
酒店在线评论数据的特征挖掘
2018-11-05 09:13秦海菲杜军平
智能系统学报 2018年6期
秦海菲,杜军平
在网购中,在线点评是买家购买决策的重要依据,同时也是卖家经营信息反馈的重要环节。在线点评分为数字评分和在线评论。目前,很多学者专注数字评分,因为数字评分比较直观,容易理解,但数字评分的粒度比较粗、少,且难于细化,例如同时被评为5分的同一家酒店,顾客对它的感受完全不一样,有的关注环境,有的关注设施,有的关注服务等。不同的人关注点不同,兴趣点也不同,评价也亦不同。从经济学和市场理论的角度看,产品和服务有多维属性,由于消费者的偏好不同,对功能和服务的期望也不同,即用户参考评论进行决策时,会依其偏好,只关注或更加关注某些方面的特征。只考虑数值评分无法反映用户对产品的全面和精确的评价[1]。因为某一类产品的数字评分不能为客户带来过多的信息,但是在线评论可以表达顾客的真实感受,能够被购买者参考和信赖。在线评论作为顾客在网络上发布的购买体验,对其他客户的购买决策起着重要的影响,这些体验也是企业在市场拓展和产品开发计划时要考虑的重要信息[2]。因此,在线评论数据也变得越来越重要。
随着网络的发展,用户生成的数据越来越多,引起了利益双方或多方的广泛兴趣,捕获这些数据并把它们转换为企业的核心洞察力,可为决策、营销、分析等不同目标服务[1-4]。在线评论数据像大数据一样具有体量巨大,增长速度快,种类繁多,价值密度低等特点。从在线评论数据中挖掘出顾客真正关心的酒店特征和对酒店的真实感受,可为酒店的分类提供真实可靠的依据,同时也为酒店的智能推荐奠定基础。
1 相关工作
1.1 在线评论数据分析
在消费者的决策过程中,在线评论已成为非常重要的信息来源[5]。研究表明,如果产品被他人推荐,产品的选择次数会增加两倍,这种影响取决于推荐来源的类型[6]。消费者在准备购买产品或服务时越来越多地寻求同行的经验,超过60%的消费者在购买前会咨询客户的反馈意见[6]。住宿评论决定了酒店的在线形象、销售额和未来收入[5−6]。
目前,对在线评论的研究主要是从情感出发,分析人们对某一产品的情感色彩和情感倾向,从在线评论中判断出人们的喜、怒、哀、乐、批评、赞扬等,从而判断出这一产品的受欢迎程度。在线评论挖掘属于观点挖掘,但不同于情感挖掘,情感挖掘只属于观点挖掘的一部分。