
基于总体经验模态分解和CoDE-BP短期风速预测
2019-02-25 13:21胡亚兰
计算机技术与发展 2019年2期
胡亚兰,陈 亮,余 相,王 丹
(东华大学 信息科学与技术学院,上海 201620)
0 引 言
随着信息技术的迅速发展,机器学习和数据挖掘领域的理论和技术研究逐渐成为备受关注的领域,越来越受到广大学者的关注。预测问题作为机器学习领域的一个分支,可以有效预测事物未来的发展趋势,如风速预测问题、产品销量问题等,挖掘出潜在的有用信息。现代科技的蓬勃发展,推动了计算机技术的不断发展和完善。风速预测问题也是一个具有挑战性的难题。为了解决国内日益严重的能源危机,风能作为一种清洁可再生的新能源,广泛应用于电力系统中,特别是风力发电风能资源丰富,将逐渐成为未来的主流发电方式之一[1]。然而,风速具有间歇性、随机性和不稳定性,大规模的风电并网将给电力系统带来巨大的影响[2]。因此,提出一种准确、高效的风速预测方法刻不容缓。
目前,常用的风速预测方法主要有持续法、时间序列法、卡尔曼滤波法、人工智能算法、支持向量机法及组合预测法等[3-6]。文献[7]提出一种基于神经网络和小波分析的短期风速预测方法,对比NWP风速模型,该方法的预测结果更贴近实际风速。文献[8]将迟滞特性引入神经网络中,提出了一种迟滞极速学习机的风速预测模型,增强了模型对历史数据的利用率。文献[9]利用遗传算法和支持向量机对风速进行预测,仿真表明该方法对风速预测具有极大的准确性。Du Pei等[10]提出了一种基于多目标优化蚁狮算法和ENN混合的风速预测模型,用多目标蚁狮优化算法对ENN的权重进行初始化,得到最优的初始化权值参数,克服了单目标优化算法的缺点。Zhang Chu等[11]利用混合回溯搜索算法进行特征选择和参数优化的极速学习机对风速进行预测,对非线性风速序列的建模提出了一种有效的方法。
为了深入研究非线性非平稳时间序列,部分学者已经将经验模态分解方法引入风速预测,较小波分解的优势在于不需要依赖人为设定的基函数。Zhang Chi等[12]研究了一种基于经验模态分解和特征选择相结合的混合风速预测方法,采用ANN和SVM作为特征选择方法,对风速有较准确的预测。Wang H等[13]提出了基于总体经验模态分解EEMD和最小二乘支持向量机LSSVM的风速预测模型,并证明了EEMD方法在解决非线性非平稳问题上的优越性。Zhang Y H等[14]采用EEMD和改进的极速学习机的混合方法预测风速,对风速有较强的拟合能力和预测效果。
传统的BP神经网络在权重寻优过程具有收敛速度慢、容易陷入局部最优等缺点。面对这些问题,文献[15]研究了基于遗传算法和BP神经网络的超短期风速预测模型,利用遗传算法有效地克服了BP神经网络的缺陷,网络的整体性能明显提高。文献[16]将小波分析和BP神经网络进行组合来预测风速,并利用遗传算法对BP网络进行优化,相比单一BP网络,预测效果更好,准确性更高。
基于上述的分析,文中提出一种新的短期风速预测方法,基于总体经验模态分解EEMD和CoDE-BP神经网络的风速预测法(EEMD-CoDE-BP),通过引入EEMD方法可以有效缓解风速这类非线性非平稳信号对预测效果的负面影响。针对传统BP在权重寻优过程易陷入局部最优的缺点,采用CoDE算法优化BP神经网络权重。利用EEMD分解方法将原始风速序列分解为不同频率的子序列和残差序列,将每个子序列作为输入来训练CoDE-BP模型,最后的风速预测结果由每个子序列预测结果的等权求和得到。
