
改进的LeNet-5模型在苹果图像识别中的应用
2018-11-17 01:26张力超张垚鑫
计算机工程与设计 2018年11期
张力超,马 蓉,张垚鑫
(石河子大学 机械电气工程学院,新疆 石河子 832003)
0 引 言
早期的图像识别与分类系统主要是基于用尺度不变特征变换(scale-invariant feature transform,SIFT)[1]和方向梯度直方图(histogram of oriented gradients,HOG)[2]等特征提取方法进行特征提取,再将提取到的特征作为支持向量机[3]、Adaboost[4]等分类器的输入来进行识别与分类。然而很多特征本质上都是通过人对特定问题进行深入研究之后设计的,当问题较复杂的时候,特征的设计将十分困难。因此,这段时期的视觉识别与分类系统大多是针对某个或某几个特定的识别任务,数据量一般不大,且泛化能力也较差。
卷积神经网络[5](convolutional neural network,CNN)是一种前馈的多层神经网络,其布局更接近于实际的生物神经网络。CNN不同于以往的机器学习方法,直接对图像练数据进行学习,其输入是图像的像素值而非显示特征。此外,CNN网络采用一种共享权值的方式,即同一层的不同神经元映射权值是相同的,极大降低了网络中需要学习的参数量,降低了网络的复杂性,使得网络可以并行学习,这是卷积网络的另一大优势[6]。因此,CNN在语音识别[7,8]和图像处理[9,10]方面有着独特的优越性。
上世纪90年代,Facebook公司的LeCun基于卷积神经网络CNN这一特殊的深度学习,研发了一套命名为LeNet的手写数字识别系统,IEEE计算机学会为此给他颁发了著名的“神经网络先锋奖”。但由于数据量和计算资源有限等原因,CNN在图像识别领域经历了一段时期的萧条,支持向量机和其它的一些更简单的感知器模型则得到了更高的关注。然而随着大数据时代的到来,GPU和分布式计算的出现,计算机的计算能力得到了极大的加强,尤其是Krizhevsky等提出基于CNN的AlexNet结构模型在ImageNet竞赛中以远超第二名的成绩刷新了image classification的记录,一举奠定了深度学习(deep learning)在机器学习中的地位,近年来其在手写字体识别和人脸检测等各种任务中出色的表现使得深度学习已成为互联网巨头竞争的一个焦点。
国内目前也有一些基于CNN模型的识别与分类研究。曲景影等[11]在对卫星遥感图像中的目标进行分类时就采用了CNN模型进行分类。该文中对传统的LeNet-5网络模型进行了改进,将传统模型中的激励层Sigmoid函数改为ReLu函数,提高了模型的运算效率并取得了不错的分类精度。史天予等[12]则在传统的LeNet-5网络模型中的全连接层后面加入随机Dropout层以提高神经网络的泛化能力。汤一平等[13]在对图像进行一定预处理之后采用CNN模型实现了火炮全景图的瑕疵病识别。本文拟基于LeNet-5模型构建改进的神经网络模型,通过对比实验确定模型参数,实现红富士与红元帅苹果的自动分类。
1 基于改进的LeNet-5苹果分类
LeNet-5是一种典型的用来识别手写数字的卷积神经网络模型。LeNet-5共有7层网络(不包括输出层),每层都含有大量的可训练的权重参数。经典的LeNet-5模型的输入数据先后经过了卷积层-池化层-卷积层-全连接层-激励层-全连接层-Soft Max层。其中最后一层的Soft Max是一种用于解决多分类问题的回归模型,是logistic回归模型在多分类问题上的一个推广。
