
基于K-means算法的研究生入学成绩分析
2019-02-25 13:14李春生张可佳
计算机技术与发展 2019年2期
李春生,刘 涛,于 澍,张可佳
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
研究生入学成绩作为学生在毕业学校期间表现好坏的重要评价标准之一,是学生检测之前学习状态、学习态度的依据,是学校之间相互了解的重要参考标准,然而大多数学校对于学生的入学成绩仅仅停留在登记、分类、储存等表面的工作,缺乏对学生入学成绩背后潜在信息的深入分析,从而造成了教学资源的浪费。通过对研究生入学成绩的分析,可以帮助导师了解学生的学习能力、学习风格,帮助学生制定个性化培养方案。同时,学生的入学成绩反映出学生毕业学校的办学条件,教学水平,人才培养的质量。因此,对研究生入学成绩进行合理有效的深度挖掘,可以更好地帮助学生进行研究方向的选择,帮助其找到适合自己发展的方向,实现研究生的个性化教育和培养。
应用聚类分析算法对研究生入学成绩进行分析,能够发现学生成绩分布的特点,找出成绩之间的关系,弥补传统分析方法对研究生入学成绩分析的不足,为教学管理者提供了决策指导。
1 聚类分析
聚类分析属于探索性、无监督的数据分析方法,即将给定的数据元素进行划分,使高相似性的数据元素归为一类,低相似性的数据元素归为不同类。相似度的高低是通过计算两个数据元素之间的距离来判断的[1]。欧几里得公式是常用的距离计算公式,表示如下:
(1)
主要的聚类分析算法包括层次聚类算法、基于密度的聚类算法、基于网格的聚类算法、基于模型的聚类算法和划分聚类算法[2]。
1.1 层次聚类算法
层次聚类算法是运用层次分解的方法将给定的数据集合形成满足某种条件的聚类树。层次聚类算法具有很高的聚类精度,但其时间复杂度和空间复杂度较高的缺点依旧无法避免[3]。随着研究生人数的迅速增长,入学成绩数据量的增大,层次聚类算法因其自身的缺点,无法高效地实现对研究生入学成绩的分析。
