
PCA联合字典的稀疏系数NMF融合
2018-12-20 11:10孙小芳
自然资源遥感 2018年4期
孙小芳
(闽江学院地理科学系,福州 350121)
0 引言
稀疏表达又称为稀疏分解,用冗余函数构造稀疏字典,在影像融合中对高、低空间分辨率影像分别计算稀疏系数,通过算法生成融合影像的融合稀疏系数,进而结合稀疏字典完成影像稀疏融合[1]。基于稀疏思想的融合中,稀疏字典与融合稀疏系数的生成是2个研究重点。
稀疏字典从用途来看,可分成待融合影像的稀疏字典与融合结果影像的稀疏字典。待融合影像是指用于融合的高、低空间分辨率影像,该类字典的来源有2种:①将标准正交基级联得到超完备字典,通常包括傅里叶变换、小波变换、离散余弦变换、Gabor滤波、曲线波以及轮廓波等,例如将同一空间位置对应的同方向跨尺度小波基函数的线性组合作为新的基函数[2];②通过待融合影像的样本学习来构造过完备字典,参与字典学习的样本类型包括随机选择样本[3]、基于影像分割或分类所产生的区域影像建立样本[4]、基于随机共振和自适应的稀疏域选择样本[5]及选择纯像元建立字典学习样本[6]等。融合结果影像的字典除了各种标准正交基函数外,还包括以下3类:①采用多光谱影像字典,例如在MODIS与ETM+影像融合中,由MODIS影像提供融合影像的字典[6];②采用高空间分辨率影像字典,例如SPOT与TM影像融合中,融合字典由SPOT影像字典提供[7];③基于多光谱字典与高空间分辨率影像字典利用规则生成融合字典,该种融合字典生成的方法包括正则项建立优化函数求融合字典[8-10]、对各种聚类子字典采用主成分分析(principal component analysis,PCA)方法构造融合字典[11]、利用融合字典与高空间分辨率影像字典存在的权重关系及融合字典与多光谱字典存在的模糊滤波关系构建融合字典[8]以及随机选择高空间分辨率影像与多光谱影像样本建立联合字典[3]。
目前字典的生成多数直接来源于影像样本,但由于遥感影像的空间分辨率限制,在地物复杂地区大多数影像存在着混合像元问题,这使得字典的精度受到一定影响。2014年Huang等[6]利用MODIS影像中的纯像元建立字典,但是MODIS影像中各种地类的纯像元个数较少,影响了字典的应用效果。为了减少混合像元对字典建立的影响,本研究在像元线性分解影像中利用在线字典学习法建立字典,通过提取分解影像字典与全色影像字典的主成分分量建立PCA联合稀疏字典,融合影像的稀疏系数采用非负矩阵分解(nonnegative matrix factor,NMF)融合多光谱影像与全色影像的稀疏系数生成。
1 基本理论
1.1 稀疏分解
利用尽量少的原子影像块与非零值稀疏系数来完全或近似地表达原始影像的方式,就是影像稀疏表达。该种表达方式将影像投影到由稀疏字典组成的特征空间,影像的信息集中在较少的原子影像块中,非零值稀疏系数表明了影像的内部结构及特征[12]。基于高度非线性逼近理论的稀疏表达公式中包含2个系数:一是根据信号的特点构造的原子库即过完备字典D; 二是从字典中找到最佳线性组合所用到的稀疏系数α[13-14]。
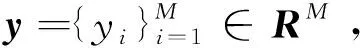