首先,由于LeNet-5模型最初是用于手写识别,采用的是28×28的图像。而本文的识别对象是红富士与红元帅苹果,图片内容的复杂程度远超过手写数字,参考人脸识别系统[14]所采用的图片大小80×80,本文尝试将64×64像素作为改进的LeNet-5模型的输入,由于输入图像为彩色图像,因此其输入格式为3×64×64。具体模型结构与原始LeNet-5对比如图1所示。

图1 改进的LeNet-5与原始模型对比
其次,由于本文中的初始输入数据是一个3维数据,而原始模型中处理的图像是一维的黑白手写图像。因此本文改进的模型在原始LeNet-5模型全连接层之前加入了一个Flatten层,用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。
再次,为增强模型的泛化能力,本文在原始LeNet-5模型全连接层之后加入了Dropout函数。Dropout是一种能够提高神经网络泛化能力的学习方法,其操作是在训练过程中将一部分的神经元输出设为0,在下一次训练过程时再将之前保留下的值恢复,之后再次随机选择一部分神经元并设其输出为0,如此反复操作,以减弱神经元节点间的联合适应性。
最后,在激励函数方面,本文采用的是LeakyReLU。传统的LeNet-5,激励层所使用的激励函数是Sigmoid函数,该函数计算量较大,且对于深层次的网络结构,反向传播时产生的梯度消失现象较明显以至深层次的神经网络一般以修正线性单元(ReLU函数)取而代之[15]。与Sigmoid函数相比,ReLU函数最主要的优点就是易于优化,并且由于其一半定义域中输出为0,这使得网络变得更加稀疏,有利于缓解过拟合;而另一半定义域输出的梯度保持为1,这就意味着它的梯度对于学习来说将会更加有用。然而ReLU也存在一个弊端,就是当网络进行第一次训练时若权重为0以下时,根据ReLU的计算方式,之后的训练将一直为0。为避免这种现象,本文采用LeakyReLU,这种特殊的ReLU,当神经元不激活时仍会有一个小梯度的非零值输出,从而避免可能出现的神经元“死亡”现象。Sigmoid函数、ReLU函数、LeakyReLU函数的大致图形,如图2所示。
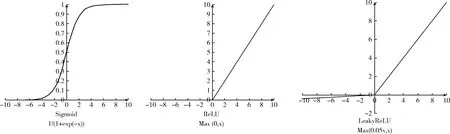
图2 几种激励函数图像
2 实验与分析
2.1 实验材料
本实验中视觉采集系统是由视觉采集箱、环形无影光源以及顶端固定的单目相机组成。实验研究对象是在新疆石河子农贸批发市场采购的红富士苹果和红元帅苹果各300个,每个苹果进行3次拍照,每次拍照时将苹果以果柄为轴翻转大约120度,最终得到两种苹果各900张图像样本,将其中每种苹果的600张图像作为训练样本,300张图像作为测试样本,所有图像尺寸归一化为64×64。单个红元帅与单个红富士苹果的3个面拍摄图片,如图3所示。
图3 部分苹果图片
2.2 实验过程
针对于CNN模型中的优化器选取、卷积核大小、卷积层学习步长、卷积层的滤波器数量对网络模型训练的影响进行了研究。本研究中的参数是在图1模型结构的基础上进行的参数选取,同时卷积核大小等参数均采用LeNet的默认参数,并将首层输入改为3×64×64。在此基础上,通过对比实验,依次选择出最佳的学习率、卷积核大小、卷积层学习步长、卷积层的滤波器数量,进而使苹果的分类准确率达到最优。