1.2 基于密度的聚类算法
基于密度的聚类算法给定密度阈值,将密度超过阈值的区域连接,形成相同密度区[4]。使用该算法的基础是数据分布的密度差距较大,由于研究生入学成绩首先要超过国家分数线,研究生入学成绩的分布很难出现密度差距较大的区域,因此基于密度的聚类算法不适用于研究生入学成绩的分析。
1.3 基于网格的聚类算法
基于网格的聚类算法将给定的数据元素划分成若干网格单元,然后进行网格单元的凝聚和分裂[5]。基于网格的聚类算法优缺点明显,优点是聚类速度快,缺点是无法处理分布不规则的数据。研究生入学成绩在空间上分为多个维度,数据的分布具有随机性易形成不规则分布,因此基于网格的聚类算法对于研究生入学成绩的分析缺乏精确性。
1.4 基于模型的聚类算法
基于模型的聚类算法将每个聚类构想成数学模型,然后通过聚类使数据元素找到自己的对应模型,用统计法得到类个数的过程。常见的算法有统计学方法和神经网络方法。该算法复杂度较高,执行效率缓慢,因此也不适用于对研究生入学成绩进行分析。
1.5 划分聚类算法
划分聚类算法运用分裂的方法将数据集进行分类,分组的结果使同类元素之间的相似性高,异类元素之间相似性低,并且保证每一类中都包含一个或多个数据元素,每个数据元素只属于一个类。划分聚类算法具有算法简单、复杂性低、收敛速度快、聚类效果较好等特点,加之研究生入学成绩有复试分数线作为“基础分数”,没有明显的噪声点的影响,因此适用于研究生入学成绩的分析。常见的算法有K-means算法、K-medoids算法及CLARANS算法等[6],其中典型的代表算法就是K-means聚类算法。
2 K-means聚类算法
K-means算法是划分聚类算法中一种经典的聚类方法,在生物应用、图像分析、市场调查等领域中应用广泛[7-9]。以K-means算法为关键字在中国知网上进行搜索,发现对于K-means算法的研究虽然在某个年份中有略微的下降趋势,但其总体上是持续上升的,如图1所示(2018年为预测数值)。
