
开源云上的Kubernetes弹性调度
2019-02-25 13:21张可颖彭丽苹吕晓丹吕尚青
计算机技术与发展 2019年2期
张可颖,彭丽苹,吕晓丹,吕尚青
(1.贵州大学 大数据与信息工程学院,贵州 贵阳 550025;2.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;3.北京邮电大学 信息与通信工程学院,北京 100000)
0 引 言
云平台通过虚拟化技术将计算机资源整合成资源池,以按需付费的方式实现了用户对计算资源的弹性需求[1]。云计算发展至今,虚拟化技术一直是云平台中的关键技术[2]。Openstack是完全开源的云操作系统,在近几年已经占有私有云市场,是基于传统虚拟化技术的私有云。传统虚拟化技术启动虚拟机时间过长,在弹性扩容方面存在不足。
容器技术是一种新兴的虚拟化技术[2],它的出现给传统虚拟机虚拟化技术带来了挑战,为构建高效的云平台提供了新思路[3-6]。容器与Openstack云平台的结合受到国内外企业的普遍关注[7],如华为、Easystack、Redhat、Vmware等。Kubernetes是容器编排技术的代表,市场占有率越来越多,数据显示2017年77%企业使用Kubernetes作为容器编排[8]。容器技术的高可扩展性得到了行业内的普遍认可[4-7],根据IBM测试报告显示容器启动时间平均是虚拟机的1/21[8],这给Openstack高效弹性调度提供了新思路。IBM的研究人员比较了虚拟机与Docker容器的性能。他们使用一系列工具模拟CPU,内存,存储和网络资源的工作负载进行测试,结果表明几乎在所有情况下,容器的性能都等于或优于虚拟机。
Kubernetes是Google的Borg开源版本,一个通用的容器调度编排器,是典型的Master-Slave模型,使用一个Master管理多个Node(物理机或者虚拟机)上的容器。通常应用程序被分在一个或者多个容器中执行。Kubernetes Scheduler是运行在Master节点上的调度器,通过监听Apiserver将Pod调度到合适的Node上。调度过程简述如下:
第一步:Predicate,过滤掉不满足资源条件的节点。
第二步:Priority,计算各个节点的CPU和内存使用率权重(目前Kubernetes最多支持CPU、内存和GPU)。使用率越低,权重越高。计算镜像权重,镜像越大,权重越高,倾向于调度到已经有需要用到的镜像的节点。由此来对各个节点打分,以确定它们的优先级顺序,选择打分最高的节点作为Pod运行的Node。