2012年刘冰[7]在情感分析和观点挖掘一文中对观点挖掘涉及相关技术进行了总结;2015年Ravi,Guellil等[8−9]充分阐述了观点挖掘;2016 年 Rana[10]对观点挖掘中的方面提取技术进行了综述;2017年Sun等[11]和李建华等[12]对观点挖掘上进行进一步的总结和挖掘;2018年韩忠明等[13]对网络评论方面级观点挖掘方法作了综述研究。酒店是在线评论的重要内容,且酒店在线评论数据的获取是很方便的,可以从猫途鹰、携程、美团、大众点评、驴妈妈、微博、微信等网站上获取,但从目前的研究看,有影响的研究成果还比较少。
1.2 短文本分析
在线评论数据属于短文本研究。每个人每天都在应用短文本(短信、微博、微信、评论、Tweets、facebook等),短文本与普通文本有很大区别。短文本是包含有限的上下文,大多数短文本搜索查询少于5个单词,Tweets是不超过140个字符短文本[14]。几乎所有的短文本都在200字以内,在线点评数据也不例外。短文本通常不遵循语法,自然语言处理技术(如词性标注和句法解析等)难于直接应用于短文本分析[15]。短文本具有稀疏性强、价值密度低,实时性强、变化大、嘈声大、规则性弱等特点。因此,对短文本的分析比一般的文本分析要难。目前短文本研究多数都集中在社交网络,酒店在线评论的研究属于社交网络研究中的一部分。
2 酒店在线评论数据的特征挖掘
在线评论特征的挖掘包括数据获取、数据清洗、词性分析、特征抽取、特征词确定等环节。具体流程如图1所示。
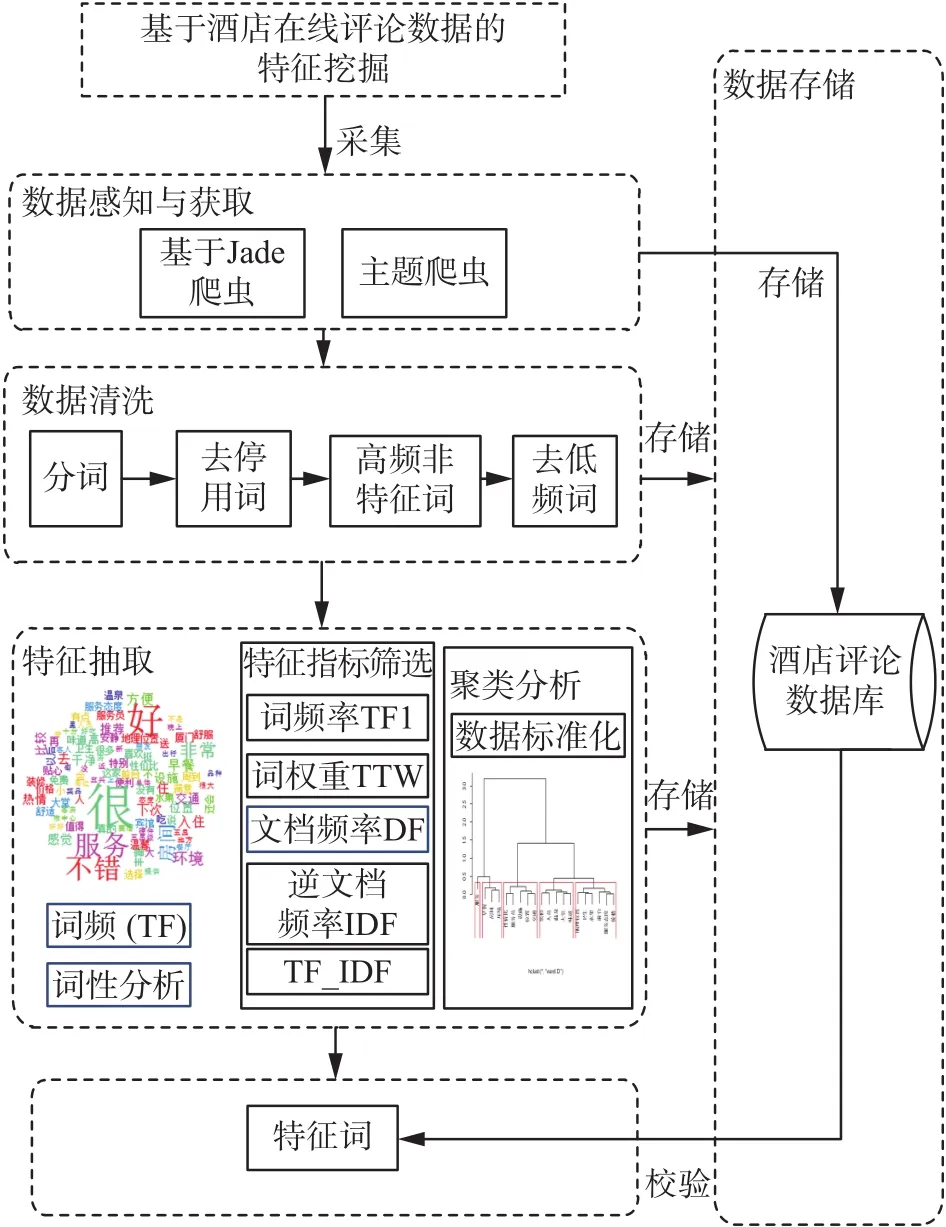
图1 基于酒店在线评论数据的特征挖掘Fig. 1 Feature mining based on hotel online review data
2.1 数据获取
在线点评数据包括数字、文本、图片等,本文应用主题爬虫在猫途鹰网(tripadvisor)和携程网(ctrip)上爬取相关数据,去除与主题无关的各种噪音数据(如导航条、广告信息、版权信息和其他图片、图像、声音等),对获取到的数据进行预处理(主要是去除无关和重复的数据)和清洗。
2.2 数据清洗
数据清洗是保证数据质量的关键环节,在线评论数据的清洗工作主要包括数据预处理(去特殊标记、标点等)、分词、去停用词、去低频词、去高频非特征词,具体步骤如图2所示。

图2 数据清洗的过程Fig. 2 Process of data clean
文本数据预处理:完成多余字符删除和多余数据清除。
分词:采用中科院分词和结巴分词相结合的方式,分词后的数据为分词集1。
去停用词:在分词集1中很多词没有实际意义,仅仅代表一种结构,比如介词、叹词、连词等,把这部分词集合在一起形成停用词表。在数据清洗中需要将停用词剔除,以降低特征向量维度,去除停用词后的词集为分词集2。