1 总体经验模态分解方法
1.1 经验模态分解方法
Huang N E等在1998年提出了希尔伯特黄变换(HHT),它是一种分析非线性和非平稳信号的有效方法,该方法的关键就是经验模态分解方法(EMD)[17]。EMD方法将时间序列分解为一系列频率不同的子序列和残差序列,其中,子序列被称为固有模态函数(IMFs)。相比于传统的傅里叶变换和小波变换,EMD分解方法具有极大优势,它是一种自适应分解信号的方法,不需要人为设定基函数,对非线性非平稳信号的分解效果优于传统分解方法。风速信号作为一种非线性非平稳序列,采用EMD方法可以有效地用来分析风速序列。
EMD算法分解的过程:首先,对原始时间序列x(t)利用三次样条插值法按时间先后顺序分别将极大值点和极小值点连起来,得到上下两条包络线并且计算其均值,记为m1;根据h(t)=x(t)-m(t)计算得到第一个成分h(t),将h(t)看作新的x(t)重复上述操作,直到满足停止条件m(t)趋于零或达到预定的最大迭代次数;然后,将h(t)看作一个IMF,并计算残差序列r(t)=x(t)-h(t);再将残差信号r(t)作为新的x(t)来寻找下一个IMF,如此重复,直到得到所有的IMF。
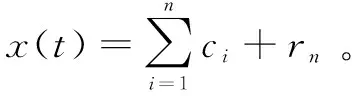
1.2 总体经验模态分解方法
EMD分解方法存在严重的模态混叠问题。针对这个问题,Wu等[18]提出了总体经验模态分解(ensemble empirical mode decomposition,EEMD)方法,它是EMD的一种改进方法,其分解效果明显优于EMD。EEMD分解方法[19]的核心在于分解前在原始信号中添加高斯白噪声,将两者看作一个整体,使不同尺度的信号自动分布在合适的尺度范围内,根据白噪声零均值特性,经过多次加权平均后白噪声可以相互抵消。EEMD算法的过程:首先,添加高斯白噪声至原始风速序列,利用EMD分解方法将原始序列和白噪声所组成的整体分解成不同频率的子序列IMFs,再用不同量级的高斯白噪声重复上述操作,分别得到各自对应的IMF分量和残差分量。EEMD中添加高斯白噪声后平均次数满足以下公式:
(1)
其中,n为平均次数;ε为加入白噪声的百分比;εn为最终误差的标准差。
EEMD分解方法中,由于在原始信号中添加了白噪声信号,不同振幅的振荡不再存在于同一模态,解决了EMD的模态混叠问题。因此,EEMD分解得到的IMF子序列效果更好更平滑,预测精度也明显增强。
2 CoDE-BP神经网络
传统的差分进化算法(differential evolution,DE)中每个个体只能产生一个子个体,这样极大限制了算法的搜索多样性。Wang Y等[20]提出了组合差分进化算法(composit differential evolution,CoDE),采用三种策略对父代个体进行操作,这样每个目标向量便可以产生三个子个体,算法的搜索多样性明显得到提高。CoDE算法的基本思想是,首先随机产生NP个个体作为初始种群,计算每个个体的适应度值。然后采用三种策略产生三个子个体,其中,每种策略分别由一种试验向量产生策略和一组控制参数随机结合而成。计算三个子个体的适应度值,将最好的子个体与父代个体进行选择操作,选出最优的个体进入下一代。如此重复,直到满足终止条件,筛选出具有最小适应度值的个体,得到种群中最好的个体。
