
基于Fisher准则和TrAdaboost的高光谱相似样本分类算法
2018-12-20 11:10刘万军李天慧曲海成
自然资源遥感 2018年4期
刘万军, 李天慧, 曲海成
(辽宁工程技术大学软件学院,葫芦岛 125105)
0 引言
随着卫星遥感技术的不断发展,高光谱图像的获取变得更加容易。相对于多光谱遥感,高光谱遥感能够获得大量的波段信息,这些波段信息被广泛应用于目标探测、环境监控和地物分类等方面[1],其中高光谱遥感图像的分类问题一直是国内外学者研究的热点。高光谱遥感图像具有维数大和训练样本数量少的特点[2],在小样本图像分类情况下,维数过大易导致分类任务变得复杂,分类精度会因为波段数量的增加反而下降,从而产生Hughes现象[3]。其中支持向量机(support vector machine,SVM)的分类算法常用于解决此类问题[4]。杨凯歌等[5]将随机子空间集成法结合SVM提出优化子空间SVM集成的分类算法,利用SVM对随机子空间进行聚类,根据J-M距离准则对最优分类器进行集成,通过对比实验证明该算法可以有效地解决小样本情况下的分类问题;Persello等[6]通过对比主动学习策略和半监督学习方法的优缺点,结合2种方法应用在SVM上,解决了小样本情况下未知样本标注问题。
此外,迁移学习通过对同领域或者跨领域进行知识迁移也可以解决小样本情况下的高光谱图像分类问题,当源训练样本集包含的带标签样本数量非常少时,迁移学习将与源训练样本集相似的样本作为辅助样本集,与源样本集组成总训练样本集完成目标样本集的分类、识别等任务[7]。吴田军等[8]将迁移学习应用在高光谱图像分类的样本选择中,将历史的地物信息迁移到新的图像中,建立一种新的特征映射关系,从而实现对目标高光谱图像样本的自动分类;Zhou等[9]将迁移学习应用在极限学习机中,并与最小二乘法结合,利用TrAdaboost算法的权重调整策略对样本进行分类,最后经过对比实验证明了该算法的有效性。其中TrAdaboost算法是Dai等[10]提出的一种基于实例的迁移学习算法,对Adaboost算法进行了改进,使之具有迁移能力,通过判别训练样本的可利用价值调整样本的权重,完成小样本情况下的文本分类任务。