词频统计:词频(term frequency,TF)是指词或短语在给定文档中出现的总次数,通常认为词频越高,其在文档中的重要度越高,成为关键词的可能性越大[16]。在酒店评论数据中,指在评论中某个词出现的次数。
词频排序:对分词结果的词频进行降序排列,排序结果为分词集3。
去低频词:对低频词进行剔除处理,去除低频词后的词集是分词集4。
去高频非特征词:在线评论数据中,特征不明显的高频词会削弱特征词的特性,去除高频非特征词的词集是分词集5。
2.3 特征词的抽取
从在线评论中提取反映评论主题的特征词(Keyphrases,包括单词或词组),提取的特征词需要满足可读性相关性重要性覆盖度一致性[16]。目前比常用的特征提取方法有TF-IDF、词频、文档频率、逆文档频率等。单独使用上述方法不能达到特征词选取的良好效果。
1)词性分析
众多文献提出特征词通常是名词短语[16,20],因此需要对词性进行分析。
2)特征词指标
① 词频(TF):词W在评论中出现的次数。频数(TF)越高,评论的次数越多,关注人群越多,关注程度也就越大。某词W的词频NW(即词W出现的次数)为出现的第i次。
②词频率(TF1):词W在所有词中的比重。为了与词频数区分开,采用TF1表示。

处理后某一词W的词频率如式(2)所示:
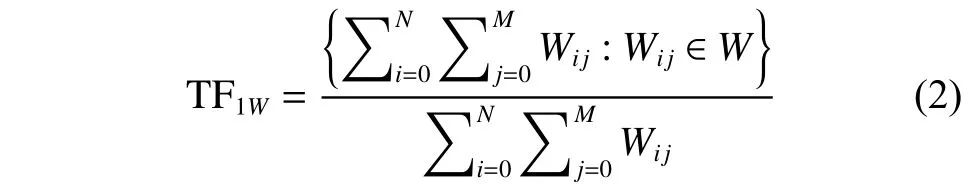
③词评权重(TTW):词W在评论中的比重。
某词W在一条评论中被多次提到和被多人提到,意义是不一样的,为了更好区分两者关系,采用词评权重(TTW)。假设每一条评论代表了一个点评人,如果一个词被多个人评论,那么代表这个词被多人关注,这样的词可以是特征词。词评权重既考虑了词频数,也考虑了评论人数。TFW是词W在评论中出现的次数,NW是含词W的{评∑论条数(假设}一条评论代表一个人),,词W的词权重计算如式(3)所示:

④ 评论频率(DF):评论频率也称文档频率,指某条评论在总评论中的比重。
DF=包含该词的评论条数/总评论数,N是总评论数,评论频率计算如式如(4)所示:

⑤ 逆文档频率(IDF):衡量词或词组所在的文档在整个语料库中的频率。
逆文档频率越大表明该词越重要,它是一个词语普遍重要性的度量[16]。IDF的思想是:如果包含词条W的评论越少,也就是,NW越小,IDF越大,则说明词条W具有很好的类别区分能力。特定词语W的IDF,可以由总评论数除以包含该词语的评论,再取对数得到。计算公式如式(5)所示:

⑥ 特征权重值(TF-IDF):词频−逆文档频率(TF-IDF)是结合词频和逆文档频率来衡量候选关键词的重要度量。
词频−逆文档频率(TF-IDF)被认为是所有特征中最有效、最常用的特征之一[16]。如果某个词或短语在一篇文章中出现的频率TF1高,并且在其他文章中很少出现,则认为该词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF的计算如式(6)所示:

TF-IDF值与该词的出现频率成正比,与在整个评论中出现的次数成反比。
3)特征词的筛选
特征词的筛选是特征词选取和降低特征词维度最有效的方法。分析各特征词指标的关系是特征词选取中重要的环节,但各个指标之间存在有很强的相关性,并且量纲差异较大。为了消除各指标量纲的影响和指标之间的相关性,采用标准差标准化(Z标准化)对数据进行标准化处理。计算公式如式(7)所示:
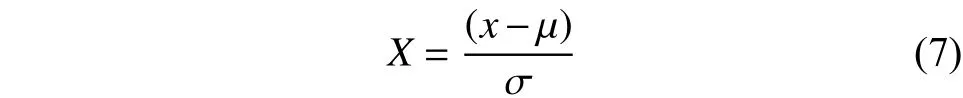
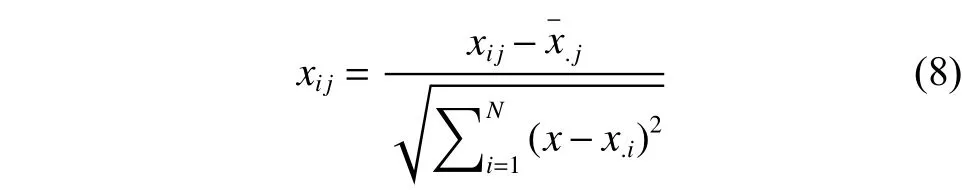
聚类分析是研究样品和指标分类问题的一种多元统计方法[17−19]。在实际应用中一般有两种处理方式,一种是根据分类问题本身的专业知识结合实际需要来选择分类方法,并确定分类个数;另一种是多用几种分类方法,把结果中共性取出来,如果用几种方法的某些结果都一样,则说明这样的聚类确实反映事物的本质[19]。采用专业知识与多种聚类算法结合的方式对特征进行筛选,以确定特征词。
算法1 在线评论数据的特征挖掘聚类算法
②计算各类之间的距离(类平均法、ward法、最大距离法、相似分析法),得到观测值矩阵;
③合并类间距离最小的两类为一新类。并重新计算新类与各类之间的距离,更新矩阵表,类的总个数依次递减,直到为1;
④画聚类树图;
⑤根据聚类图和专业知识决定分类的个数和成员;
4)特征词提取方法评价
本文认为特征词能代表评价主题,Nc为代表评价主题的特征词数,NA为选择的特征词数,准确率P如式(9)所示:

有学者研究提出召回率不适合评论数据的评价指标,因此本文借助别人提出的GMM指标,Nc为能代表评价主题的特征词数,NA为所选择的特征词数,准确率GMM如式(10)所示:
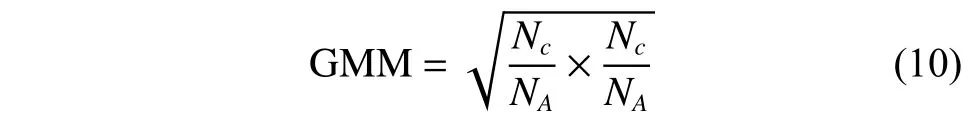
2.4 特征词的验证
采用数据集2对所选特征词进行校验。
3 实验及结果分析