前馈(back propagation,BP)神经网络[21]结构简单,由输入层、隐含层及输出层构成,通过误差反向传播算法来训练网络,其应用范围广泛,特别是在分类与预测领域中有广泛应用。BP神经网络可以模拟任何复杂的非线性关系,对非线性问题的处理能力强,因此能够有效地处理风速这类非线性非平稳序列。目前,基于BP神经网络的预测模型在风速预测上已经取得了较好的效果,其预测精度高,但还是无法克服BP网络易陷入局部最优的缺陷,同时存在收敛速度慢等问题。为了解决这一问题,文中将组合差分进化算法CoDE和BP神经网络进行组合,利用CoDE算法优化BP神经网络权重,获取BP网络最优权值阈值,然后网络以最好的初始权重开始训练过程,从而得到具有全局最优解的预测值。
3 基于EEMD和CoDE-BP神经网络的风速预测模型
基于EEMD和CoDE-BP神经网络的风速预测模型的核心思想:首先利用EEMD分解方法将原始风速序列分解为一系列频率不同的子序列和残差序列,然后用每个子序列或者残差分别训练CoDE-BP模型,最后将每个子序列的预测结果进行等权求和作为最终的风速预测结果。基于EEMD和CoDE-BP的模型结构如图1所示;CoDE-BP的算法流程如图2所示。
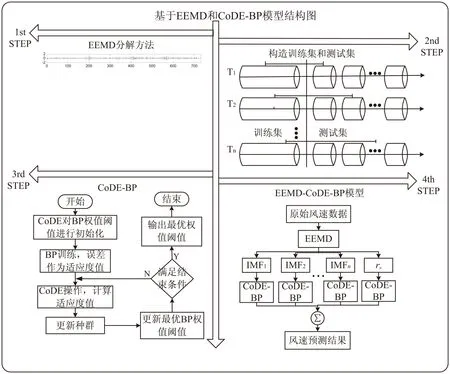
图1 EEMD-CoDE-BP模型结构
EEMD-CoDE-BP算法具体实现步骤如下:
Step1:将原始风速序列通过EEMD分解成不同频率的子序列IMFs和残差序列rn;输入CoDE算法的参数(包括NP,Max_FES,F,CR),并且令FES=NP;确定BP神经网络结构(包括输入层、隐含层、输出层)。
Step2:将每个子分量IMFs和残差分量r分为训练集和测试集。利用CoDE对BP网络权值阈值进行编码,得到初始种群P0={X1,X2,…,XNP},并且令P=P0,其中初始种群包含NP个个体,每个个体代表BP的初始权值和阈值。
Step3:训练BP神经网络,通过CoDE策略对其进行优化。计算P中每个个体的目标函数J(X1),J(X2),…,J(XNP);具体的目标函数(最小化)为:
(2)
其中,Wij为输入层与隐含层之间的连接权值;Wjk为输入层与隐含层之间的连接权值;β为隐含层的阈值;γ为输出层的阈值。Wij,Wjk,β,γ为BP中需要优化的变量。yi为BP第i个节点的期望输出;oi为BP第i个节点的预测输出;m为网络节点个数。
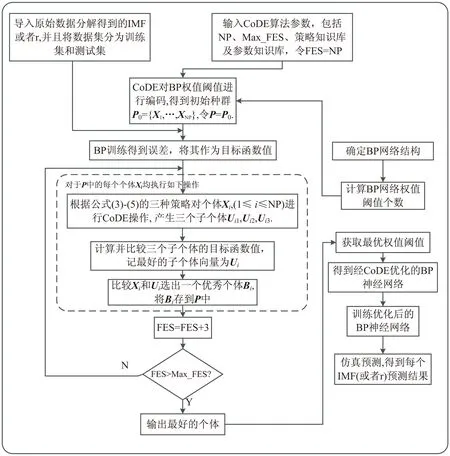
图2 CoDE-BP算法流程
Step4:根据式3~5的三种策略对每个目标向量Xi进行操作,产生三个子个体Ui1,Ui2,Ui3,其中三个个体分别由一种试验向量产生策略随机与一组控制参数结合而成。子个体产生策略如下:
(1)DE/rand/1/bin。
Ui,j,G=
(3)
(2)DE/rand/2/bin。
Ui,j,G=
(4)
(3)current-to-rand/1。
Ui,G=Xi,G+rand·(Xr1,G-Xi,G)+
F·(Xr2,G-Xr3,G)
(5)
其中,F和CR为控制参数,文中选取[1.0,0.1],[1.0,0.9]和[0.8,0.2]这三组参数。
Step5:分别计算三个子个体的目标函数值,即J(Ui1),J(Ui2),J(Ui3),选出最好的一个个体,标记为Ui。
Step6:比较Xi和Ui,选出一个优秀个体Bi存入到一代P中。
Step7:如此重复,直至满足算法终止条件,输出目标函数值最小的个体,得到BP神经网络最优的初始权值和阈值。
Step8:训练经CoDE优化过的神经网络,得到每个子序列的预测值。
