
基于逻辑确定性的BDD变量排序方法
2018-10-23 02:02崔谱龙叶华平
计算机与数字工程 2018年10期
崔谱龙 叶华平 闫 华
(陆军勤务学院 重庆 400000)
1 引言
从多阶段任务系统的角度,对战时油料保障任务可靠性进行分析,能够发现系统中的薄弱环节,并据此改进任务配置,提高油料保障的任务可靠性。但是,由于战时油料保障任务时间跨度长、任务复杂,且随作战要求的变化其装备配置也在不断变化,因此,对其可靠性的分析变得非常复杂。目前,多阶段任务系统的可靠性分析方法主要有两类:1)组合模型法,常用的如二维决策图法(Binary Decision Diagram,BDD)[1~4];2)状态空间法[5~8],如Markov法和Petri网法。基于状态空间的方法能够有效描述多阶段任务的动态行为并解决部件的跨阶段依赖问题,但存在状态空间爆炸的问题。基于BDD的分析方法比传统的组合模型及状态空间模型在存储空间和计算效率都有明显的优势[9],其通过阶段代数和微元替代法解决跨阶段依赖问题。但随着阶段数和微部件的增加,生成BDD的规模会不断增大,需要确定合理的变量排序方法进一步缩减BDD的规模。
利用BDD对油料保障任务可靠性进行分析时,变量排序方法直接影响最终可靠性模型的规模大小,其不仅包括阶段内变量的排序,还包括各阶段之间变量的排序。对于阶段内变量的排序,现在排序方法一般可以分为两类:基于结构的方法和基于权重的方法。基于结构的排序方法[10~11]根据从上至下、从左至右或深度优先等方式对故障树进行遍历,根据变量的访问顺序对变量排序;基于权重的方法[12],一般需要对变量进行两次遍历,根据不同的赋权规则对第一次遍历的变量赋权,第二次遍历再根据变量的权重进行排序。这两类方法主要是借鉴对单阶段变量排序的方法,没有考虑变量在不同阶段的跨阶段依赖性,对不同结构的多阶段任务,排序的性能波动较大。对于阶段之间变量的排序,现有的排序方法,根据变量顺序与阶段顺序关系可分为向前PDO和向后PDO,研究证明向后PDO能自动删除共同部件,比向前PDO生成更小规模的BDD[13]。将相同部件的变量排在一起,有利于处理变量的阶段依赖性,但存在相邻实变量逻辑确定性不强从而产生重复节点的问题,需要进一步优化。将相同阶段的变量排在一起,重复节点较少,但构造BDD时,需要执行辅助的移除过程来处理变量的阶段依赖性,因为BDD本身的化简操作会使这一过程变得很复杂。
通过总结现有排序方法中影响BDD规模的因素,本文提出了一种多阶段任务系统BDD变量的排序方法。该方法通过化简系统故障树减少实变量,基于逻辑确定性排序减少实变量重复节点,从而有效减少BDD模型中的节点数量。最后,通过实例验证方法的有效性。
2 基于逻辑确定性变量排序方法
2.1 排序思想
在多阶段任务中,实变量的个数会因阶段数增加而增多,因为同一部件可能在多个阶段重复出现。同一部件的工作状态可能对不同阶段产生不同的影响,但任一阶段任务的失败都会导致整个任务的失败。根据多阶段任务这种结构特点,提出系统故障树化简和基于逻辑确定性的BDD排序方法,通过减少实变量的个数和增加共享的BDD节点数,以减少BDD结构的的重复节点,从而减小BDD的规模。通过对现有排序方法[14~16]的分析,影响逻辑确定性的因素有变量的层次、子树变量数目、最小相邻变量和变量重复度。变量在故障树中的层次越高,越靠近顶事件,逻辑确定性越高;变量所在子树的变量数目越少,逻辑确定性越高;最小相邻变量已排序,逻辑确定性越高;变量的重复度越低,逻辑确定性越高。
2.2 排序原则
要生成系统的排序,需要按一定的方式将元变量排序,再用实变量代替元变量则是系统。对于实变量在阶段之间的排序方式,采用向后PDO排序的方式:以变量A为例,在各阶段的实变量排序为:AnAn-1,…,A。现在主要确定元变量的排序原则。
定义1:逻辑确定性在多阶段任务中,变量的失效状态对其所在阶段或整个任务成败影响的大小称为逻辑确定性。影响越大则逻辑确定性越强,对于逻辑确定性强的变量给予较高的排序优先级。
定义2:最小相邻变量是在故障树中与同一逻辑门(或门或者与门)相连的变量。
对于影响逻辑确定性的影响因素:变量的层次、子树变量数目、最小相邻变量和变量重复度依次给予较低的优先级。具体的优先规则如下:
1)优先规则一:变量的层次,变量在故障树中的层次越高,逻辑确定性强,其排序优先级越高。
2)优先规则二:子树变量数目,变量所在子树的变量数目越少,逻辑确定性强,其排序优先级高。
3)优先规则三:最小相邻变量,如果变量的最小相邻变量已排序,已排序的最小相邻变量越靠前,逻辑确定性强,其排序优先级高。
4)优先规则四:变量重复度,变量在各个阶段重复的次数越少,逻辑确定性强,其排序优先级高。
2.3 排序流程

