
基于TMS320F28335的声码器设计与实现
2018-10-24 07:46孙凤梅薛颜李克靖
电子设计工程 2018年20期
孙凤梅,薛颜,李克靖
(中国电子科技集团公司第五十八研究所江苏无锡 214035)
近年来,语音通信系统发展迅速,需要使用不同速率的语音编解码算法,在有限的带宽中对语音进行编码去冗余并准确地传递[1]。面对越来越复杂的通信环境,低速率语音编解码算法能够在保证了合成语音质量的同时,有效地提高通信系统容量,主要应用于军事保密通信,卫星通信和数字语音存储系统[2]。低速率语音编解码算法可以分为波形编码、参数编码及混合编码。典型的编码算法有:多带激励编码、混合激励线性预测编码、正弦变化编码、正弦激励线性预测(SELP)等[3-7]。其中清华大学自主研发的SELP模型基于线性预测技术,具有提取参数方便、合成语音质量高的特点,是极具潜力的低速率语音编码模型。基于SELP模型已经实现了各种低速率编解码算法[8]。然而,通过研究发现,当清浊音判决不够准确或发生基音周期的倍/半频错误时,一些码率下的语音编码算法的合成语音会出现机器音较重、偶发性嘶哑及变调等问题。因此,为得到更高质量的合成语音,需要提高参数提取的精度[9]。
目前,语音编解码专用集成电路并不是很多。其中最著名的是美国DVSI公司生产的AMBE系列的声码器芯片,包括AMBE-1000TM、AMBE-2000TM、AMBE-3000TM等系列。其中,AMBE-3000TM是DVSI公司生产的新一代编解码芯片,能够提供最低2.0 kb/s的编码速率,编码速率可以在2.0~9.6 kb/s之间灵活选择[10-11]。但多数情况下,用户需要根据实际应用设计专用的编解码算法并实现其硬件模块,因此在当前的卫星通信、数字移动通信、数字声音存储等领域,通过数字信号处理器(DSP)实现的实时语音编解码器得到越来越广泛的应用[12-15]。
文中设计实现了一种基于TMS320F28335 DSP的多速率声码器,该声码器可实现基于SELP算法的2.4 kb/s、1.2 kb/s及0.6 kb/s 3种低速率的语音编解码算法。在参数提取过程中,通过支持向量机分类器进行清浊音的判决。根据算法复杂度及DSP芯片结构对算法进行优化,在硬件集成和调试后,实时实现了声码器通信系统。
1 语音编解码算法
SELP算法采用与基因频率成倍频关系的正弦信号激励,使需要编码量化传输的语音参数数目大大降低,从而降低了编码速率。
1.1 SELP语音编解码算法
SELP语音编码算法原始输入语音为PCM信,采样率为8 kHz。算法采用分帧处理方法,每帧语音包含样点数160~240。本文算法中,子帧帧长为25 ms,采样点数为200个。图1为SELP模型的编码框图。

