
微信公众号层次模糊元关联规则聚类预警
2018-11-17 01:25罗兴宇
计算机工程与设计 2018年11期
宋 华,罗兴宇,刘 亮
(1.重庆警察学院 信息安全系, 重庆 401331; 2.重庆邮电大学 移通学院, 重庆 400065)
0 引 言
当前,随着网络技术的发展,网络环境纷繁复杂,网络舆情监测变得非常重要,是很多政府、企业和社会关注的焦点。而微信公众号[1-3]是当前社会上适用最为广泛的网络工具,因此对网络舆情进行有效的监测具有非常重要的意义。国内外在微信公众号主题数据挖掘方面的研究成果较少,对此考虑采用关联规则方式进行数据主题的挖掘,在关联规则研究方面,国内外已有许多成熟研究。传统意义的关联规则算法可获得一切满足符合条件的最小置信度和支持度阈值的规则。为了获得上述目标,有学者提出了Apriori挖掘算法[4],其将关联规则算法分成两组不同的子问题进行处理:①利用置信度指标,获得强关联属性的规则;②按照支持度规则算法,获得算法的频繁项集。但是对数据库进行反复扫描和算法产生的大量的候选集严重影响算法的性能。同时,关联规则计算过程中频繁项集处理速度严重影响着算法的计算效率,因此提高Apriori算法的计算效率是当前的研究热点。为了降低算法执行中I/O操作复杂度,在对数据库进行一次扫描中会获得多组大小各异的频繁项集[5]是主要的改进措施,同时采取的措施有利用位操作实现集合操作的提速[6];为降低算法的内存占用,一般可将数据按照垂直和水平向进行压缩,获得进位表处理方式[7]。此外,还有算法提出利用并行方法实现Apriori数据处理速度提升[8],以及频繁项集逻辑规则改进[9]等方式。
当前,对于关联规则的研究大多集中在规则提取和数量降低上,但存在的问题主要有:①冗余规则具有过于严格的定义,因此规则降低能力有限;②频繁项集所含项数过多会导致关联规则形式过于复杂,导致信息的重复和冗余度过高,不方便使用。为此,提出一种基于层次理论的模糊元关联规则方法,进行微信公众号主题知识的元规则二进制融合提取,允许从单个数据库中获得结果/模式,减少规则挖掘过程中所需的时间。
1 微信公众号服务网络
在微信公众号中标签信息服务、网络API以及网络服务之间存在一定的关联,其构建了微信公众号网络的运作基础。微信公众号网络通常情况下可由下列4部分因素构建:①微信公众号网络社区划分;②微信公众号网络主题标签定义;③微信公众号服务的数据采集;④微信公众号网络的主题用户查询,具体如图1(a)所示。

图1 微信公众号服务网络模型
定义1 (M-M网):构建微信公众号服务与微信公众号服务间网络关系,如图1(b)所示。图中,方框表示微信公众号服务,服务之间的连线是指微信公众号网络中服务间存在的关系。那么M-M网形式为
M-M=(N,E)
(1)
式中:E表示微信公众号网路中服务之间的相互关系集合,N表示网路内微信公众号所包含的服务集合。
定义2 (A-M网):构建微信公众号服务与API服务之间存在的二模关联网络,如图1(b)所示。圆圈或方框表示的是API或者微信公众号服务,图中连线是网络模型中API服务与微信公众号服务之间存在的调用联系。可看出微信公众号一般是与多组API服务之间构成关联。
按照以上定义形式,微信公众号服务推荐过程即为通过聚类策略使得相同类别的服务进行分类并向用户进行推荐,并且希望这种服务的推荐足够准确,可以满足用户对于精度和实时性的需要。
2 基于层次理论的模糊元关联规则
2.1 有关定义


(2)
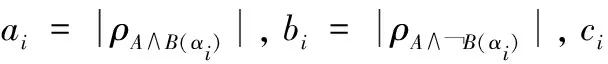
(3)
式中:必须至少有一个原像α∈Λ,通过设定Λ=1可对其进行清晰化

(4)
(5)
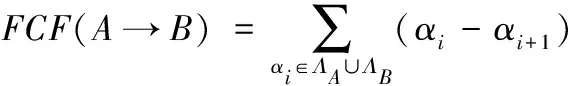
(6)
当|ρA(αi)|=0时,置信度计算可能具有不确定形式0/0,这种情况是不允许存在的。因此,为了确保模糊规则的定义,对于上述不确定情形,设定其为1。
2.2 元规则提取
元关联规则的目的是从数据库中获得数据的位置分布或横向分区存储,在这两种情况下,希望从每个主要数据集的一组关联规则中提取可能的关联。对于大规模、复杂和异构的微信主题数据集,这种处理方式是有效的[14,15]。
这里利用示例进行说明,假设一个多分支机构,例如微信主题标签,有许多的分支遍布网络。在这种情况下,每个单独微信分支存储的数据将具有相似的结构。利用元规则融合提取的知识具有一定的优势:①处理完整数据集是没有必要的,这会降低算法计算效率。②它允许从单个数据库中获得结果/模式,减少规则挖掘过程中所需的时间。


