
基于改进互信息的微博新情感词提取
2019-02-11 10:44柳文婷
延边大学学报(自然科学版) 2019年4期
柳文婷
( 安徽理工大学 计算机科学与工程学院, 安徽 淮南 232001 )
0 引言
微博新情感词的提取一般分为新词提取和新词情感识别[1].目前,新词提取方法主要分为基于规则的方法和基于统计的方法.基于规则的方法提取新词[2]主要是根据构词学原理或词性信息来匹配新词,但由于该方法需要人工标注信息,所以需要耗费大量的人力物力.基于统计的方法提取新词[3]是使用统计学方法来建造模型并判断字串是否为新词,该方法适用于大规模的语料库.也有学者将上述两种方法结合起来提取新词,这种方法虽然效果较为稳定,但在实际应用中很难获得高质量的标记语料[4].
近年来,在微博情感倾向的相关研究中,大多数学者都是通过对微博中的词汇和句子进行情感判断来分析微博的情感倾向[5-7],而对微博新情感词的相关研究较少.对微博的情感分析目前可分为基于词典的方法、基于机器学习的方法和基于词典与机器学习相结合的方法.基于词典的方法[8]主要是通过构造情感词典和制定一系列的规则来计算新词的情感值,该方法虽然判断新词情感的准确率较高,但召回率偏低,且构建不同领域情感词典的成本较高.基于机器学习的方法[9]是将文本的情感分析作为分类问题进行分析,分类算法主要有深度学习的方法和支持向量的方法.前者计算量大,但准确率较高;后者准确率相对较高,但不适用于大规模数据.基于词典与机器学习相结合的方法[10]是将词典融合到机器学习的模型中进行文本情感分析,该方法虽然可提高机器学习性能,但却需要人工收集情感词,因此使得情感词库的覆盖面较低.基于上述研究,本文结合新词构词特点,提出一种基于互信息和构造情感词库的微博新情感词提取方法,并通过实验验证该方法的可行性.
1 微博新情感词提取流程
微博作为一种服务类的社交网站,它具有公开性、及时性以及多样性.绝大多数用户都能随时随地以文字、图片或视频来表达自己的所思所想,但由于微博用户的教育背景、生活习惯、语言表达等的不同,因此使得微博数据较为混乱,其中最常见的问题有: ①重复性.微博上内容重复的网页较多,且其真实性有待确认.②随意性.微博用词(包括文本、图片等)缺少规范,随意性很大.③领域广.微博文本涉及的领域广,仅使用某一领域的提取方法会极大地影响新词的提取准确率.④人造词多.用户使用的一些新词或是来自某地方言或是自创,不存在于字典中,因此难以判断其情感倾向.为解决以上问题,并达到快速、准确地提取新情感词,本文提出一种基于多字互信息和词间情感相似度的微博新情感词提取方法.该方法主要分为两个阶段:新词提取和新词情感倾向分析.
1)新词提取阶段.该阶段的主要工作是对预处理的数据进行N元切分,以此得到候选字串;然后再根据多字互信息和左右侧邻接熵计算候选字串的内部统计量和外部统计量的值,以此得到候选新词集;最后将得到的候选新词集与词典进行对比,删除词典中已有的词后即得到新词集.
2)新词情感倾向分析阶段.该阶段主要是根据新词之间的情感倾向影响来改进情感倾向点互信息公式,以此得到词间情感相似度的计算公式; 根据该公式计算新词的情感倾向值,并依据该值判断新词的情感倾向,删除中性新词后剩下的即为新情感词.
新情感词的提取过程如图1所示.
