
多源异构土地基础数据一体化管理检索方法研究
2018-09-10 09:50张书瑜张定祥王荣彬季宏伟
浙江大学学报(理学版) 2018年5期
张书瑜,张定祥,王荣彬 ,季宏伟
(1. 浙江大学 地球科学学院, 浙江 杭州 310027; 2. 中国土地勘测规划院, 北京100035)
0 引 言
我国在土地调查、监测和评价项目中已积累了海量基础数据,涵盖土地利用、变更、监测、评价、规划等方面,涉及土地、测绘与遥感、自然地理、社会经济统计等多个专题分类. 海量数据成果为国家土地管理和宏观决策提供了有力的数据支撑,但其海量性和多源异构性也对数据管理的有效性和数据检索的快捷性提出了巨大的挑战. 基于ArcGIS、SuperMap[1]实现的土地管理信息系统可对传统的土地时空数据进行有效的管理和检索,但对数量和复杂程度呈几何级数增长的多源异构土地时空大数据而言,这些方法易导致计算效率低、扩展检索难等问题. 文献[2]设计的基于Hadoop集群计算的土地时空大数据集成平台框架可大大提升海量数据的管理、处理和服务性能,但在用户检索模块中缺乏灵活的数据搜索引擎. 因此,开发更加实用高效的土地时空大数据管理检索一体化框架是一个重要的研究课题.
垂直搜索是专门为某一学科或主题的数据而设计的信息查询方式,适用于解决针对性强和精确度要求高的实际查询问题. 垂直搜索较综合搜索具有更高的查准率和相关度,通常基于原始数据提取后的结构化信息进行检索,检索结果排序方式可由用户设定[3]. 垂直信息检索在电子商务、影视娱乐、教育资源、旅游等行业的应用越来越广泛,而在土地数据领域的应用还较少. 构建垂直搜索引擎时对结构化信息进行进一步的分类和去重处理有助于提高检索的效率和准确度[4],元数据技术是实现海量数据资源结构化信息提取的主要手段,有助于快速搜索、提供关键信息、管理和维护、数据共享等[5],但针对多源异构的土地基础数据进行规范化元数据提取的研究较少. 基于数据库技术实现的土地管理系统[6]在信息检索方面存在模糊匹配不精确和无相似度排序等不足,而基于全文索引技术实现的垂直搜索引擎[7],可通过中文分词、反向索引和相似度算法较好地实现信息检索,但对于信息提取后的结构化土地数据而言,直接应用全文索引技术仍存在不同字段信息之间相对权重差异无法体现、土地领域一义多词现象检索不全的问题. 基于关键词匹配的传统自然语言检索模型,文献[8]通过本体概念扩展策略提高了信息检索的查全率和查准率;文献[9]通过术语同义词扩展提高了信息检索的性能. 但对于海量土地基础数据而言,构建完整的领域本体模型及逻辑计算体系难度很大,且易导致模型计算复杂和检索效率低下. 所以,同义词扩展方式的适用性更强.
本文研究适合海量多源异构土地基础数据的管理检索一体化方法框架,旨在提高管理和检索过程中信息的融合程度、计算效率、检索准确率和查全率. 基于元数据技术和土地数据标准规范实现复杂土地数据的结构化信息提取,并采用反向索引技术进行信息加权优化,实现更为精准的土地数据检索计算和排序;通过同义词扩展方式,结合地名和土地数据层实体,实现灵活有效的土地数据检索过滤和匹配,以此管理检索一体化方法框架,推动土地时空大数据共享服务平台的建设和发展.
1 元数据信息提取
土地基础数据包括空间与非空间数据集,空间信息以矢量、栅格、空间数据库为主,记录了土地利用现状、土地规划布局、遥感监测影像等与空间位置相关的数据,包括shp、shx、sbn、sbx、prj、img、tif、tiff、dxf、tfw、gdb等多种文件格式;非空间信息以文档、统计表、非空间数据库为主,记录了行政区划土地统计、土地业务标准规范、土地调查报告等非空间数据,包括doc、docx、pdf、xls、xlsx、mdb、txt、psd、xml等多种文件格式. 这些数据文件来自多个地方国土部门和多个土地业务流程,存在格式多样、目录结构不一、分布不均匀等问题. 元数据是说明数据的数据,可以描述土地基础数据的内容信息、地理覆盖范围、数据质量、数据所有者和分发者、数据格式等多方面的信息. 应用元数据技术从多源异构的土地基础数据中提取结构化信息,需要基于国家地理信息标准和土地领域元数据规范进行实体图和数据表结构设计[5].