图1 SELP编码端框图
输入语音首先进行预处理。是对8 kHz滤波后的语音信号再进行以下的分析处理。线性预测分析得到10维的预测系数(LPC)。通常将LPC系数转换为频域上的线谱对(LSF)参数进行量化传输。余量谱提取时先进行512点DFT变换,将最大峰值作为谐波幅度。SELP算法采用子相关法提取基音周期。采用带通语音信号的子相关函数和其包络信号的自相关函数联合判断子带的清浊状态。为了提高算法的抗误码性能,采用对残差信号的处理得到短时能量参数。
在特征参数的量化时,一般共有5个语音参数用于量化编码,将码流传递到解码端。但在低速率情况下,为了节省比特数,在矢量量化时采用了超帧策略,以2帧或3帧构成一个超帧为运算单元。1200 b/s的编解码算法由2个连续语音子帧组成一个超级帧,600 b/s则是由3个子帧组成一个超级帧。另外,余量谱参数可以不参加量化,在解码端用归一化“1”值代替。3种不同编解码速率具体参数的量化比特分配见表1。
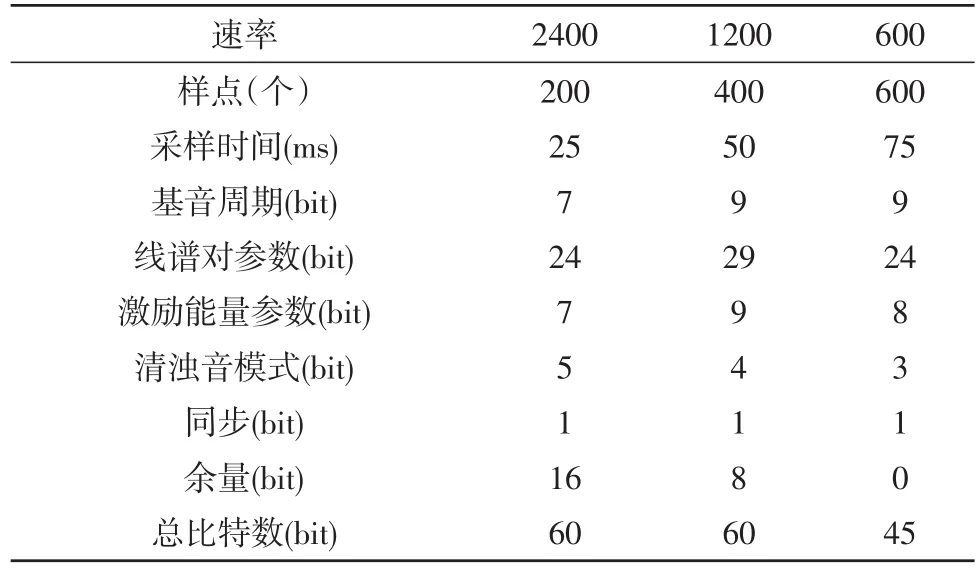
表1 SELP算法比特分配
在解码端,将接收到的各个特征参数进行反量化,得到基音周期、线谱对参数等5组特征参数。SELP模型的解码原理框图如图2所示。激励信号采用清音成分与浊音成分混合组成。根据子带清浊判决结果,其中清音成分用白噪声描述,由噪声发生器产生。浊音成分由一组不同幅度、频率变化的的正弦信号叠加而成。最后,合成的激励信号通过合成滤波器、后滤波器滤波后得到合成语音。

图2 SELP解码端框图
1.2 基于SVM的清浊音判决
支持向量机在线性分类器的基础上,引入结构风险最小原理和最优化理论,根据有限的样本信息,在模型学习能力和复杂性之间寻求最佳折衷,克服了“维数灾难”[16]。
假设训练样本集有n个训练样本,分为两种类别:(x1,y1),…,(xn,yn),xi∈Rk,其中yi∈{-1,1}是分类标签。典型SVM的主要思想是构造一个间隔最大的最优超平面wTx+b=0。如果存在一个超平面可以将所有训练数据无错误地分开,并且离超平面最近的向量与超平面之间的距离是所有可能情况中最大的。即对于w和b,满足以下条件:

由统计学习理论可知,使分类距离最大实际上就是使推广性的界中的置信范围最小。通过引入松弛变量ξi求解以下优化问题得到参数w和b,得到广义的最优分类面:

约束条件:

其中C为惩罚因子,C值越大表示对错误分类的惩罚越大。
提取语音特征参数的原则是:特征参数要对不同模式的分类可靠有效且取值范围在待分类别中的交叠较少。下面给出本文算法所涉及到的最大自相关值(r),过零率(z),短时帧能量(e)和谱倾斜度(t)等4个特征参数的定义。
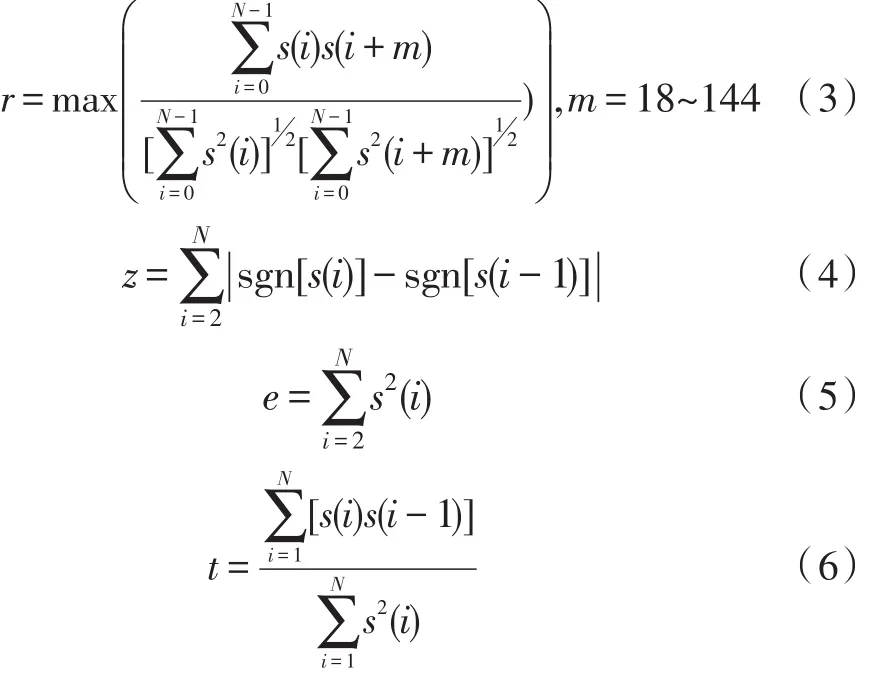
其中,N为每帧样点数,s(i)为经过滤波后的语音信号。
通过对比分析,可以较为明显地看出:浊音段的最大自相关值和短时帧能量较大,过零率较小;清音段的有较小最大自相关值和短时帧能量,及较大的过零率。谱倾斜度可以在一定程度上提高训练所得分类器的分类准确度。对已经标记完成的语音样本提取4个参数组成特征向量X=(r,z,e,t),输入SVM进行训练。
2 多速率声码器的硬件设计
2.1 芯片选择
声码器是数字通信系统中一个关键的部分,通常要求其体积尽量小,成本和功耗尽量低、可靠性高。因此,在不影响系统性能的前提下尽可能简化硬件设计。
TMS320F28335 DSP是高性能低功耗32位数字信号处理器,工作频率为150 MHz,资源丰富,数据处理能力强,功耗低,集成了256k的Flash存储器及34k的SRAM存储器。由于完成3种速率下的编解码算法的代码量和所需的量化码表所需的存储空间非常大,TMS320f28335能够满足多速率语音编解码算法对存储空间的需求,不需要额外设计存储器,即可用于完成语音编码算法和控制功能。
模拟音频接口部分采用TLV320AIC23B芯片。该芯片是一款通用型低功耗16位AD,DA音频接口芯片,用于处理语音以及宽带音频,是可移动数字音频应用系统中模拟输入输出的理想选择。
2.2 声码器硬件实现
TLV320AIC23B与TMS320f28335都是TI公司提供的高速芯片,两者在速度和时序上能够完全匹配,实现芯片间的无缝连接。图3为声码器硬件结构图。
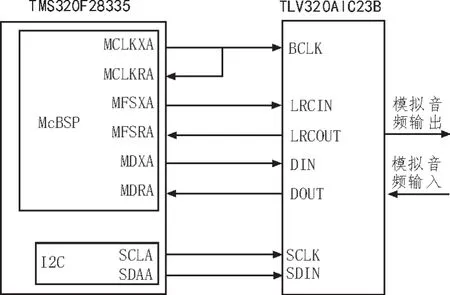
图3 声码器硬件结构
TLV320AIC23B的编解码器数字接口可直接与TMS320F28335的多通道缓冲串口(MCBSP)连接。其中BCLK提供位时钟信号,FS提供帧同步信号,DIN为串行数据输入,DOUT为串行数据输出。TMS320F28335的I2C与TLV320AIC23B的控制口连接,对TLV320AIC23B的寄存器进行设置,配置语音帧速率为8 kHz,采样精度为16 bit。
3 多速率声码器的系统实现
3.1 系统优化
3.1.1 存储空间配置
存储空间的合理分配是声码器实现的基础,高效的存储空间配置可以提高系统地处理速率,满足声码器实时处理要求。在完成系统设计后,需要将程序固化在FLASH。然而,CPU访问FLASH一般至少需要5个以上的等待周期。因此,在实际的实时处理系统中是需要通过Bootloader将程序从FLASH上加载到SRAM中并在SRAM中运行,使代码运行最有效率。具体操作如下:
1)将code_start段中LB_c_int00语句更改为LB copy_sections;
2)将wd_disable段中中.text语句更改为.sect“wddisable”;
3)将wd_disable段中中LB_c_int00语句更改为LB copy_sections;
4)通过#pragma DATA_SECTION指令将数据放置SRAM上。