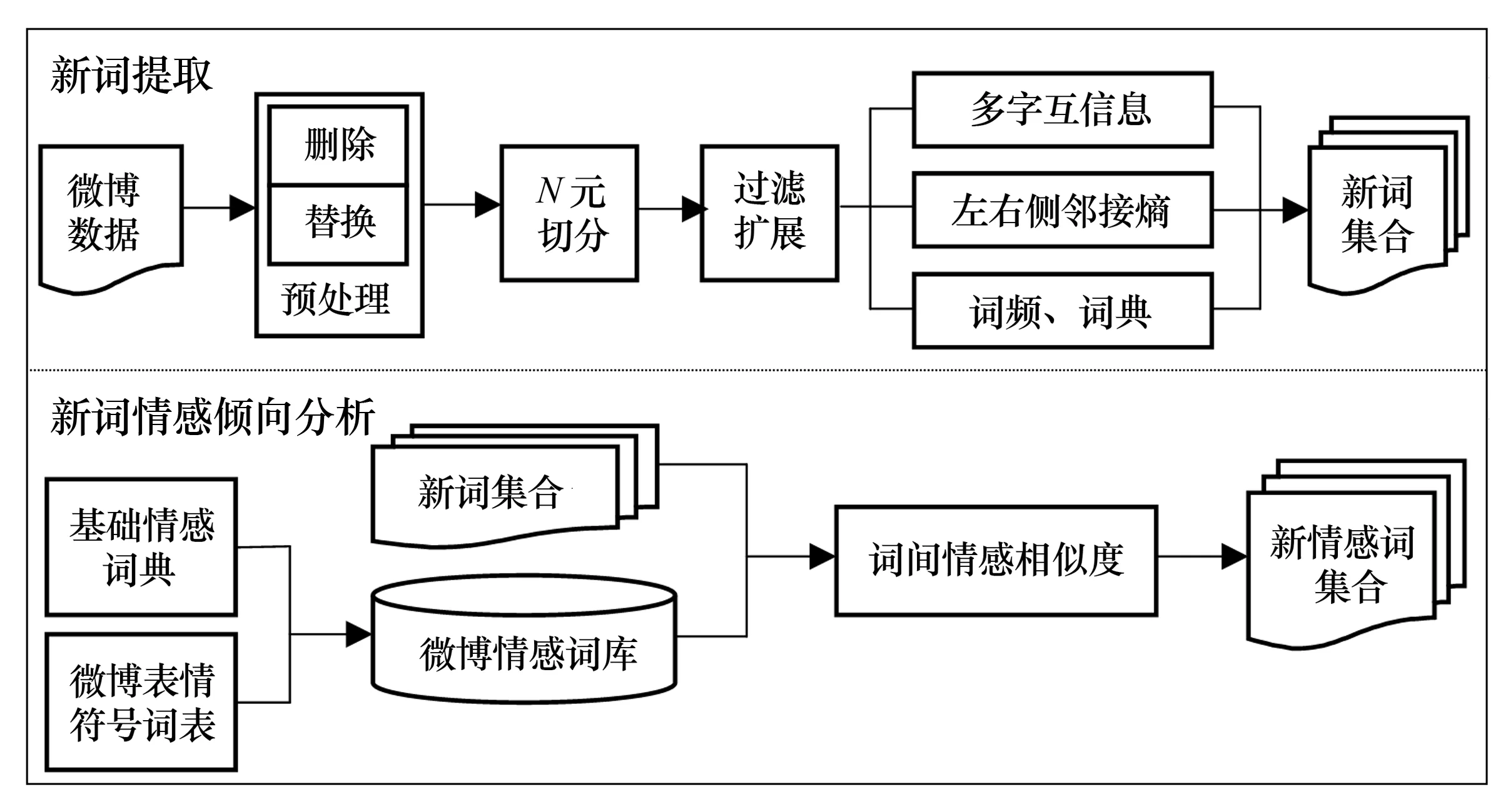
图1 微博新情感词的提取过程
2 微博新词的提取
2.1 微博数据的预处理
由于微博具有用户背景不同、包含领域广、文本书写不规范、字数有限等特点,因此通过爬取方法所获得的微博数据中存在大量的噪声.为此,本文对微博数据进行预处理,预处理后文本的处理时间和数据的存储空间可得到有效提高.预处理的主要方法是删除和替换.
1)删除.删除微博数据中的链接、重复的标点符号以及“#***#”、“@+用户名”等微博程序自带的固定字串.
2)替换.用ICTCLAS词法分析系统切分微博文本中的词句,将切分后得到的标点符号和停用词用空格代替,并将繁体字换成简体字.