本研究中,土地基础数据共享元数据的设计参考《地理信息元数据》GB/T 19710-2005、《国土资源信息核心元数据元素列表标准》TD/T 1016-2003、《地理信息共享元数据国家标准(附录K)》GB/T 19333.15-200X/ISO 19115: 2003等标准规范. 由于土地基础共享数据包括空间信息和非空间信息,在文档和统计表等非空间数据的元数据描述中并不涉及空间参照系统等空间信息,因此,部分空间实体和属性是可选的. 核心元数据聚合实体包括: 标识信息、数据质量信息、内容信息3个必选实体,以及分发信息、空间参照系统信息2个可选实体,核心元数据聚合实体本身,包括日期和负责单位信息2个必选要素. 标识信息实体中,对矢量和栅格数据而言,除共同的地理范围和地理描述属性外,描述空间信息的属性是条件必选的,矢量数据具备表示方式和比例尺属性描述,栅格数据具备空间分辨率、卫星类型、影像类型、影像轨道表示和垂向范围信息属性描述. 内容信息实体中,矢量描述属性包含了图层名称、要素类型名称和属性列表,而栅格描述属性包括了栅格影像内容描述.
以土地基础矢量数据为例,共享元数据设计框图如图1所示.

图1 土地基础矢量数据共享元数据设计框图Fig.1 Design of sharing metadata entities of land basic vector data
2 基于元数据的加权索引
信息检索中常用的索引和匹配方法为基于向量空间模型和TF-IDF算法[10],从原文件文本中提取特征向量表示该文档,选择索引词并计算权重. 通过建立专业领域词典和停用词典简化分词和识别词组,并高效获取候选特征词集[11]. 本研究基于采集的多源异构土地基础数据的结构化元数据信息进行索引构建和数据检索,从而解决了多种数据格式,尤其是复杂的时空数据,不便于提取特征向量和构建索引的问题.
首先,采用文献[12]中的层次隐马尔可夫模型(HMM)进行中文词法分析和分词切分,并导入经整理的土地基础数据字典和地理行政单元字典,以提高土地专题数据名词和地理名词识别的完整性和准确率. 其中,采用N-最短路径作为切分排歧策略,在初始阶段保留切分概率最大的N个结果,词法分析后通过评价函数计算真正的最优结果. 该思想是最少切分方法和全切分方法的泛化和综合. 在基于类的隐马尔可夫模型中,最终取概率最大的分词结果. 利用贝叶斯公式和一阶HMM展开,得到计算公式:
(1)
其中,W=(w1,w2,…,wn)为一个可能的分词结果,W=(c1,c2,…,cn)为对应的类别序列,W#为最终的分词结果.
其次,考虑到TF-IDF算法无法全面反映特征词条在各文本分类中的分布,本文采用引入了信息熵因子的TF-IDF算法[13],以反映特征词条在不同级别土地专题分类文本中的分布情况,其计算公式为
Wj(ti)=TF(ti)×IDF(ti)×μ(I(p)),
(2)
其中,
TF(ti)为特征词条ti的词频值,即ti在文档j中出现的次数占该文档总词数的比例;IDF(ti)为逆文档概率值,即包含ti的文档数占总文档数比例的倒数再取对数值;μ(I(p))为信息熵因子值,即ti分布信息熵的倒数,而分母是不能为0的,因此在分母上加上词条信息熵的次小值[13].
