
基于双向消息链路卷积网络的显著性物体检测
2019-02-27 08:55申凯王晓峰杨亚东
智能系统学报 2019年6期
申凯,王晓峰,杨亚东
(上海海事大学 信息工程学院,上海 201306)
视觉显著性是用来刻画图像中的部分区域,这些区域相对于它们的临近区域更为突出。显著性模型可分为基于数据驱动的自底向上模型[1]和基于任务驱动的自顶向下模型[2]。Itti 等[3]提出的ITTI 模型模拟生物视觉注意力机制用于显著性检测。Liu 等[4]将显著性检测定义为二元分割问题引发了显著性检测模型的热潮。基于卷积神经网络[5-7]的显著性检测方法消除了对手工特征的需求,逐渐成为显著性检测的主流方向。显著性物体检测用于突出图像中最重要的部分,常作为图像预处理步骤用于计算机视觉任务中,包括图像分割[8-10]、视觉跟踪[11]、场景分类[12]、物体检测[13-15]、图像检索[16-18]、图像识别[19]等。
基于深度卷积神经网络,特别是全卷积神经网络(FCN),已经在语义分割[20]、姿态估计[21]和对象提取[22]等标记任务中表现出优异的性能。同时也推动了尝试使用FCN 解决显著性物体检测中显著性物体定位问题,虽然这些模型[5-6,23-24]在预测物体显著性的任务中有出色的高层语义提取能力,但是显著图缺少精确的边界细节,显著图无法保留精确的对象边界信息。这促使很多研究人员利用不同层级的特征的非线性组合进行显著性检测。Xiao 等[25]建议提取不同级别的显著图,并将其进行非线性融合得到显著图,使其获取高级语义信息的同时兼顾低级空间信息。Hou 等[26]建议在多个侧输出层之间添加短连接,用以组合不同级别的特征。Zhang 等[27]提出通过低级别的特征与高级别的特征进行聚合,生成多级特征。Jin 等[28]提出使用循环神经网络的方式将高级语义信息和低级空间信息相互传递,生成显著图。Chen 等[29]提出使用空间注意机制与通道注意力机制捕捉图片高级语义信息,但依旧存在边界信息缺失的现象,且对于背景抑制、实体镜像问题的处理还需要进一步提高。
为解决上述问题,本文提出了一种基于双向消息链路卷积网络的显著性物体检测方法。为了解决边界缺失问题使用设计一个具有跳过连接结构的上下文感知模块将高级语义与低级空间特征进行融合,对于每一个侧输出采用了空洞卷积获取每一个侧输出的更多的上下文信息。为了准确地定位显著性物体的位置信息以及减少无关通道对显著物体的高级语义与空间信息的影响,借助了空间注意力与通道注意力机制组成的注意力模块。为了更加有效地传递上下文语义信息,借助具有门控的消息传递通道,完成从高级特征到低级特征的传递。为了融合产生的多层特征信息,借助多尺度融合策略生成物体显著性预测图。本文将提出的BML-CNN 在6 个数据集上与13 种先进的显著性物体检测模型进行比较,实验表明BML-CNN 在不同的评价指标下均有最出色的表现,此外,模型的实时处理速度为18 f/s。本文的贡献主要分为以下三个方面:
1)使用由通道注意力与空间注意力组成的注意力模块来提取有效特征,可赋予有效通道、有效卷积特征更高的权值,减少背景对显著性物体预测的影响。
2)提出具有跳过连接结构的上下文感知模块与带门控函数的消息链路组成的双向消息链路,可在获取高级语义信息的同时,保留完整的边界信息。
3)借助多尺度融合策略将多级有效特征进行融合,可在不同角度产生对显著性物体的预测,并进一步融合不同尺度的信息生成具有完整边界的显著性物体预测图。
1 相关工作
本节将从3 个方面介绍相关工作。首先,描述特征传递在显著性检测中的应用。其次,描述了注意力机制在各种视觉任务中的应用。最后,介绍了多尺度融合在显著性物体检测任务中的应用。
1.1 特征传递
不同级别的特征传递是显著性物体检测任务中的一项重要工作,也促使很多研究人员探讨更优异的特征传递策略。例如,Wang 等[6]提出了使用双卷积神经网络,将局部超像素估计传递到高层卷积指导生成全局对象提议搜索的显著性物体检测。Jin 等[28]提出使用循环神经网络的方式将高级语义信息和低级空间信息相互传递,生成显著图。Long 等[30]借助跳过连接的方法,将高层语义添加到中间层,已生成多分辨率,多尺度的预测信息,并由预测信息生成像素的预测结果。Zhao等[19]通过融合全局和局部的上下文信息来预测每个超像素的显著度,并依据每个超像素的显著度生成显著对象的显著图。Lee 等[23]提出将降低级空间信息与高级语义信息进行传递并编码,并使用编码后的特征预测显著性图。Liu 等[24]建议使用分阶段检测物体的显著性,第一阶段使用卷积神经网络提取全局结构特征,并产生粗略估计,第二阶段融合策略,将本地上下文信息细化为显著图的细节,并与第一阶段产生的粗略显著图进行相互传递并融合得到精确的显著性图。Wang等[7]设计了全卷积神经网络(FCN),将粗略的显著性预测特征传递到高层,并逐步指导显著性图的生成。上述方法在实现特征传递过程中并没有考虑到高层语义对低层轮廓提取的影响程度,使得低层轮廓提取过于注重显著度高的位置,从而导致显著度较低的边缘信息保留不足。