2.2 微博新词的提取方法
1)N元切分方法.一般的分词系统都是根据已有的字典对句子进行切分,这种切分方法可能会造成错误切分或遗漏新词.例如“王经/理/了/理/袖口”,分词系统有可能会将这个句子划分成“王/经理/了/理/袖口”,遗漏掉“王经”这个新词.所以,本文采用N元切分方法来切分文本.N元切分方法的基本思想是对文本进行逐一扫描、N字切分,切分后的每N个单字构成一个字串.因目前二元和三元切分技术较为成熟,且新词一般由2~4个字组成[11],所以本文中的N取2和3.
2)多字互信息.互信息是表示两个字之间的依赖程度,传统的互信息的表达式为
(1)
其中:P(xy)表示x和y在语料库中共同出现的频次与语料库中总词数的比;P(x)和P(y)分别表示x和y单独出现在语料库中的频次与语料库中总词数的比.
由公式(1)可以看出,传统的互信息只考虑了候选词被划分成两部分的构成模式,即该方法只可对2字词进行划分,而无法对多字词进行划分.因此,本文对传统互信息进行改进,即考虑多字候选词(字数超过2的候选词)的构成模式.3字词的所有构成模式如图2所示.根据图2可类推4字词的构成模式(7种),且所有构成模式包含的元素为9种.
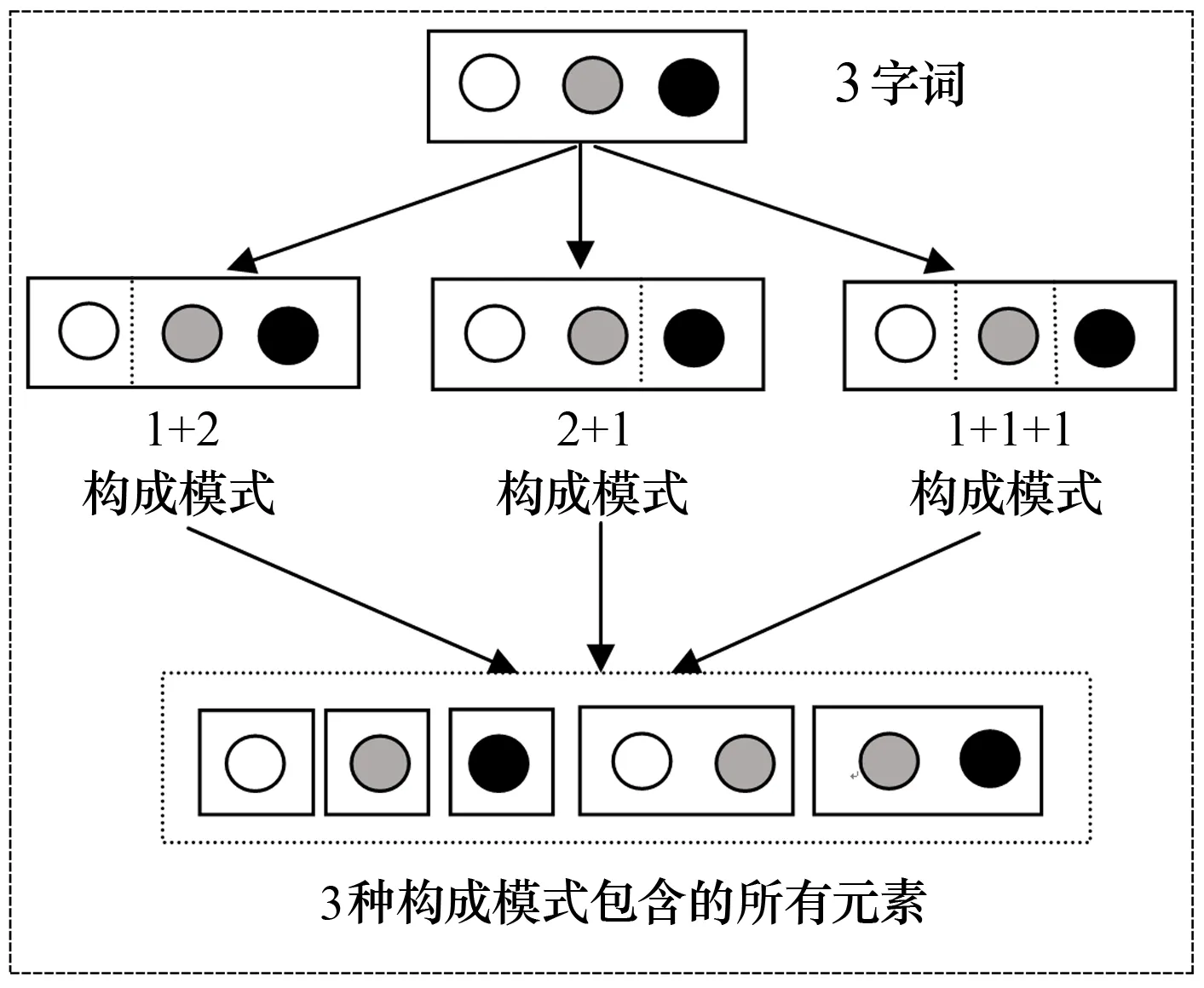
图2 3字词的构成模式
为了扩大新词识别的范围和提高新词识别的准确率,本文对多字互信息进行如下定义:
定义1多字互信息(multiword mutual information,MMI)是在多种构成模式下衡量多字词的内部凝聚度,其计算公式为
(2)
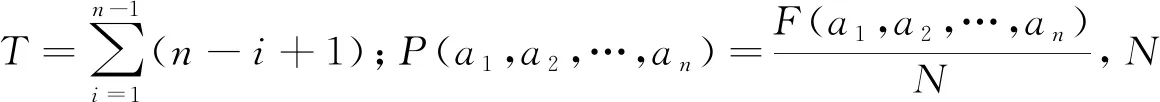
3)左右侧邻接熵.左右侧邻接熵能够反映字符串邻接元素的不确定性,熵值越大邻接元素的不确定性越大,即该字符串成为词的可能性也越大.左侧邻接熵和右侧邻接熵的计算公式[12]分别为:
(3)
(4)
其中: |Vl|和|Vr|分别为左右侧邻接字种类的数量;n和m分别为左右侧邻接字的总个数;ni和mj分别为左右侧某一种邻接字的个数.
2.3 微博新词的提取算法
本文提出的微博新词提取算法(算法1)如下:
输入:微博文本集合T, 字频阈值θ1, 多字互信息阈值θ2, 左右侧邻接熵阈值θ3和θ4, 词典D
输出:微博新词集合E
step 1 对微博文本集合T进行预处理.
step 2 对step 1中得到的内容进行N元切分得到二元字串和三元字串,并统计每个字串的频率,删除频率小于θ1的字串后得到候选字串.
step 3 计算step 2中候选字串的多字互信息MMI(a1,a2,…,an), 删除多字互信息小于θ2的字串.
step 4 计算step 3中剩余候选字串中二元字串的左右侧邻接熵{El,Er}.若El≥θ3,且Er≥θ4, 则将该字串添加到新词集合E中.
step 5 计算step 3中剩余候选字串中三元字串的左侧邻接熵El.若El≥θ3, 字串的左边界确定,执行step 6;否则,字串向左扩展一个字后,执行step 6.
step 6 计算step 5中得到的字串的左侧邻接熵{El,Er}.若El≥θ3,且Er≥θ4, 则将该字串添加到新词集合E中.
step 7 对比新词集合E和词典D,删除共有的词后即得到最终的新词集合.
从上述的算法中可以看出:算法首先对微博文本进行扫描,以此判断并建立候选字串集,此时的时间复杂度为O(n),n为候选字串的个数.然后再对候选字串集进行多字互信息过滤,此时的时间复杂度为O(n).候选字串为二元字串的有k个,三元字串的有(n-k)个.通常情况下,三元字串运用左右侧邻接熵进行扩展的次数极少超过2次,因此扩展的时间复杂度可记为O(n).