Step9:利用测试集合,预测每个子序列和残差的结果,再通过等权求和作为最终的风速预测结果。
4 短期风速预测应用
采用国内某风电场的风速数据进行仿真实验,为了证明所提方法的可行性与有效性,分两个实验来进行仿真。实验一进行超短期(每隔10 min)风速预测,实验二进行短期(每隔1 h)风速预测,两种情况的原始风速如图3所示。可以看出风速具有极大的随机性、不稳定性和波动性。所提方法EEMD-CoDE-BP将与BP、WNN、ENN、CoDE-BP、EMD-CoDE-BP进行对比。所有实验均在Intel(R) Core(TM) i5-3210M CPU 2.50 GHz电脑的MATLAB R2016a上完成。

图3 原始风速(10 min和1 h)分布图
实验中,采用平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)及相关系数(R)作为评价指标。分别定义如下:
(6)
(7)
(8)
(9)
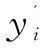
由以上公式知,MAE,RMSE,MAPE越小,R值越大,算法预测性能越好。
4.1 超短期(10 min)风速预测
实验数据来自国内某风电场2013年1月4号6:00到1月9号6:00每10 min间隔采样的721个风速数据。将数据集划分为训练集和测试集,前600个数据作为CoDE-BP神经网络的训练集,剩下271个数据作为测试集。使用前六个数据预测后一个数据,即利用前一个小时的数据提前预测后10 min的风速大小。
EEMD分解方法将原始风速序列分解为一系列IMF和残差序列r。实验中,设置白噪声标准差为0.1,添加噪声的总次数为200。不同的IMF呈现出不同的特征,IMF1和IMF2分量的频率要高得多,主要反映了原始风速信号中的随机信息。IMF3之后的分量周期性趋势比IMF1、IMF2更为显著,它们主要是原始序列的周期分量。经EEMD分解后序列更为平滑,使EMD存在的模态混叠问题得以改善,实现了非线性非平稳的原始风速序列向平稳序列的转化。
经EEMD分解后,用每个IMF分量和残差分量r训练CoDE-BP神经网络模型,CoDE-BP网络输入层、隐含层、输出层分别设置为6、10、1,最终的风速预测结果由单个IMF分量和残差分量r预测结果叠加得到。EEMD-CoDE-BP模型的风速预测结果如图4(f)所示。为了进行比较,传统的BP、WNN、ENN、CoDE-BP、EMD-CoDE-BP模型的风速预测结果分别如图4中(a)~(e)所示。另外,各个风速预测模型的评价指标在表1中列出。
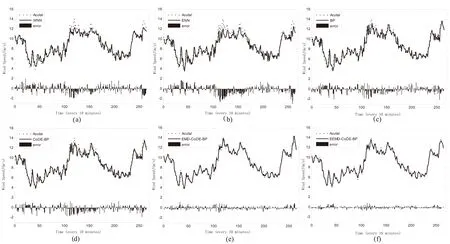
图4 风速预测结果(1)
从图4可以看出,EEMD-CoDE-BP比其他算法能更加精确地预测风速序列未来的变化趋势。而且,根据表1中的性能指标也可以得出同样的结果。换言之,所提出的混合模型比其他模型更适合短期风速预测。为了更深入分析模型,更多的分析如下:

表1 不同算法的风速预测结果(10 min)
(1)图4中,WNN、ENN、BP、CoDE-BP预测模型能对风速变化趋势进行较好的预测,但是预测结果并不令人满意。相比较而言,EEMD-CoDE-BP方法更好,预测结果更准确,能与实际风速更好的拟合。对比图4(e)与(f),虽然EMD-CoDE-BP算法得到了较好的预测结果,但是可以发现EEMD-CoDE-BP算法较EMD-CoDE-BP算法对原始风速序列的跟随性更好,因为EEMD避免了EMD的模态混叠问题,对非线性非平稳风速序列的分解效果更好。