综上所述,SVM和迁移学习分类算法都能够很好地解决小样本问题。但对于高光谱图像分类问题,随着训练样本数目减少(小样本情况),样本维数大且存在冗余波段,相似类别样本间的分类边界变得模糊,导致分类精度大幅度降低。为了解决这个问题,本文提出了基于Fisher准则和TrAdaboost权重调整策略的H_TrAdaboost (Hyperspectral TrAdaboost)算法,利用Fisher准则放大样本间的差异,完成相似样本的划分;结合TrAdaboost权重调整策略,动态调整样本的权重,实现高光谱相似样本的分类;最后,在AVIRIS高光谱数据集上进行对比实验,验证H_TrAdaboost算法的有效性。
1 Fisher准则和TrAdaboost算法改进
1.1 辅助样本集确定
1.1.1 迁移学习
传统的机器学习方法对目标样本分类具有一定的前提条件,要求训练样本和测试样本必须符合相同的数据分布,并且需要足够数量的训练样本才能进行学习。这导致了在小样本情况下很多分类方法都不能取得很好的分类效果。迁移学习作为一种新的机器学习方法被提出,打破了传统学习方法的束缚,可以通过确定辅助样本集来解决样本数量少的问题。为了更加清晰地解释迁移学习,对样本集进行如下描述。
定义1:训练样本数据集Da和Db
(1)
(2)
式中:Da表示辅助训练样本数据集;Db表示源训练样本数据集;Sa为Da的辅助样本空间;Sb为Db的源样本空间;M(x)表示一种映射关系,将样本x映射到它所对应的类别标号上;{()}表示样本和样本对应的类标组成的数对集合。由于Da与Db来自于不同的类空间,表示数据分布是不相同的。
定义2:目标样本数据集Dt
(3)
根据以上定义,迁移学习解决的问题可以描述为:源训练样本集Db含有少量有标签样本,不足以训练出一个适于分类目标样本集的分类器,此时利用迁移学习,可以得到与Db相似的辅助训练集Da,最后合并Da与Db组成总训练集训练分类器,用于分类目标样本集Dt。
由于本文研究的高光谱数据集,具有样本维数大、标记样本少的特点,而迁移学习可以有效解决小样本问题。因此,利用迁移学习,通过确定辅助样本集,将有利于目标分类的样本迁移到训练样本集中,从而扩大总样本数量,解决高光谱分类问题中由于训练样本过少导致的分类问题。
1.1.2 SID_SA结合法
为了扩大训练样本集数量,需要一种合适的光谱相似度测量方法,确定辅助样本集。常规方法有光谱角法(spectral angle mapping,SAM)和光谱信息散度法(spectral information divergence,SID)[11]。SAM的原理是将目标光谱与测试光谱投影到空间中,计算其间的夹角,其值越小代表相似度越高。SID是一种基于信息论理念,通过计算信息熵来判断光谱相似性的方法。而2种方法结合的SID_SA结合法[12]同时考虑到SAM和SID的优点,从光谱的形状以及反射能量差异2方面入手,能有效计算光谱间的相似度。