由此可见,Kubernetes调度算法存在很大的局限性。第一,Kubernetes提供了一个只考虑CPU和内存的动态资源配置机制[9]。这是不现实的,因为影响应用程序性能的因素有很多,如网络、I/O和存储。第二,Kubernetes的权重打分机制倾向于将Workload平均分布在各个节点,一方面在资源高效利用方面存在不足,除了应用高峰期,其他时间整个集群都处于低负载状态,同时也增加了数据中心的能耗;另一方面,资源均分一定程度造成资源碎片化,降低了集群资源利用率,也可能造成新进大资源无法部署,永远处于Pending状态[10]。另外,Kubernetes社区尚不成熟,本身在存储、网络和多租户管理方面不完善[6],因而与Openstack结合是对其良好的补充。
针对上述问题,首先将Openstack虚拟机容器化,作为Kubernetes集群中的Docker容器,以获得容器的弹性扩展,高效在线迁移的特性。用Kubernetes自带的挂在卷Volume集群作为后端跨主机的块存储,一定程度保证冷数据的安全性。然后建立一个基于Openstack的Kubernetes集群资源调度优化模型,在综合考虑资源负载和应用服务性能的前提下,对集群资源进行了细粒度划分,实现了Openstack集群的容器化的虚拟机的调度和应用容器的在线迁移。
1 相关工作
对Openstack和Kubernetes结合进行数据中心弹性调度的研究目前较少。但在相关领域,学者和企业进行了大量研究。
Chia Chen等[9]提出了一种基于资源利用率和应用QoS度量指标的Kubernetes资源调配算法,在原本Kubernetes考虑CPU的基础上,又加入了系统其他的资源利用率(如内存和磁盘访问)和QoS指标(如响应时间),在一定程度上完善了Kubernetes的调度机制。唐瑞[11]改进了一种抢占式的Pod调度策略,通过将Pod划分为三个优先级,在资源不足时有效提高了高优先级Pod的运行比例。杨鹏飞[12]提出一种基于训练融合ARIMA模型和神经网络模型的动态资源调度算法,有效提高了Kubernetes调度资源利用率和应用服务质量。彭丽萍等[13]在Ceph集群研究中指出集群除了在应用高峰期外,集群中大多数点都处于低负载状态,这就造成资源浪费并增加了系统能耗,并基于Docker和Ceph加权平均的调度策略,在保证数据安全性的前提下,提出一种尽量使少量节点处于高负载,休眠低负载节点的数据中心节能的弹性调度算法[10]。