K-means聚类的算法思想为,给定包含X个d维数据的数据集M={m1,m2,…,mn}(mi∈Rd),及将要生成数据的子集数目K,K-means算法将给定的数据集分为K组[10-11]。每个分组为一个类C={Ck,i=1,2,…,K},每个类Ck都有一个中心Oi。以欧氏距离作为数据之间相似性的判断标准,计算类中数据点到聚类中心Oi的距离平方和,计算公式为:
(2)
聚类的最终的目的是使同类中所有数据元素到其聚类中心距离的平方和J(C)值最小[12]。
(3)
(4)
算法流程如图2所示。
K-means聚类算法可以对大型的数据集进行高效的分类、聚类,其复杂度是O(nkt),其中n为数据元素的个数,k为聚类个数,t为迭代次数[13]。
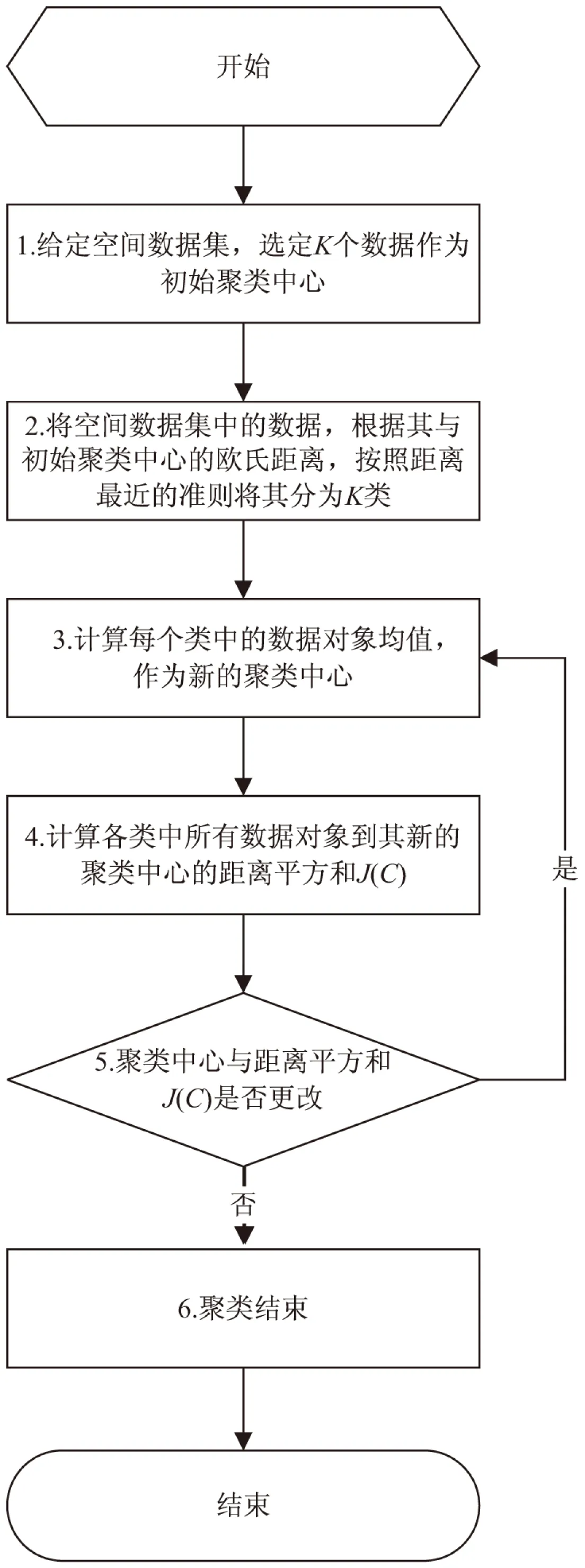
图2 K-means聚类算法流程
3 K-means聚类算法在学生入学成绩分析中的应用
本次实验用统计分析软件SPSS对数据进行分析。
3.1 数据来源
实验数据来源某高校2013年、2014年马克思主义理论专业研究生入学成绩。马克思主义理论专业学生共115人,其中2013年学生66人,2014年49人。
3.2 数据预处理
实验中对于数据的处理采用忽略元组的方法,删除外语考试为非英语一、免试入学、专业课考试为中国近代史的学生共31人,得到最终实验数据情况为:马克思主义理论学生总人数为104人,其中2013年学生62人,2014年42人。预处理结果(部分)如表1所示。
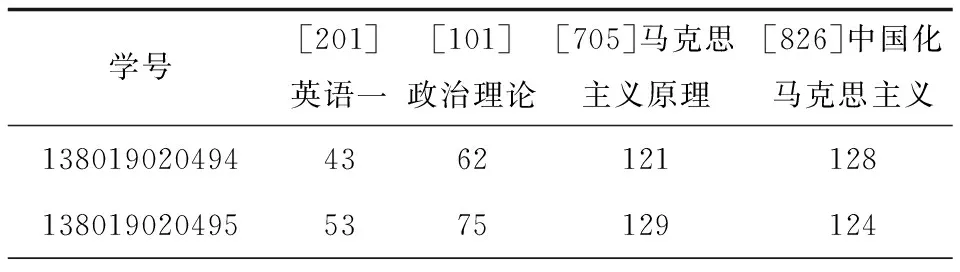
表1 马克思主义理论专业研究生入学成绩
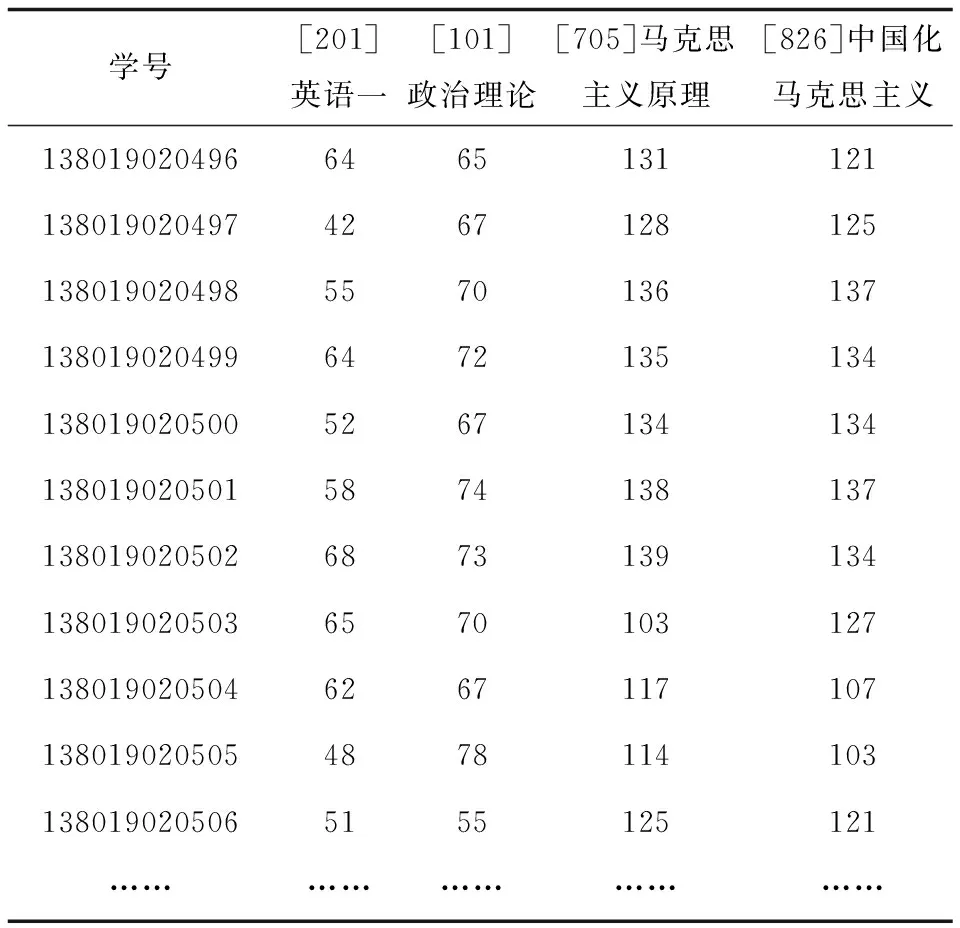
续表1
3.3 聚类数的处理