表2 声码器占用存储器资源
从表2中可以看出,应用程序及编解码数据量比较大,片内RAM空间不足以把所有的代码和数据搬移到片内RAM,因此在搬移程序会将所有.text搬移到SRAM,而通过#pragma DATA_SECTION指令将部分码表数据放置SRAM上。
3.1.2 程序汇编优化
通过集成开发环境CCS(Code Composer Studio,CCS)工具的profile功能可以分析统计算法各部分运算复杂度,测试所有函数运算量。根据profile的输出结果,按照复杂度从高到低的顺序编写DSP汇编程序,直到达到实用水平。可以采用汇编语音实现。算法中调用频繁,消耗较多CPU周期数的函数用汇编实现,大大提高程序的处理速度,实现了语音编解码的实时处理。
3.2 系统码率变换方式
由于声码器能够实现0.6 k/1.2 k/2.4 kbps 3种速率的编解码算法,在系统工作前,需要确定系统编解码的速率。不同于AMBE系列芯片通过外部控制MCU发送控制命令字来改变声码器速率的方式,我们的声码器通过外部引脚高低电平的配置,直接来确定编解码速率。具体控制接口的配置如表2。当MOD1与MOD2都配置为高电平时,编解码速率为2.4 kbps。当MOD1配置为高电平,MOD2配置为低电平时,编解码速率为1.2 kbps。当MOD1配置为低电平,MOD2配置为高电平时,编解码速率为0.6 kbps。其中MOD1和MOD2为TMS320F28335的两个通用GPIO。