在企业界,相关的云平台调度策略有Borg、Yarn、Meros等等。Borg把应用程序分成两类—批处理作业和长服务。批处理作业是类似于MapReduce和Spark的作业,在一定时间内会运行结束,长服务则类似于Web Service、HDFS Service等,可能会永久运行下去,永不停止[14]。Borg对长服务的支持细节未知,因为是闭源的,但是Meros和Yarn对长服务存在以下问题:由于Yarn和Meros和Kubernetes具有相似的打分机制,倾向于将Workload平均分配在集群,会造成长服务永远占着资源,预留资源可能永远不足于分配给新服务的情况。
长服务运行一段时间以后,可能需要的资源会有动态变化。资源伸缩有两个维度:一个是横向的,即增加实例数目;另一方面是纵向的,即原地增加正在运行实例的资源量[15]。
以上的弹性调度策略完善了云平台资源监控的度量,优化了数据中心资源调度算法,在一定程度上提高了数据中心资源利用率。但并没有细分考虑服务类型,仅仅考虑初始资源分配,没有考虑服务运行的时间对集群资源调度的影响,以及应用长时间运行而导致资源碎片化问题。因此,针对长服务,实现了Openstack使用Kubernetes弹性调度容器化的虚拟机云平台调度的弹性策略。
2 私有云调度模型的建立与求解
模型假设:假设已知各类应用CPU、内存、网络和I/O的最低需求;假设容器迁移时存储可靠且启动时间和初次容器拉起时间一样,运行一段时间后不造成额外重启开销。
2.1 Kubernetes集群系统建模
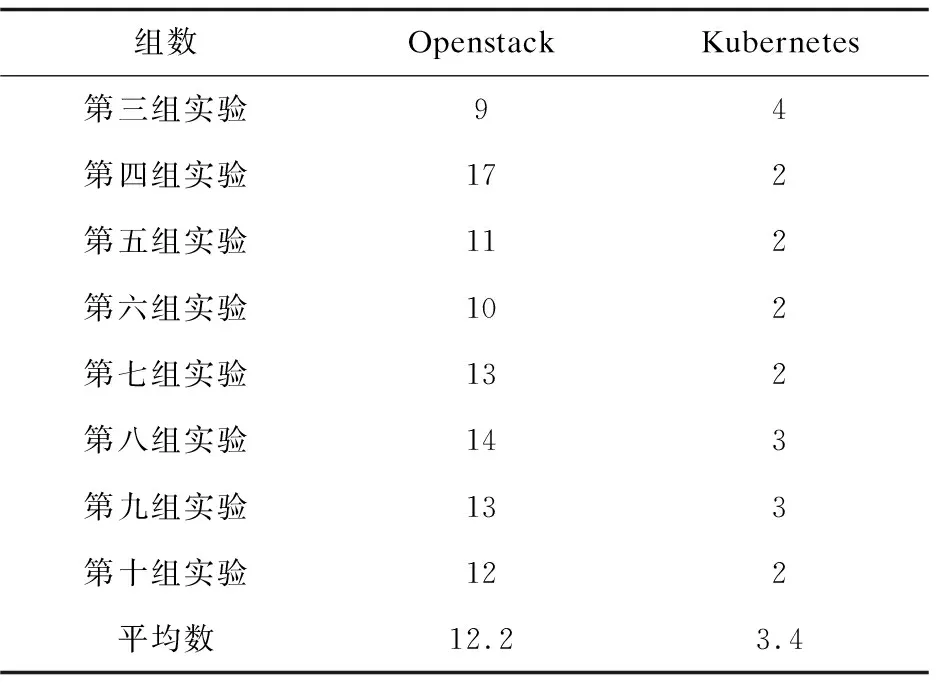
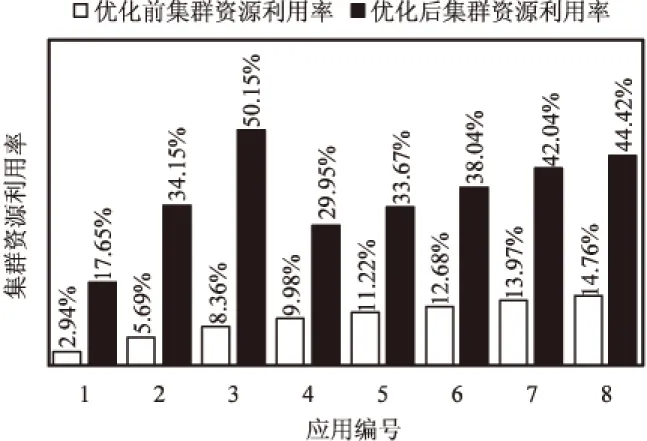
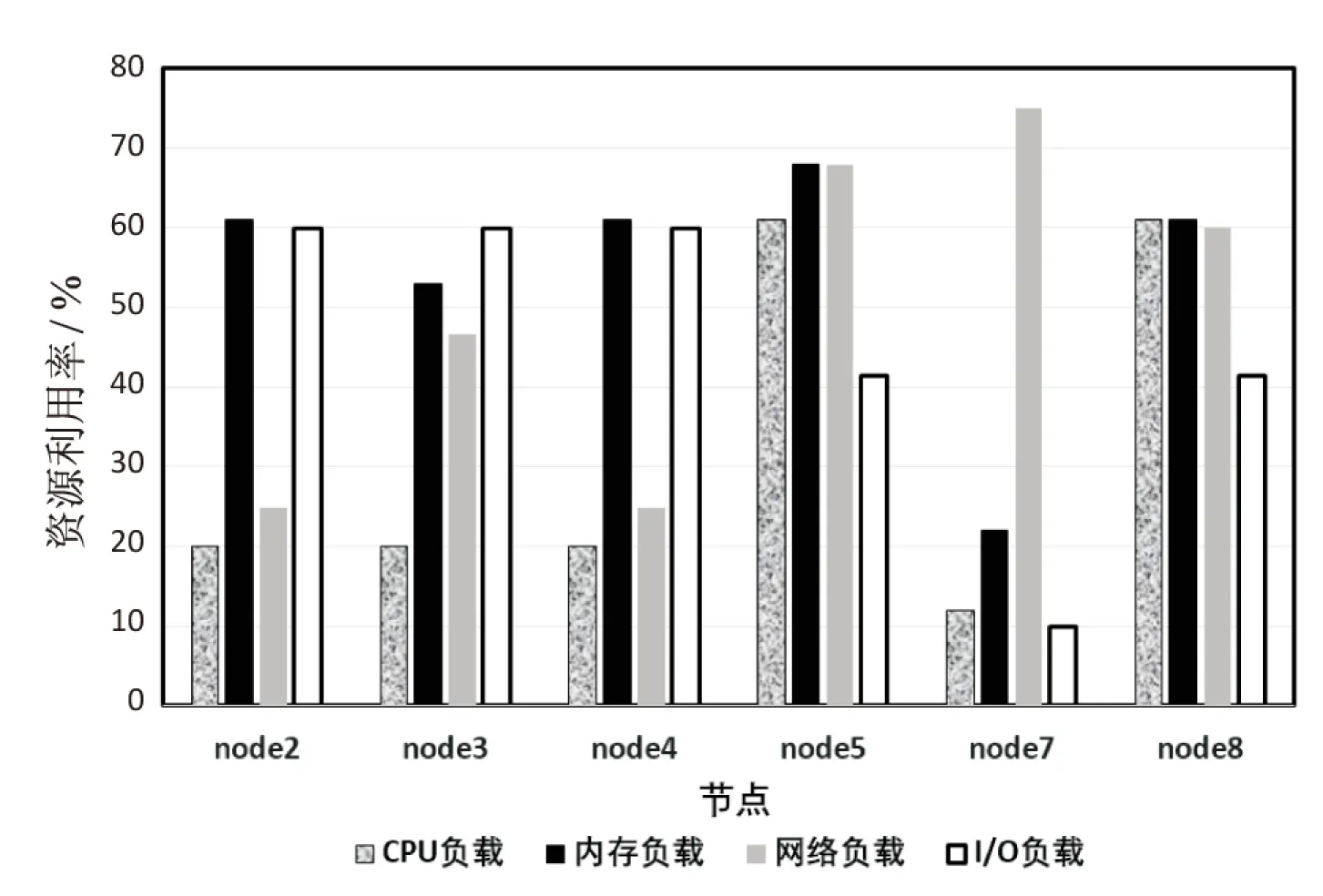
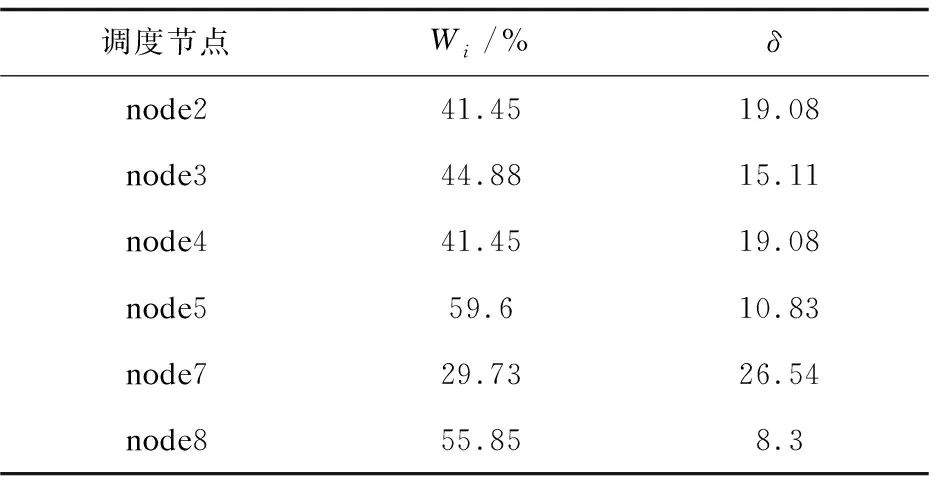
假设集群内共有K台服务器serveri(0 基于以上,建立一个资源调度优化模型: (1) Palloc=Pnode-(Psys+Pkube+Ptake) (3) WCPU=Wcpu+λtwait (4) WM=Wm+λtwait (5) WN=Wn+λtwait (6) WI/O=Wi/o+λtwait (7) WALL=WCPU+WM+WN+WI/O (8) Wi表示服务器的平均使用率,由于应用往往对资源要求不是均匀的,一个服务器节点往往在内存占用密集时,CPU、网络或I/O处于空闲状态。针对这种情况,对应用类型进行分类排序使服务器负载尽可能均匀,将应用占用最多的资源进行分类,在各个分类内从大到小排列分类资源,形成四个应用链表。δ描述负载是否均匀。 