另一方面,如果直接对土地基础数据的所有元数据字段进行分词、TF-IDF值计算和构建索引,会导致不同字段信息的相对权重差异无法体现,因为元数据字段中有重要的必选字段和次重要的可选字段. 例如一个数据的标题中包含用户检索的查询词汇,而另一个数据只在内容描述中包含该词汇,显然,标题中包含查询词汇的数据与用户检索的相关度更高,因此,需要根据元数据中字段的重要性对分词TF-IDF权重值进行加权计算,使查询效果更符合用户的检索需求. 在空间、时间和内容3个维度的所有元数据字段信息中,因空间和时间维度信息较重要,会基于识别和提取的方式对其主要的时间名词和地理名词构建相应的反向索引表;而内容维度中的标题和关键词字段信息较文件摘要和内容描述等字段信息更重要,可简明扼要地概括数据的主题内容. 采用以下公式计算每一条元数据记录的特征向量的TF-IDF权重:
TF_IDF*(ti)=TF_IDF(ti)×Wc(Cj(ti)),
(3)
其中,TF_IDF*(ti)是考虑元数据字段重要性加权后的新TF-IDF权重,TF_IDF(ti)是未考虑重要性加权的原TF-IDF权重,Cj是ti词汇所出现的相对较重要的字段,Wc是Cj字段相对重要的权重,该权重值可以使不同元数据记录中出现在不同字段的同一个特征分词具有差异.
3 基于实体同义词的检索扩展
3.1 地名实体的提取和匹配
在土地基础数据的空间维度信息中,除了用地理坐标表示的空间位置和地理范围外,还有数据文件对应的地理行政单元信息,对于土地业务用户而言,地理行政单元是其更为关注和常用的检索词汇. 地理行政单元体系是非扁平化和非单一化的,既存在省、市、县等相互之间的层级包含关系,也存在同一地名实体有不同文本表达的复杂性(例如,“杭州”“杭州市”“330100”,都表示杭州这个地名实体),因此,需要构建地名实体模型,对土地基础数据和用户检索语句中对应的地名实体进行明确表达,并对两者之间地名实体匹配进行精确的关联计算.
