
多层卷积特征融合的行人检测
2018-11-17 01:26吕俊奇邱卫根张立臣李雪武
计算机工程与设计 2018年11期
吕俊奇,邱卫根,张立臣,李雪武
(广东工业大学 计算机学院,广东 广州 510006)
0 引 言
行人检测在车辆辅助驾驶、智能视频监控、人机交互等领域具有广泛的应用[1],也是计算机视觉中极具挑战问题。
Dalal等[2]提出了稠密的、重叠的、固定尺度的HOG局部特征描述子描述人体轮廓。该描述子借鉴了旋转尺度不变特征(scale invariant feature transform,SIFT)中运用梯度方向直方图表示目标的思想。
DPM(deformable parts model)[3]算法采用了传统的滑动窗口检测,通过构建尺度金字塔在多种尺度空间上搜索候选目标,对目标的形变具有很强的鲁棒性。
Dollar等[4]提出融合积分图和原始HOG特征的多通道特征(aggregate channel features,ACF),利用级联决策树构建AdaBoost分类器,进一步提高了行人检测精度。
从2014年开始,基于深度学习的目标检测取得了巨大的突破,以R-CNN[5]为代表的目标检测框架在VOC目标检测数据集上取得了较好的成绩,通过结合候选区域提取和卷积神经网络分类,利用卷积神经网络强大的学习特征能力极大提高了特征提取的能力。
针对目标的多尺度问题,R-CNN使用Selective Search[6]生成多尺度的目标假设区域,然后将这些建议归一化CNN支持的大小(例如224×224)。然而,从计算的角度来看,这种做法非常低效。最新的Faster RCNN[7]通过区域生成网络(RPN)来共享卷积运算,该网络实现了网络端到端的快速高效训练。RPN通过使用一组固定大小的滤波器在卷积特征图上滑动,来产生多种尺度的目标候选区域。然而这种机制造成了可变大小的目标和固定过滤器感受野之间的匹配不一致。
特征金字塔是多尺度的行人检测的常用技巧,但是构建金字塔会带来存储空间的消耗和计算量的巨大开销,因此目前基于深度学习的行人检测回避了使用特征金字塔进行特征表示。针对行人的多尺度问题,本文尝试利用卷积神经网络的金字塔结构构建内在的多尺度,并且引入全局和局部上下文信息,提高算法对小目标以及遮挡严重的行人检测能力。
1 行人检测系统架构
目标检测的问题被定义为确定目标在图像中的位置以及每个目标所属的类别。上述定义为我们提供了如何解决这样一个问题的线索:通过从图像生成目标候选区域,然后将每个候选区域分类到不同的对象类别。在某种程度上,这种两步解决方案与人类看到事物的注意机制相匹配,这首先是对整个场景进行粗略扫描,然后着重于我们感兴趣的区域。
与Faster RCNN类似,我们的行人检测算法也采用注意力机制,由两大模块组成:候选框提取模块和检测模块。其中,候选框提取模块是全卷积神经网络,用于提取目标候选区域;检测模块针对区域生成模块提取的候选区域识别并定位目标。
1.1 特征提取
传统的目标检测,构建图像金字塔,将图像放大或缩小为一组尺寸,然后提取特征,这样带来了巨大的计算量,在深度卷积网络领域这种机制是无法接受的。然而,图像金字塔不是计算多尺度特征表示的唯一方法。深度卷积网络逐层计算层次化特征,子采样层的特征层次结构具有固有的多尺度金字塔属性。这种网络内在的特征层次结构产生于不同空间分辨率的特征图,我们使用特征上采样替代输入图像上采样,改变特征图的尺度大小,这表明可以减少内存和计算成本。
深度卷积神经网络的结构如图1所示。