假设x与y分别代表目标光谱与测试光谱,长度都为n1,则SID_SA结合法公式为
(4)
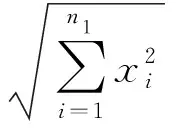
SID(x,y)=D(x‖y)+D(y‖x)
(5)
(6)
(7)
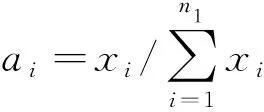
SID_SA(x,y)=SID(x,y)sin[SAM(x,y)] ,
(8)
式中SID_SA(x,y)是本文算法的光谱相似度度量值,值越小,证明光谱相似度越高,反之则说明光谱间相似度低,因此通过对比各光谱间的SID_SA值,确定辅助样本集。
1.2 波段选择
1.2.1 问题分析
为了更好地在小样本条件下进行相似地物类间分类,需要使用一种特征提取的方法,帮助放大样本间的差距,提高分类精度。高光谱图像特征提取方法常用的主成分分析法(principal components analysis,PCA)[13],是通过数学变换来压缩波段达到提取特征的目的,容易改变高光谱图像的光谱物理意义。而波段选择的方法是从大量波段中选择出利于分类的波段数据,构成一个波段子集,这样不会破坏物理结构而且可以达到数据降维的目的。因此本文在解决相似样本划分问题时采用的是波段选择的方法。
以美国印第安纳州高光谱数据集为例进行分析,从中选取名称为corn-notill和corn-mintill的2类相似地物,分别从2类地物中随机选取200个样本点,计算2类光谱均值和标准差。对比结果分别如图1所示。
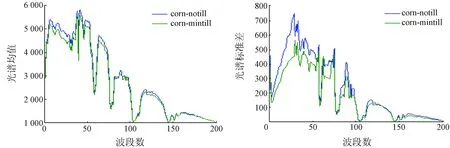
(a) 光谱均值 (b) 光谱标准差
从图1中可以得知,2类样本在B2—B57和B64—B76等波段上的可分性比较大,在B54—B63和B77—B103等波段上的可分性比较小。这说明虽然相似样本间的波段信息比较相近,但是样本在各个波段上仍然具有可分性,如果在实验中对样本的所有波段进行相同的处理,则弱化了一些重要波段的信息。因此,在解决相似样本划分问题中进行波段选择是必要的,需要秉承的原则是最大化样本类间间距,最小化样本类内间距,最终选择可分性强的波段组成最优子集。Fisher准则作为一种直观有效的类别可分性判据,是波段选择的一个重要依据,因此利用改进的Fisher准则可解决相似样本可分性问题。
1.2.2 改进的Fisher准则