本文采用主题爬虫对网络数据进行抓取。获取全国高端酒店(四、五星级酒店)的在线点评数据,并对在线点评数据进行处理,把全国高端酒店(四、五星级酒店)按数字评分进行排序,取出数字评分排在前20名的酒店数据为数据集1和数字评分排在后20名的酒店数据为数据集2。应用数据集1进行建模分析。在建模过程中,对数据进行清洗,再对数据进行特征抽取、特征筛选和特征选取,应用数据集2对特征词进行校验。
根据实验需求,从网络上爬取的50余万条数据中筛选出前20名的酒店174 449条评论数据(数据集1)和后20名的酒店104 898条数据(数据集2)进行分析,采用中科院分词系统和结巴分词相结合的方法分别对数据集1和数据集2进行分词,去停用词后分别得到4 049 078个词条和1 857 523个词条,并分别对词条进行分析。由于词条数太多,再次对词条的低频词和高频非特征词进行处理,为了降低词条维度和分析的难度,采用降维、抽样的方法对词条进行分析。抽取了频数排在前100的词条进行词云分析,词云图如图3所示。

图3 词云图Fig. 3 Word cloud
3.1 特征词抽取与筛选
近年来,有许多学者对特征词的提取方法进行研究。特征词提取方法可以归纳为监督型和非监督型两类[20]。监督型可以用多种方法训练模型,并实时调整参数;非监督型特征词抽取主要有基于统计、基于词性规则、基于主题模型、基于词排列图的方法。本文将利用统计、词性和主题模型的方法对特征词抽取进行分析。
3.1.1 词性分析
从图3可以看出词条多且复杂,如果把所有的词都作为候选特征词,那么特征向量的维数将非常大,难于进行计算和分类。在词云图中很多词要与其他词组合在一起才具有实际意义。比如:“服务好”、“服务不错”、“服务不好”、“服务很差”、“环境好”、“环境不错”、“环境很好”、“环境很差”、“好”、“不错”、“差”等词是对某一主题的评价。根据酒店在线评论数据的分词结果,对词性的分析如表1所示。
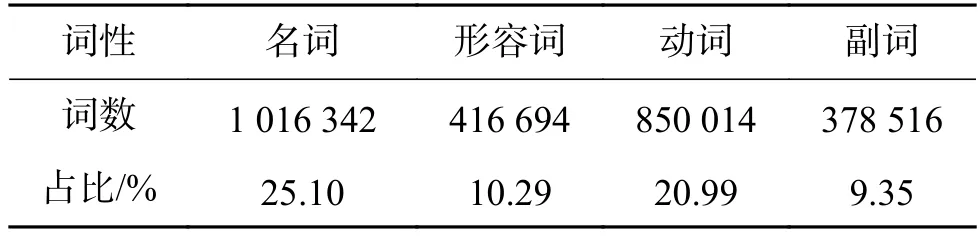
表 1 词性分析Table 1 Part of speech analysis
从表1可以看出,在所有词语中名词、形容词、动词、副词在所有词中占到了2/3,名词的占比是最高的,占到了25.10%,其次是动词占20.99%(包含动名词占总词数的2.5%,后面分析时把这部分词归属名词处理)。对词性进行分析,分析结果如图4所示。

图4 词性词云图Fig. 4 Part of speech word cloud
