
基于Scrapy框架的爬虫和反爬虫研究
2019-02-25 13:14马明栋王得玉
计算机技术与发展 2019年2期
韩 贝,马明栋,王得玉
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 地理与生物信息学院,江苏 南京 210003)
0 引 言
信息时代下,每天有数以万计网络爬虫[1]程序在万维网上自动运行,搜集大量数据。如何有效阻止这些爬虫是每个网站构建者必须要考虑的事情,而如何以低成本突破网站对爬虫的限制,继续搜集数据则是每个爬虫使用者思考的问题,这场在反爬虫[2]和爬虫之间的较量,从未停歇过。文中结合实际网站来分析反爬虫的一些常用手段,如IP限制、访问频率控制等[3];同时基于爬虫使用者经常使用的开源爬虫框架Scrapy,来说明爬虫使用者又是如何来化解网站限制的。
1 Scrapy框架简介
1.1 Scrapy概述
被称为胶水语言的Python,具有丰富和强大的库,如requests、urllib、scrapy和pyquery等[4],其中scrapy库应用最为广泛。Scrapy是Python语言开发,为爬取万维网上网站数据而设计的开源应用型框架,可以应用在数据挖掘以及信息处理等方面。借助Scrapy,可以方便快速地按照自己的需求,保存网页关键数据为任意数据格式。
1.2 Scrapy框架详解
Scrapy是由Scrapy Engine、Spiders、Item Pipeline、调度器、下载器、下载器中间件和Spider中间件构成[5],具体框架如图1所示。
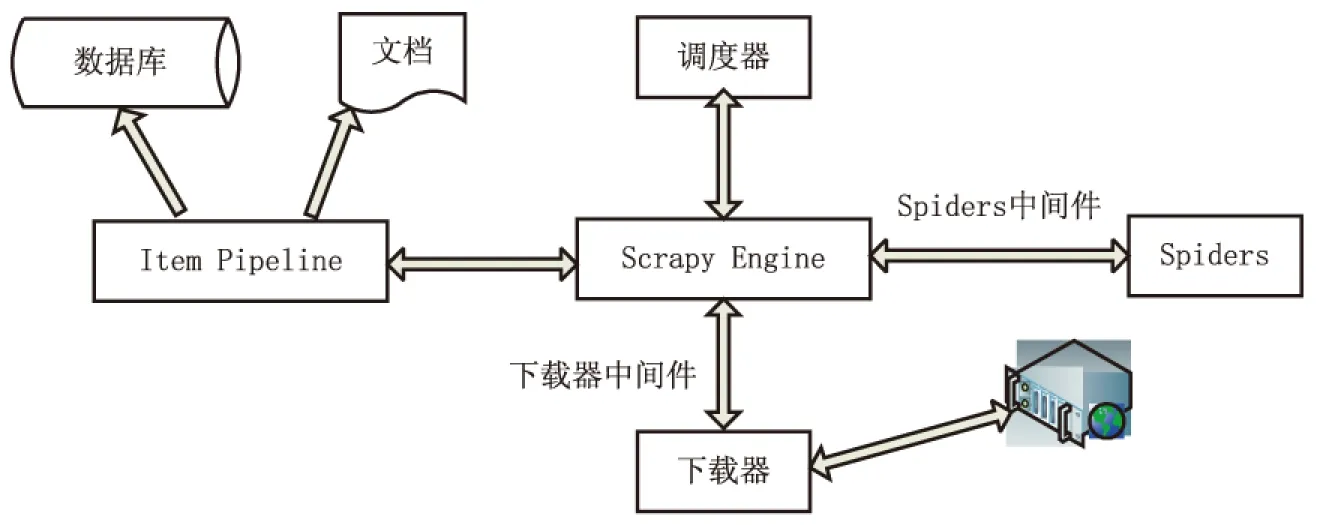
图1 Scrapy框架
(1)Scrapy Engine:负责系统中数据流动,维护框架各个部分正常运作;
(2)Spiders:处理下载的网页信息,提取结构化数据,获取需要额外跟进的URL;
(3)Item Pipeline:处理Spiders提取出来的数据;
(4)调度器:控制整个URL请求顺序;
(5)下载器:从浏览器中下载相应网页信息;
(6)下载器中间件:Scrapy Engine和下载器之间的钩子,用于修改Scrapy请求和响应;
(7)Spider中间件:Scrapy Engine和Spiders之间的钩子,处理Spider输入输出。
1.3 Scrapy基本工作原理
Scrapy首先从Spiders中拿到第一个要请求的URL,通过调度器调度下载器进行页面下载,下载的页面信息由Spiders进行处理。Spiders从页面中提取数据信息并交给Item Pipeline,而提取的URL信息则通过Scrapy Engine交由调度器处理。Item Pipeline接收到Spiders数据,对数据进行处理,处理之后保存为制定的数据格式。调度器获取URL之后,重复以上操作,直至调度器里URL队列为空时,结束爬虫运行[6]。
2 常见反爬虫方法
2.1 IP地址限制
爬虫爬取某个网站数据时,会发生短时间内发出大量访问请求,而请求IP都是同一个的情况。因此,网站会设置访问阈值,针对超过阈值的异常IP,网站可以禁止其访问[7]。但是由于大量用户公网IP相同,这种方法容易误伤普通用户,所以,一般采取禁止一段时间访问。
2.2 账号限制
目前大部分网站会设置会员限制,部分数据及操作只能登陆账号才能有权限访问,这一做法限制了普通爬虫随意访问。但深层爬虫[8]可以通过携带cookies信息,突破网站权限设置,继续爬取数据。网站可以实时监测账号访问频率,设置访问频率限制,当某一账号访问超过限制,即可视为异常账号,禁止其访问。