图2 从原始数据集到最终的元关联规则
然后,我们可以区分模糊或清晰的元关联规则,步骤如下:
步骤1 令{D1,D2,…,Dk}是一组属性共享的数据库。应用规则提取程序,每个数据库中可为每个Di提取一组不同的关联规则Ri。关于发现的关联规则及其评估值可表示成集合R1,R2,…,Rk,其中有很多重复规则,不失一般性,假设采取相同的阈值最小支持和确定性因子用于数据集处理。

表1 布尔(上)和模糊(下)元数据库
2.3 模糊层次元关联规则融合
元关联规则挖掘过程如算法1所示。所谓的频繁项集或候选集的项计算过程见算法1中第(6)~(12)行代码所示。这些规则利用高于用户定义的阈值进行提取,见算法(13)~(15)行代码所示。第一步计算所需计算最为复杂,并提出了不同的启发式策略,以减少在规则挖掘过程中花费的时间。在所提算法中,使用二进制位串对项进行表示,加快连词的计算速度,此外使用二进制表示的内存占用不高,降低了系统的内存需求。
算法1: 元关联规则
输入:D2,…,Dk,at1,at2,…,atm,minsupp,minCF;
输出:R1,R2,…,Rk;
(1)forallDido
(2) #Di预处理
(3) 读取Di, 并存储项I;
(4) 将Di转换成布尔数据库;
(5) #关联规则的挖掘
(6)ifSupp(X)≥minsuppthen
(7)X∈C#C为候选集
(8)endif
(9)forallX,Y∈C;X∩Y=∅do
(10)ifSupp(X→Y)≥minsuppthen
(11)X∧Y∈CandX→Y是频繁的;
(12)endif
(13)ifCF(X→Y)≥minCFthen
(14)X→Y∈RiandX→Y为确定的;
(15)endif
(16)endfor
(17)endfor
(19)编译所有不同的规则R1,R2,…,Rk;
(21) #元规则挖掘
(22)利用D反复执行步骤(2)~步骤(16);
那么基于层次理论的元关联规则融合算法可见算法2所示。在并行水平集上利用式(4)和式(9)的FSupp和FCF进行模糊评估。特别是在步骤(9)中,对于每个α∈Λ,可对确定性因素和清晰度支持进行独立计算,并对式(4)和式(6)的计算结果进行权重和计算。
算法2: 模糊关联规则挖掘

输出:FR,#模糊关联规则集

(2) 读取Di, 并存储项I;

(4) 将数据库编码成二进制的p向量;
(5) #关联规则的挖掘
(6)forallαi∈Λdo
(7) 反复执行算法1的步骤(6)~步骤(16), 在每一级获得清晰规则集;
(8) 读取层级αi中所有被发现的规则;
(9) 利用式(4)和式(6)计算FSupp和FCF;
(10)endfor
(11)收集满足FSupp和FCF要求的规则;
2.4 计算复杂度分析
如前所述,关联规则挖掘算法通常有两个步骤。该算法的计算复杂度为O(|D|2|I|)。在我们所提方法中,因为原始Di可实现并行化处理,算法1中(1)~(17)行的第一阶段,具有与标准算法相同的计算复杂度,O(|D|2|I|),取决于每种情况下的交易数量|Di|和项的数量。算法1中(18)~(22)行的第二阶段,计算复杂度与初始数据库规模k、附加属性的数目m、以及第一步中获得不同规则数目相关。由此可得,其计算复杂度为O(k2m+r),因为算法2所示计算过程对于α∈Λ是并行执行的。
3 实验分析
3.1 性能测试
为直观表现算法性能优势,这里利用Matlab聚类算法分析工具箱对所提关联规则算法进行实验对比,对比算法选取标准Apriori算法。硬件设置CPU:i3-6500K,内存大小为8GRAM,系统为Win10旗舰版。测试集选取Matlab聚类算法分析工具箱中的nDexample数据集,人造数据集的具体参数:data.X=nDexample(5,250,2,0),并利用工具箱中自带的clusteval函数对算法聚类效果进行评价,该评价函数采用了等值线评价方式,能够更加直观获得算法聚类数据效果,如图3所示。