改进的Fisher准则是对原始Fisher准则中的距离度量方法由简单的欧氏距离变为马氏距离。其中马氏距离是表示数据的协方差距离[14],在相似度对比过程中,欧氏距离计算2个样本在空间上的直接距离,而马氏距离考虑的是样本数据各种特性之间的关系与差异,放大个体的影响。在不同的总体样本下,马氏距离的计算结果是不同的,更加适合用于相似样本的划分。因此本文采用基于马氏距离的改进Fisher准则对样本进行可分性研究,具体计算公式为
(9)
式中:ai与aj分别代表2条光谱;d为马氏距离。
根据最小化类内间距、最大化类间间距的原则,可以得出改进的Fisher准则Jp为
(10)
(11)
(12)
(13)
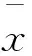
类间可分性越大,SB的值越大;类内可分性越小,Sw的值越小。因此通过最大化Jp可以得到类别可分性强的波段集合,从而严格控制了分类阶段的样本集输入,为分类提供了足够的且具有差别性的样本集。
1.3 权重调整策略
对于最后分类阶段,由于每个训练样本在分类过程中的可利用价值有所不同,因此在迭代训练过程中需要对每个样本进行不同的权重控制。原始的TrAdaboost算法是用于文本分类的,对样本进行权重分配时,分别调整辅助训练样本与源训练样本的权值,达到较好的分类效果。而本文在解决高光谱相似样本分类问题时,同样考虑到不同样本的权重问题,因此采用TrAdaboost算法的权重调整策略对目标样本进行分类。对于辅助训练样本,基本思想是如果样本被错误分类,证明此样本不利于分类,在下一次迭代过程中减少权重,主要通过参数βa实现,即
βa=1/(1+2 lnn/N)
(14)
式中:n代表辅助样本数量;N代表迭代次数。
对于源训练样本,基本思想是如果样本被错误分类,在下一次迭代过程中通过增加权重来强调此样本,更正分类模型,主要通过参数βb实现,即
βb=εt/(1-εt)
(15)
式中εt为第t次迭代过程中分类器在源训练样本上的错误率。
综上所述,如果在N次迭代过程中,分别对2个训练样本集的权重进行动态调整,可以更好地完成小样本情况下相似样本分类任务。
2 H_TrAdaboost算法
H_TrAdaboost算法流程如图2所示。
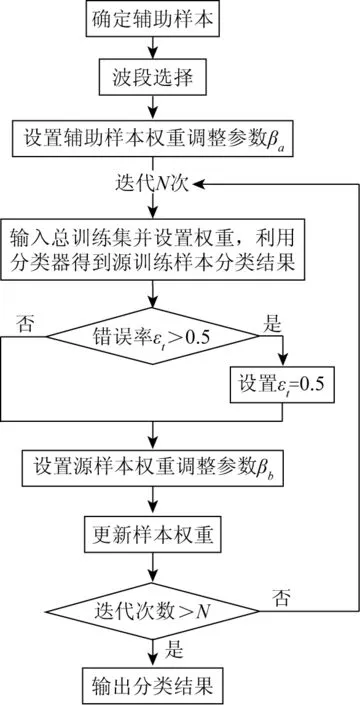
图2 H_TrAdaboost算法流程
本文提出的H_TrAdaboost算法的要点是:首先,利用SID_SA结合法确定辅助样本集;然后,根据改进Fisher准则对波段进行可分性研究;最后,利用权重调整策略完成高光谱相似样本分类。