根据图4名词、形容词、动词、副词的词云图可以看出名词作为评价的主题,作为候选特征词的确比较显著。除名词外,在动词词云图中最为明显的“服务”一词也可以作为评价的主题。对这部分词语的词性进行查看,“服务”属于动名词,为了特征提取的方便,把动名词归属于名词的行列。但还有一部分词语完全是动词,但也表达名词的意思,比如“装修”、“位置”、“出行”等,这一部分是动词名用,对于这一部分词需要作为特征词分析。评论数据属于短文本数据,并没有完全遵从自然语言的语法结构,动词名用或名词动用情况很常见。因此,在特征词的选取上只选取系统所分的名词是不可取的,必须根据专业、行业、常识等对词性进行进一步的筛选与确定。根据词性的词频对候选特征词的分析如表2所示。
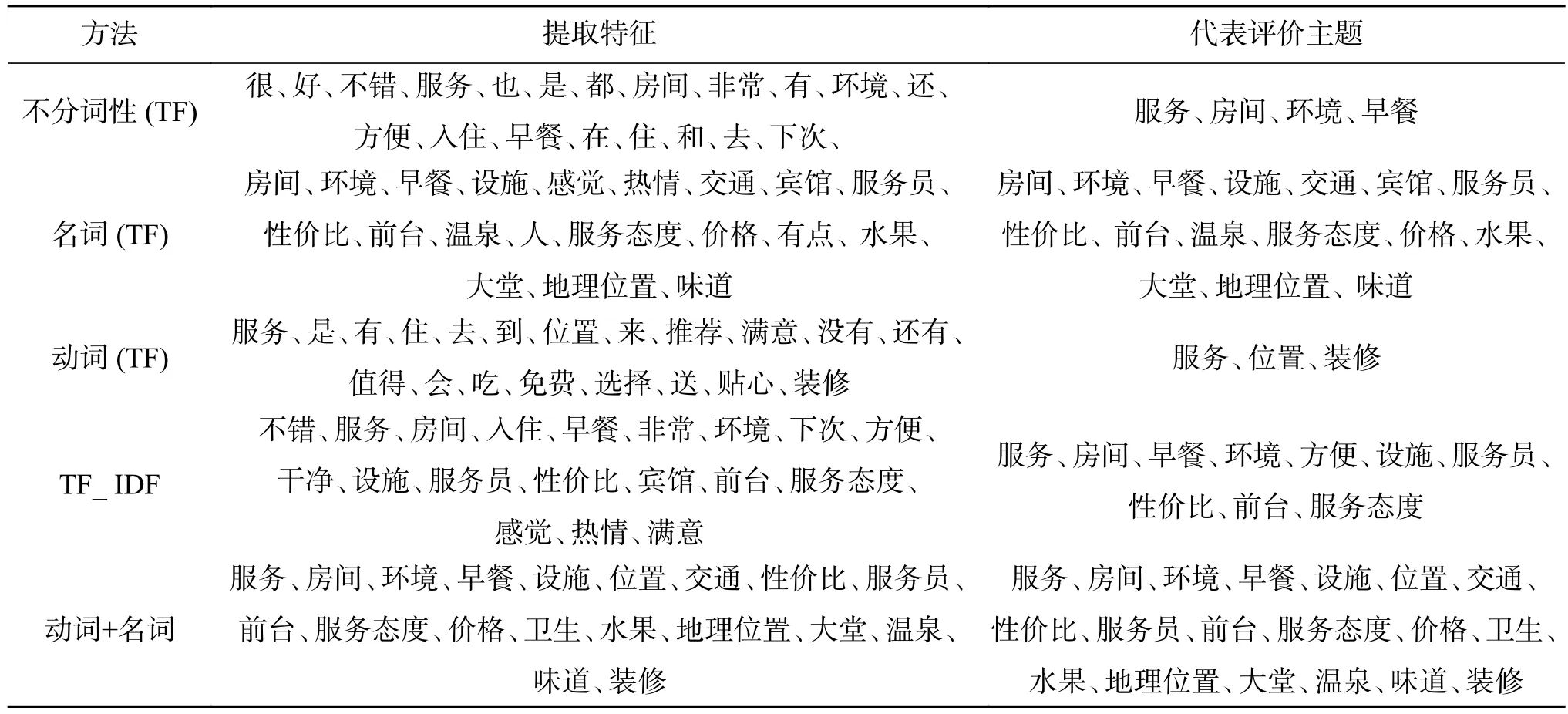
表 2 候选特征词词性分析Table 2 Part of speech analysis of candidate feature words
综合几种特征词提取方法,本文先利用无监督方法TF(词频数)提取候选特征,所提取的20个特征词能代表评价主题值有4个。综合TF和词性进行分析,形容词、副词中没有能代表评价主题的候选特征词;动词中代表评价主题的有3个,名词中16个。利用TF_IDF提取的候选特征词代表评价主题的有10个。而综合无监督型的TF、词性在无监督的情况下动词+名词提取的特征词效果与TF_IDF的提取效果一样,而选择名词作为特征词,在监督下筛选动词作为补充,所提取的效果要比只提取名词的效果要好,准确率和GMM值都达到了87%,而若名词+动词的筛选都在监督下完成,所得的候选特征词与评价主题的特征词的准确率和GMM达到95%以上。具体结果如图5所示。
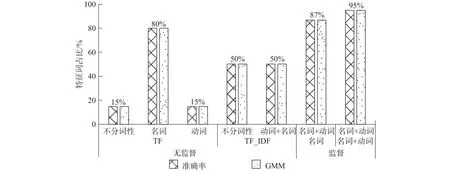
图5 特征词提取方法对比Fig. 5 Comparison of feature words extraction methods
3.2 特征词指标分析
虽然动词+名词结合的特征词比较适合分析,但候选特征词的维度比较大,各候选特征词之间的关系比较复杂,是否具备特征词的特性还需要进一步分析,特征词指标分析如表3所示。
