
海表面温时间序列的相关性及复杂性研究
2019-02-25 13:21于文静徐凌宇
计算机技术与发展 2019年2期
于文静,余 洁,徐凌宇
(上海大学 计算机工程与科学学院,上海 200444)
0 引 言
海洋系统是一个动态的复杂系统,在演化过程中,海洋系统动力学特征往往呈现出复杂性和非线性。海洋表面温度(sea surface temperature,SST)是一个重要的海洋环境参数,几乎所有的海洋过程,特别是海洋动力过程都直接或间接地与温度有关。SST时间序列具有明显的季节性,长记忆性行为是复杂系统内在机制的综合表现,是探索时空耦合系统的深层动力机制的有效工具。因此对SST时间序列的复杂性及相关性进行研究,对揭示海洋的特性和机理具有非常重要的意义[1-3]。
样本熵[4]是一种衡量时间序列复杂度的方法,广泛应用在生理信号、脑电信号、振动信号等复杂度分析中[5-6]。但是样本熵在衡量时间序列复杂度时,熵值的大小有时和系统复杂度的增加没有关系[7],因此文中提出了一种样本熵的改进算法——二维熵。相比于样本熵,二维熵在计算向量的相似性时,不仅仅考虑向量之间的模式相似性,还考虑了向量之间的时间距离对相似性的影响。同时,二维熵在最后计算熵值的模型中,考虑了序列中向量的自相似程度对时间序列复杂性的影响。因此二维熵在计算时间序列的复杂性时更加合理。
相关性的分析最早是由英国水文学家H.E.Hurst[8]于1954年提出的,通过重标极差(R/S)分析法构建Hurst指数来度量时间序列的长程相关性。1992年,C.K.Peng等在《Nature》上提出的基于随机游走理论的标准标度分析法[9],计算出波动指数可以刻画时间序列的长程相关性和短程相关性。但这两种方法都是基于平稳时间序列建立的,而现实世界中大多数的时间序列都是非平稳的。对于非平稳的时间序列,C.K.Peng等于1994年在研究DNA序列时提出了去趋势波动分析法(detrended fluctuation analysis,DFA)[10],能够有效减小序列局部趋势导致的非平稳性。DFA分析方法已成功应用在金融市场、情感心电信号、气温变化、降雨演变中等[11-15]。
1 方 法
1.1 二维熵方法
二维熵的定义和样本熵类似,二维熵参数用N,m,r,k表示。其中,N为序列长度,m为嵌入维数,r为相似容限,k为时间衰减系数,具体算法如下:
设原始时间序列U(i)为由N个点构成的序列,根据预先设定的嵌入维数m将原始时间序列重构成一组m维向量,每个向量代表从第i个点开始连续的m个u的值:
