将运行时间作为判断预测模型时间复杂度的标准,模拟含噪声数据在相同环境和参数下运行5次,运行时间如表1所示(保留两位小数)。
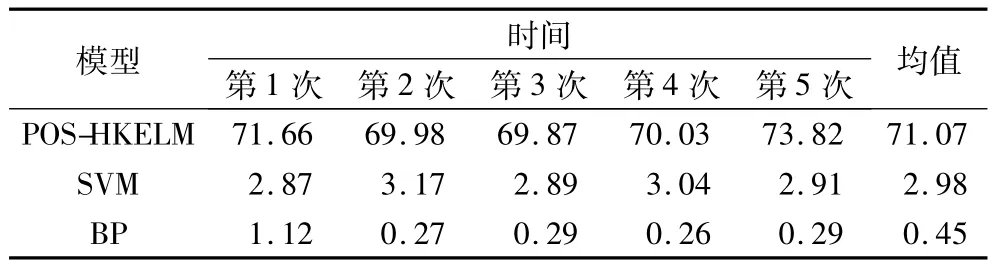
表1 模拟含噪声数据的运行时间 sTab.1 Running time of simulated data with noise s
由表1可以发现,改进模型运行时间较长,算法复杂度较高,但考虑到其预测精度提高较为明显,预测结果较为稳定,且在实际开采中,预测构造煤厚度对实时要求不高,因此,本文提出的一种改进PSO-HKELM预测模型在预测构造煤厚度上的运用是可行的,且预测效果较好。
3 实例预测
3.1 研究区概况
本文选取阳煤集团新景煤矿芦南二采区中部的15#煤层作为研究区域,结合实际地震属性,对构造煤厚度进行预测。阳煤集团新景煤矿底层层滑构造特征明显,瓦斯含量较高,极易发生煤与瓦斯突出,因此阳煤集团新景煤矿成为研究煤与瓦斯突出课题的理想区域。新景煤矿二采区面积为3.42 km2,其中15#煤层埋深 575.9 m ~640.93 m,平均深埋623.8 m,煤层厚度为6.25 m ~10.4 m,平均厚度 7.925 m;构造煤厚度为0 m~4.3 m,平均厚度为1.57 m。钻孔共有10口,详细情况见表2。
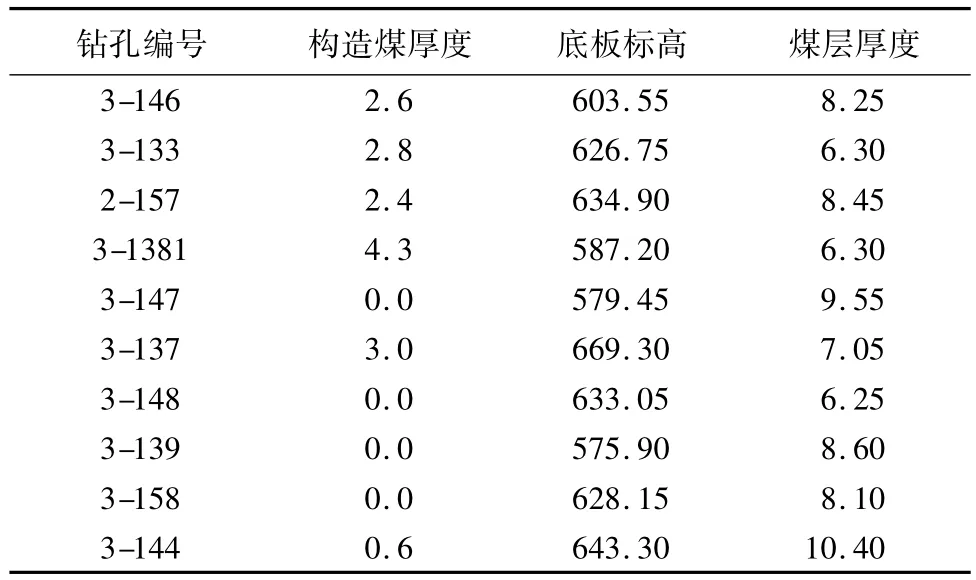
表2 15#煤层钻孔揭露煤层信息 mTab.2 Exposing coal information of drills in 15#coal seam m
根据钻孔揭露的煤层厚度和构造煤厚度,插值生成煤层厚度分布图,如图8所示。
3.2 构造煤厚度的预测
利用第2章建立的预测模型,对研究目标区域的构造煤厚度进行预测。如果只采取已知的10口钻孔数据作为训练样本,则训练样本太少,预测模型的可靠性难以保证。因此,将钻孔附近较小范围内(15 m×15 m)的地震属性提取出作为训练集(共2232个样本),以提高训练集的数量。15#煤层收集地震属性共14维,首先对14维数据进行主成分分析,降维后的数据变为6维。然后采用2232×6的数据训练构造煤厚度预测模型。将BP、SVM和改进PSO-HKELM模型分别运用到整个15#煤层的构造煤厚度预测中,将三种方法预测出的10口钻孔处的构造煤厚度提取出来,与实际的钻孔数据作对比。10口钻孔的值与预测误差如表3所示。