3 新词情感倾向分析
3.1 构建微博基础情感词库
在微博中,表情符号和情感词都是用户情感的直接表达,因此本文使用基于词典的方法分析新词情感倾向.本文将知网情感词典与台湾大学简体中文情感极性词典合并、去重后的情感词集作为基础情感词典,然后选取倾向性明显的(出现频次在前36个)的褒贬义表情符号作为微博表情符号词表,如表1所示.最后将基础情感词典与微博表情符号词表去重、合并得到微博基础情感词库.

表1 微博褒贬义表情符号
3.2 新词情感倾向识别
一般情况下,微博中出现的新词是用户情绪的一种宣泄或表达,而情感词是用户情感的直接体现.因用户发表的微博内容中出现的新词和情感词的情感倾向大多是类似的,所以可以从用户使用的情感鲜明的情感词来分析新词的情感倾向.由于传统的情感倾向点互信息只考虑了微博情感词库中已经存在的情感词,未考虑新词的情感对与其共同出现的其他新词情感的影响,因此需对传统的情感倾向点互信息进行改进.本文通过分析新词之间的情感倾向影响,对情感倾向点互信息进行改进,即通过分析词间相似度来分析新词之间的情感倾向影响.词间情感相似度的相关定义和公式如下:
定义2词间情感相似度(sentiment similarity between the words,SW)是衡量同一个文本中某个新词和情感词对同一条微博中的其他新词的情感倾向的影响程度,其计算公式为:
SWj=α(PA_PMIj-NA_PMIj).
(5)
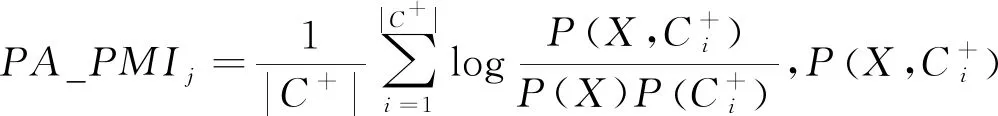
由以上可知,由算法1得到的微博新词只有经过词间情感相似度的判断才能确定某个新词是否是具有情感的新词.微博新情感词提取算法(算法2)如下:
输入:微博新词集合E, 微博基础情感词库C, 词间情感相似度阈值θ5和θ6
输出:微博新情感词集合S
step 1 结合微博基础情感词库,计算新词集合中每个词的词间情感相似度SW;
step 2 如果SW<θ5或SW>θ6, 则判定该词为微博新情感词.
从算法2中可看出,只需对微博新词集合进行1次扫描即可完成所有新词的情感倾向分析,其时间复杂度为O(m), 新词个数为m.
4 实验
4.1 实验数据
1)新情感词提取.爬取2018年11月—2019年3月3个不同热门话题(“军训式应援”“杨超越登上《人物》杂志”“翟天临学术造假”)的40 000条微博,用于微博新情感词提取.
2)停用词库.对哈工大停用词词库、四川大学机器学习智能实验室停用词库、百度停用词表进行整理、去重后得到本文的停用词库共计1 598个停用词,(不包括英文词和中文标点符号),用于微博数据预处理阶段.
3)词典.将知网文本词库与同义词词林相结合后得到的词语集合即为本文中使用的词典,用于候选新词筛选.
4)微博基础情感词库.将知网情感词典、台湾大学简体中文情感极性词典以及本文列出的微博褒贬义表情符号(表1)进行合并、去重,所得的情感词集即为本文的基础情感词典,用于新词情感倾向识别阶段.
4.2 实验评估指标
采用准确率P(precision)、召回率R(recall)、综合指标F(F-score)来评价算法的准确性,各指标的计算公式为:
P=TP/(TP+FP)×100%,
(6)
R=TP/(TP+FN)×100%,
(7)
F=2PR/(P+R)×100%.
(8)
其中:TP表示将待测的词语预测为新(情感)词,实际也为新(情感)词的数量;FP表示将待测的词语预测为新(情感)词,实际为非新(情感)词的数量;FN表示将待测的词语预测为非新(情感)词,实际为新(情感)词的数量.