文献[14]利用地名语义实现了Web地震事件的空间信息提取,通过构建地名本体库和标准化地名提取地震事件的地点信息,并通过语义库和推理机制搜索地名标定范围内的地震事件. 本文构建的地名实体库亦基于2条基本的推理规则: 地理行政单元的层级包含规则和地名实体的同义表达规则. 只是在同义表达规则中增加了地理行政编码表达方式,尽管用户一般不会采用地理编码方式查询语句,但土地基础数据中有大量矢量和栅格数据是以地理编码方式表达地理信息的,因此,地理编码方式对于从数据中提取地理信息必不可少. 基于国家地理行政单元体系的地名本体库结构如图2所示,其中“包含”层级为“父类”,“被包含”层级为“子类”.
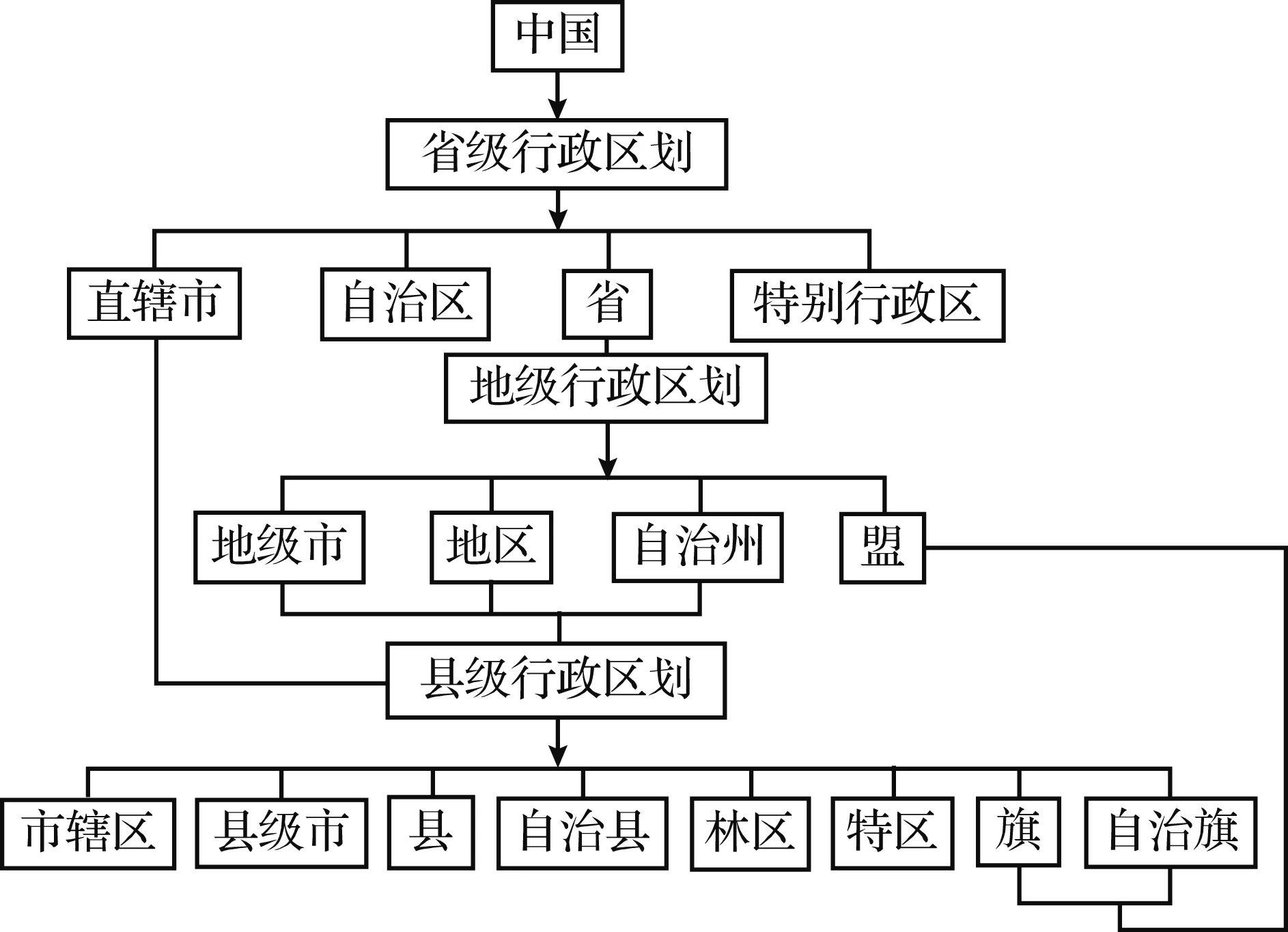
图2 地名实体库结构图[14]Fig.2 Structure of toponym entity database
对地名实体进行提取时,需要明确其边界范围,利用地名语义库、词性、句法和词法分析以识别同等边界范围的地名实体. 例如,“浙江省杭州市”的等价地名实体是杭州,而不是“浙江”或“浙江和杭州”;“浙江省和杭州市”则指浙江和杭州这2个地名实体,而非只浙江或杭州一个地名实体. 因此,首先利用中文分词技术对字段文本进行切分,分别标注名词、动词、形容词、副词、介词等,对其中的名词细化标注为普通名词和地名等;然后将其中的地名与地名语义库进行匹配,并根据文本中介词的逻辑语义得到同等地名实体.
3.2 专题数据层的提取和匹配
土地基础数据中的矢量和栅格数据大多具有规范化的命名规则. 土地利用、管制、整治或规划图等的数据命名规则为“地理行政编码+专题数据层缩写词”,例如,“500232024TDZZGHT.JPG”为重庆武隆县土地整治规划栅格图数据,“500242JQXZDW.shp”为重庆酉阳县乡级基期线状地物矢量数据. 对于图层内容类土地专题数据层缩写词,单纯进行字面匹配对于信息检索而言是不够精确的,因此需要构建土地专题及数据层的语义库进行同义转换. 以县级土地利用目标年规划数据为例,整理的专题数据层缩写词如图3所示.