(2)从图4中误差分布图(error=实际值-预测值)可看出,EEMD-CoDE-BP算法误差值在零值附近波动很小,其他算法的波动性大,充分说明该算法对风速预测准确性高,具有更大的优越性。
(3)对比BP、CoDE-BP、EMD-CoDE-BP、EEMD-CoDE-BP算法,可以明显看出EEMD-CoDE-BP算法优于其他算法,算法预测精度更高。例如,对于本实验的数据集,BP、CoDE-BP、EMD-CoDE-BP、EEMD-CoDE-BP算法的MAPE值分别为6.292%、5.952%、3.024%、2.257%。基于上述分析,可以得出结论:EEMD分解技术能有效地提高风速预测的精度。
4.2 短期(1 h)风速预测
短期风速预测实验中,数据集来自同一风电场2013年4月4号0:00到4月24号19:00每间隔1 h采样的500个风速数据,前350个数据作训练集,后150个数据作测试集。实验中,设置白噪声标准差为0.1,添加噪声的总次数为200,CoDE-BP模型的输入层、隐藏层、输出层分别设为3、5、1。传统的BP、WNN、Elman、CoDE-BP、EMD-CoDE-BP、EEMD-CoDE-BP模型风速预测结果分别如图5(a)~(f)所示。
图5 风速预测结果(2)
表2为不同风速预测模型详细的预测误差值。

表2 不同算法的风速预测结果(1 h)
续表2
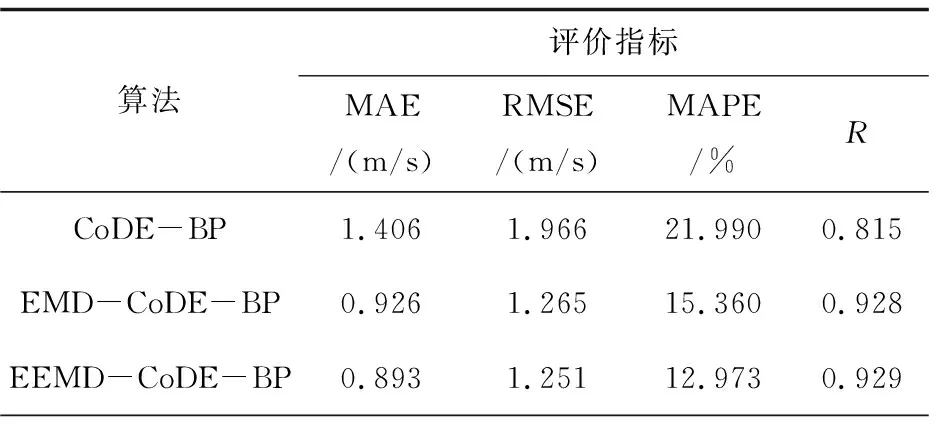
从图4和表2可以得出与超短期风速预测实验中类似的结论。值得注意的是,随着风速序列采样间隔的减小,预测精度也变得更大。例如,所提算法在10 min、1 h采样间隔的MAPE值分别为2.257%、12.973%。另外,风速的随机性非平稳性和不规则性以及不同的特征和不同采样间隔的两个数据集,不仅使上述两个实验的预测精度不同,也大大增加了预测的难度。然而,两个实验中所有的实验结果均表明,所提模型的准确性和稳定性要比其他对比模型更加优越。
5 结束语
通过对比传统的BP、WNN、ENN、CoDE-BP、EMD-CoDE-BP五种算法,证实了基于总体经验模态分解和CoDE-BP神经网络(EEMD-CoDE-BP)的风速预测方法不仅具有良好的拟合能力,而且具有较强的精度和处理非线性时间序列的能力,有效提高了风速预测的准确率。风速数据的采样间隔对风速的预测精度存在较大影响。总体而言,采样间隔越大,风速预测的精度越低,预测误差越大。优异的性能及合理的预测精度也揭示了该模型可以应用于其他预测领域,如电力负荷预测、交通流量预测等。基于总体经验模态分解和CoDE-BP的风速预测是机器学习领域的实例应用,预测问题也是计算机领域的一个重要分支。机器学习方法在各领域的应用,将不断推动计算机技术往智能化方向发展。
猜你喜欢
农业灾害研究(2022年9期)2022-11-19
农业技术与装备(2022年5期)2022-07-25
成都信息工程大学学报(2022年2期)2022-06-14
汽车实用技术(2022年10期)2022-06-09
昆明医科大学学报(2022年3期)2022-04-19
北京大学学报(自然科学版)(2022年1期)2022-02-21
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
现代农业科技(2018年11期)2018-08-14