表3 编解码速率控制接口的配置
3.3 系统工作流程
基于多速率声码器实现的语音通信系统的工作流程如图4所示。完成系统初始化、语音参数配置、语音编码和语音解码。

图4 系统工作流程图
系统开机加电或复位后,TMS320F28335运行自引导程序,将片上FLASH中的程序和数据加载至DSP内部SRAM。通过设置寄存器,初始化DSP系统和外围电路,打开MCBSP、SCI中断源。
读取速率控制接口的值,根据速率控制接口的设置,确定编解码速率,并初始化编解码所需要的参数。数据化的语音信号通过多通道缓存串口传送到DSP内部的缓冲区,送入编码器进行编码,得到的数据流经SCI传输。从SCI接收到的数据流传给DSP内部缓冲区,送入解码端解码,得到的数字语音经MCBSP传给DAC,转换成模拟信号输出。
4 实验结果
在算法程序优化后进行软件仿真测试,测试的语音格式为PCM,采样为8000 Hz,语音数据精度为16bit,选自中国科学院声学研究所语音数据库。在清浊音判决中,SVM训练样本帧长为25 ms,训练样本共有2500帧。发音人为两男两女,其中清音约占55%,浊音45%。采用国际电信联盟(International Telecommunication Union,ITU)建议的 p.862 MOS分测试软件,测试指标为平均意见得分(Mean Opinion Score,MOS)。通过测试,平均MOS得分为3.197。图为3种码率下原始语音与合成语音的波形对比图。
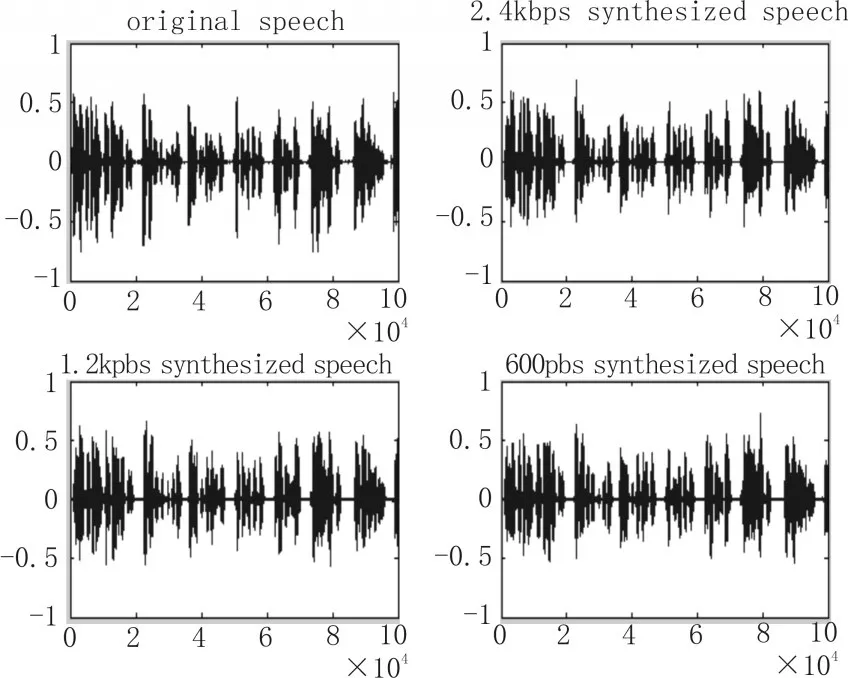
图5 原始语音与合成语音的波形图比较
为了测试了声码器的实时处理效果,在软件优化、硬件集成后,实现了一个简单的语音通信系统。下图为已经完成的声码器语音通信系统实物图。

图6 声码器语音通信系统实物图
通信系统中,需要两块声码器,声码器A和B都能够同时进行编解码,声码器的码流通过SCI接口直接发送接收,通信波特率配置为115200 bps,无奇偶校验位。从安排多人进行试听的反映来看,合成语音清晰自然,偶发性嘶哑和变调问题得到一定的改善。声码器实现了2.4 kb/s,1.2 kb/s和0.6 kb/s 3种速率的编解码算法,合成语音清晰自然。该声码器通过端口配置进行码率转换,具有较好的通用性和灵活性。
5 结论
文中设计实现的声码器软件方面完成了2.4kbps、1.2 kbps及0.6 kbps 3种不同速率的编解码算法,能够适应不同环境下的通信场合。在参数提取过程中,通过支持向量机分类器进行清浊音的判决,能够在一定程度上解决合成语音的偶发性嘶哑、变调等问题。声码器硬件设计能够充分利用TMS320F28335 DSP的硬件资源,在成本、体积和功耗方面有一定优势,通过端口配置进行码率转换,具有较好的通用性和灵活性。实验结果表明,该声码器合成语音质量清晰自然,达到了预期的效果,在其低速率语音通信场合具有一定的应用前景。
猜你喜欢
电子测试(2021年22期)2021-12-17
空间科学学报(2020年4期)2020-04-22
传播与制作(2019年9期)2019-10-20
传感器世界(2019年5期)2019-08-07
民用飞机设计与研究(2019年2期)2019-08-05
青年与社会(2019年4期)2019-03-29
电子技术与软件工程(2017年24期)2018-01-17
——以NHK新闻为中心
小说月刊(2017年14期)2017-12-06
自动化博览(2014年4期)2014-02-28
电信工程技术与标准化(2014年1期)2014-02-08
