
基于MEEMD排列熵的高速列车轮对轴承故障诊断
2018-10-13 02:09陈星李慧娟
机械工程师 2018年10期
陈星, 李慧娟
(中车青岛四方机车车辆股份有限公司,山东青岛 266111)
0 引言
近年来,我们国家高铁蓬勃发展,铁路网覆盖面不断扩大,越来越多的高速列车投入运营,如何保障列车的安全运行已成为各专家学者重点研究的内容。轮对轴承作为列车走行部的关键部件,其功能为承担列车垂向自重及载重力,及列车轮轨间特有的横向非稳定力,对列车行车安全有至关重要的影响。随着车辆行驶速度提高,运营里程增长,轮轨间的动载荷的加剧使得轮对轴承的运行工况越发恶劣,这加剧了轮对轴承异常磨损、擦伤等故障的产生,继而危及列车运行安全。因此,对高速列车轮对轴承进行故障检测研究就具有重要意义。
国内外专家与行业人士对此进行了广泛而深入的探究,并取得诸多研究成果。早期轮对轴承故障检测传统的方法多为时域统计分析和频域傅里叶分析,这种方法主要是针对平稳线性特征的信号[1],就应用而言,因轮对轴承故障时检测到的振动信号实际具有非线性、非平稳特征,早期诊断分析方法已不能满足应用要求[2]。为了有效处理非线性、非平稳信号,时-频分析方法得到充分应用,其中小波变换相对于Wigner-Ville分布而言,因其具有无交叉项、小波函数灵活选择的特点,在机械旋转部件的故障检测中得到了充分应用[3-5]。但是小波分析的分解质量与小波函数的选取有着密切的关系,仅当小波函数中波形、信号特性匹配度较高时,才能将小波分解系数的效果充分发挥。相对而言,经验模态分解(Empirical Mode Decomposition,简称EMD)是具有自适应能力的信号分析方法,尤其适用于非线性、非平稳信号的分析过程,已经成功应用到机械设备、结构的健康检测中[6]。