1)根据小样本的源训练样本数据Db,采用SAM与SID相结合的方法计算光谱间相似值,SID_SA值越小证明光谱越相似,利用式(4)—(8)选择出与Db相似度最大的样本作为辅助样本集Da,合并辅助训练样本集Da与源训练样本集Db为总训练样本集Dt。并初始化样本的权重,辅助训练样本的初始权重设置为1/n,源训练样本的初始权重设置为1/m,即
(16)
2)通过对高光谱相似地物的光谱特性进行分析,得知每个波段的可分性不同,采用基于马氏距离的改进Fisher准则,利用式(12)—(13)对总训练样本Dt计算类内间距,利用式(11)计算类间间距,最后通过最大化类间间距和最小化类内间距,对波段进行最终筛选,将可分性较强的波段组成一个子集,达到放大相似类别样本光谱间差异的目的。
3)已知辅助样本数量n以及迭代次数N,利用式(14)得到辅助样本权重调整参数βa。
4)输入总训练集,设置样本权重为
(17)
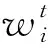
(18)
式中Lt(xi)为样本在第t次迭代后的分类结果。如果εt>0.5,则将εt设置为0.5,利用式(15)得到源训练样本的权重调整参数βb。
5)设置迭代过程中训练样本的权重更新策略,即
(19)
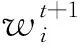
6)最终分类器设置为
(20)
式中:「⎤为向下求和;L(x)代表最终分类结果,如果分类正确分类器输出1,分类错误输出0。
3 实验与结果分析
3.1 实验数据
实验采用美国印第安纳州实验区(Indian Pines)的高光谱遥感图像数据集,通过AVIRIS采集获得,包含了145×145个样本点,原始波段数有220个,除去其中水汽吸收及低信噪比的波段,剩余200个波段将作为实验数据。原始图像共有16种地物类别,真值图如图3所示。由于本文解决的是相似样本分类问题,且其中一些类别样本数量不足,因此选取了其中满足实验条件的8种地物类别,重新编号用于验证实验,具体的样本信息统计见表1。

图3 Indian Pines数据集真值
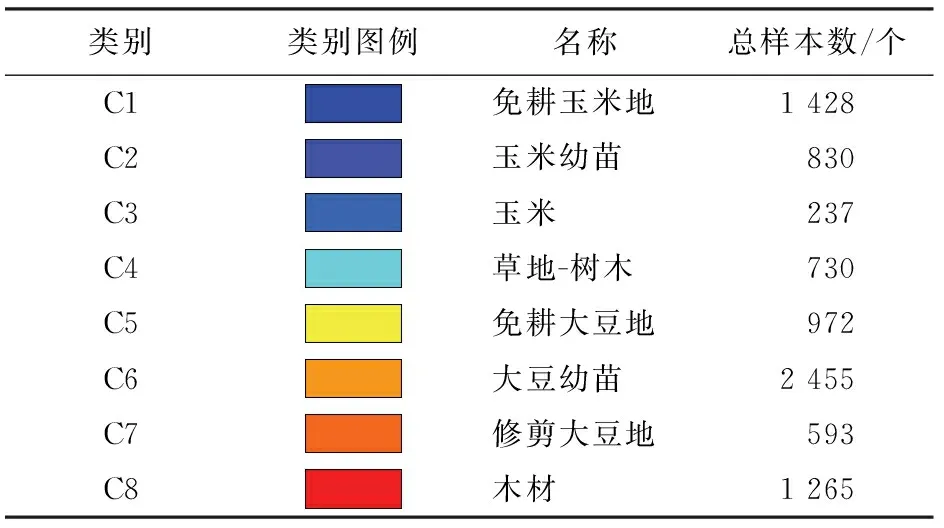
表1 实验用Indian Pines数据集信息
3.2 实验结果