(1)优化器选取
本研究中的实验是基于Python平台下的Keras库进行编程的,模型的学习率选取最常用的0.01。原始的LeNet-5模型中采用的优化器是随机梯度下降的方法(SGD),本研究中分别采用SGD、ADAM、RMSProp进行了3组对比实验,其中每组做10次实验取平均值,实验结果见表1,从结果可以看到ADAM取得了最佳的损失函数和对测试样本的分类准确度,故本研究采取ADAM作为模型的优化器。

表1 优化器选取对比实验结果
(2)卷积核大小的选取
在学习率为0.01,优化器选用ADAM的基础上,分别进行了6组对比实验,如图4所示,横坐标表示第一个卷积核大小,每个横坐标对应的5个柱状图分别对应5×5至25×25,以不同颜色深度表示,纵坐标表示平均错误率。通过图中结果可以发现,当2个卷积核分别为17×17和21×21时模型的平均错误率最低。

图4 卷积核大小选取对比实验结果
(3)卷积层学习步长的选取
在前面实验确定的参数的基础上,分别选取步长为(1,1),(2,2),(3,3),(4,4)做4组对比实验。实验结果如图5所示,横坐标表示第一个卷积层学习步长,不同颜色的柱状条代表第二个卷积层的学习步长。通过结果可以发现,当第一个卷积层学习步长为(2,2),第二个卷积层学习步长为(1,1)时,模型的平均错误率最低。同时可以看到一个大致的趋势是,在LeNet-5的模型中第二个卷积层中的学习步长会随着步长的增加降低分类准确度。

图5 学习步长对比实验结果
(4)卷积层的滤波器数量选取
鉴于LeNet-5默认滤波器数量分别为6和16,本研究中分别选取4、6、8和12、16、20作为滤波器数量进行了3组实验,实验结果如图6所示,横坐标表示第一个卷积层的滤波器数量,不同颜色的柱状条表示第二个卷积层的滤波器数量。实验结果表明当滤波器数量分别为6和20时平均错误率最低。
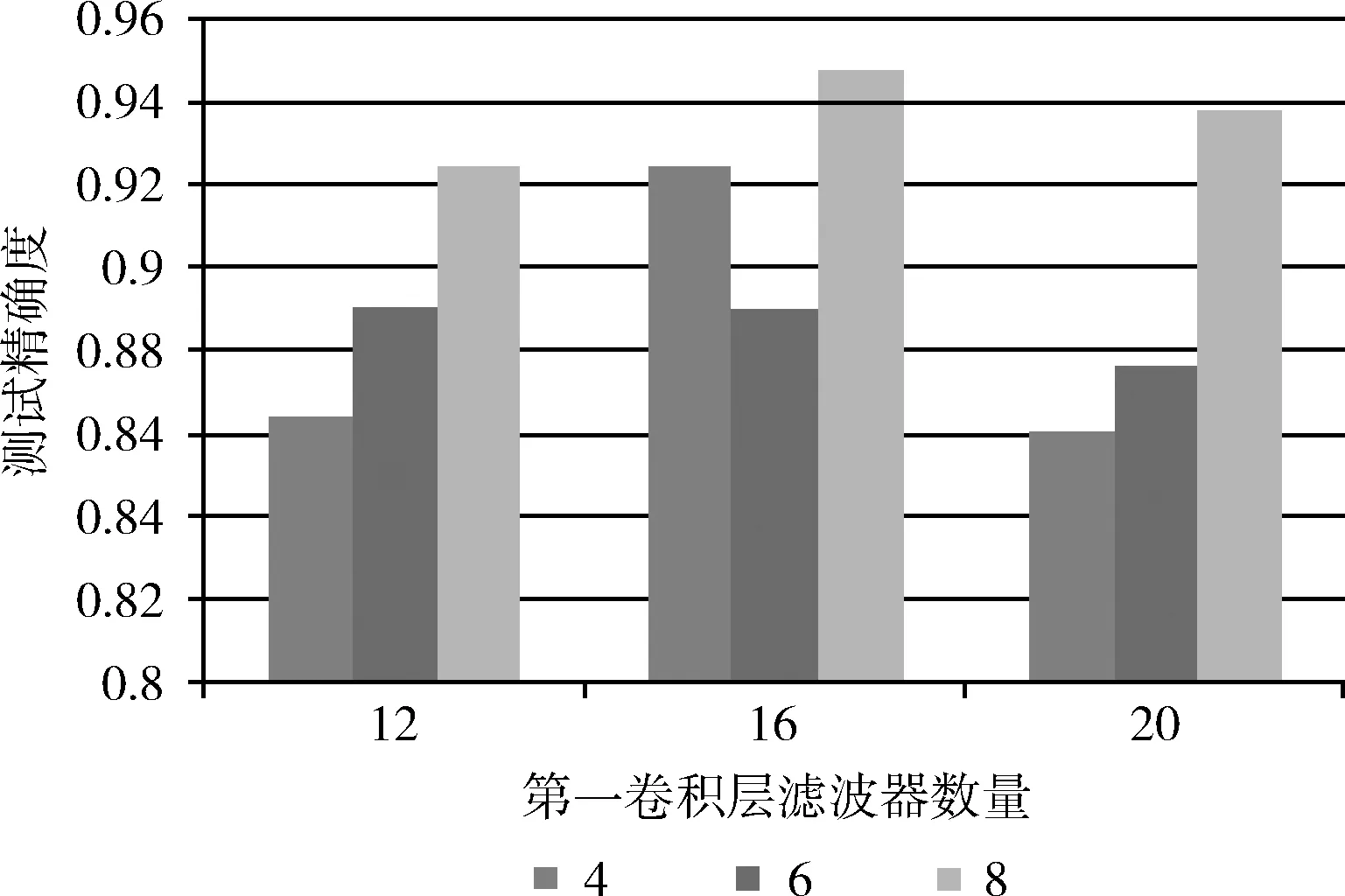
图6 滤波器数量选取对比实验结果
(5)全连接层神经元个数选取
本研究中的模型含有2个全连接层,而第二个全连接层受到所分类个数的影响只能选2,因此对第一个全连接层选取不同个数做了对比实验。实验数据对神经元个数分别为100、200、300、400、500做了5组实验,每组实验进行了10次,将每组10次实验得到数据的平均值作为表2的数据。由下表可以看出当神经元数量为200时具有最高的测试准确度。
综上所述,本文提出的基于改进LeNet-5模型的苹果分类器最优参数为:学习率0.01,ADAM优化器,第一第二卷积层的卷积核尺寸分别为21×21和17×17,学习步长分别为(2,2)和(1,1),滤波器数量分别为6和20,第一全连接层的神经元个数为200,第二全连接层神经元个数为2,此时可达到最高的测试集分类精度95.31%。

表2 全连接层神经元个数选取实验结果
2.3 结果及分析