y=D·α
(1)
由于实际处理的信号通常带有噪声,影像稀疏分解过程实际上是一种逼近过程,即
(2)
式中:yM为原始信号y的逼近信号;xr为残差分量;dN为给定稀疏字典D∈RM×N中的一个原子;〈RNxrdN〉为信号在dN上的投影,构成信号在稀疏字典D上的稀疏系数α;RMx对应残差分量xr。
为了求解最优α,且满足残差分量xr达到最小,将式(2)转换为
(3)
式中:‖α‖0为α的l0范数;αN为给定稀疏字典中的一个稀疏系数;ΩΜ为稀疏字典大小;ε为误差总和。式(3)表明在最小均方误差约束条件下,求解稀疏系数的最少个数。由于l0范数的非凸性,为了求解这个NP-hard问题,学者通常用l1范数近似代替l0范数。
1.2 NMF融合
利用NMF算法将原始影像V分解成基向量W和权重系数矩阵H,当W的秩r与数据集的特征空间维数一致时,那么得到的W是对V最有效的体现,既反映了影像V中最基本的特征,同时有效抑制了影像的噪声。利用NMF的这种特性,可以完成NMF的影像融合。将待融合的影像按行优先的方式存储成V,即
(4)
式中:Ii为待融合的影像,i=1,2,…,m;M和N分别为每一幅待融合影像的行数和列数,并令n=M×N,则有V∈Rn×m。V可近似分解为非负矩阵Wn×r与非负矩阵Hr×m的乘积[15]。本文的稀疏系数融合是采用逐个多光谱波段与全色波段进行融合,所以选取r=1,即W的维数为MN×1。融合时采用标准梯度下降法迭代规则求解W和H,由于V=W×H+δ,在每次迭代后计算误差δ,若δ小于设定的值,则迭代终止。
2 融合算法
本文融合算法的流程如图1所示。
本研究改进了稀疏字典的生成方法,提出了利用不同地物的线性分解影像作为字典的来源影像。进行线性光谱分解时,所用到的纯像元来源于纯像元指数(pure pixel index,PPI)计算,再利用N维可视化器从PPI指数计算的像元中提取出感兴趣区域(region of interest,ROI)纯像元,作为线性光谱分解的端元。利用在线字典学习算法分别对各类地物分解影像进行处理,得到各类地物分解影像的稀疏字典,将每一幅分解影像稀疏字典与全色稀疏字典分别进行PCA处理并提取第一主成分分量作为PCA稀疏字典,并将8个PCA稀疏字典生成PCA联合稀疏字典。利用PCA联合稀疏字典与正交匹配追踪(orthogonal matching pursuit,OMP)算法计算多光谱影像与全色影像的稀疏系数,将每一幅多光谱影像的稀疏系数与全色影像的稀疏系数进行NMF融合,得到该波段融合影像的稀疏系数,融合影像的稀疏系数与PCA联合字典重构生成融合影像。
3 实验与分析
采用2012年8月8日福建赛场的WorldView-2影像数据作为实验数据。该数据拥有1个0.5 m空间分辨率的全色波段和8个2 m空间分辨率的多光谱波段,具体包括:海岸波段B1、红光波段B2、蓝光波段B3、红边波段B4、绿光波段B5、近红外1波段B6、黄光波段B7和近红外2波段B8。数据已完成辐射校正与几何纠正,可以进行影像融合处理,实验影像的大小为512像元×512像元。