然而EMD在分解带有冲击成分的轮对轴承故障振动信号时,易产生模态混叠现象,该现象使得EMD分解获得的本征模态函数(Intrinsic Mode Functions,简称IMFs)包络谱较杂乱,难以准确识别反映轴承故障特性频率,使轮对的故障模式识别、故障严重性评价效果并不理想。聚合经验模态分解(Ensemble Empirical Mode Decomposition,简称EEMD)的出现,很好地解决了上述问题,并在轴承故障诊断领域得到了广泛应用[7-8]。
然而EEMD方法也有一些缺陷。其一,如果EEMD添加的白噪声的幅值很小将导致其分解不能抑制信号中的模态混叠,如果添加白噪声的幅值较大,将导致集总平均的计算量大幅增加,同时也将导致信号中的高频成分难于分解,其分解结果也将包含大量的残余白噪声;其二,信号采用EEMD方法分解获得的结果可能不是标准的IMF分量,甚至还会有模态分裂的问题,即同一个物理过程被分解到两个或者多个IMF分量里[9]。
综合上述存在问题,郑旭等[10]提出了可以有效抑制模态混叠、减小信号残余噪声的集总平均经验模态分解(Modified EnsembleEmpiricalMode Decomposition,MEEMD)方法,该方法还可以确保分解结果接近于标准的IMF分量,避免模态分裂问题。
针对高速列车轮对轴承故障振动信号成分复杂(包含轨道激励振动、故障状态振动、车体固有频率振动的特点),利用将MEEMD和排列熵相结合的方法,提取与原信号最相关的IMFs排列熵,用于高速列车轮对轴承故障振动信号的多尺度特征提取,完善了因仅提取原始振动信号排列熵而无法全面反映信号故障特征的不足,最后利用最小二乘支持向量机(Least Squares Support Vector Machine,简称LSSVM)进行模式辨识,证明了该方法可有效应用于轮对轴承故障诊断(尤其是复合故障诊断)。
1 轮对轴承的MEEMD排列熵分析原理
1.1 改进聚合经验模态分解
MEEMD计算步骤[10]如下:
1)要求用于分解所添加的白噪声信号的均方根值接近待分解信号的内部噪声,或者确保有效抑制模态混叠的状态下不超过待分析信号的30%。
2)在待分析信号x(t)中加入绝对值相等的正负2组白噪声信号n(t),分别对其进行集总平均次数相等的EEMD分解:
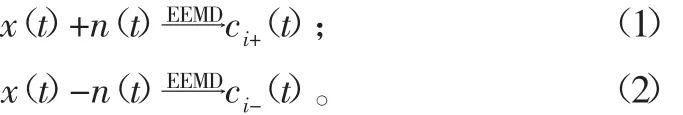
式中:ci+(t)和ci-(t)(i=1,2,…,m)代表分解得到的两组结果。
3)对分解获得的2组结果里相应IMF分量求均,从而极大地减小信号中的残余白噪声
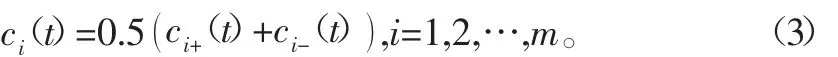
4)因为ci(t)可能不是标准的IMF分量,亦可能包含模态分裂的现象,故将其定义为预备本征模态函数(pro-IMF),需要进一步对其进行EMD分解:
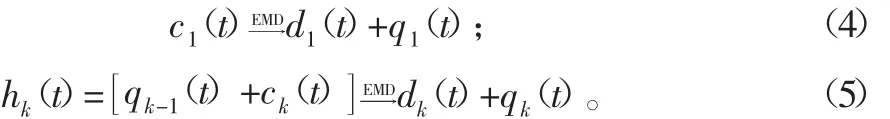
式中:d1(t)表示第1个pro-IMF分量c1(t)经EMD分解得到的第1个IMF分量;q1(t)表示剩下的残余分量的叠加.hk(t)表示第k个pro-IMF分量,它是由第k-1个残余分量qk-1(t)和第k个分量ck(t)所组成,dk(t)表示由hk(t)分解得到的第1个IMF分量,qk(t)表示其相应的残余分量的叠加,其中k=2,…,m。
5)则最终的MEEMD可以表示为
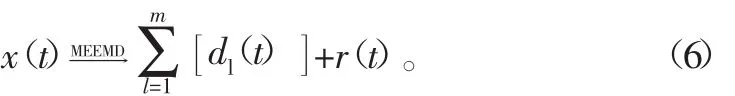
式中:dl(t)表示最终得到的IMF分量;r(t)表示残余分量。
1.2 排列熵特征提取
信息熵是最早由C.E.Shannon提出的用于表征信源不确定度的度量概念,其值正比于信息复杂程度。排列熵是Bandt等[11]专家学者近年来在信息熵基础上提出了一种新的计算方法,现已广泛适用于医疗、工程等各类时间序列分析,而且该算法具有执行效率高,所需时间序列短,噪声敏感度低,运行结果可靠等优点[12-13]。