为控制高层语义对低层轮廓提取的影响程度,提出使用带跳过连接结构与带门控函数组成的双向消息传递链路,在实现高层语义信息与低层轮廓信息相互传递的同时,能控制高层语义对低层轮廓提取的影响程度,达到高层语义有限指导低层轮廓的获取,低层轮廓信息为高层语义提供精确的空间信息。
1.2 注意力机制
视觉注意力机制是借鉴人类的视觉注意力机制,扫描全局图片获取需要关注的目标实体区域,并为这一区域投入更多的资源,可获取更为完善的关注目标的信息,而降低其他信息的影响。注意力机制在多个视觉任务中都有很出色的表现,例如,图像字幕[29,31]、视觉问答[32-33]、目标识别[19]和图像分类[34]等。Xu 等[35]首先提出了使用“软”和“硬”注意力机制解决图像字幕。Wang 等[34]提出使用一种残差注意力机制来训练深度残差网络进行图像分类。Chen 等[29]提出了一种SCACNN 网络,网络使用CNN 结合了空间注意力机制与通道注意力机制赋予各个通道和空间位置不同的权重,提高目标响应并降低背景的干扰。
在显著性物体检测时,并不是所有通道的卷积特征对显著性物体的预测都具有同等重要性,个别通道会存在背景的卷积特征,且在同一通道中不同位置的卷积特征也对显著性物体的预测产生影响。为更有利地获取有效卷积特征,进一步消除背景对显著物体的影响,本文采用通道注意力机制为不同卷积通道赋予不同权值,以降低含背景卷积信息的通道对显著性物体预测的影响,另外引入空间注意力机制来为同一通道上不同位置的卷积特征赋予不同权值,以进一步消除背景的影响。将空间注意力与通道注意力串联组成注意力模块以实现对物体的初步关注,并以渐进的方式指导下一层关注的提取,逐步消除背景对显著性物体预测的影响。
1.3 多尺度特征融合
从一些可视化深度卷积神经网络的工作[9-10,36-40]可以看出,不同层次的卷积特征是从不同的视角描述物体特征及其周围环境。高级语义有助于图像区域物体类别的识别,而低级视觉特征有助于保留空间细节,生成具有高分辨率的显著性图。然而如何有效地利用多尺度特征依然是一个值得探讨的问题。为此,已经有很多有价值的研究,例如,Li 等[5]通过使用先生成局部超像素估计,然后在多个CNN 中提取多尺度特征来预测物体的显著性。Zhang 等[27]提出Amulet 网络使用RFC 生成多分辨率的预测信息,并使用FS 进行多尺度融合,获得显著性的预测。Hariharan 等[22]提出使用Hypercolumn 方法,不仅融合了来自多个中间层的卷积特征,还学习了密集特征分类器。Badrinarayanan 等[11]采用编码器−解码器网络,使用池化引导反卷积模块多级卷积特征。Ronneberger 等[2]提出U-Net 网络,应用多个跳过连接结构来捕获上下文结构,并通过收缩路径和扩展路径融合多尺度卷积特征生成有精确定位的显著性预测图。
受到以上研究的启发,本文提出的方法中也使用跳过连接结构实现捕获上下文信息,并借助空洞卷积对上下文信息进一步提取,同时借助带门控的信息传递链路,实现高级语义与中间卷积特征的相互融合,这种融合是以阶段方式进行的,由跳过连接结构与带门控的信息传递链路组成了双向信息传递链路,有利于为显著性预测提供全面的信息。另一方面通过多尺度融合策略,为显著性预测提供不同视角的卷积特征,能够将低级的边缘感知特征与高级语义信息进行聚合,有助于保持对象边界。
2 算法模型
BML-CNN 模型使用含有注意力模块的特征提取模块来提取有效特征,借助双向消息链路实现高层语义信息与底层轮廓信息相互传递,融合上下文信息,最后使用多尺度融合策略,融合不同尺度的有效卷积特征,以实现物体的显著性预测。该模型具有出色的显著性预测能力,且边界保持较好。
2.1 通道注意力与空间注意力
通道注意力机制是调整特征通道对目标影响程度的方式,为有效的通道赋予更高的权重使其能对显著性对象有更高的响应,降低无效通道的权重使其能够降低对显著性对象预测的干扰。
将卷积特征用I∈RW×H×C表示,其中W×H×C表示卷积特征I的维度,用F={f1,f2,···,fC} 表示卷积特征I上的通道,其中fi∈RW×H,i∈{1,2,···,C}表示卷积特征I上的第i个通道,W表示宽,H表示高,C表示通道总数。用s∈RC表示通道权重向量,本文设计一个卷积层来学习每个通道的权值特征:

式中:WC表示卷积滤波器;bC表示卷积偏差。使用Softmax 激活函数获得最终的通道注意力向量

空间注意力机制直接使用卷积特征预测显著性往往可能由于非显著性区域所造成的噪音导致次优结果。空间注意力机制通过对每一个区域进行评估,为每一个区域赋予不同的权值,使得模型能够更加关注有助于显著性预测的有效信息。空间注意力机制可以突出显著性对象,减少背景区域的干扰。
使用I∈RW×H×C表示卷积特征,使用L={(x,y)|x=1,2,···,W;y=1,2,···,H} 表示卷积特征上空间位置,其中 (x,y) 表示空间上点的坐标。本文设计了一个卷积层来计算空间注意力特征图:

式中:m∈RW×H是包含所有通道的信息;WS表示卷积滤波器;bS表示卷积偏差。使用Softmax 激活函数获取每一个位置上的空间注意力权重。

式中:m(l) 表示空间注意力特征图m中第l个点,其中l∈L;aS(l) 表示第l个点的权值。令aS={aS(1),aS(2),···,aS(W×H)} 为空间关注图。
注意力模块使用通道注意力模块与空间注意力模块串联成注意力模块,结构如图1 所示。将注意力模块添加到带跳过连接的上下文感知模块,可从不同方向上减少背景区域的干扰,提高对显著性物体的预测,并精确的保留边界信息。

图1 注意力模块模型Fig.1 Attention module model
使用I∈RW×H×C表示输入注意力模块的卷积特征前半阶段为通道 注意力机制,后半段为空间注意力机制。令IC为经过通道注意力模块输出的卷积特征:

式中:aC(i) 表示第i层通道的通道注意力向量第i维参数,其中i∈{1,2,···,C}。将得到的卷积特征输入到空间注意力模块中得到ICS:

式中*表示Hadamard 矩阵乘积运算。得到的ICS是通过注意力模块的带权卷积特征,模型使用ICS指导下一层卷积对显著性物体特征的提取。
随着重庆自贸区的发展,自贸区的海关监管问题也越来越突出,就一般情况而言,自贸区货流量的增加,不仅伴随着经济的发展,还紧跟着大量法律问题特别是知识产权侵权问题的发生,加强知识产权的保护力度和相关法律法规的建设是当前自贸区海关监管面临的重大问题。
图1 中,左半边为通道注意力模块和式,右半边为空间注意力模块和式,其中I为输入和式,aC表示通道注意力向量和式由式(2)和式(3)计算得到。IC表示通道注意力模块的输出和式也是空间注意力模块的输入和式由式(7)计算得到。aS表示空间注意力权重和式,由式(5) 和式(6) 计算得到。IS表示空间注意力模块的输出和式,也是本文注意力模块的输出和式由式(8)计算得到。多层卷积之间添加注意力模块和式实现渐进式的注意力引导。每一层的注意力信息可指导下一层的训练,以自适应的方式生成新的注意项和式使得上下文信息实现由粗至简的细化过程。
2.2 双向消息链路
双向消息链路由带有跳过连接结构的上下文感知网络与带有门控函数的信息传递链路组成。带有跳过结构连接结构的上下文感知网络用来提取高级的语义信息,而带有门控函数的信息传递链路将高进语义信息和中间卷积特征指导低级空间信息提取。使得送入多尺度融合模块的不同尺度的特征图均具有完整的空间信息和语义信息,为最终的融合提供有效、可靠的输入源。
如图2 所示,带有跳过连接结构的上下文传递模块,“Conv5”是对原始图片的特征提取,使用跳过连接结构将原始图片,与语义特征一起作为新的卷积层的输入,实现上下文传递,并使用后续的卷积将低级空间特征与高级语义相融合,使得显著性特征具有比较完备的边界信息和高级语义信息。另外,注意力机制的加入减少了背景对显著性物体预测的影响。

图2 带跳过连接的上下文传递模块Fig.2 Context transfer module with skip connection

其中att_conv5 为“Conv5”通过注意力模块Atten的输出,具体计算方法由2.1 节给出。 Upi,i∈{1,2,3,4,5} 表示图2 中上采样的输出,ui为大小分别为{16×16,8×8,4×4,2×2,1×1} 的上采样内核。

式中:K表示大小为 3×3 的卷积核, C oncat 表示通道连接,U pi-5由式 (9) 和式 (10) 计算得到。式 (11)中卷 积 的 激活函数均为Relu。 ati表示 co nvi通 过注意力模块的输出。
如图3 所示,本文使用带门控函数的信息传递链路将高级语义信息与中间层卷积特征相融合,因为并不是所有的中间层都对物体显著性的预测是有帮助的,所以借助门控函数产生[0-1]的权值向量,控制高层卷积特征对低级卷积特征的影响程度,从而每一层都是由上一层加权并与本层特征融合的结果,使得每一层都有在上一层高级语义的指导下选择本层的空间特征,从而产生不同级别、不同尺度、不同视角的显著性预测先验信息,为进一步的多尺度融合提供比较全面的特征信息。

图3 带门控函数的消息传递模块Fig.3 A messaging module with gated functions
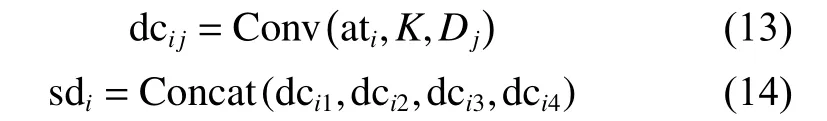
式中: dcij,i∈{1,2,3,4,5},j∈{1,2,3,4} 表示空洞卷积的输出;卷积核K的大小均为 3×3;Dj表示大小分别为1、3、5、7 的dilation rate; sdi表示融合空洞卷积的输出,i∈{1,2,3,4,5}。