图3 nDexample聚类效果对比
根据图3所示本文算法与标准Apriori算法聚类效果对比情况。可看出在nDexample测试集上结果,图3(b)所示的数据点中有8个数据点未被正确的进行识别,而在图3(a)中没有正确识别的数据点的数量比8个更少。这表明本文算法在聚类效果上要优于标准Apriori算法。
为了对算法分类结果进行量化对比,这里选取统计指标CF对规则的获取概率进行测度,测试数据集选取matlab聚类工具箱MotorCycle数据集,统计指标CF具体形式为
(7)
式中:mValue是相应的度量均值。图4(a)、图4(b)分别给出本文算法和对比算法在MotorCycle数据集上的数据分类效果的盒状图测度。

图4 盒状图测度对比
图4(a)、图4(b)所示结果显示,在规则的获取概率上,图4(b)所示的本文算法获得的规则可获取概率的分布更为集中,而原始关联规则挖掘算法的规则可获取概率的分布更加分散,这表明本文算法获得的规则的冗余度更低,而对比算法的规则的冗余度较高,存在较多的重复规则和无效规则。
3.2 微信公众号主题关联规则挖掘效果
为验证本文所提微信公众号主题推荐算法有效性,利用本文网扒数据获得的微信公众号主题数据集进行推荐效果对比,所采用的微信公众号主题推荐算法评价指标如下[12,13]
推荐精度对比
(8)
式中:参数mispl(ci)与succ(ci)分别表示微信公众号主题被错误或正确推荐到分类ci的数量。
主题评价指标
(9)
式中:reli是微信公众号服务和主题对应等级:无关、一般、相关。
对比主题推荐策略选取文献[14]所提的DAT-kmeans分类算法和文献[15]所提的DTV-kmeans推荐算法。仿真结果见表2以及图5。
表2所示为微信公众号主题的DCG均值,根据表2结果可知,在k=2取值情况下,微信公众号主题的DCG均值最大,这表明微信公众号中主题数为2的对应服务数最大。

表2 DCG均值

图5 微信公众号主题推荐结果对比
在微信服务器上网扒获取的7260组微信公众号服务可分成6种类别,分别为:①地图类微信公众号服务;②数据传输类微信公众号服务;③艺术类微信公众号服务;④搜索类微信公众号服务;⑤插件类微信公众号服务;⑥网购类微信公众号服务。图5(a)所示为选取的对比推荐方法的微信公众号主题推荐数量对比情况,图5(b)所示为选取的对比推荐方法的微信公众号主题推荐精度对比情况,图5(a)结果也显示主题数为2的对应服务数最大。图5(b)显示本文算法在第1、第2、第3和第6类微信公众号主题服务上的推荐精度相对于选取的推荐策略精度更高。本文策略在第4类微信公众号主题的推荐精度要比DAT-kmeans略低,但是仍然高于DTV-kmeans微信公众号主题的推荐精度,而算法在第5类主题的推荐精度比DTV-kmeans主题推荐精度略低,比DAT-kmeans主题推荐精度高,总体上本文算法要优于选取的对比策略。
为了对比算法在计算复杂度上的性能对比,这里仍然选择DAT-kmeans和DTV-kmeans两种算法作为对比,多3种算法的计算时间进行对比,结果见表3。

表3 算法计算时间对比
根据表3实验结果可知,在选取的对比算法中,本文算法的计算时间为9.5 s,DAT-kmeans和DTV-kmeans两种算法的计算时间分别为21.3 s和15.6 s,本文算法相对于上述两种算法的计算效率分别提升39.1%和55.4%,体现了较高的算法计算效率。
4 结束语
本文提出一种微信公众号主题层次模糊元关联规则聚类预警方法,对于微信公众号的网络主题模型进行研究,获得其服务本体和AM、MM模型定义,利用每个单独微信分支存储的数据所具有的相似结构,进行微信公众号主题知识的元规则二进制融合提取,无需对整个数据集进行处理,减少规则挖掘过程中所需的时间。下一步研究方向:①算法应用系统开发;②建立更大规模数据库对算法进行验证;③考虑利用中文算法直接进行关联规则构建。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
新世纪智能(数学备考)(2021年9期)2021-11-24
数学小灵通(1-2年级)(2021年4期)2021-06-09
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
Coco薇(2017年11期)2018-01-03
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
读者(2017年5期)2017-02-15
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