Palloc表示系统可分配,Pnode表示服务器节点总的可用资源,Psys表示操作系统保留资源,Pkube表示Kubernetes系统保留资源,Ptake表示Kubernetes已分配资源。当Ptake=0表示该服务器上没有任何应用在运行。 模型中λ是可调等待时间权重,twait是任务的等待时间,WALL用于排序等待的待分配任务队列。WCPU、WM、WN、WI/O综合考虑了应用负载和等待时间,用于优先级调度通过分类排序每一项资源等待的待分配任务队列。Si是改进的打分算法,尽可能将应用部署在得分小,即在保证有预留资源的情况下,提高服务器资源负载,最终达到提高集群资源利用率的目的。 2.2.1 初始调度算法 根据以上系统模型,以Δt为时间周期,采集serveri上各个已经部署应用及其总占用的真实CPU、内存、网络和I/O的数据。通过对采集的数据进行加工整理,可知服务器适合部署哪种应用。再根据应用对CPU、内存、网络和I/O的最低资源需求可初步判断应用是什么类型。如果服务器任一资源占用率大于80%,表示该服务器节点处于高负载,则用Kubernetes命令cordon将此节点设置为不可调度,一方面是为了保证服务器性能,一方面是预留部分资源给已经运行在该节点的应用。也将Ptake=0的服务器用cordon命令设置为不可调度(未分配容器应用的服务器),随后将该台服务器休眠,以提高集群资源利用率,同时节省数据中心资源。当集群中无法满足新应用最低资源要求,再重新唤醒添加休眠中的一台服务器进入集群,随后使用uncordon命令恢复节点为可调度节点。具体调度流程如图1所示。 2.2.2 服务器上应用迁移算法 对于服务器实际任意资源占用率大于90%在ΔT时间内(ΔT由云平台管理员设置),或δ>k(k是衡量服务器各项资源是否负载均匀的可调参数),表示该节点单种资源负载过高,或者四种资源严重不均匀,需要迁移应用。前者为了保证服务器性能和预留安全资源,后者是为提高集群资源利用率。详细的应用迁移过程如下: (9) a+b+c+d=1 (10) 图1 容器部署流程 选择serverm需要迁移容器的具体算法如下: step1:按e=(Δe1,Δe2,Δe3,Δe4)的δ'将容器从大到小排成队列,依次选取队列容器进行下一步计算; step2:计算当前容器以及队列前面容器累计迁移应用后serverm的各项资源利用率并判断Wcpu、Wm、Wn、Wi/o是否均小于90%,或者满足δ≤k。若成立,进行下一步;不成立选择队列中下一个应用,重新计算step2; 为了验证调度策略的可行性和有效性,搭建了一个基于Openstack的Kubernetes集群。在实验中使用9台戴尔R710服务器(其中Kubernetes集群7台,一台作为Master,七台作为Slave)。