
熵增强的混沌粒子群算法在车间调度中的应用*
2018-10-09 06:37黄英杰姚锡凡申辉阳
组合机床与自动化加工技术 2018年9期
黄英杰,姚锡凡,申辉阳
(1.广东机电职业技术学院 电气工程学院, 广州 510515;2.华南理工大学 机械与汽车工程学院,广州 510640)
0 引言
1995年,粒子群优化算法(PSO)首次由Eberhart与Kennedy博士提出[1],它是一种以随机搜索为基础的优化技术,当今甚为流行,其思想起源于模仿鸟群或者鱼群的社会行为。在过去几年,粒子群优化算法已成功应用于很多研究和应用领域中,与其它的方法相比,粒子群算法能更快、更方便地获得较好的最优解。混沌搜索算法是一种新型的随机任意搜索算法,遍历性、随机性和敏感性是其主要特征,卓越性十分显著。而信息熵则是由美国学者Shannon于1948年将热力学熵引入信息论而提出的,其为不确定方法的一个重要概念,常被用于较简略地给出难以精准确定的度量,系统有序性愈强,则信息熵愈低;相反,前者愈低,则后者愈高。
Job Shop调度问题是企业生产活动中出现频率较高的一种车间调度问题,同时也是很多此类实际问题的简单模型,而且被归入NP-hard问题当中。由于调度在车间中的重要性,引起人们对Job Shop调度问题的不断探索,至今已经有很多算法用于求解这类调度问题,如文献[2]通过改进的粒子群算法对柔性车间调度问题进行求解,文献[3]通过遗传退火算法对上述问题进行解答,文献[4]借助小生境粒子群算法对柔性车间调度问题加以解答,文献[5]借助邻域搜索算法对Job Shop调度的问题进行解答,然而根据研究的结果[6]发现,单独的一种算法能较好地求解小规模的车间调度问题,而对于大规模的车间调度问题,单独的一种算法求解的效果并不理想。本研究把粒子群算法和混沌搜索算法相结合,并基于信息熵的思想,提出一种能有效克服局部收敛,用于求解大规模车间调度问题的熵增强的混沌搜索粒子群算法(entropy-enhanced PSOCH, EPSOCH)。
1 用于车间调度的粒子群算法
Job Shop调度问题可以描述为:有一组部件要在一组机器上完成加工,每一个部件都包含有多个作业,而作业有固定的工作顺序,某个任务仅可在某台机器上进行加工制造,而加工时间保持不变,已经获悉所有部件在各个机器中的加工顺序制约,要求规划与工艺制约规范相契合的各个机器上全体部件的加工顺序,使整体的加工性能指数达到最优,显然Job Shop调度问题属于组合优化问题,同时极具代表性,而且证明是一个NP-Hard问题。一般Job Shop调度问题假定下述条件:在整个加工期间,部件不可在相同的机器上进行多次加工;只有在结束上一步操作之后,才可进入下一步操作,另外,每一个机器在相同的时间里只可进行一项加工;部件必须严格遵照工艺路径依次完成机床上加工;不考虑工件加工的优先级;每一个部件只要开始作业就不可中断;单个机器每一次只可对一个部件进行处理,同时每一个部件在特定的时间段也只可在一个机器上完成加工,计时从零开始。
粒子群优化算法(PSO)是一种以种群为基础的随机优化技术,对鱼群或者鸟群的社会行为加以模拟。粒子群算法和演化计算技术颇为接近。PSO 初始化是一群随机任意粒子,并借助迭代搜索得到最佳解。每完成一次迭代,粒子在自我更新的时候都必须对两个极值进行跟踪。在粒子群中,粒子本身就是潜在的解,通过跟随当前最佳粒子来搜索问题的解空间。每个粒子在解空间中跟踪自己已经获得的最优解来形成自己的路线,这个值称为个体最优位置Pi。粒子群算法跟踪的另一最优解为比较粒子邻域中的任何粒子而获得的最优解,也就是所谓的局部最优解,当所选的粒子种群中的所有粒子都被遍历之后,比较所有的局部最优解会得到一个全局最优解Pg。粒子群优化是在每一次迭代中将每个粒子冲向局部最优解位置和个体最优解位置速度改变,这两个速度随机产生,相互独立。粒子群算法的标准模型公式为:
vij(t+1)=wvij(t)+c1r1(t)(pij(t)-xij(t))+
c2r2(t)(pgj(t)-xij(t))
(1)
xij(t+1)=xij(t)+vij(t+1)
(2)
式中,惯性系数由w代表,目前的迭代次数由t表示,粒子的维数由j表示,其飞行速度由vij表示,其位置由xij表示, 其加速常数 由c1与c2表示,通常取值2。r1,r2是分布于[0,1]区间的随机数。为了避免粒子在搜索的时候过于盲目,通常提议将其速度vij局限在一定的范围[-vmax,vmax]内,将其位置xij局限于相应的范畴[-xmax,xmax]内。