排列熵的计算过程[14]:
针对一个时间序列{X(i)%,i=1,2,…,N}进行相空间重构,得到相空间矩阵:
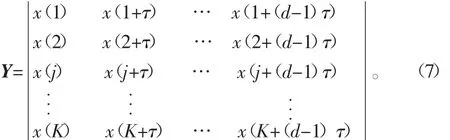
式中:j=1,2,…,K;d为嵌入维数;τ为延迟时间;K为重构向量个数,K=N-(d-1)τ。
将相空间矩阵Y中的第j个重构向量数据按照从小到大的顺序排列,得到各元素在重构向量中的位置索引j1,j2,…,jd,即:
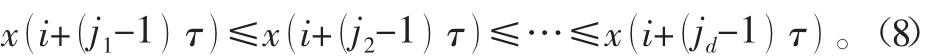
如果重构向量中存在相等的两个元素,如x(i+ (jp- 1)%τ)=x( i+ (jq- 1)%τ)。则按照jp和jq原有的顺序,即jp<jq时:
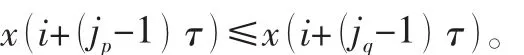
因此,重构相空间中的所有重构向量X(j)都可以得到一个符号序列S(l)={j1, j2,…jd},用以反映其元素大小顺序,其中,l=1,2,…,k且k≤d!。
在一个d维重构相空间中形成的符号序列 {j1, j2,…jd}总共有d!种形式,S(l)是其中的一种。构造序列P1,P2,…,Pk,Pk为第k种符号序列出现的概率大小。按照Shannon熵的形式,一个由时间序列X(i)的第k个重构向量对应的符号序列的排列熵的定义式为

1.3 最小二乘支持向量机
为了实现高速列车轮对轴承故障的自动分类识别,并且考虑到台架试验条件,获取的样本数有限,采用基于统计学习理论和结构风险最小化原则且针对小样本分类问题及其有效的支持向量机(Support Vector Machine,简称SVM)方法。最小二乘支持向量机是在一般支持向量机基础上创造的新的机器学习算法,该方法是利用二次损失函数将支持向量机计算过程中的二次规划问题转化成线性方程组进行求解,简化了算法的计算过程,提升了运算速度,且计算准确度并未损失,现已被广泛地应用于模式识别、故障诊断及信息预测等方面,同时获得了很好的效果[15]。