4.3 实验分析
为了验证本文算法的有效性,进行两方面实验:一是微博新词提取算法(算法1)的有效性验证,二是微博新情感词提取算法(算法2)的有效性验证.由于各个话题讨论的内容不同,所以本文将他们分开讨论.话题1(“军训式应援”)是针对国内某个明星而提出的,由于该明星形象良好,因此微博中出现的都是情感偏正向的词.话题2(“杨超越登上《人物》杂志”) 是刚出道的明星(杨超越)登上《人物》杂志而出现的各种不同评价.话题3(“翟天临学术造假”)由于是因翟天临学术造假而引起的话题,所以该话题中的词大部分都是情感负向的词.算法1在3个话题中得到的部分高频新情感词如表2所示.

表2 高频新词识别结果示例
表3为本文算法1、传统的N元方法和文献[3]算法的新词提取结果.由表3可知,本文算法1比传统的N元方法的准确率、召回率和F1值分别提高了25.86%、31.52%和30.60%,比文献[3]算法的准确率、召回率和F1值分别提高了10.16%、11.47%和11.03%.算法1的提取效果优于传统的N元方法和文献[3]算法的主要原因是:传统的N元方法对多字词的识别率较低,而且也未考虑新词内部统计量和外部统计量对新词识别的影响;文献[3]的算法过度依赖于分词系统,使一些词被错分.
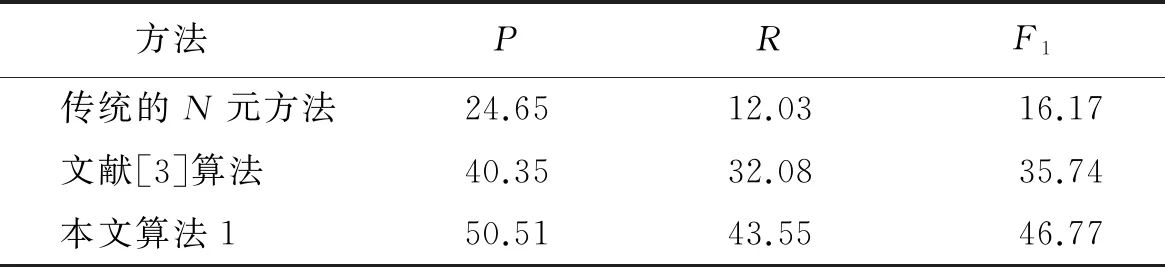
表3 不同方法的新词提取结果 %
表4是通过本文算法2得到的微博新情感词示例,表5是算法2和文献[4]算法的新情感词提取结果.从表5可以看出,算法2比文献[4]算法的准确率、召回率和F1值分别提高了13.14%、5.81%和8.59%.其主要原因是文献[4]的算法只考虑了内部统计量和外部统计量对新情感词提取的影响,并没有考虑新词的语义信息,进而导致提取结果中有很多新词不是情感词;而算法2在统计量的基础上加入了词在情感词典中的语义信息,进而使得新情感词的提取准确率有所提高.

表4 微博新情感词示例

表5 2种算法的新情感词提取结果 %
5 结论
本文基于新词构词模式多样的特点,提出了一种基于多字互信息和词间情感相似度的微博新情感词提取方法.实验结果表明,本文方法的微博新词提取的准确率(50.51%)、召回率(43.55%)和F1值(46.77%)均优于传统的N元方法和文献[3]的方法,新词情感倾向识别的准确率、召回率和F1值比文献[4]方法分别提高了13.14%、5.81%和8.59%,因此本文算法具有很好的应用价值.在今后的研究中,我们将通过完善微博情感词库以及使用融合机器学习的方法来进一步提高新词情感倾向识别的准确率和召回率.
猜你喜欢
中学生天地(B版)(2022年4期)2022-05-17
动漫界·幼教365(大班)(2020年7期)2020-06-26
现代计算机(2019年30期)2019-12-11
音乐天地(音乐创作版)(2019年12期)2019-02-09
周末·校园文学(2017年35期)2018-02-06
计算机应用(2016年10期)2017-05-12
电脑爱好者(2017年5期)2017-05-04
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
弹箭与制导学报(2015年1期)2015-03-11