图1 深度卷积神经网络的结构
1.1.1 采样
深度卷积网络,通过多个卷积层提取图像的特征,通过多个池化层不断增大卷积核的感知野。这种机制使得高层的卷积具有较高层次的语义特征,但多次池化使得目标物体的尺寸不断缩小。例如分辨率为32×32的物体,经过VGG16[8]的多层卷积之后,最后一个卷积层获得特征图分辨大小为1×1。深层卷积网络中,小物体经过多层卷积和池化之后,特征图逐步变小导致包含的信息太少,从而引入了分类错误。
HyperNet[9]提出对高层卷积采用去卷积,通过插值上采样扩大特征图的大小,使小物体能够产生较强响应的较大区域。
1.1.2 特征融合
深度卷积网络逐层计算层次化特征,产生不同空间分辨率的特征图的同时。拥有较大特征图的浅层卷积更注重目标的细节信息,但是包含的目标语义信息更少;卷积网络中深层卷积更注重目标的语义信息,但经过多次池化操作之后,目标在特征图上的分辨率很小。通过卷积层的特征融合,使得提取的特征既可以获得高层语义信息,还可以得到小目标物体的更多信息。
1.2 候选区域生成模块
给定输入图像(假设分辨率为600×1000),经过卷积操作得到最后一层的卷积特征图,分辨率缩小了16倍。与传统的滑动窗口类似,在这个特征图上使用3×3的卷积核与特征图进行卷积,VGG16的最后一层卷积层共有512个特征图,那么这个3×3的区域卷积后可以获得512维的特征向量,输出到两个并行的全连接层,分别用于分类和边框回归。


图2 边框回归

(1)先做平移(△x,△y),△x=pwdx(p),△y=phdy(p)即
(1)
(2)
(2)然后做尺度缩放(sw,sh),sw=pwdx(p),sh=phdy(p)
(3)
(4)

tx=(Gx-px)/pw
(5)
ty=(Gy-py)/ph
(6)
tw=log(Gw/pw)
(7)
th=log(Gh/ph)
(8)
(9)
1.3 目标检测模块
目标检测网络将整个图像和一组带类别和位置标记的目标作为输入。网络首先用多个卷积层以及池化层处理整个图像,以产生最后的卷积特征图。
采用FC-Dropout-FC-Dropout管道[10]是目标检测的一个简单而实用的做法。在FC层之前,我们添加一个Conv层(3×3×63),除了增强分类器的性能之外,该操作将特征图的维度降低了一半,减少了计算量。与区域生成网络相似,目标检测网络为每个区域候选框添加了的两个全连接层。不同之处在于每个候选框都有N+1个输出得分和4×N个边界框回归位置偏移(其中N为类别的数量,再加上背景类)。通过输出层对每个候选框评分和调整。
根据它们的分数,对区域采用非极大值抑制算法[11],抑制高度重叠的候选区域,从而降低了冗余和减少了算法的计算量。
2 实 验
2.1 数据集和评估指标
我们分别在VOC 2007数据集和Brainwash数据集[12]上评估了我们的方法。VOC 2007数据集中包含9964张带有多种类别标记和目标位置的图片,训练样本图片5012张,测试样本4952张。包含20种目标类别的VOC数据集一般作为通用目标检测的数据集,其中包含的行人目标的数目为4690。同时我们还在更大的Brainwash数据集上进行实验并验证我们的方法。
Brainwash数据集从视频片段中提取图像,提取时间间隔为100 s,训练集和测试集的样本图片没有任何重叠,总共包含11 917张图像和91 146个已标记的行人目标。其中训练集包含了82 906个实例,测试集、验证集分别包含4922个和3318个实例。
将分类器检测到的行人目标与XML标记文件的标记矩形框对比,如果重合百分之七十以上判定为目标检测正确。统计所有的检测结果,使用P-R曲线衡量分类器的性能,统计分类器的准确率(precision)和召回率(recall),最后利用平均准确率(mean average precision,mAP)来衡量分类器的性能。
2.2 实验结果以及对比分析
实验基于caffe版本的Faster RCNN,使用VGG16架构的卷积网络。利用在ILSVRC2012[13]上预训练模型,通过迁移学习的方法在VOC数据集和Brainwash数据集重新训练并评估我们的方法。
2.2.1 特征融合
由于CNN中的下采样操作,不同卷积特征层的尺寸大小不同。为了融合多个卷积图,需要将卷积特征图规范化统一为相同尺寸大小。我们采取不同的采样策略来融合不同层的特征。如图1所示,对较低层Conv3_3进行最大池化,减小特征图的大小。对于较高的卷积层,我们使用去卷积操作(Deconv)进行上采样增大特征图。将卷积层conv3_3,conv4_3,conv5_3融合后的特征输入到后面的RPN模块。如表1所示,增加特征融合使得VOC2007的检测结果增加了2.9个百分点。