在本研究中,稀疏字典的生成是基于地物分解影像。在利用PPI指数计算时,对所设定的参数进行调整,最终确定迭代次数为10 000次,阈值参数设为12,得到3 016个像元。PPI指数计算的结果给出了像元作为纯像元的潜在性,但并没有对纯像元的类别做出判断,这时就需要利用N维可视化器提取各类别的纯像元。通过观看各角度旋转,找出各方向散点图的尖角,选出作为各种类别的纯像元。本研究最终确定8种类别地物:水体、裸土、农田、农作物、林地、不可渗透表面、白色屋顶建筑和蓝色屋顶建筑。将8类地物的纯像元样本作为线性分解的端元输入,得到8种地物的像元分解影像。
3.1 确定稀疏字典矩阵大小
进行稀疏字典计算时,先要确定稀疏字典的大小。本研究利用多光谱影像的稀疏分解与重构来探讨适合的稀疏字典矩阵大小。利用在线字典学习算法分别对8类地物的分解影像进行处理,得到8幅影像的稀疏字典,并将其联合起来,组成联合稀疏字典。一个字典原子的大小为8像元×8像元,在考虑计算机运行能力与影像稀疏分解及重构精度问题的基础上,探讨合适的稀疏字典矩阵大小。设定各幅多光谱影像的字典个数分别为10,20,30,40,50和60,则对应的联合字典的个数分别为80,160,240,320,400和480,利用该联合字典与OMP算法分别计算各多光谱波段的稀疏系数,利用稀疏系数与联合字典重构各多光谱波段,探讨影像重构均方根误差(root mean square error,RMSE)与字典个数的关系,从而确定本研究的字典个数。
表1给出6种联合稀疏字典的参数及8个波段重构的平均RMSE,可以看出重构影像平均RMSE从80个字典的0.099下降到480个字典的0.054。说明字典个数对重构影像有着相关性影响,这从图2中所表达的8个波段的重构RMSE中也得到反映。综合考虑运算效率与影像的重构精度,本文选择的联合字典大小为480,即每个分解影像提供60个字典用于建立联合字典。
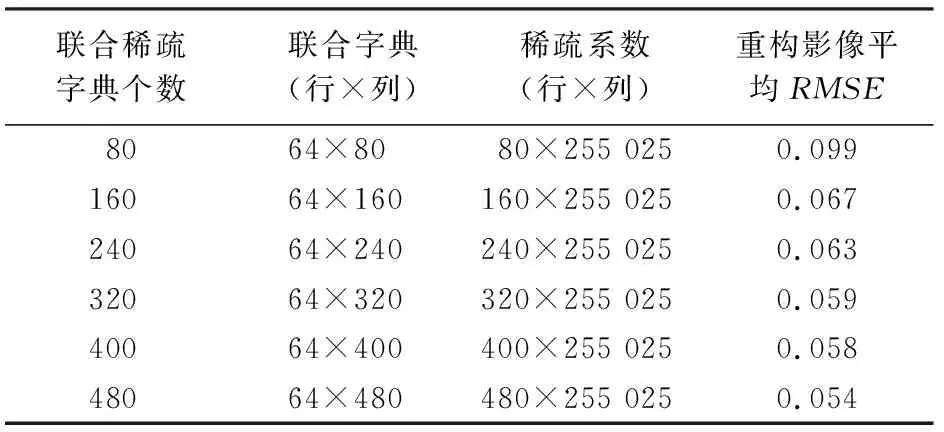
表1 字典参数与重构RMSE
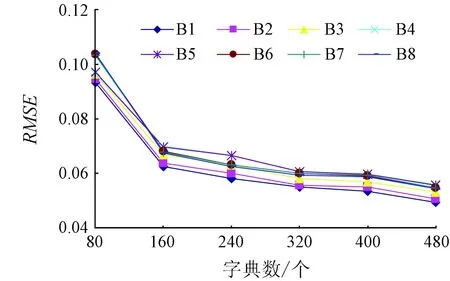
图2 各波段稀疏重构RMSE
3.2 PCA联合稀疏字典
利用在线字典学习法生成8个分解影像的字典与全色影像字典。利用PCA算法计算各分解影像稀疏字典与全色稀疏字典,取第一主成分分量作为PCA联合稀疏字典。图3分别为直接利用8个分解影像的字典组成的联合字典以及依次对8个分解影像进行处理后得到的PCA联合稀疏字典。

(a) 联合字典
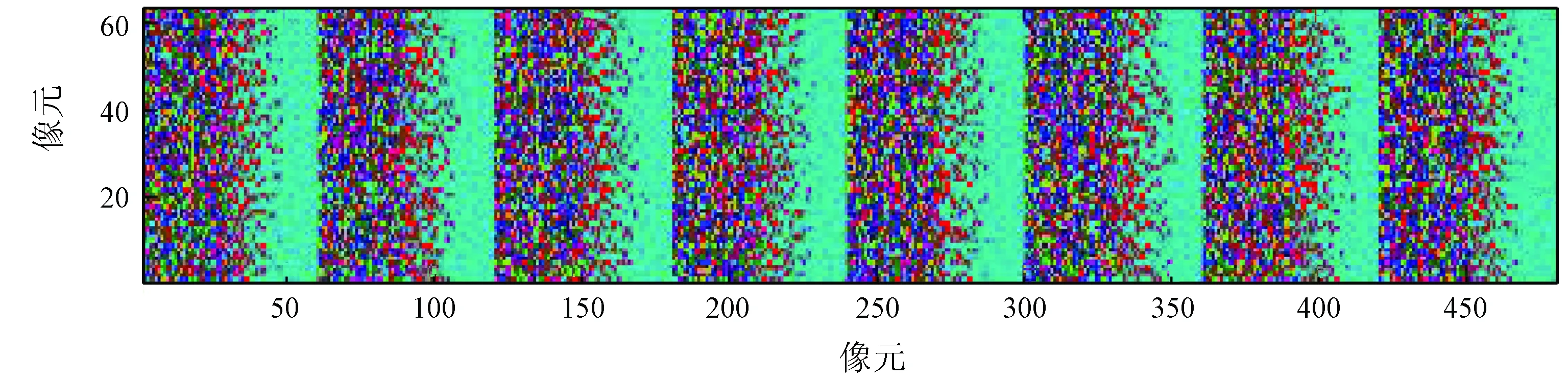
(b) PCA联合稀疏字典
影像的方差可以反映影像的信息量,比较PCA联合稀疏字典与联合字典的方差(表2)可知,经过PCA处理得到的各影像字典及影像联合字典的方差值均大于未经PCA处理的字典,说明经过PCA处理的字典融合进了全色影像字典的主要信息,从而保证PCA联合稀疏字典能代表影像中主要特征。
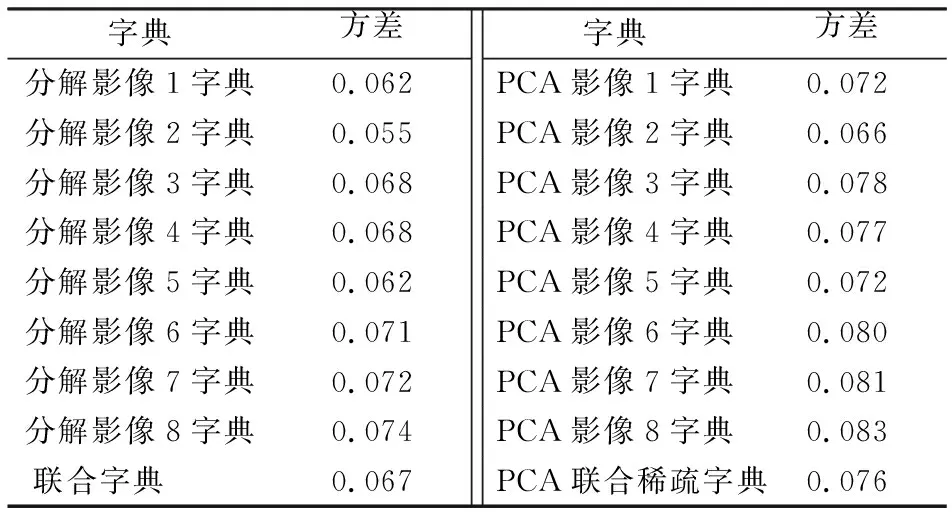
表2 联合字典与PCA联合稀疏字典的方差比较
3.3 融合影像评价
