
睡眠状况与健康的探究
2018-10-19 16:09刘帅高泽斌白倬宁毕秋哲王立亚
科学与财富 2018年25期
刘帅 高泽斌 白倬宁 毕秋哲 王立亚
摘要:睡眠质量是衡量生活质量的重要指标,与人体的年龄、性别、神经质等客观生理指标以及主观心理评价密切相关,对人的身心健康和疾病诊断起着至关重要的作用。根据统计学、病理学以及数据挖掘等知识,对睡眠质量及其影响因素间具体关系进行探究,运用皮尔逊相关分析法确定年龄、性别Reliability、Psychoticism、Nervousness、Characte这六个指标的相关系数,再根据显著性分析的结果排除了指标Reliabilit、Character。依此可确定诊断结果与睡眠的关系。
关键词:应用数学;皮尔逊相关分析法;病理学;统计学;FP-Growth算法
中国分类号:R338.63,R749.41 文件标识码: A 文章编号:
0 引言
人类将生命中1/3的时间用于睡眠,在此期间,人体的循环系统进行代谢,使人恢复体力,增强免疫力,同时神经系统进入休眠状态,保护大脑并恢复精力。但随着生活节奏的加快,压力的增大,人的睡眠质量逐渐得不到保障。据统计,中国成人失眠率高达38.2%,近年来,青少年的睡眠障碍率也在逐步上升至43.5%。长时间失眠和睡眠障碍会导致人的精神不集中,工作效率低下,甚至影响任的身心健康,不利于青少年的健康成长。因此,保持良好的睡眠质量对于我们的健康生活尤为重要。
1 模型建立与求解
1.1 睡眠质量与指标间相关性分析模型
1.1.1 数据标准化
由于医生对患者进行诊断时,不可避免的夹杂着人为主观因素,因此利用式(1)来对数据进行标准化处理。
1.1.2 皮尔逊相关分析法与回归系数
皮尔逊相关系数法[8](Pearson product-moment correlation coefficient)是一种准确度量两个变量间相关程度的统计学方法。对于两个变量x和y,通过试验可得到若干组数据,记为(xi,yi)(i=1,2,3,…,n),相关系数r的取值范围为[-1,1],即 。 越接近于1,表明x与y的线性相关程度越高。如果r=-1,则表明x与y之间为完全负线性相关,反之,若r=+1,则表明x与y之间为完全正线性相关,如果r=0,则x与y间不存在线性相关的关系。
一般情况下,r的取值在(-1,1)之间,变量间的相关程度可分为以下几种情况:当 时,可视为高度相关; 时,为中度相关;
时,为低度相关;当 时,说明两个变量间的相关程度极弱,可视为非线性相关。
接着,利用已求得的相关系數r,求得对应的回归系数b。回归系数[9](regression coefficient)在回归方程中表示自变量x对因变量y的影响程度的参数,其值越大则表明x对y的影响越大。
1.1.3 显著性检验
相关系数r是通过对样本数据进行计算获得的,其值受到样本抽样的随机性、样本的数量等影响,因此,需要考虑样本相关系数的可靠性,即进行显著性检验。首先将样本不相关的推断假设为H0;其次计算检验的统计量,一般情况下采用T分布检验[10]。
最后,根据给定的显著性水平α和自由度df=n-2,利用T分布表查出 的临界值。若 ,则拒绝原假设 ,表明总体上两个变量间存在显著的线性关系。
1.1.4 数据处理与相关性分析
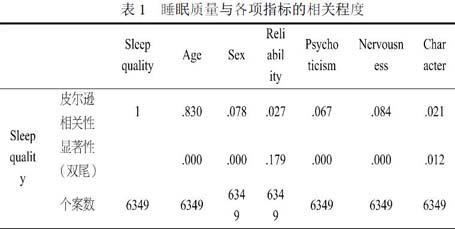
根据式(2)以及样本中经标准化处理后的相关数据,运用SPSS软件计算出睡眠质量与年龄、性别等指标的相关系数和显著性系数,结果如表1。
由表可知,睡眠质量与年龄、Psychoticism高度相关,相关系数分别为0.83和0.84,与性别、Nervousness中度相关,相关系数分别为0.78和0.67,而与Reliabilit、Character的相关系数均小于0.3,相关程度极弱,可忽略。有显著性的判断结果可知,睡眠质量与年龄、性别、Psychoticism、Nervousness的相关性较为显著。
1.2 基于FP-Growth挖掘症状与睡眠状况的关联规则模型
1.2.1 FP-Growth理论准备
FP-Growth是关联分析中一种经典的算法,由韩家炜[11]等人于2000年提出,采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树[12](FP-tree),但仍保留项集关联信息,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构。FP-Growth算法的使用可有效降低学习算法的复杂度,加快学习速度,提高学习与分类精度。
在算法中使用了一种称为频繁模式树FP-tree(Frequent Pattern Tree)的数据结构。FP-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。将事务数据表中的各个事务数据项按照支持度排序后,把每个事务中的数据项按降序依次插入到一棵以NULL为根结点的树中,同时在每个结点处记录该结点出现的支持度。
基本思路:不断地迭代FP-tree的构造和投影过程。
1.2.2 数据筛选
首先,根据病理学知识,对附件中的128种疾病的发病原因、发生机制、发展规律以及疾病过程中机体的形态结构、功能代谢变化情况进行分析,最终将其归为四类:Anxiety,以符号A代表;Emotingal problem(E);Sleep disorder(S);Depreesion(D)。
接着,对数据进行预处理,包括清洗、集成、转换、离散和规约等工作。一个预处理良好的数据集不仅可以提高挖掘算法的效率和质量,还可以尽量减少因为数据不合理付出的代价。
1.数据清洗:
利用均值填空的方法处理缺省值,缺省值和现有数据具有一定的相关性。利用噪声平滑和删除孤立点的方法清洗噪声数据与脏数据。剔除无关项,如删除在Diagnosis项中标识为空白和?的数据等。
2.数据离散:
将多数据源和多文件的异构数据进行合并处理,达到数据统一存储的目的。例如:在128种疾病中,某些疾病仅包含一条数据,将此类数据分离整合为同一数据集。
3.数据规约:
某些患者诊断为多种疾病,将这些数据集同时归为各种疾病的包涵项中。如Sleep disorder,Depression,在处理Sleep disorder时包涵这一数据,在处理Depression时也包涵这一数据。
2 结论
设计的基于FP-growth关联挖掘模型,实现了诊断结果与睡眠状况关联规则的研究。创新的提出了基于频繁顺序表的FP-Tree算法结构,有效地提高了计算效率,并求解出关联规则中负相关和弱相关规则,准确的到了各参数与诊断结果的关联规律,确定其参数的优先性和置信度范围。虽然此改进型FP-Growth算法虽然能反映出项集的客观度量,但是对于非对称的项集,提升度也有一定的局限性。接着再将测试样本中数据导入模型,得出了附件中10个病例的诊断结果,但在挖掘系统中,考虑到数据的冗杂性,并没有对128种疾病进行分析,而是将其整合为4种类型,没有更加准确的分析这些患者所患的疾病。
猜你喜欢
中国毕业后医学教育(2022年2期)2022-10-12
临床医药实践(2022年2期)2022-03-07
临床医药实践(2021年9期)2021-09-13
中华肩肘外科电子杂志(2020年1期)2020-08-24
上海农业学报(2017年4期)2017-04-10
中国经贸(2016年20期)2016-12-20
新教育时代·教师版(2016年26期)2016-12-06
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
医学研究杂志(2015年6期)2015-07-01
卫生职业教育(2014年12期)2014-05-16