表1 多层卷积特征融合前后对比
2.2.2 上下文信息
在Faster RCNN算法中,RPN模块获得的候选区域,采用一种特殊的池化方法(RoI Pooling),使得在不同大小的图像上获得相同维度的卷积特征。如图3所示,我们除了对目标候选区域进行RoI Pooling操作之外,我们还对整个图像采用RoI Pooling操作来获得全局上下文信息。相应的通过放大目标候选区域,获得目标局部上下文信息,我们将放大比例设置为1.5倍。全局和局部上下文特征仅仅被用来目标分类,不参加边框回归。
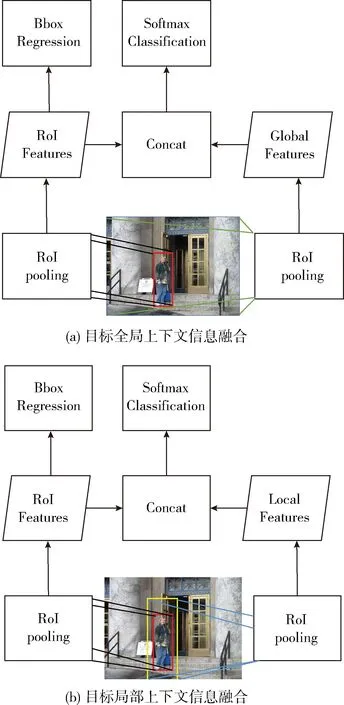
图3 上下文信息融合
如表2所示,增加全局上下文信息和局部上下文信息使得检测结果分别提升了1.5个以及1.1个百分点。融合多层卷积特征和目标上下文信息之后,相比原始的Faster RCNN算法,我们方法的检测结果从69.9提升到74.2,提高了4.3个百分点。