在对粒子群算法进行设计期间,应对编码问题加强重视,譬如车间调度的此算法编码即选择使用以操作为基础的编码。换言之,即每一个工序向量通过j个表示操作的位构成,是全体操作的一个分布。比如编码为[1 2 3 2 1 3 1 3 2],编码中的自然数表示工件的编号,不同位置上的同一工件编号表示部件的不同工序,比如编码中第1维的“1”代表部件1的首道工序,而中第5维的“1”代表部件1的第二道工序,第7维的“1”即表示部件1的第三道工序,其他部件也是同理。
作业车间调度的问题即为离散的非数值优化的问题,然而粒子群算法属于连续空间的优化算法,所以在迭代运算期间加以相应更改。
之所以选择使用迭代运算,是因为车间调度优化问题是工序次序的排列问题。假设初始值为:
维数:1 2 3 4 5 6 7 8 9
X[j]:1 1 1 2 2 2 3 3 3 (初始值)
经过公式(1)的飞行运算得到如下的结果:
X[j]:0.13 0.26 0.91 0.19 2.53 1.24 0.84 2.41 1.53
初始值: 1 1 1 2 2 2 3 3 3
根据自小至大的次序对计算后的X[j]加以排列,对运算后的数值所对应的初始值加以再次列序,具体结果如下:
计算后的值排序:0.13 0.19 0.26 0.84 0.91 1.24 1.53 2.41 2.53
X[j]: 1 2 1 3 1 2 3 3 2
此次迭代运算得出[1 2 1 3 1 2 3 3 2]的结果,通过如此排序即可获取与要求相符的数值。
适配值的计算方法一般是将目标函数直接作为适应度函数,因此车间调度把各工件在机器上的最后完成时间作为适应度函数,个体适应度函数值越小,则代表其具有的适应度越高,个体就更可能变为最优解。
标准的粒子群算法虽能较好地求解小规模的车间调度问题,但对于大规模的车间调度问题,标准的粒子群算法求解的效果并不理想。因此,这里需要设计一种更好的混合粒子群算法,可以更好地对各种车间调度问题进行解答。
2 基于熵的混沌粒子群算法
2.1 混沌搜索算法
随机性、遍历性及敏感性是混沌的基本特征,看上去不甚清楚,但其实内里却具有一定的规律,对最初条件的敏感性极高,可以在相应的范畴里根据自身规律将全部的状态经历一遍,而且不得对统一状态进行重复[7]。造成混沌的规则很多,Logistic映射就是一个极具代表性的此类系统,迭代公式为:x(t+1)=μx(t)(1-x(t)),其中,0≤x(t)≤1,μ代表控制变量,当μ=4的时候,系统处于混沌状态,具体优化的基本思想是:先生成一组和优化变量数量一致的混沌变量,然后通过载波的形式将其值域放大至优化变量的取值范畴空间,然后直接借助混沌变量的规律性及遍历性完成搜索。
2.2 混沌粒子群算法
标准的粒子群算法不但使用简单、易实现,而且在全局寻优方面功能显著,然而规范的粒子群算法对种群的初始化则为随机产生的形式,因为初始化原本就具有一定的盲目性,使得粒子的位置分布极不均衡,给全局寻优造成极大阻碍。同时该算法运算后期时收敛的速度非常缓慢,而且在历经次数较少的迭代进化之后,此算法种群里的所有粒子就常常具备一致的特点,也正是因此引发种群类型单一,难以摆脱局部最优,最终致使收敛过早。而混沌搜索算法虽然优势显著,然而倘若在搜索起始点的选取方面存在不足时,由于遍历区间很大,使得搜索结果很难达到较优点,也就是说要花很长时间去搜索才能获得最优解。
因此,把粒子群算法和混沌搜索算法相结合,可以相互取长补短,本文采用以下的方法进行改进:首先借助混沌变量对粒子群算法的种群的初始化加以人为影响,使得随机初始化导致的盲目性得以被规避,有效对种群完成决策性的初始化,可以生产精准度更高的最优解;其次为了使粒子群算法的全局收敛特性有所增强,对粒子群算法获取的全局及个体最优解加以混沌搜索优化,为了防止PSO算法容易陷进局部最优引发早熟收敛的问题出现。
2.3 熵的引入
信息熵也被理解为系统有序化程度的一个度量。某个系统的有序愈强,则其信息熵就会愈加低;反之,前者愈弱,则后者就会愈高[8-10];此处可将粒子群的种群视为一个系统,借助种群里个体基因的信息熵来对其中所有个体间的差异高低进行判断,再借助种群信息熵来对控制粒子群算法的w取值自适应。在粒子群算法里,惯性系数w取值可以决定该算法的搜索精准性,其数值愈高,则搜索范畴愈广阔,然而这样却会导致精准性下降;反之,则会使精准性提升,然而这样却容易导致陷进局部最优解。因此,论文选择使用公式(4)对w进行自适应转变,在搜索期间缓缓降低。