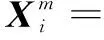
i=1,2,…,N-m+1
(1)
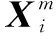
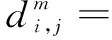
(2)
(3)
(4)
(5)
将维数m增加1,重复上述步骤,得到Bm+1(r,k)。
二维熵在计算时间序列的复杂度时不仅考虑新信息的产生率还考虑向量自相似程度,故二维熵的计算模型如下:
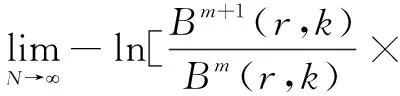
Bm+1(r,k)]
(6)
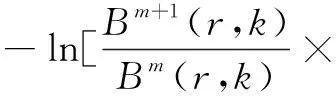
Bm+1(r,k)]
(7)
根据Pincus建议,实验中将m设为2,r为0.2SD,SD为时间序列的标准差;同时将衰减系数k设为0.01。
1.2 DFA方法
给定一个时间序列X={x(i),i=1,2,…,N},N是时间序列的长度,DFA算法[16]主要包含以下几个步骤:
(1)运用以下公式,构造序列的轮廓序列。
(8)
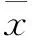
(2)重构序列Y={Y(k),k=1,2,…,N},将它划分成长度为s的互相不重叠的窗口,窗口个数为Ns=int(N/s)。
(3)分别在每个窗口v中,用最小二乘法拟合数据,则可获得局部趋势记为yv(k)。而拟合多项式的阶数可根据实际情况确定,主要用于去除线性的,二次的或者更高次的趋势。将去除趋势后的序列记作:
Ys(k)=Y(k)-yv(k)
(9)
(4)计算去除趋势后每个窗口内的局部波动。
(10)
其中,v=1,2,…,Ns,表示正向顺序的窗口。
(5)由于步骤2中N不一定能被s整除,故在序列尾部存在一小部分数据没有被分析。为了克服这个问题,将序列进行逆序操作,重复步骤3、4,这样就得到2Ns个窗口。
(11)
对于给定的窗口长度值s(或称为标度),可以得到对应的波动函数值F(s),设F(s)与s具有幂律关系,即
F(s)~sα
(12)
其中,指数α称为标度指数。
根据式12可知logF(s)~αlog[s],则在(s,F(s))的双对数图中,可以用最小二乘法拟合得到标度指数α,可知α的数值大小可以反映序列的相关性,如表1所示。

表1 标度指数α的含义
2 数 据