最小二乘支持向量机的优化目标为
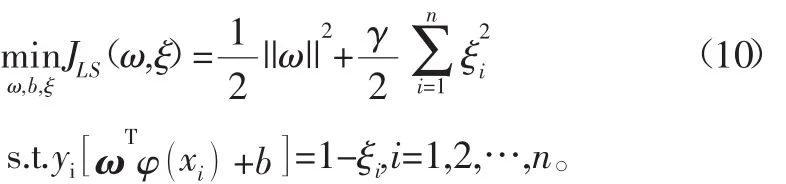
式中:γ为惩罚系数,是为了对JLS(ω,ξ)进行控制;ω为权向量;ξi为松弛因子。
引入拉格朗日函数,ai为拉格朗日乘子,从而将以上的问题转变成对于以下线性方程组(10)的求解问题:
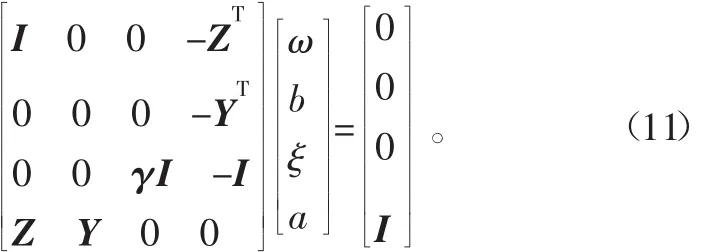
其中:
ξ= [ξ1ξ2… ξn]T,a= [α1α2… αn]T。I是单位矩阵。消去ω和ξ,上面的方程组可以简化为
利用最小二乘法求解式(11),得到线性分类器
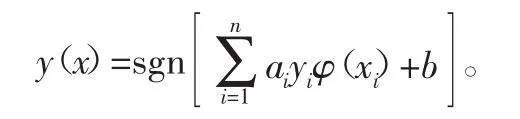
采用最小二乘支持向量机的一对多算法,可实现针对高速列车轮对轴承实现多故障的分类识别。
2 轮对轴承故障检测模型
高速列车轮对轴承故障振动信号是典型的非线性非平稳信号。首先,将原始振动信号通过小波包变换进行信号滤波、消噪;之后再对进行预处理之后的信号进行MEEMD分解,获取相应的IMFs,根据文献 [10][16],MEEMD过程中加入高斯白噪声幅值系数定为0.2,聚合经验模态的分解次数设定50次。利用相关系数法选取和原始数据最为相关的IMFs,将预处理后的振动信号和选定的IMFs分量选择适当的嵌入维数与延迟时间进行相空间重构,计算各尺度信号的排列熵测度值,用该值组成高维特征向量。将该高维特征向量分为两组,一组作为训练样本输入至LSSVM得到训练模型,一组作为待测样本输入至训练模型,获得最终的高速列车轮对轴承的故障模式辨识诊断结果。图1为基于MEEMD排列熵的LSSVM算法流程图。
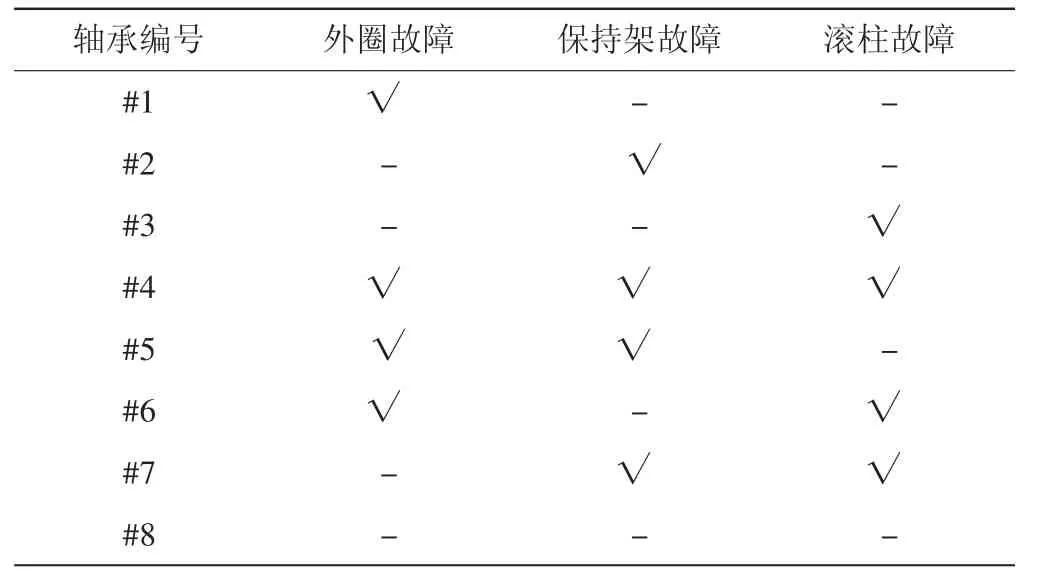
表1 轴承故障编号及工况条件