利用PCA联合稀疏字典完成多光谱波段(图4(a))与全色波段(图4(b))的OMP计算,分别得到各个多光谱波段与全色波段的稀疏系数α。利用NMF融合算法计算每个多光谱波段与全色波段的融合系数α,即各个波段融合影像的系数α,将该数值乘以PCA联合稀疏字典,得到各个融合波段,如图4(c)。在完成本文提出的融合算法后,利用联合字典进行多光谱与全色稀疏分解,将得到的系数α利用NMF算法进行融合,得到联合字典的NMF融合影像,如图4(d);同时为了对比分析本文方法与传统方法的融合效果,分别完成小波融合与经典的PCA影像融合,如图4(e)与图4(f)。从目视效果上看,本文提出的融合算法与图4(a)多光谱影像色调较一致,保证了多光谱信息。融合影像的纹理层次丰富与图4(b)全色影像清晰度接近,信息量增加,同时具有多光谱与高空间分辨率影像的特征。对比其他3种融合算法,本文方法所融合的地物光谱表现与实际情况接近,田地、水体和居民区更清晰可辨,更有力地表现了细节。

(a) 多光谱影像 (b) 全色影像 (c) PCA联合稀疏字典NMF融合影像

(d) 联合字典NMF融合影像 (e) 小波融合影像 (f) PCA融合影像
通过计算4幅融合影像的5种定量评价指标来比较本文方法与其他经典方法的融合效果,具体如表3所示。

表3 融合评价指标
信息熵可以评价影像中信息量的多少,值越高,表示影像的信息越多。可以看出PCA联合稀疏字典的NMF融合影像具有更多的信息,信息熵值在4种方法中最高。清晰度与空间频率是通过相邻像元的差别来反映影像的空间变化频率,表现为细节的反映能力。相较于联合字典NMF融合、小波融合与PCA融合,本文方法的这2个参数指标明显更高,说明本文方法提高了融合影像的纹理细节信息,更加清晰地反映了地物的特征。扭曲程度与偏差指数反映融合影像与多光谱影像的差别程度,值越大说明与原始多光谱影像的差异越大。本文方法的这2个指标均小于其他3种融合方法,说明本文方法较好地保持了影像的光谱信息。
4 结论
1)本研究提出分解地物影像字典与全色影像字典的第一主成分分量构成PCA联合稀疏字典。所生成的PCA联合稀疏字典既能包含多光谱影像分解地物特征,也包含高空间分辨率影像特征。
2)利用重构影像与原始影像的RMSE探讨合适的字典个数。随着字典个数的增加,重构影像的误差有明显减小的趋势。考虑到重构影像的效率与计算机运算的限制,最终确定稀疏字典个数为480。
3)利用NMF融合确定融合影像的稀疏系数。该稀疏系数最大限度地保留2幅原始影像的信息。采用5种定量评价指标分析,本文提出的融合算法包含更多的信息,提高了融合影像的纹理细节,并较好地保持了原始影像的多光谱特征。
猜你喜欢
航天返回与遥感(2022年2期)2022-05-12
家庭影院技术(2021年7期)2021-08-14
家庭影院技术(2020年8期)2020-09-11
收藏界(2019年4期)2019-10-14
小学阅读指南·低年级版(2019年11期)2019-07-01
电子制作(2018年2期)2018-04-18
小天使·一年级语数英综合(2017年11期)2017-12-05
制导与引信(2017年3期)2017-11-02
电子制作(2017年8期)2017-06-05
读者(2016年14期)2016-06-29