实验数据来自国家海洋信息中心,卫星遥感中国近海的SST实测数据。数据观测点位于中国东部海域130.125°E经度上31个不同纬度。时间分辨率为1天,时间跨度为1994年1月1日至2016年12月31日,数据点长度为8 401。主要选取了位于低纬度第1个观测点和中纬度第16个观测点以及高纬度第31个观测点的SST进行相关性及复杂性研究。
3 实 验
三个观测点的SST从1994年1月1日至2016年12月31日的时间序列如图1所示。可以看出,低纬度第1个观测点序列温差变化小于第16个观测点以及第31个观测点的温差变化,且第1个观测点的SST时间序列变化更复杂。第16个观测点以及第31个观测点的周期性更加明显。
接下来用二维熵度量这三个观测点每一年SST时间序列的复杂度,如图2所示。可以看出,低纬度第1个观测点每一年的SST时间序列的复杂度大于中纬度第16个观测点以及高纬度第31个观测点每一年的SST时间序列的复杂度。并且在2007年及以后三个观测点的SST时间序列的复杂度趋势都是降低的。
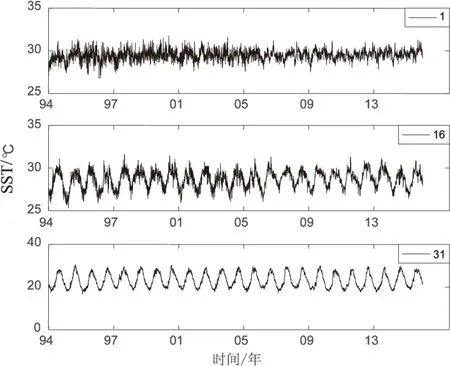
图1 三个观测点的SST时间序列
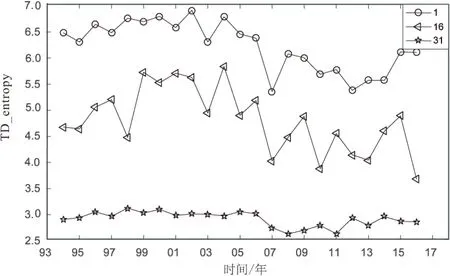
图2 三个观测点每一年SST的复杂度
实际上从图1中可以看出第1个观测点SST时间序列的波动比较明显,相应的季节性等趋势不明显;而第16个观测点和第31个观测点的季节性都比较明显,相应的受其他因素影响的波动趋势就比较弱,序列看起来有规则,所以序列的复杂度相应就小。而低纬度区除了季节性会影响海表面温,其他因素,如太阳辐射和海洋大气热交换等影响更加明显。但是高纬度地区季节性因素相对来说对SST的影响性更大。
然后用DFA方法来研究三个观测点的长相关性。三个观测点每年的SST时间序列的DFA标度指数α如图3所示,每个观测点23年的SST时间序列的长相关性如图4所示。
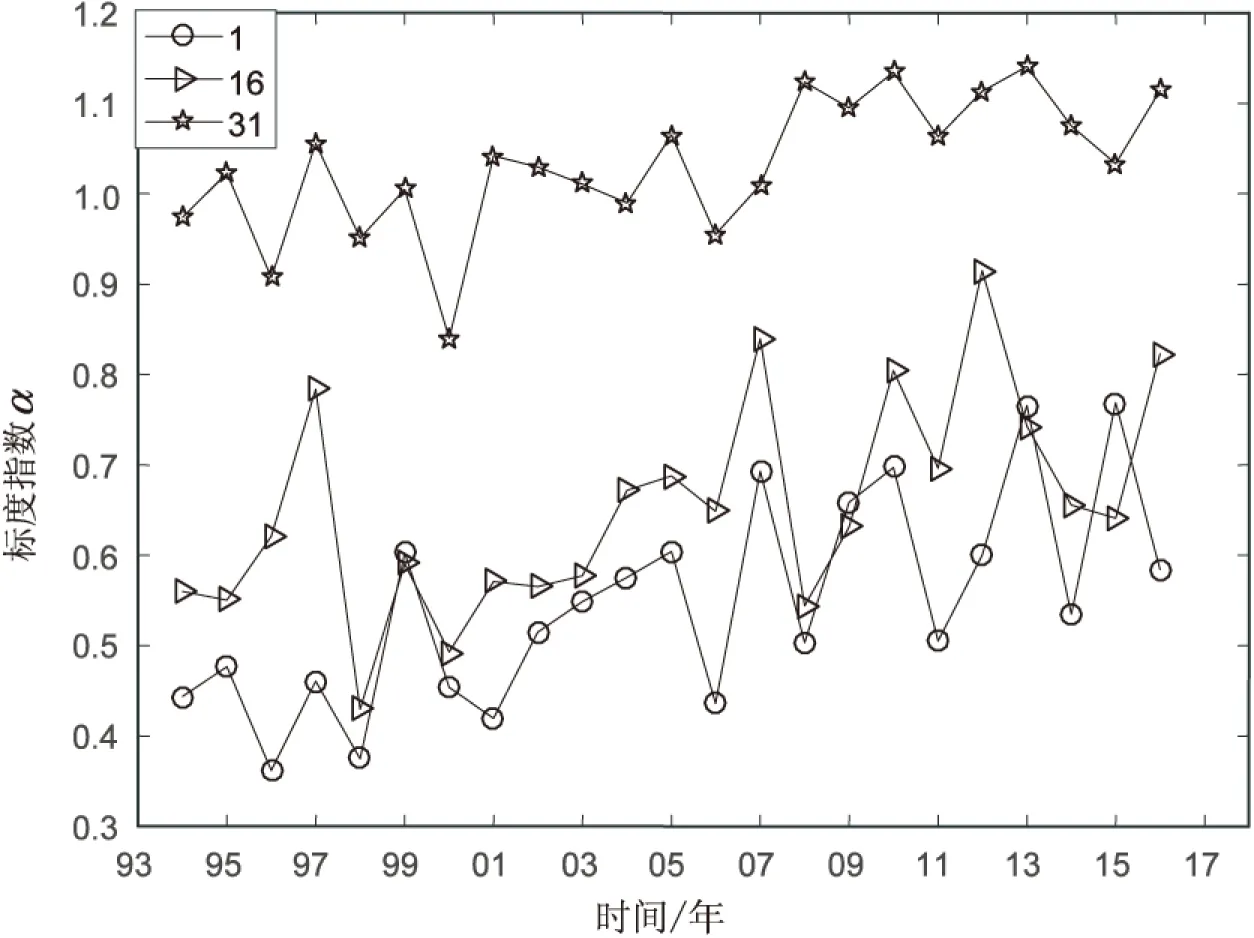
图3 三个观测点每年SST时间序列的DFA标度指数
从图3可以看出,高纬度第31个观测点获得的SST时间序列每一年的DFA标度指数α比其他两个观测点的标度指数都要高,且α值在1上下浮动,表明第31个观测点的SST时间序列具有较强的非平稳性和长记忆性。而第1个观测点的SST的DFA标度指数在0.5上下浮动,表明这个纬度每年的SST时间序列呈现出不同的特点,有时具有长记忆性,有时具有反记忆性。