图1 子树选择判定流程

图2 变量选择流程
阶段间的排序采用的向后PDO的排序方法,从最后一阶段的故障树开始对各阶段故障树依次遍历。根据以上四个优先规则,对各阶段故障树进行子树选择和变量选择。如果以上规则都无法确定优先级,则按照故障树结构,从左至右的方式进行排序。在故障树的遍历过程中,首先确定子树,然后对子树中包含的变量进行排序。子树的判定过程如图1所示,首先按照优先规则一优先选择包含层次最少的子树;如果都相同则按照优先规则二优先选择包含变量数少的子树;如果都相同按照优先规则三选择包含最小相邻变量且变量排序靠前的变量的子树;如果都相同则按照从左至右的顺序选择子树。
变量的选择过程如图2所示,首先按照优先规则一,层次越高的变量排序优先级越高;如果都相同,则按照优先规则三,具有最小相邻变量且变量排序靠前的变量优先排序;如果都相同,则按照从左至右的顺序进行变量排序。
2.4 步骤分析
假设多阶段任务由n个变量,j个阶段组成:Di代表故障树第i阶段门事件所包含变量数目集;C代表变量的最小相邻变量集;R代表变量的重复度集;Oi代表故障树元变量在第i阶段的排序结果。
步骤一:根据共同失效变量对多阶段任务系统故障树化简。
步骤二:对系统故障树进行遍历,得到各个阶段故障树门事件所包含变量数目集Di、变量的重复度集R、变量的最小相邻变量集C。
步骤三:从第j个阶段的最高层开始,按照逻辑确定性的四个优先规则对变量进行选择判定,对子树进行选择判定。具体过程是,先将最高层中的变量排序,然后进行子树选择,再进行下一层变量排序,子树排序完成后再回溯至上一层进行子树选择,变量排序,直至第j阶段故障树所有变量都被排序,生成阶段排序Oi。

图3 排序方法流程图
步骤四:对i-1阶段中没有参与排序的变量继续排序。排序的方法同步骤三,直到各个阶段的变量都已排序,得到排序各阶段的排序结果分别有O1,O2,…,Oj表示。
步骤五:得到多阶段任务元变量的排序Oj≺…≺O2≺O1,按照向后PDO的方式将元变量用实变量代替则得到多阶段任务实变量的排序。整个过程排序流程如图3所示。
2.5 算例分析
为了更好地说明基于逻辑确定性BDD变量的排序方法的排序过程,本文对经过简化的油料保障案例,如图4,用文中的排序方法进行变量排序。

图4 油料保障案例
1)BDD变量排序
步骤一:根据共同失效变量对多阶段任务系统故障树化简。故障树中存在共同失效变量A,在阶段1中,A与B通过与门连接则将A与G1门事件对应的子树删去;在阶段2中,A与G3门事件通过与门连接则将A与G3门事件对应的子树删去;在阶段3中将A删去,G6与G8对应的子树是共同失效模块,G8在阶段4中且与或门相连则将G6对应的子树删去。通过上述化简后对故障树进行重新整理,可以得到新的故障树,如图5。