K8s使用1.9.2版本,Docker使用1.17.03版本,操作系统为Centos7.4。 为了模拟云平台负载,用以下工具模拟云平台各项资源负载。 (1)CPU和内存:对于CPU负载使用Linux下标准负载测试工具包Stress-ng模拟CPU和内存负载。 (2)网络:在容器里使用tomcat搭建简单网站,使用专业网站测压工具Apache Bench模拟网站用户并发访问负载。 (3)I/O:用专业磁盘测试工具fio模拟和监测磁盘负载。 3.2.1 实验一:容器和虚拟机的开机时间对比 对Openstack启动虚拟机和Kubernetes启动centos7.4容器所需的时间分别进行测试,结果如表1所示。 表1 Openstack容器和虚拟机开机时间对比 s 续表1 实验证明了在此云平台上,容器从创建命令开始到成功创建启动时间是虚拟机创建到启动时间的约四分之一。 3.2.2 实验二:首次部署调度和迁移对照实验 实验组1:容器初次调度算法对照实验。 假设在Δt时间内有以下应用,分别按照Kubernetes默认算法和改进后的调度算法调度以下应用。用Centos命令sar获取CPU服务器系统占用率;vmstat获得内存占用数据;用iftop获取网络带宽数据;用iostat获得磁盘iops数据,采集时间间隔为10 s,共采集10次,将命令执行结果写成脚本重定向到指定文件,然后整理数据,计算出各项负载平均值作为serveri的Wcpu、Wm、Wn、Wi/o。应用情况和部署每一个应用集群内每一台服务器状态转移情况如图2所示。 图2 部署应用过程优化前后集群资源占用率对比 最开始,优化后的算法集群内只有一个激活节点,当部署第三个应用时再激活第二个节点;而Kubernetes自带算法最开始集群内所有节点都被激活,导致整体集群负载率很低,造成服务器资源的大量浪费。 实验组2:容器迁移算法。 由于队列中应用任务大多数时都是随机的,且应用真实负载是未知的,serveri节点在经过一段时间的运行,资源有可能存在不足即某一个或多个资源占用率超过节点资源的90%,即Palloc<10%Pnode,或者节点资源严重分配不均匀,δ>k,此次实验设置k为16。 在时间内随机顺序对Kubernetes部署应用,由于应用的不可预知性,所以此时节点真实负载不均匀,需要进行二次调度即迁移调整。 应用运行一段时间后每个节点详细资源使用率如图3所示,节点的平均资源使用率和方差如表2所示。 