从表3可以看出根据词频数(TF)、词频率(TF1)、词频权重(TTW)、评论频率(DF)、逆文档频率(IDF)和TF1-IDF这6个评价指标选取特征词时,在各个指标上选取特征词的结果都不一样。TF和DF最高的是“服务”,TF1最高的是“房间”,TTW最高的是“环境”,IDF最高的是“装修”,TF1-IDF最高的是“温泉”。“温泉”的TF1-IDF的值是最高的,但从专业的角度看,温泉可能是高端型酒店的一个特征,但不能作为最重要的评价指标。“温泉”的TF1-IDF值高说明有很多高端客户在关注“温泉”,但用“温泉”作为酒店评论数据的特征词是没有代表性的。从单一的指标中选取出的特征词不能完全满足特征词选择的可读性、相关性、重要性、覆盖度、一致性的要求,但各个指标对候选特征词又都有影响。因此,考虑对象酒店在线评论数据的实际情况,综合应用TF、TF1、TTW、DF、IDF和TF1-IDF这6个指标对候选特征词进行分析。从表3可以看出各个候选特征词在各个评价指标上的量纲是不同的,并且差距很大,TF、TF1、TTW、DF、IDF和 TF1-IDF各指标之间存在着很强的相关性。综合19个候选特征词的6个评价指标的实际情况看,降低特征词的维度是选取特征词最实用的方法。

表 3 指标分析Table 3 Index analysis
综合图6候选特征词的4个聚类树图根据聚类结果和酒店的专业知识,聚类为5类比较合理,把酒店在线评论候选词归并为5类,并对5类特征进行综合分析,综合19个候选特征词的聚类结果如表4所示。

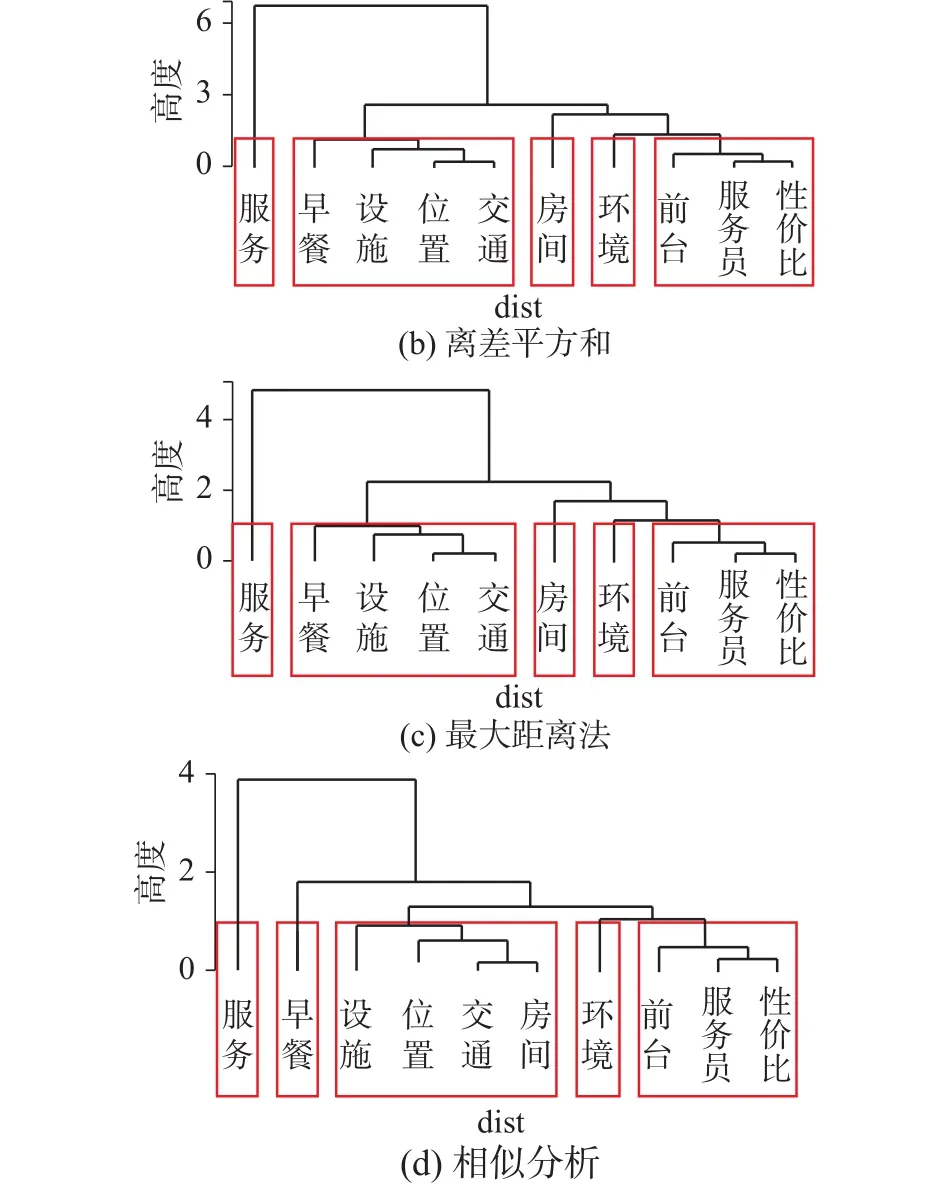
图6 数据集1候选特征词聚类Fig. 6 Dataset1 Candidate feature words cluster

表 4 候选特征词归类表Table 4 Candidate feature word classification
通过表4可以看出特征词“服务”包含了“服务”、“服务员”、“服务态度”、“前台”等服务信息;特征词“设施”包含了“房间”、“设施”等硬件设施信息;特征词“环境”包含了“位置”、“环境”、“交通”、“地理位置”等信息;特征词“餐饮”包含了“早餐”、“水果”、“味道”等餐饮信息;整体舒适度包含了“大堂”、“性价比”、“价格”、“卫生”、“装修”、“温泉”等整体舒适度信息。这5个特征词能满足特征词选取的可读性、相关性、重要性、覆盖度、一致性的准则,因此可以作为酒店在线评论数据的特征词。
3.3 特征词的校验和选定
3.3.1 方法的验证
采用同样的方法,用数据集2(数字评分排在后20家的酒店数据)的词条进行了词性分析,处理后得到了24个候选特征词,计算出24个候选特征词的 6个指标 (TF、TF1、TTW、DF、IDF和TF1-IDF)的值,并对数据进行标准化后,采用6个指标对候选特征词进行聚类,所得的聚类结果如图7所示(为了图形清晰,本文只选取了TF最高的数据进行展示)。