图5 化简后的故障树
步骤二:对系统故障树进行遍历,得到各个阶段故障树门事件所包含变量数目集Di、变量的重复度集R、变量的最小相邻变量集C。遍历结果如下表1所示。
步骤三:从阶段4的最高层开始,变量A是故障树第0层的唯一变量故首先对A进行排序。第0层存在唯一门事件G8故确定了子树,变量C和变量F是最小相邻变量,F的重复度小于C故先对F排序后对C排序,生成阶段4排序O4{A≺F≺C}。
步骤四:对阶段3中没有参与排序的变量继续排序。变量E是阶段3故障树第0层的唯一变量故首先对E进行排序。第0层存在唯一门事件G5故确定了子树,变量B和变量D是最小相邻变量,B的重复度小于D故先对B排序后对D排序,生成阶段3的排序O3{E≺B≺D}。至此所有的元变量都已排序。
步骤五:得到多阶段任务元变量的排序O4≺O3{A≺F≺C≺E≺B≺D},按照向后PDO的方式将元变量用实变量代替则得到整个任务实变量的排序为
A4≺ F4≺ C4≺ C1≺ E3≺ B3≺ D3≺ D1
2)BDD构造
根据本文BDD变量的排序,构造出整个任务的BDD,如图6所示,实变量有8个,BDD图中只包括9个节点,只有E3变量重复出现了一次。

图6 本文方法生成BDD图
下面运用传统的深度优先法对本例进行排序,从阶段1至阶段4,按照从左至右、从上至下并考虑变量重复度的方法进行排序。通过对比BDD的规模,体现基于逻辑确定性排序方法的优势。通过改进的深度优先法,对本例的排序结果为C4≺C2≺C1≺D3≺D2≺D1≺E3≺E2≺B3≺B1≺A4≺A3≺A2≺A1≺F4。构造BDD如图7所示,节点数为16个。通过对比可以发现传统排序方法生成的BDD中实变量个数多,相同的实变量的重复次数也比用本文的方法生成的BDD多。E3、D3、A4分别重复了5次、3次和2次,相邻变量D3和B3分别重复了3次和2次。在本文排序方法中,根据逻辑确定性将失效会直接导致任务失败的变量A优先排序,将相邻变量D和B相邻排序,将重复次数较多D和C给予较低的排序优先级,所以构造的BDD中有更多的共享节点,减少了重复出现的节点数,从而减小了BDD的规模,有利于提高可靠性计算的效率。
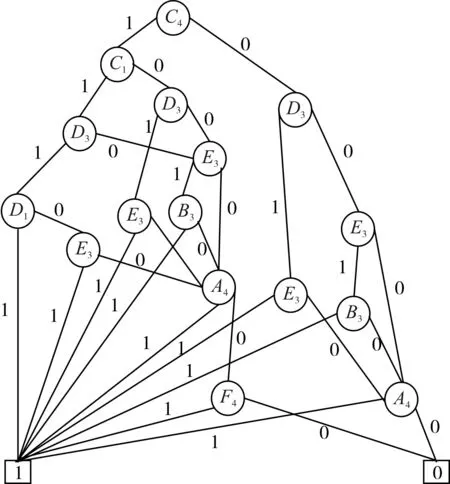
图7 传统方法生成BDD图
3 结语
基于二维决策图的战时油料保障任务可靠性分析,其变量排序对BDD的规模以及计算效率有重要的影响。通过总结现有研究方法中对BDD规模的影响因素,提出一种改进的变量排序方法。基于逻辑确定性对变量的层次、子树变量数目、最小相邻变量和变量重复度依次给予较低的优先级,从而增加BDD中的共享节点,有助于减小BDD的规模,提高战时油料保障任务可靠性分析的效率。
猜你喜欢
社会科学战线(2022年7期)2022-08-26
社会科学战线(2022年3期)2022-06-15
名家名作(2021年4期)2021-05-12
法律方法(2021年3期)2021-03-16
科普童话·学霸日记(2020年1期)2020-05-08
文苑·感悟(2019年8期)2019-08-06
文苑(2019年15期)2019-08-01
小天使·一年级语数英综合(2019年2期)2019-01-10
商周刊(2018年25期)2019-01-08
小资CHIC!ELEGANCE(2016年28期)2016-12-16