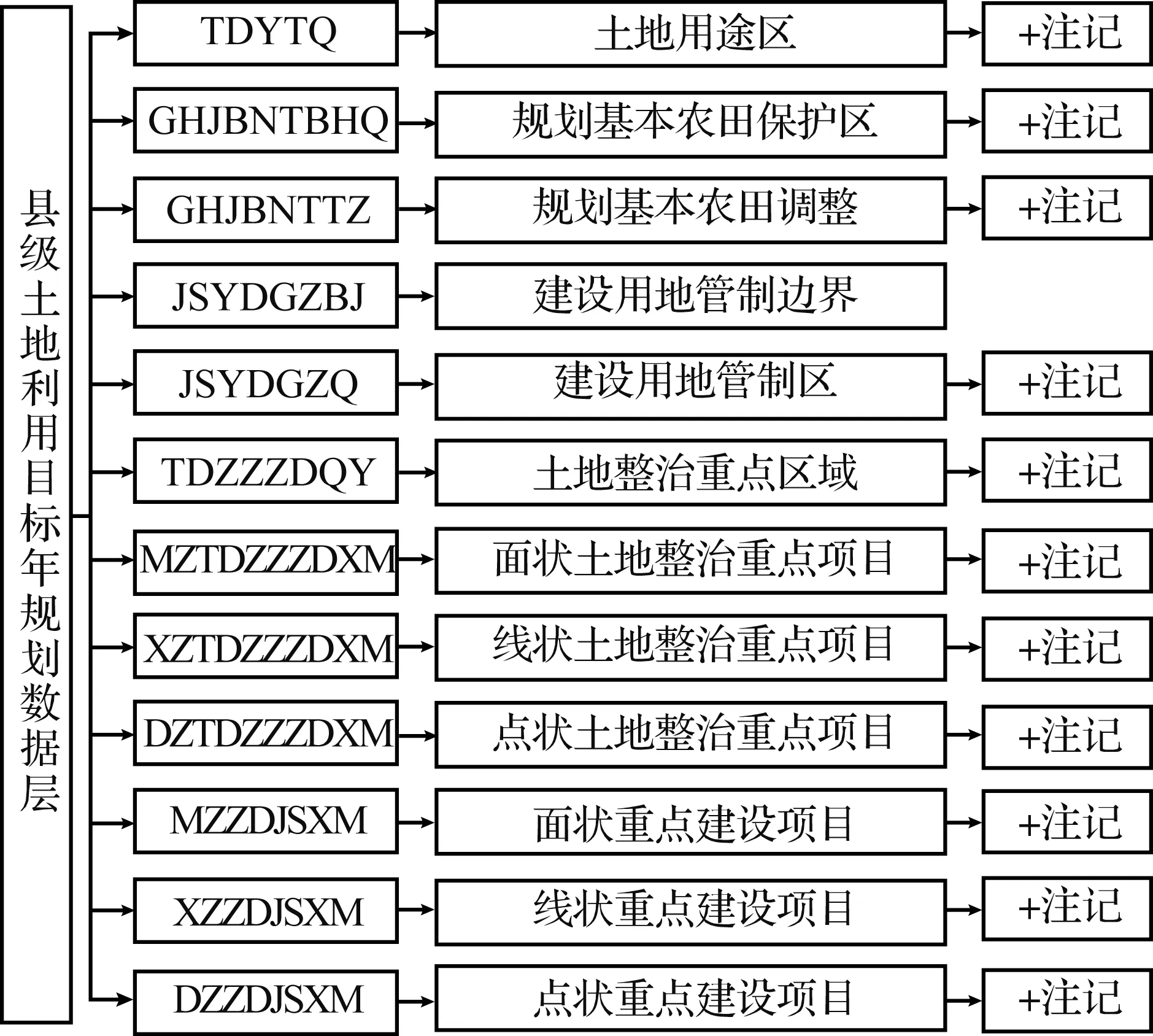
图3 县级土地利用目标年规划专题数据层缩写词Fig.3 Thematic data layer acronym of land use planning for target year at county level
土地基础数据可根据专题领域划分为层级式的专题结构,包括一级专题和二级专题. 一级专题主要涵括土地详查、土地资源大调查、城镇地籍调查、全国土地调查、土地利用总体规划、城乡土地价格监测、土地利用变更调查及其监测核查八方面. 不同专题包含的数据文件格式和类型不同,其中矢量和栅格数据多以地理行政单元编码和土地专题数据层缩写词命名. 以年度土地利用变更调查成果一级专题为例,包括基础地理要素、土地权属要素、基本农田要素、土地利用要素、栅格要素、其他要素等. 其中,空间要素采用分层(层名称及各层要素)的方法进行组织管理,每个空间数据层都有原词和缩写词2种名称,以构建土地专题及数据层的语义库,在信息检索时进行同义转换,提高数据检索的查准率和查全率.