为了验证H_TrAdaboost算法的有效性,将表1的数据集作为实验数据集,实验环境为Matlab2012b。实验过程中,采用随机抽取的方式对源训练样本和辅助训练样本进行选择,实验中分类器参数C和gamma的数值通过十折交叉验证获得。通过前期实验可以得出,当源训练样本集的样本数量小于总训练样本集的15%时,相似地物分类问题变得模糊,精度降低明显,因此本文实验将低于总训练样本集15%的定义为小样本条件。首先进行的实验是采用SID_SA方法确定辅助样本,从样本集中随机选取200个样本作为本部分实验数据,实验得到各类地物之间的SID_SA值见表2。
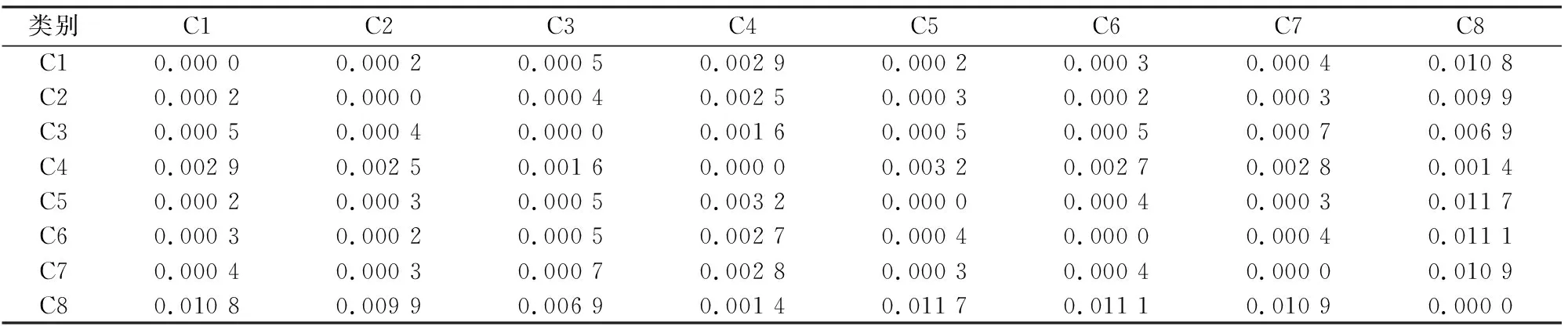
表2 各类别之间的SID_SA值
从表2可以得知,每个类别的样本都有与其相似的样本,例如C1类与C2类、C5类间SID_SA值最小,为相似样本集,同理C8类与C4类为相似样本集,因此,通过对比波段间的SID_SA值可以得到最适合的相似样本类别作为辅助样本集。从实验样本中随机选取测试样本1%的样本点作为源训练样本集,根据SID_SA算法确定辅助样本进行实验。将H_TrAdaboost算法与原始的TrAdaboost算法和SVM分类算法进行比较,分类精度对比结果见表3。
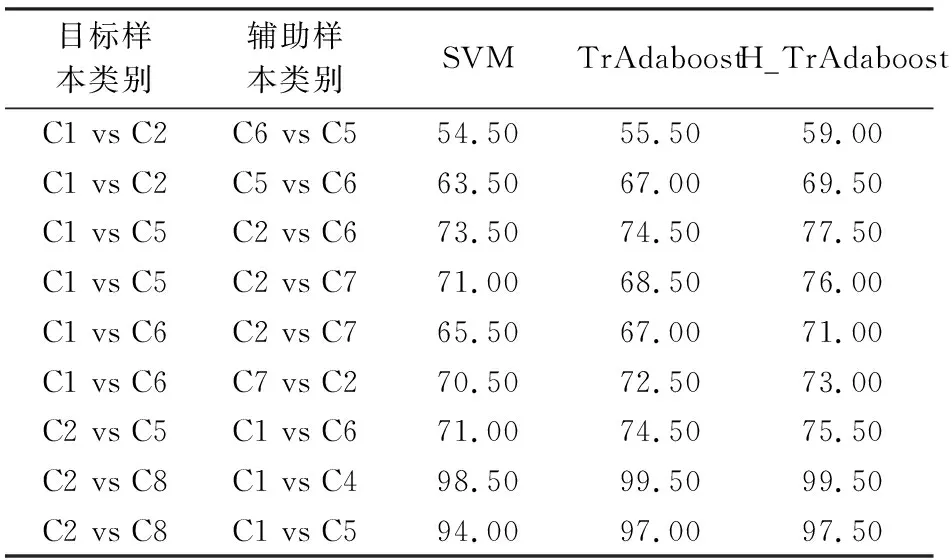
表3 算法间的分类精度对比
从表3中可以看出,当分类C1和C2类样本时,辅助样本类别分别选取为C5与C6类时,分类精度最高且提高较多;当分类C1和C6类样本时,辅助样本类别分别选取为C7与C2类时,分类精度最高且提高较多;从而验证了SID_SA值越小,越适合做辅助样本,帮助源训练样本进行分类。同时,当类别本身相似性很小的时候,例如C2和C8类的分类,3种分类算法的效果都很明显,并且SVM算法、TrAdaboost算法与H_TrAdaboost算法分类精度呈上升趋势。验证了TrAdaboost算法经过数据处理后可以较好地应用在高光谱数据上,分类精度比SVM有所提高,将H_TrAdaboost算法与原始的TrAdaboost算法相比,分类精度也有显著提升,证明此算法在非相似样本分类问题上也具有较好的分类效果。
为了更直观地表示本文算法的有效性,将不同算法对表3中几种类别进行分类,效果分别展示如表4所示。从表4的几组对比图中可以清晰地看出,对C1,C2,C5和 C6等相似类别进行分类时,H_TrAdaboost算法比SVM算法和TrAdaboost算法噪声点更少,分类效果更明显。
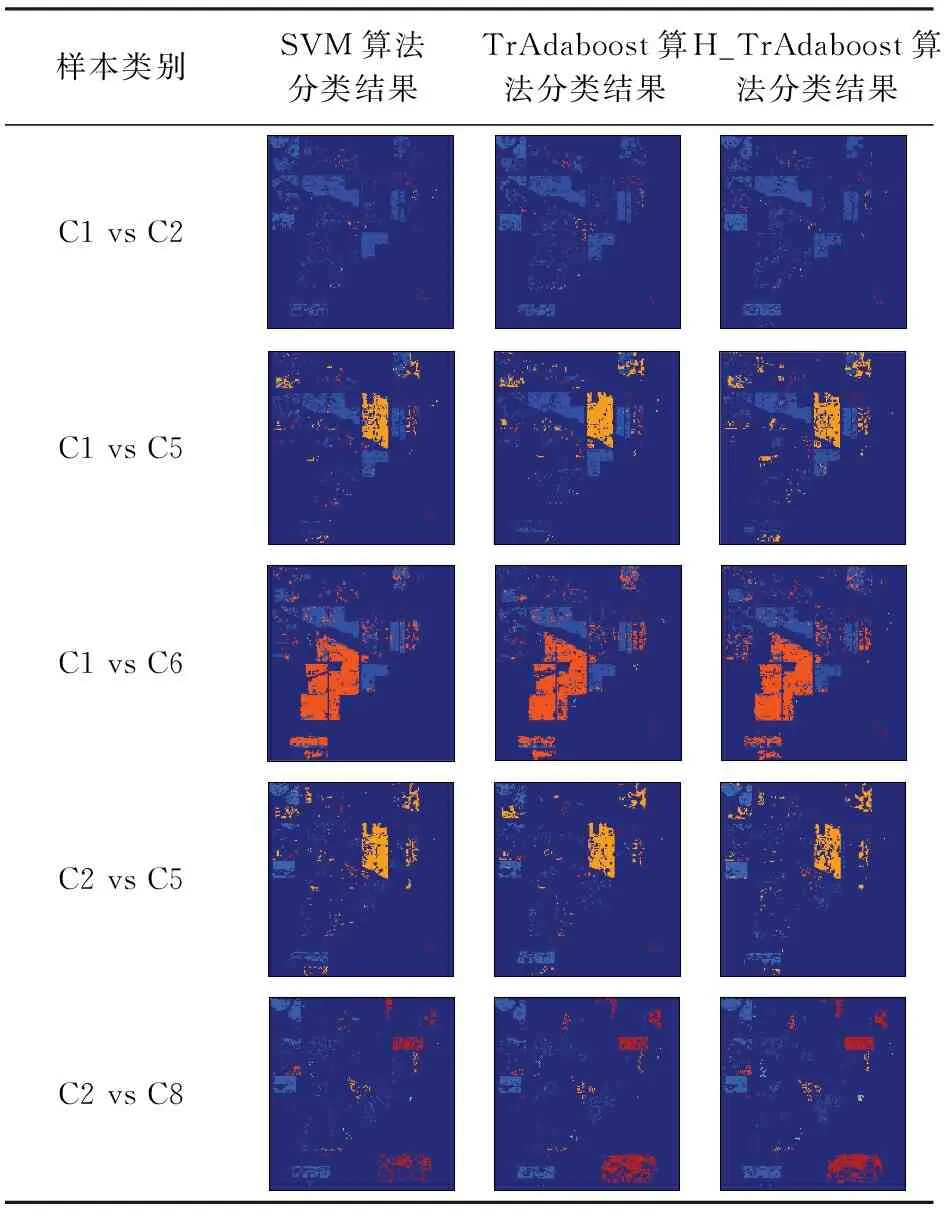