图3 应用运行一段时间后每个节点详细资源使用率 调度节点Wi/%δnode241.4519.08node344.8815.11node441.4519.08node559.610.83node729.7326.54node855.858.3 表3 node7上应用按负载最高资源从小到大排列 由表3确定迁移应用1,迁移后node7的δ=8.87满足δ≤15,将应用一加入到2.1中调度模型重新调度。 同理,筛选出node2、node4和node3上需要迁移的应用,加入到2.1中调度模型链表中,重新分配,最后运行状态如图4所示。 在实现迁移算法后,运行同样数目的容器应用,能减少运行应用的服务器节点,从而提高集群资源利用率,节约数据中心能耗。 优化后的调度策略更细粒度地划分了数据中心资源和增加了调整云平台的参数,在提高集群资源利用率的条件下综合考虑了各种资源的负载均匀以及迁移时间代价,有效优化了基于Openstack的Kubernetes私有云调度模型。 图4 集群中运行应用的节点数对比 改进了Kubernetes原有的调度策略,结合Openstack云平台,提出一种基于Openstack的Kubernetes私有云弹性调度策略,细粒度划分了调度资源。通过对每种资源需求从多到少的排序轮转调度和运行一段时间后监测负载过高以及资源严重分配不均的服务器节点应用二次调整迁移算法,实现了对私有云的弹性调度,有效提高了云平台资源利用率,达到合理使用数据中心硬件资源和降低数据中心运营成本的效果。下一步将研究复杂的调度、混合云调度,通过更加细粒度地划分服务类型如有无持久存储需求,服务时长以及在可知和不可知应用最大资源上限的调度等,结合现有开源云架构如Hadoop、Kubernetes、Openstack和更高级算法解决实际问题。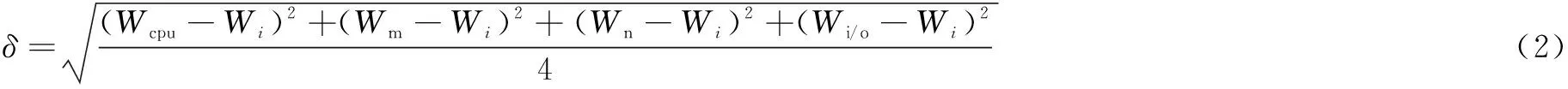

2.2 调度策略


3 实验及对比分析
3.1 实验环境
3.2 实验过程及对照分析

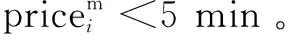


4 结束语
猜你喜欢
矿山安全信息(2022年11期)2022-11-26
矿山安全信息(2021年3期)2021-11-30
读者·校园版(2019年24期)2019-12-10
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
中学生数理化(高中版.高考理化)(2019年6期)2019-06-22
妇女生活(2018年7期)2018-07-14
考试周刊(2016年82期)2016-11-01
小朋友·聪明学堂(2015年8期)2015-11-30
电脑爱好者(2015年21期)2015-09-10