4 管理检索一体化方法框架
在本研究的开发实践中,基于Visual Studio 2010(.NetFramework 4.0)开发环境,采用C#语言,利用Arc Engine 10.1和DevExpress 13.1开发了土地基础数据半自动化元数据采集工具. 使用该元数据采集工具,从北京市2015年的多源异构土地基础数据中提取元数据信息,并整理入库,数据库采用MySQL 5.5软件. 在元数据字段的相对重要性权重计算中,标识信息的权重设置较数据质量信息和内容信息等的权重高,数据文件的标题和关键词字段的权重较摘要和概述等的权重高. 基于提取的土地基础数据元数据信息进行中文分词和加权TF-IDF值计算,构建分词的反向索引表数据库.
在用户进行土地基础数据的检索查询时,首先对用户查询语句进行分词处理,并基于专题数据层和地名实体同义词库进行检索扩展,对于地名实体,可考虑是否选择父子类地名扩展查询,即检索结果中是否包含上下级行政地名的土地基础数据,若包含,则上下级地名与检索条件的相关度低于原地名,用扩展的地名条件进行检索可以获得更加全面和精确的结果. 然后,根据扩展的检索语句分词在索引库中搜索和过滤相关的土地数据记录,并采用向量空间模型的余弦相似性原理计算检索分词向量与数据特征向量之间的相关度,最后按相关度从高到低进行排序,并将检索结果返回给用户. 检索流程如图4所示.
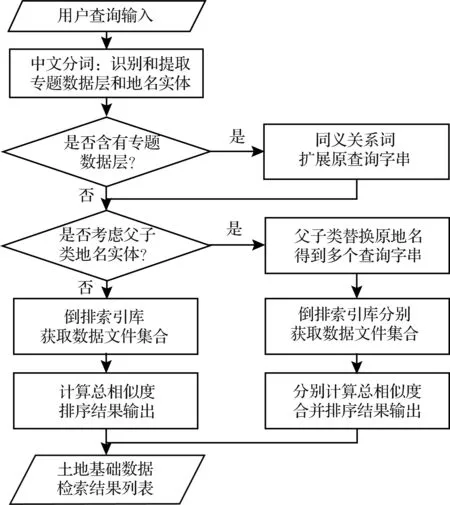
图4 土地基础数据检索流程Fig.4 Retrieval process of land basic data
实践证明,本文提出的基于元数据的管理检索一体化方法的框架有助于实现多源异构土地基础数据的统一管理和精确检索,在检索效率和满足用户需求方面都有很大的提升.
5 结 论
结合土地领域专业知识和用户实际需求,提出了适用于多源异构土地基础数据信息管理检索一体化方法的框架,以实现多源异构的复杂土地基础数据的统一管理和精确检索. 针对元数据信息提取,根据国家元数据标准和土地领域元数据规范的相关文件,设计了土地基础数据的实体图和元数据表结构,并开发了元数据采集工具;在基于元数据的加权索引中,在传统的TF-IDF向量权重计算基础上考虑了元数据不同字段的相对重要性以及信息熵因子,使结果更符合土地领域知识和用户检索需求;在基于实体同义词的检索扩展中,构建了地名实体同义词库和专题数据层实体同义词库,较好地实现了用户查询语句的检索扩展,提高了检索的全面性和准确率;最后,将这些适用于多源异构土地基础数据的优化改进方法集成于管理检索一体化方法框架中,开发了相应的检索应用系统.测试表明,对于多源异构的复杂土地基础数据,本文提出的基于元数据的管理检索一体化方法框架,较于传统的通用信息检索框架,具有更好的适用性和更高的准确率.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
中国外汇(2019年18期)2019-11-25
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
当代陕西(2019年5期)2019-03-21
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