表4 各算法在不同样本上的分类精度对比
为了进一步验证本文算法在不同程度小样本情况下对相似样本的分类效果,将源训练样本数量分别设置为占总样本的1%,2%,3%,5%,10%,15%,对C1与C2类分类,辅助样本选取C5与C6组成样本1;对C1与C6类分类,辅助样本选取C7与C2组成样本2。则H_TrAadboost算法与TrAadboost算法和SVM分类算法的分类精度对比结果见表5与表6。为了便于比较各类算法在不同样本数量下的分类效果,均采用相同的参数设置。

表5 样本1上算法间的分类精度对比

表6 样本2上算法间的分类精度对比
从表5与表6可以看出,样本数量的大小对分类精度有所影响。当源训练样本数量不断减少,分类精度随之降低,即小样本条件越苛刻,相似样本分类效果越不明显。但是实验结果表明,随着源样本数量的降低,本文提出的H_TrAdaboost算法对比原始的TrAdaboost算法以及SVM算法,在对相似样本进行分类时,分类精度仍然高于其他分类算法,说明基于改进的Fisher准则和TrAdaboost提出的算法,可以较好地解决分类问题中的由于相似样本导致分类精度低的问题。
4 结论
1)利用实例迁移思想,采用SID_SA结合法对高光谱波段进行相似度度量,达到了确定辅助样本集的目的,解决小样本问题。
2)改进的Fisher准则侧重于高光谱数据整体特点,利用该准则从训练样本中选择可分性强的波段,达到放大相似样本波段间差异的目的。
3)利用TrAdaboost算法的权重调整策略为样本分配合理权重,最终通过实验表明,H_TrAdaboost算法可以很好地实现相似样本的分类。
4)虽然本文算法对与相似地物分类精度上有了一定提高,但仍有可以改进的地方。下一步的研究方向是考虑结合空间信息,从光谱的空间特征方面进一步提升高光谱相似地物的分类精度问题。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
航天返回与遥感(2022年2期)2022-05-12
空间科学学报(2021年1期)2021-05-22
科技创新与应用(2020年6期)2020-02-29
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
电子制作(2017年8期)2017-06-05
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
中国光学(2015年5期)2015-12-09