将处理过后的数据导入SPSS软件,利用K-均值聚类。首先,将2013年马克思主义原理专业研究生的入学的成绩分别进行分析,初始的聚类中心随机产生,聚类数目定为5。当迭代次数为6时,任何中心的最大绝对坐标更改为0,初始中心间的最小距离则为29.563。其次,对2014年马克思主义原理专业研究生入学成绩进行分析,K=5得到的初始中心间的最小距离为41.061。
3.4 聚类结果分析
最终聚类中心与每个聚类中的案例数如表2和表3所示。
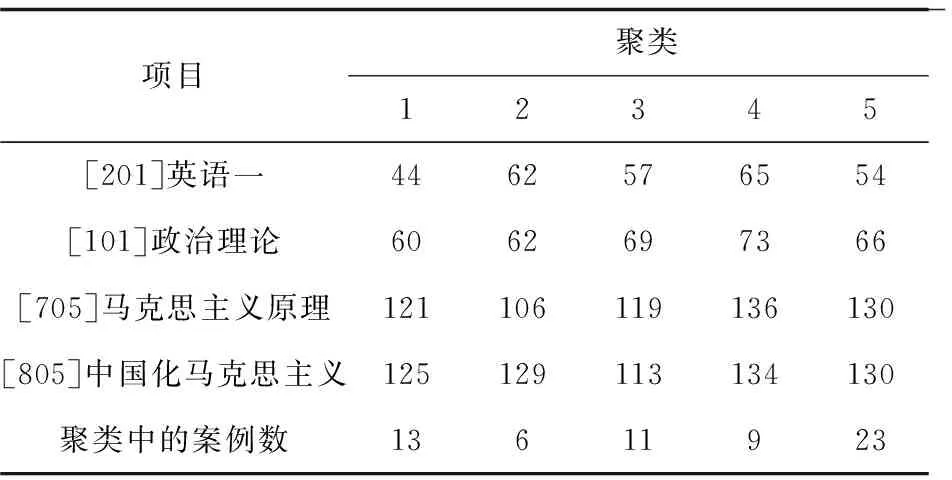
表2 2013年最终聚类中心及案例数
由表2分析可知,第一类学生共13人,占总学生人数的21%,总体成绩状况较差,低分出现概率最高区域,专业课能力相对较好,英语成绩水平有待提高,培养方案中应加强对英语能力的培养;第二类学生共6人,占总学生人数的9.7%,其中马克思主义原理成绩较低,其他成绩相对较好,表明该类学生马克思主义原理的知识结构相对匮乏,应加强对于专业课能力的培养,研究方向可考虑中国化马克思主义相关领域;第三类学生共11人,占总学生人数的17.8%,这类学生成绩处于中间水平,专业课能力有待提高;第四类学生共9人,占总学生人数的14.5%,这类学生的总体情况稳定,成绩较为优秀,没有弱科情况;第5类学生共23人,占总学生人数的37%,这类学生成绩相对较好,但相比较其他学科来说英语较弱。
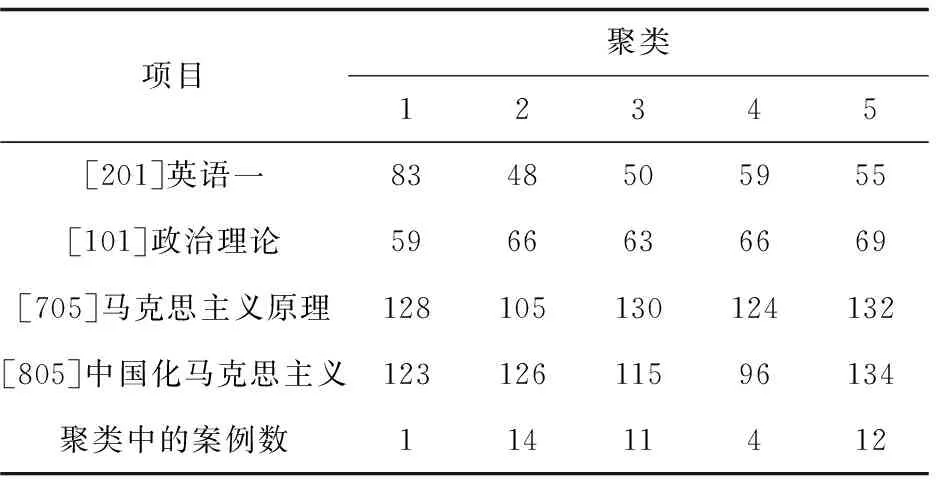
表3 2014年最终聚类中心及案例数
由表3分析可知,第一类学生共1人,占总学生人数的2.4%,总体成绩状况较好,政治理论成绩较低,英语成绩突出,专业课能力相对较好,培养方案中应加强对政治理论能力的培养;第二类学生共14人,占总学生人数的33.3%,其中英语和马克思主义原理成绩较低,其他成绩相对较好,应加强英语以及马克思主义理论方面的研究培养,研究方向应趋向于中国化马克思主义相关领域;第三类学生共11人,占总学生人数的26.2%,这类学生英语和中国化马克思主义成绩相对较弱,应加强这两方面能力的培养,但这类马克思主