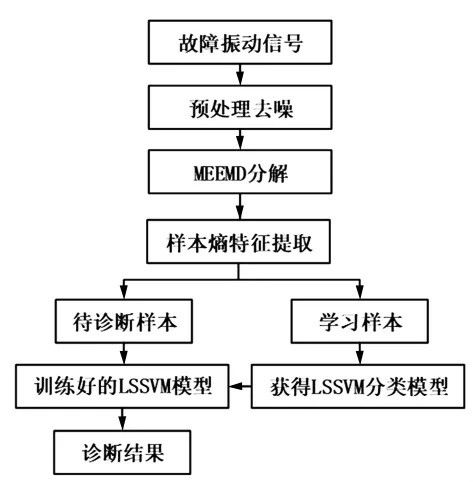
图1 信号处理流程
3 试验验证
3.1 数据来源及试验方案
为了得到高速列车轮对轴承振动信号,试验采用高速列车轮对跑合试验台进行台架试验,如图2所示,图3为高速列车轮对轴承,该轴承为密封型双列圆锥滚子轴承。

图2 高速列车轮对跑合试验台

图3 高速列车轮对轴承
列车轮对轴承故障多出现在内圈、外圈、保持架及滚动体处,故障模式多为裂缝、点蚀等[17]。为了进一步研究轮对轴承故障特性分析方法,试验对轮对轴承设置了外圈、保持架与滚柱三种人工伤,如图4所示。

图4 轮对轴承故障试验故障类型

图5 8种工况的原始振动时域信号
跑合试验在不同速度级下针对单一故障及组合故障等共7类故障状态进行模拟。试验工况如表1所示,其中8号轴承为健康轴承。100 km/h速度级下的8种试验工况垂向振动加速度信号时域图如图5所示。
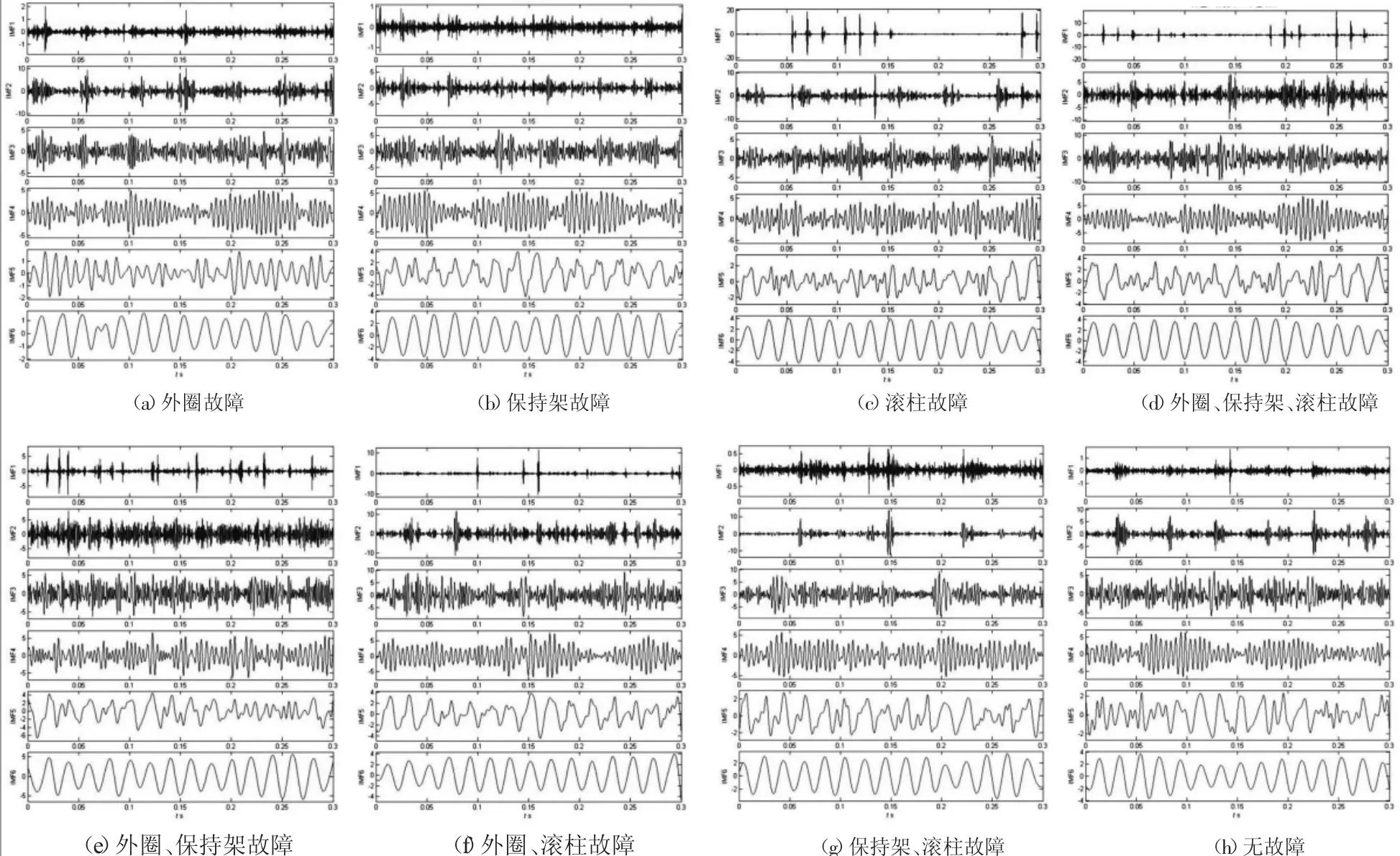
图6 信号MEEMD分解结果
3.2 信号的改进聚合经验模态分解
对消噪后的振动信号采用MEEMD进行分解,图6为各轴承在不同故障状态下振动信号的MEEMD分解得到的前6个IMFs分量。
3.3 排列熵特征提取
在排列熵的计算中,嵌入维数d及延迟时间τ的选择尤为重要:嵌入维数d过小会导致排列熵计算结果不利于反映信号的突变情况,过大则会导致排列熵整体变化范围较小不易观察;延迟时间τ过大将使得对于信号的平滑作用过强,导致计算结果不能检测到信号的微小变化。按照刘永斌等[18]的经验,选取嵌入维数d=5,延迟时间τ=3进行计算,取得原始数据及前6个IMFs的排列熵结果,每个故障状态各获得7组排列熵计算结果,如表2所示。
针对台架试验获取的数据,以每组3000个采样点的长度,截取50组样本,结合8种工况条件,将所有样本原始数据以及MEEMD分解出的前6个IMFs排列熵特征进行计算,并取部分计算数据,组成8×30×7特征矩阵,将该特征矩阵绘于三维特征空间中,其分布情况如图7、图8所示。