2.3 登陆控制
网站通过浏览器请求信息中的cookies信息[9]来判断该请求是否有权限访问核心数据,一般网站直接输入用户的账号和密码即可成功登陆并获取cookies信息。这一操作爬虫可通过分析网页Html源码,模拟发送请求,就能正常获取cookies信息。于是部分网站设置了验证码等验证方式,只有成功输入验证码,才能获取cookies信息。同时,部分网站还会设置Session方式进行账号认证,只有获取服务器对用户的唯一标识ID,才能得到cookies信息。
2.4 网页数据异步加载
早期简单网页采取静态网页方式,网页所有内容都包含在Html源码里,爬虫通过伪造请求,获取网页Html源码并分析Html源码,就能提取出自己想要的数据。
随着网页技术的发展,动态网页[10]逐渐成为主流。动态网页页面源码相对于静态网页而言,显示的内容可以随着时间、环境或者数据库操作的结果而发生改变。如果爬虫只是单纯分析Html源码,将无法获取有效数据。
3 基于Scrapy的爬虫方法
3.1 构建IP代理池
爬虫需要在短时间内发出大量访问请求,若爬虫一直使用同一IP地址,就会被网站禁用,为避免这种情况发生,使用IP代理[11]是非常有必要的。爬虫IP代理有付费和免费两种,付费IP质量较高,爬虫直接请求相关付费接口即可获取不同IP;免费IP质量较低,容易出现连接失败的情况。下面,以西刺代理网站免费IP为例,构建自己的IP代理池,其架构如图2所示。
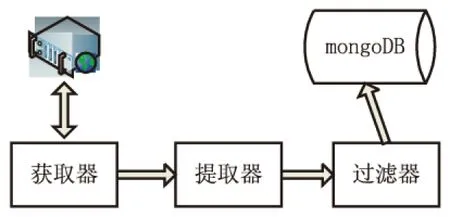
图2 IP代理池架构
使用详解:
(1)分析西刺代理网站页面源码,从源码中找到需要提取的IP地址数据和端口信息;
(2)利用Scrapy构建西刺代理网站爬虫,首先创建spiders,定义要爬取的西刺代理网站地址,通过spiders的css选择器,提取出需要的数据,实现获取和提取功能,将数据存入items中;
(3)对items中的数据进行验证处理,实现对提取出的数据进行过滤。导入requests模块,使用爬取出来的IP代理去请求百度网址,若返回的状态码为200,则证明该IP代理有效,将该IP地址存入到mongoDB数据库中,反之则丢弃该数据;
(4)爬虫若需要使用IP代理池中的IP数据,只需要修改下载器中间件类中process_request方法,在该方法中调用request.meta设置IP代理,IP代理的具体数据可从mongoDB数据库中查找得到,运行该爬虫就能实现更换IP地址的功能。
3.2 构建cookies池
部分网站数据需要登陆获取权限才能继续访问网页,针对这种情况,爬虫需要构造并携带cookies信息。同时网站会对账号访问记录进行统计,超过一定频率就会被标为异常账户,爬虫重复使用单一的cookies信息很容易造成账号异常而无法使用。解决办法是构建自己的cookies池[12],使用爬虫时,按一定频率来切换cookies信息。需要注意的是,部分网站的cookies信息具有时效性,需考虑更新问题。下面以伯乐在线为例进行详细说明,构建的cookies池架构如图3所示。
使用详解:
(1)需要注册伯乐在线账号,将注册好的账号密码存入文档;
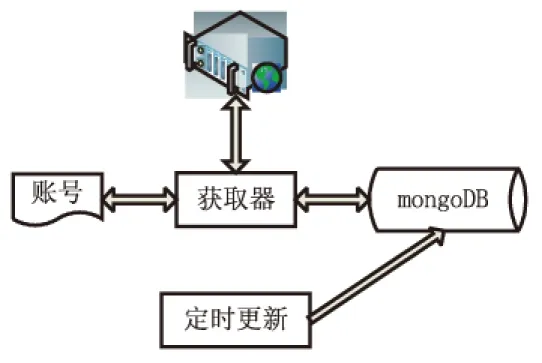
图3 cookies架构
(2)分析伯乐在线登陆页面源码,伯乐在线登陆过程较为简单,直接将账号密码用post方法请求就可获取cookies信息;