倘若种群中有N个个体,每一个都由2k个基因组成,设Rj代表N个个体第j位基因值的聚集,那么种群的多样性就可用其平均信息熵H来表示[8]:
(3)
式中,bij代表第i个个体第j位基因值在Rj中的重复数量,Pij代表第i个个体第j位基因值在Rj中的占有百分比。
则惯性参数w用如下的公式进行调整:
(4)
式中,w1及w2分别为许可的最大惯性系数及最小惯性系数。
2.4 熵增强的混沌搜索粒子群算法
用混沌变量进行混沌初始化、粒子群飞行运算、适值计算,在每代中获得个体最优解和全局最优解,然后进行混沌搜索,并用信息熵来调节粒子群算法的惯性系数,熵增强的混沌搜索粒子群算法采用的步骤如下:
(1)给定粒子群算法的相关参数,如粒子群算法的最大惯性系数w1和最小惯性系数w2、粒子群算法的种群数N、加速常数c1和c2和最大迭代次数MaxEvolve,给定混沌搜索算法的相关参数。
(2) 混沌初始化粒子群算法种群,也就是任意生成L个[0,1]随机数构成向量x1[L],借助Logistic映射x(t+1)=μx(t)(1-x(t))生成向量x2[L],x3[L]…xN[L],其中N为种群数,将x1[L],x2[L],x3[L]…xN[L]映射到位置变量的数值选取范围,获取最初位置X1[L],X2[L],X3[L]…XN[L],同样的方法得到初始速度V1[L],V2[L],V3[L]…VN[L]。
(3)计算粒子群算法每个粒子的适应数值,就每个粒子而言,倘若其适应值优于个体最优解Pi,那么通过目前的粒子对其加以取代,根据其找出本代种群的最优解,倘若此最优解比全局最优解Pg更优,则通过最优解将Pg加以取代。借助公式(3)对本代种群的种群熵进行运算,按照相应公式得出惯性系数w。
(4)针对种群中每个粒子,借助公式(1)对速度向量V[L]加以更新,借助公式(2)对位置向量X[L]加以更新,并且完成排序,获得下一代的可行解。
(5)对最优解Pi与Pg采用混沌搜索运算,倘若获取的结果优于前二者,则使用该结果对此二者加以取代。
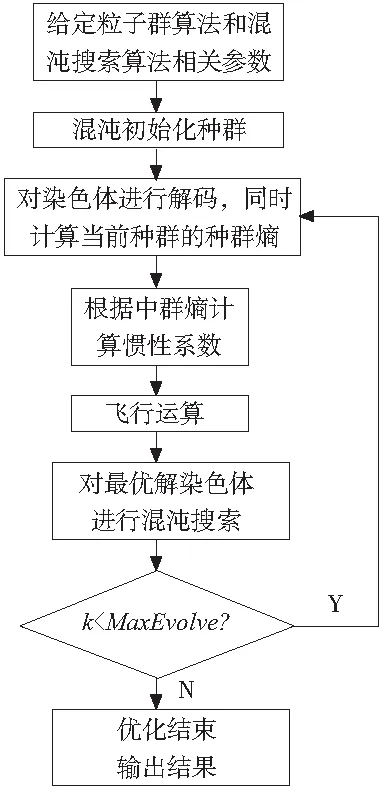
图1 熵增强的混沌搜索粒子群算法流程图
(6)判断迭代次数是不是比最大迭代次数MaxEvolve小,倘若结果为“是”,那么转第三步,反之则进行下一步。
(7)优化结束,输出最优解。
3 实例分析
以FT06问题为例,来验证算法。设种群数为100,最大迭代次数为50,ωmax=1.2,ωmin=0.2,c1=c2=2.0,连续运行10次后,PSO与熵增强的混沌搜索粒子群算法优化结果的数据对比如表1所示。

表1 FT06问题的优化结果
以FT10问题为例验证算法,以上相同的优化参数,连续运行10次后,PSO与熵增强的混沌搜索粒子群算法优化结果的数据对比如表2所示。

表2 FT10问题的优化结果
以LA01、LA21和LA40问题为例验证算法,以上相同的优化参数,连续运行10次后,PSO与熵增强的混沌粒子群算法优化结果的数据对比如表3所示。

表3 LA01、LA21和LA40问题的优化结果
由优化结果可以看出,熵增强的混沌搜索粒子群算法不但能很精确地求解小规模的车间调度问题,对于较大规模的车间调度问题也能求出较精确的最优解,比其他混合算法更具有优越性。
4 结束语
论文针对粒子群算法局部收敛的问题,将粒子群算法与混沌搜索算法加以融合,并用信息熵对惯性系数进行自适应调节,设计出一种熵增强的混沌搜索粒子群算法,用典型实例进行验证。实验结果表明,该算法不论在搜索质量还是在搜索效率上都优于简单的粒子群算法,能很好地使上述问题得以顺利解决,相较于标准的粒子群算法,前者的优势极为显著。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
现代电力(2022年2期)2022-05-23
军民两用技术与产品(2021年2期)2021-04-13
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
装备制造技术(2020年4期)2020-12-25
汽车维修与保养(2020年11期)2020-06-09
制造技术与机床(2019年7期)2019-07-22
雷达学报(2017年6期)2017-03-26
振动工程学报(2015年1期)2015-03-01
中央民族大学学报(自然科学版)(2014年1期)2014-06-11