综合图7候选特征词的4个聚类树图,根据聚类结果,可以看出聚类为5类比较合理,根据酒店的专业知识,把酒店在线评论候选词归并为5类,结果如表5所示。

图7 数据集2候选特征词聚类Fig. 7 Dataset2 Candidate feature words cluster
从表5中可以看出,部分被归并的候选特征词有了更细化、更相近或概括的变化,例如设施中增加了“床”、“房”、“空调”等细化词;环境中增加了“地段”、“出行”、“周边”、“附近”等相近词;整体舒适度增加了“总体”、“整体”概括词。综合酒店在线评论的两个数据集和网络在线点评数据的特性,可以看出把服务、设施、环境、餐饮和整体舒适度作为酒店在线评论数据的特征词是合理的。

表 5 后20名酒店特征词归类表Table 5 The last 20 Hotel feature word
综合6个评价指标聚类图,对于评论数据,TF分析的结果要比TF_IDF的效果好,选取以TF为主,TF1、TTW、DF、IDF、TF1_IDF为辅的指标聚类时,选取TF排在前10的候选特征词聚类和选取更多的候选特征词聚类结果类似,后面的候选特征词只是对前面结果的补充或细化。
4 结束语
本文从酒店在线点评数据出发,对数据的感知获取、数据预处理、词性分析、特征选取、特征筛选、特征确定等进行了研究。对特征词的筛选和确定进行了分析。单个指标(TF或者TF1-IDF)对特征词的筛选和选择效果不理想,需要综合 TF、TF1、TTW、DF、IDF、TF1-IDF 多个指标进行分析。采用了无监督的聚类方法对变量进行聚类分析,聚类时采用数据标准化消除指标相关性和量纲的影响。综合聚类分析的结果和酒店专业知识选定酒店在线评论数据的特征词,通过将20家酒店作为数据集2对特征词进行校验,得出酒店在线评论的特征词是服务、环境、设施、整体舒适度、餐饮。下一步将根据特征词构造更方便、快捷、可靠的分类器,为酒店和客户进一步细分做好准备,同时也为酒店为客户提供的个性化的智能推荐服务奠定基础。
猜你喜欢
计算机系统应用(2021年9期)2021-10-11
内江科技(2021年8期)2021-09-13
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
中国修辞(2017年0期)2017-01-31
读者·校园版(2015年7期)2015-05-14
中文信息学报(2015年4期)2015-04-21