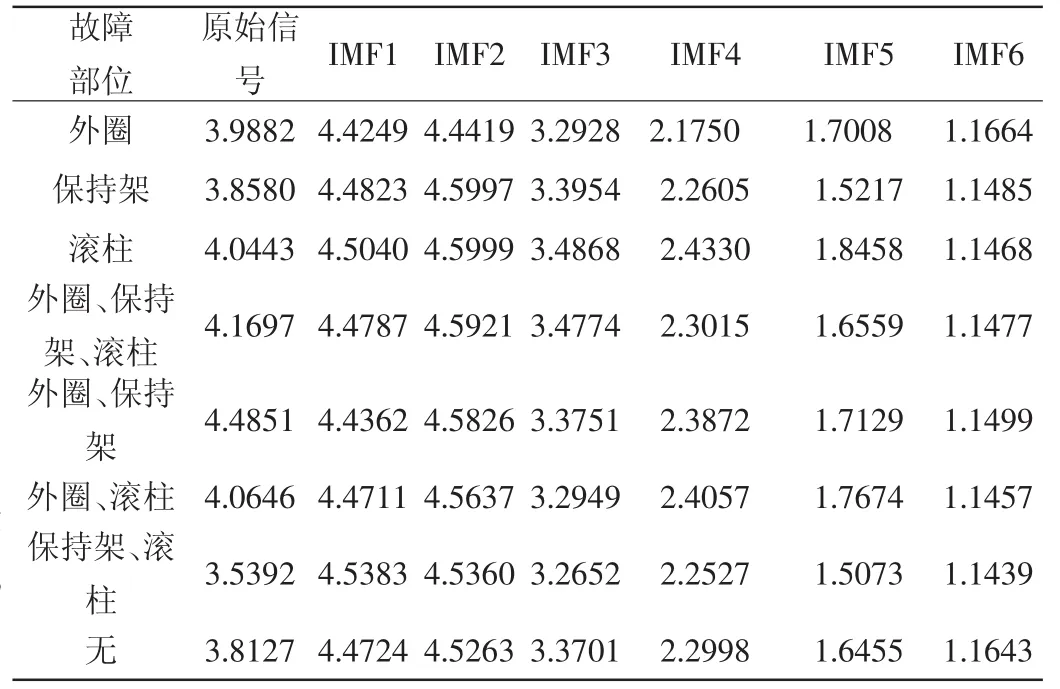
表2 8种工况的(下)各尺度排列熵特征值
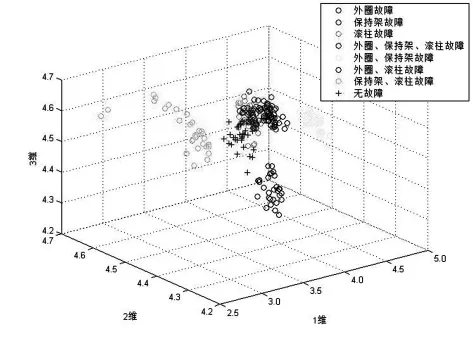
图7 1、2、3维排列熵特征
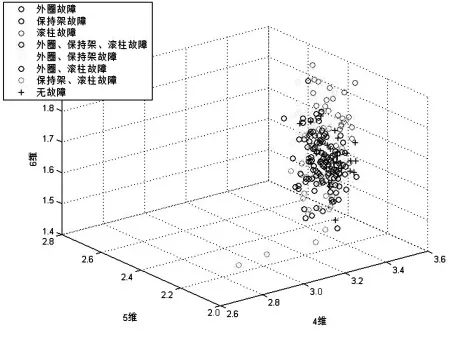
图8 4、5、6维排列熵特征
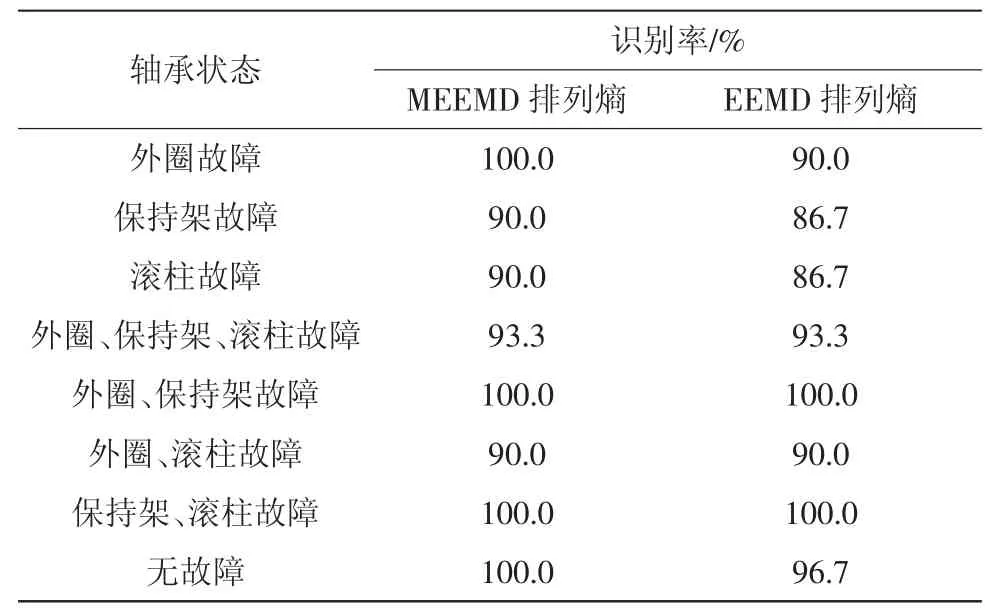
表3 不同位置的故障识别率
3.4 最小二乘支持向量机故障状态识别
受客观因素影响,台架试验所采集数据相对有限,需对高速列车轮对轴承故障状态进行智能分类,因此采用运算速度高、所需样本少、分类精度高的LSSVM作为分类器。取20组7维数据排列熵特征向量作为LSSVM的训练样本获得训练模型,再取30组数据作为测试样本输入至训练模型中,得到运行速度为100 km/h下识别率如表3所示。可以看出,基于MEEMD排列熵的诊断方法可以有效地实现不同轴承故障状态的智能识别,结果表明,特征提取环节MEEMD的引入使得信号特征在多个尺度上得到了体现,相对于EMD排列熵特征识别率相比,对单一故障模式识别率得到了明显提升。
4 结论
本文针对EMD、EEMD的缺点,提出一种基于MEEMD、排列熵及最小二乘支持向量机的高速列车轮对轴承故障方法,应用该方法分析台架实测数据表明:基于MEEMD排列熵的分析方法所需数据较短,抗噪、抗干扰能力较强,可以有效地应用于高速列车轮对轴承故障分析。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
知识经济·中国直销(2018年12期)2018-12-29
英美文学研究论丛(2018年1期)2018-08-16