为验证本文算法的有效性,将目前比较主流的两种SVM方法与本文方法进行了对比。总共进行10次实验,每次实验从每类苹果的900张图片中随机选出300张作为测试样本,其它作为训练样本。相比于CNN方法,SVM的方法的输入是苹果的特征而非图像本身,在经过图像处理后需要经过一定的计算得到所需要的特征参数。结合相关文献[16-18]中介绍的特征参数计算方式,本文对比了目前主流的两种SVM方法。其中SVM+HOG表示采用方向梯度直方图方法提取特征,以9个方向的VL_feat方法进行特征提取,最初采用64×64像素的图片进行实验,但实验结果几乎不能够用来进行红富士与红元帅两种苹果的分类,经多次尝试,最终以256×256图片大小进行实验,以8×8像素大小组成一个Cell,再以8×8个Cell组成一个block,并将此结果与本文CNN进行比较。SVM+G表示采用matlab自带的梯度函数方法提取特征,参数默认,图片大小为256×256。两种方法均用LibSVM工具进行SVM训练与分类测试,svm类型为C-SVM,核函数选择RBF核,惩罚系数默认选择1,进行10折交叉验证,终止准则中可允许偏差设为0.001,学习率0.01。实验结果见表3。
实验结果表明,在测试准确度方面,CNN方法相比于其它算法具有更高的分类准确度,CNN方法相对于其它算法有比较明显的测试准确度,分析其原因是CNN网络不需要人为建立特征,而是由机器自主学习特征,相比于SVM这类可以看成是只有一个隐含层的网络具有更好的泛化能力。在测试阶段耗时上,CNN方法的输入为图像数据本身,不像SVM需要对图像数据进行一系列的计算求得特征参数,因此其运行效率明显的优于其它方法。但需要注意的是神经网络的训练时间,神经网络的训练时间与网络中需要进行学习的参数数量有直接关系[19]。本文算法的训练耗时优于SVM的方法主要是由于LeNet-5模型本身层数不高,同时经过对比实验得出的最佳参数中,全连接层神经元个数也并不多,因此在训练时间上相比SVM更优。由此可以得出,经过合理改进的LeNet-5模型,可以适用于对红富士以及红元帅两种苹果的分类。

表3 几种方法的测试准确度
3 结束语
本文提出了一种基于LeNet-5改进的CNN模型进行红富士苹果与红元帅苹果分类。由于CNN模型不同于以往的模式识别方式,减少了人工手动建立并提取特征的难度,这是采用CNN网络进行分类的好处之一,此外在数据量庞大时这种分类器在时间效率和泛化能力方面也具有明显的优势。
本文在LeNet-5模型的基础上进行了改进,将最初适用于1维黑白手写数字识别的CNN模型改进成一种可以用于处理彩色苹果图片的模型。通过实验,确定了最佳模型参数,构建了基于改进LeNet-5模型的苹果分类器,并与SVM+HOG和SVM+G进行了分类实验对比,实验结果表明CNN方法相比于SVM方法在测试精度和训练时间上都有较明显的优势,论证了本文方法的有效性。在下一步的工作中,将继续对分类模型进行改进,以进一步提高苹果分类的精度,并尝试将其应用于更多的分类领域中。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
自然杂志(2021年6期)2021-12-23
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
现代装饰(2018年5期)2018-05-26
北京航空航天大学学报(2018年1期)2018-04-20
电源技术(2015年5期)2015-08-22
河北科技大学学报(2015年5期)2015-03-11
弹箭与制导学报(2015年1期)2015-03-11
电测与仪表(2014年2期)2014-04-04