式中:门控函数由G表示;Ki、Ki1和Ki2均表示大小为 3 ×3 的卷积核;Si则表示双向消息链路的侧输出。
2.3 多尺度特征融合策略

其中, Up 表示上采样操作;ui分别表示大小为{1×1,2×2,4×4,8×8,16×16} 的采样内核。
如图4 所示,将式 (18) 计算得到的5 个分层特征映射 S mi输入到特征融合策略,生成最终的显著性预测图。

图4 多尺度融合策略Fig.4 Multi-scale fusion strategy

式中:K1、K2和K3分别表示大小为 3×3 、 3 ×3、1×1 的卷积核;激活函数分别为Relu、Relu、Sigmoid; pre_gt 为模型最终的输出,也是物体的显著性预测图。
BML-CNN 模型结构由图5 给出,通过带有注意力机制的基础特征提取层,提取有效高级语义信息,并结合带有跳过连接结构的上下文传递与带门控的消息传递链路组成的双向信息传递模型完成有效消息的双向传递,使各层具有不同角度语义信息的同时保留完整的边界信息。最后使用特征融合策略将各层卷积特征相融合,生成最终的显著性物体预测图。

图5 双向消息链路卷积网络的结构图Fig.5 Structure diagram of bidirectional message link convolution network
3 实验
3.1 实验设置
数据集:该模型使用DUTS-TR 数据集[19]作为训练集,数据集包括10 553 张图片,为了使模型获得更好的训练效果,使用了数据增强策略生成了63 318 张图片作为训练图片。为了评估模型,本文使用了以下6 个标准数据集作为模型先进性验证:DUTS-TE 数据集[19],该数据集具有5 019 个具有高像素注释的测试数据集。DUTOMRON 数据集[41],该数据集有5 168 个高质量的图像,数据集中的图像具有一个或多个显著性对象和相对复杂的背景。ECSSD 数据集[31],该数据集具有1 000 个图像,在语义上具有比较复杂的分割结构。HKU-IS 数据集[19],该数据集具有4 447幅图片,具有多个不相连的显著性对象。PASCAL-S 数据集[42],该数据集是从PASCAL VOC 数据集[43]中挑选的,具有850 张自然图像。
实现细节:本文提出的算法使用Keras 实现,前13 层卷积使用VGG-16 预训练参数进行初始化,其他权值的初始化采用Xavier[44],初始学习率为10−5,权重衰减为0.000 5,输入图片大小为256×256,训练集采用DUTS-TR,并使用数据增强。在训练模型时模型共进行了150 次迭代,训练用时29 个小时。对本文模型进行测试时,实时处理速度为18 f/s。源代码可在:https://github.com/yshenkai/SOD 中下载。
评价指标:为了评估本文模型,借助了PR 曲线、F-measure 值和平均绝对误差MAE 3 个指标将本文模型与其他的13 个先进的模型相比较。

其中令β2= 0.3,Precision 表示准确率;Recall 表示召回率。使用Fβ作为评价指标的目的在于消除Precision 与Recall 之间的矛盾,可综合评价模型的优劣。除了Fβ和PR 曲线,还计算了平均绝对误差(MAE)来测量预测的显著性图与真实显著图之间的差异。