表2 上下文信息融合前后对比
不同于VOC数据集,Brainwash数据集包含了大量遮挡比较严重的行人目标,而且行人的尺度比较小。实验表明改变非极大值抑制的阈值,Faster RCNN算法的检测结果相差很大。通过分析3种不同的nms阈值的Faster RCNN的结果以及我们的算法在Brandwish数据集上的结果,如图4所示。其中nms的阈值为0.75时,Faster RCNN对同一个目标会产生多个连续预测结果,导致了较差的准确率。当nms的阈值为0.25时,Faster RCNN在Brainwash数据集的测试集上取得最好的检测结果,但仍然落后于我们的方法。部分检测结果对比如图5所示,在当行人目标较小、较模糊时,原始的Faster RCNN算法存在大量的行人目标漏检问题,而我们的方法在这方面好很多。
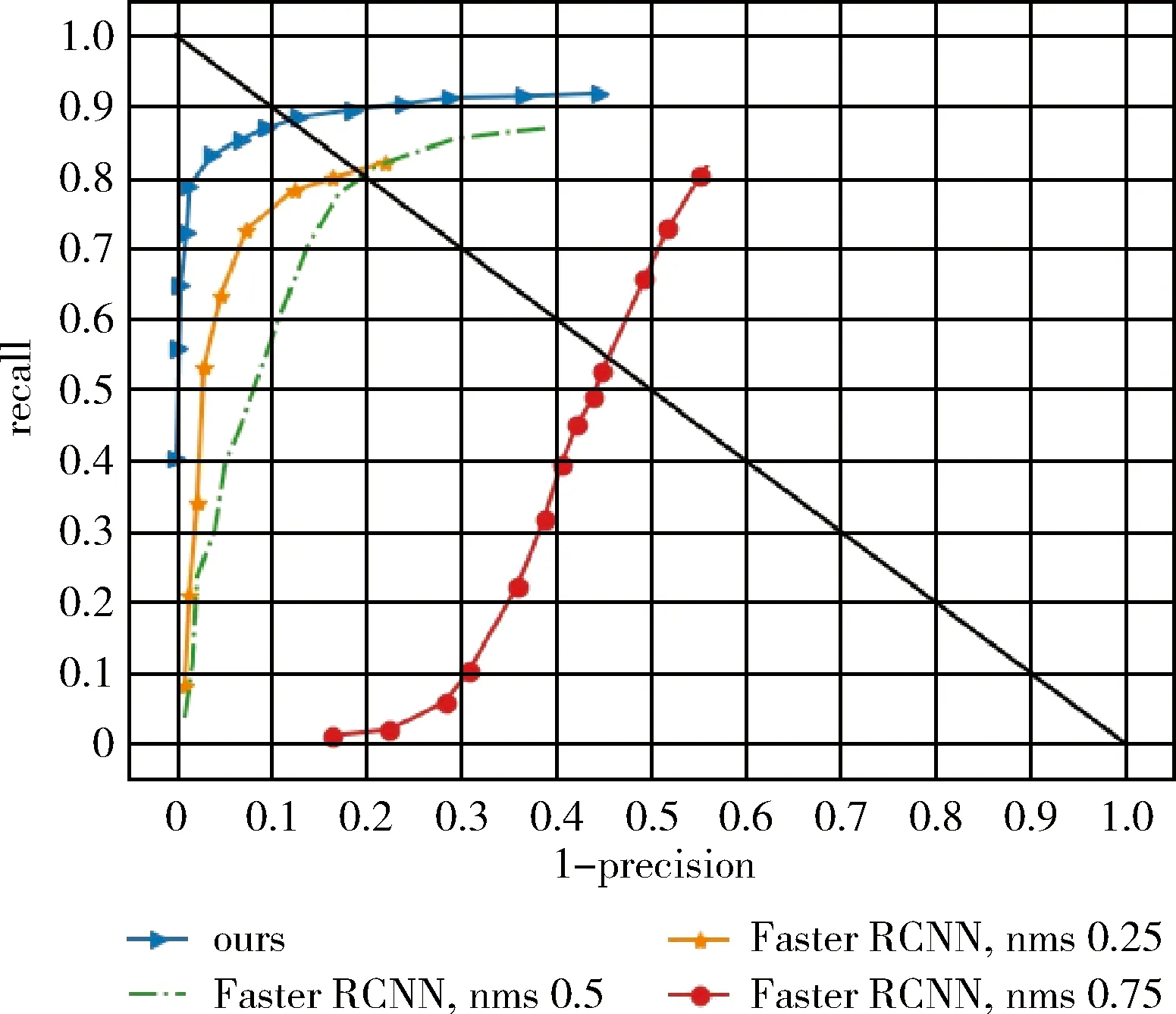
图4 在Brainwash数据集的测试结果

图5 在Brandwish数据集上部分检测结果
3 结束语
本文提出的方法在Faster RCNN算法的基础上,融合了多尺度以及目标全局和局部上下文信息。测评结果表明,相比于Faster RCNN算法,所提出的方法对不同尺寸、遮挡严重的目标检测效果均有明显的提升。模型融合多层卷积特征后,对于多尺度目标的平均检测准确率提升了2.9%。在包含更多遮挡目标的Brainwash数据集的测评表明,融合上下文的检测网络相比原始的Faster RCNN,平均准确率提升了4.3%。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