图8 15#煤层厚度分布Fig.8 15#coal seam thickness distribution

表3 不同方法钻孔处预测值对比 mTab.3 Prediction value comparison of drilling holes of different methods m
由表3可以得出,其中改进PSO-HKELM模型预测出的相对误差最小,误差均值为0.05(其中最大误差为0.06,最小误差为0.00),而且预测结果均比较稳定;K折交叉验证方法优化参数的SVM的预测精度其次,误差均值为0.21(其中最大误差为0.97,最小误差为0.00);BP效果最弱,误差均值为0.27(其中最大误差为 1.02,最小误差为 0.01)。因此,利用本文提出的改进PSO-HKELM模型在构造煤厚度的预测上效果更好。
数据经过PCA处理,运用改进PSO-HKELM模型预测出的构造煤厚度分布图如图9所示。

图9 预测目标区构造煤厚度分布Fig.9 Distribution of tectonic coal thickness in prediction target area
根据图9总体上可以看出,预测分布图与煤层整体的构造煤分布具有很高的一致性。构造煤主要分布在井3-1381、井3-146和井3-137为中心的三个独立区域。
4 结语
本文利用地震属性预测构造煤厚度,首先运用主成分分析的方法对数据进行预处理,然后针对传统预测方法的不足,建立了改进的PSO-HKELM的构造煤厚度预测的模型。采用较为常用的高斯核和多项式核组合成为混合核极限学习机的核函数,并用改进的粒子群算法对混合核参数进行优化。在改进的粒子群算法中加入模拟退火的思想、随迭代次数减小的惯性权重以及基于随机反向学习的变异操作,能有效地弥补粒子群算法较易陷入局部最优的缺点。最后,将建立预测模型应用于阳煤集团新景煤矿#15采区的实际煤层。通过模拟数据和新景煤矿#15区煤层数据的实验分析,采用改进的PSO-HKELM算法对构造煤厚度建立预测模型,其性能将优于传统的BP神经网络和用K折交叉验证优化参数SVM预测模型,且其精度较高,为预测煤矿采区煤与瓦斯突出形势提供了一种可行的新途径。构建的混合核极限学习机的构造煤厚度预测模型可以较为准确地预测实际采区构造煤厚度,但预测结果受地震属性信噪比的影响较为严重,当训练数据中含有噪声的样本较多时,预测结果不理想,因此寻找一种降低数据信噪比的处理方法需要进一步的研究。
猜你喜欢
选煤技术(2022年3期)2022-08-20
昆明医科大学学报(2022年1期)2022-02-28
煤(2021年12期)2021-12-17
文萃报·周五版(2021年30期)2021-09-05
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
消费导刊(2017年24期)2018-01-31
北京航空航天大学学报(2017年6期)2017-11-23
山东工业技术(2016年15期)2016-12-01