式中:W、H分别为输入图片的宽和高;S(x,y)表示在 (x,y) 点上的显著度预测;G(x,y) 表示在该点真实显著度值。使用MAE 作为评价指标的目的在于能够比较直观地反映预测值与真实值之间的偏差。在本文中W=H=256。
3.2 性能比较
本节使用了上述的评价指标将BML-CNN 模型与其他13 个先进模型BL[45]、KSR[46]、DRFI[47]、LEGS[6]、MDF[5]、ELD[23]、DS[48]、MCDL[19]、DCL[49]、RFCN[7]、DHS[24]、UCF[40,50]和Amulet[27]进行比较,同时为了实验的严谨性,使用了作者推荐的参数设计和其提供的源码或者直接利用作者提供的显著性图。
表1 中MAE 与F-measure 是14 个 模 型 在6 个标准数据集上计算而来,前三好的结果分别以红色、绿色和蓝色标注。可以看出本文所提出的模型在以上数据集中表现极为出色。

表1 14 个模型的MAE 和Fβ 对比Table 1 MAE and F-measure were compared in 14 models
定量比较:由表1 可以看出本文提出的模型BML-CNN 在数据集DUTS-TE、DUT-OMRON、HKU-IS、THUR15K、PASCAL-S 上MAE 降低了5.97%、21.35%、5.77%、13.41%和10%,在Fβ指标上分别提高了4.69%、7.02%、2.23%、8.62% 和3.88%。在数据集ECSSD 上BML-CNN 比Amulet 的MAE 高了3.28%,但BML-CNN 却在Fβ比Amulet 高了1.26%。由图6 中PR 曲线可以看出本文提出的BML-CNN 模型在数据集DUTS-TE、THUR15K、ECSSD 上,具有更高的召回曲线,表明在这3 个数据集中,模型BML-CNN 表现得比其他13 个模型更加出色。


图6 14 种 显 著 性 检 测 方 法 在ECSSD、HKU-IS 和THUR15K 上的PR 曲线比较Fig.6 PR curves of 14 saliency detection methods on DUTS-TE, THUR15K and ECSSD were compared
如图7,第1 行表示输入的图片,可以看出,本文提出的BML-CNN 模型在显著物体预测和边界保持中均优于现有的Amulet 和UCF 方法,此外在处理含有倒影的图片(例如图7 中第5 幅图片),BML-CNN 模型具有更高的鲁邦性。
定性比较:在HKU-IS 与DUTS-TE 两个数据集上,使用13 个模型中表现比较出色的Amulet 与UCF 模型给出的显著性预测图进行比较,为防止模型对特定显著性物体出现过拟合,选取具有不同显著性物体来进行比较。如图7,从第一幅图片可以看出,在动物显著性预测时本文模型比其他模型保留了更多实体的信息,且边界保持较好,从第3 幅图片中可以看出,注意力机制的应用消除了更多背景的影响,实现了更准确的预测。从第4 幅图中可以看出,使用更有效的高层语义与底层轮廓传递策略,可在显著性预测时保留更加完整的边界信息。从第5 幅图片中可以看出,注意力机制和高层语义与低层轮廓传递策略在处理镜像实体的问题中表现出更高的鲁棒性。

图7 物体显著性预测图对比Fig.7 Object saliency prediction graph comparison
4 结束语
本文提出了结合注意力机制与多尺度融合的双向消息传递链路显著性目标检测算法,首先通过带有注意力模块的特征提取层获取有效高层语义信息,然后通过双向消息传递链路实现高层语义与底层轮廓的双向传递,最后通过多尺度融合策略实现多层不同尺度的卷积特征的融合,从而产生显著物体的预测图。与现有算法相比,BMLCNN 模型的性能在不同数据集上均获得较高的提升,在边界保持、抑制背景噪声和镜像实体的处理等问题上都有最优异的表现。
模型虽然在复杂背景下的表现比较出色,也有很好的边界保持。但是该模型对于镜像实体问题(如倒影、镜中映像) 的处理尚未达到最优效果,接下来可以针对镜像实体问题来优化模型。此外,注意力模块与带门控函数的消息传递链路的引入导致网络实时处理能力下降,如何同时提高预测效果和实时处理能力值得进一步研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
开放教育研究(2020年2期)2020-03-31
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国修辞(2017年0期)2017-01-31
第二课堂(课外活动版)(2016年2期)2016-10-21