(3)基于Scrapy框架,构建爬虫,编写spiders代码,改写类中parse方法,调用mongoDB中账号密码数据,用post请求重复请求登陆页面,获取cookies信息,将提取出来的cookies信息存入mongoDB;
(4)若要使用cookies信息,只需要改写下载器中间件的代码,需要注意cookies的时效性,要定时更新mongoDB中的cookies信息。
3.3 突破登陆限制
上面分析的伯乐在线登陆过程较简单,但是部分网站登陆过程远比这个复杂,例如登陆github网页,需要获取存储在token字段中的Session标识。而知乎的登陆过程则更为复杂,在有Session标识的同时,还需要正确输入验证码才能登陆成功。下面以知乎登陆过程为例,详细说明爬虫是如何处理这些登陆问题的。
使用详解:
(1)分析知乎登陆页面源码,可以发现其中有一个xsrf值,登陆时需包含该值,同时还有验证码校验,必须输入正确验证码才能成功登陆;
(2)用Scrapy框架编写爬虫,在spiders文件里的parse方法中,提取登陆页面源码里的xsrf值,将该值写入post方法中;
(3)对于登陆页面验证码,可以采用人工输入或者自动识别两种方法。若采用人工输入,首先获取验证码图片,用PIL库中Image类的show方法,展示图片,然后手动输入。若采用自动识别,可接入打码平台或者使用机器学习来识别,自动输入;
(4)解决以上两个问题,爬虫便可成功登陆,获取cookies信息并进行数据提取。
3.4 Selenium处理动态网页
随着前端技术的不断发展,现在部分网站页面采用动态页面,需要进行一些页面操作,动态加载出数据。可以通过分析网页的Ajax请求,用爬虫直接请求其对应接口获取数据,但是这种分析较复杂,更简便的方法是使用Selenium[13]。Selenium是一个自动化测试工具,主要用来测试Web应用,能够在浏览器中模拟用户操作。下面以淘宝为例,详细说明其使用方法。
(1)分析淘宝主页面,通过在检索框中输入检索词,点击确定,就能得到相关商品信息;
(2)构建基于Scrapy爬虫,改写下载器中间件文件,在该文件中导入Selenium模块,创建Selenium的Chrome对象;
(3)修改类中process_request方法,添加元素等待语句,一旦页面元素加载出来,就进行填入检索词和点击按钮两个操作;
(4)运行以上爬虫,可以看到Chrome浏览器被自动打开,自动进行填入检索词和点击按钮两个操作,页面数据正常加载出来,爬虫就可以提取加载出来的数据。
4 结束语
爬虫作为获取数据的重要工具之一,广泛应用于各种网站。据统计,网络上百分之六十的流量都是爬虫产生的。文中仅仅列举了一些简单的爬虫和反爬虫方法,指出网站为保护数据所采取的措施,以及爬虫又是如何突破重重限制的。如今,爬虫和反爬虫之间的较量愈演愈烈,还有更复杂的爬虫和反爬技术值得去探讨。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
网络空间安全(2020年1期)2020-05-25
智能计算机与应用(2018年5期)2018-10-20
魅力中国(2018年5期)2018-07-30
电脑知识与技术·经验技巧(2018年1期)2018-05-30
中学科技(2016年7期)2017-05-16
中国计算机报(2014年40期)2014-10-31
移动通信(2009年18期)2009-10-29