义原理成绩突出,研究方向应趋向于此研究领域;第四类学生共4人,占总学生人数的9.5%,这类学生中国化马克思主义成绩较低,其他成绩相对较好应加强关于马克思主义中国化的研究;第5类学生共12人,占总学生人数的28.6%,这类学生成绩相对较好,英语成绩相比较低,专业课水平较高,基础扎实。
将2013年和2014年聚类情况表进行纵向分析,如图3所示,其中纯色填充表示2013年情况,宽上对角线填充表示2014年情况。
由图3可得,除英语最低聚类中心2013年为44分,而2014年为48分,2013年略低以外,其他科目成绩的最高值均在2013年,成绩最低值均在2014年,说明了2013年学生的学习能力,专业课功底相对高于2014年的学生。
4 结束语
聚类分析作为数据挖掘中的一种重要的技术手段和方法,已经广泛应用于各个领域。在教育信息化[14]的发展趋势下,数据挖掘技术应用于教育领域已经成为必然。文中通过列举法对几种常见的聚类分析算法在研究生入学成绩领域的适用性进行说明,得出划分聚类算法应用于研究生入学成绩中效果最优的结论,并运用划分聚类算法中的典型算法K-means进行论证,以实例证明了K-means算法对研究生入学成绩进行分析的可行性。分析结果科学合理地反映了学生的学习状态及学习能力,为研究生的培养,专业培养方案的制定提供了有利的依据。
猜你喜欢
学与玩(2022年9期)2022-10-31
北京航空航天大学学报(2022年8期)2022-08-31
中国饲料(2022年5期)2022-04-26
文教资料(2022年1期)2022-04-08
作文·小学低年级(2021年8期)2021-11-02
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
21世纪商业评论(2018年1期)2018-01-22
快乐作文·低年级(2016年9期)2016-09-30
互联网天地(2016年1期)2016-05-04