这个结果和复杂度结果相似,对于高纬度地区的SST的季节性比较明显,所以序列会呈现出长记忆性特征。而低纬度地区影响SST序列的因素比较多,当季节性因素影响较强时,序列会呈现出长记忆性;当其他因素影响更强时,序列会表现出随机性或者反记忆性。第16个观测点所在的中纬度地区的SST序列的季节性更加明显,同时其他因素对SST的影响也比第31个观测点强,所以第16个观测点SST的相关性在第1个观测点和第31个观测点之间波动。
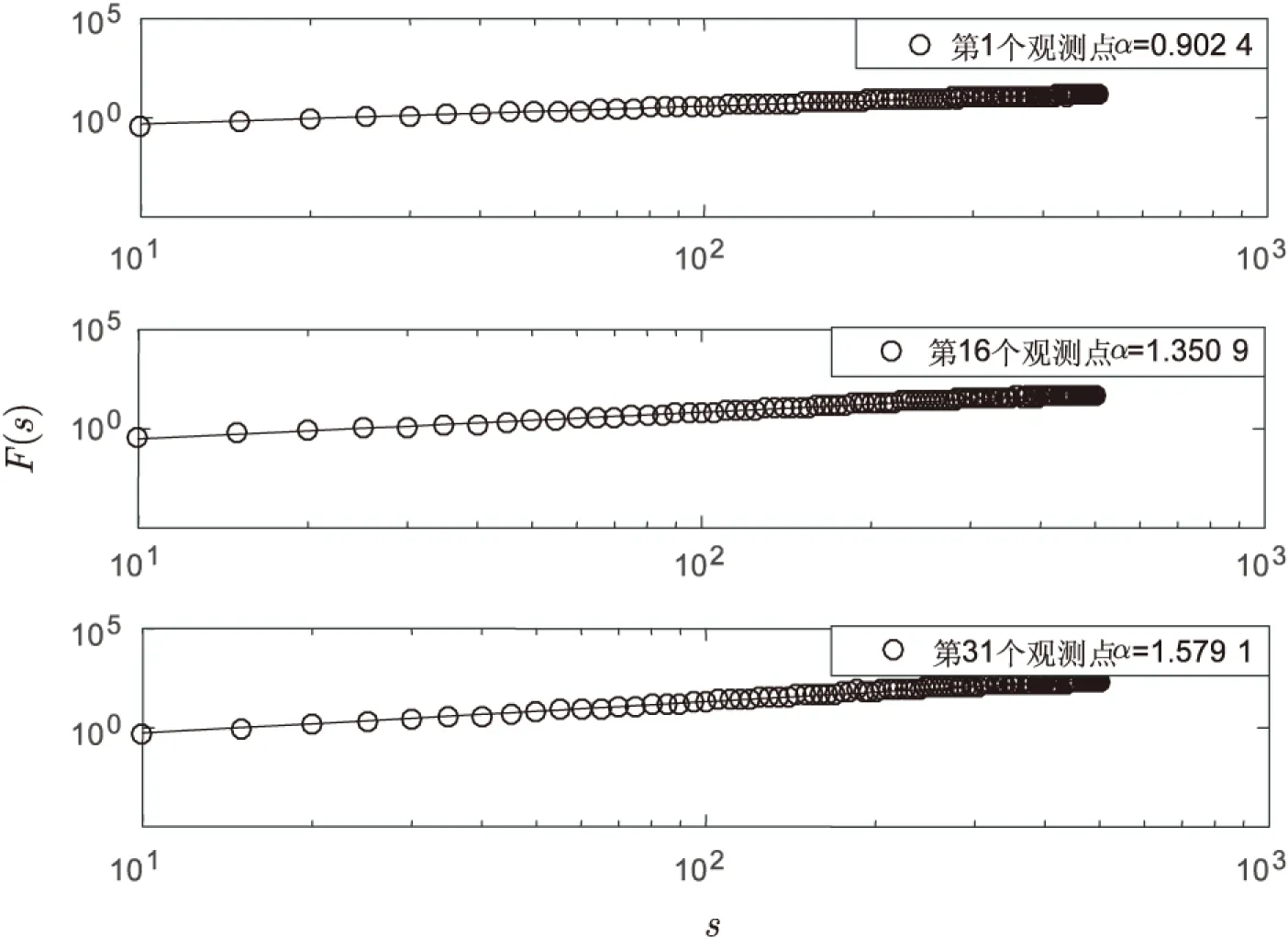
图4 三个观测点23年的SST的DFA标度指数
图4是这三个观测点23年来(1994-2016年)的SST时间序列的波动函数值F(s)与窗口长度s之间的函数关系,直线是两者最小二乘法的拟合直线。可以看出,对于长时间序列,这三个观测点的DFA标度指数α都大于0.5,且高纬度地区第31个观测点的α大于中纬度地区第16个观测点的α以及低纬度地区第1个观测点的α。这三个观测点的SST长时间序列呈现出长记忆性且具有非平稳性。这是因为时间足够长时,序列的季节性特征就相对更加明显,序列的长期记忆性就强。
4 结束语
主要研究了海表面温(SST)时间序列的复杂性与相关性。根据一种改进的样本熵方法——二维熵方法来研究SST的复杂性;使用DFA方法研究SST的相关性。实验结果表明,周期性明显的高纬度地区的SST时间序列的复杂度低于低纬度地区SST时间序列的复杂性。因为影响低纬度地区的SST的因素较多,序列波动的周期性不明显,序列相对来说比较复杂。相对不复杂的高纬度地区SST时间序列长记忆性更加明显,且显示出较强的非平稳性。而相对复杂的低纬度地区SST时间序列呈现出反记忆性及长记忆性不同的特点。然而当序列的长度足够长时,不同纬度下的SST时间序列都呈现出明显的长记忆性及非平稳性。
猜你喜欢
四川大学学报(自然科学版)(2022年1期)2022-02-10
湖南饲料(2021年3期)2021-07-28
天津诗人(2019年4期)2019-11-14
绿色科技(2019年12期)2019-07-15
Coco薇(2017年12期)2018-01-03
科技经济市场(2017年5期)2017-09-16
数学学习与研究(2017年11期)2017-06-23
科技视界(2016年19期)2017-05-18
智富时代(2017年3期)2017-04-02
智富时代(2017年3期)2017-04-02
