
易变数据流的系统资源配置方法
2019-02-27 08:56王春凯庄福振史忠植
智能系统学报 2019年6期
王春凯,庄福振,史忠植
(1.中国再保险(集团)股份有限公司 博士后科研工作站,北京 100033; 2.中国科学院 计算技术研究所,北京 100190)
日前,许多应用需要大规模的连续查询和分析,如:社会网络中的微博分析、金融领域中的高频交易监控,以及电子商务中的实时推荐等[1-3]。这些应用往往需要快速响应用户提交的查询请求,要求大规模数据流管理系统对数据流的查询处理具有较高的吞吐率和较低的处理延迟。这往往需要用户预先设置相关的系统参数,如查询算子的并行度、查询进程的内存使用率等。然而,由于数据流的易变性和查询任务的不同,为确保实时处理查询请求的同时尽量减少资源使用情况是一个非常有挑战性的问题。接下来举例说明该问题的普遍性。
我们以交通监控系统实时分析路况为例,使用流处理系统Storm[4]和轨迹数据集GeoLife[5]实现如下查询任务。查询包含一个映射处理逻辑,用于接收由GPS 设备采集的轨迹数据,并通过函数映射找到使用该GPS 设备的对象所在的道路信息。此外,包括一个测速处理逻辑接收来自映射处理逻辑发送的数据,并实时计算出不同道路上的各GPS 设备对象的平均行驶速度。
然而,配置查询任务的参数不能动态感知数据流的变化,导致了查询延迟的增加和系统资源的浪费。为应对此问题,文献[6-7]已进行了相关研究。但是,文献[6]需要重启查询任务,数据阻塞和查询延迟的问题较为突出;文献[7]通过保存状态信息避免了查询任务的重启操作。然而,针对流速频繁改变的易变数据流,文献[6-7]均会导致系统延迟的缓慢增加,以至于超过用户自定义的查询延迟阈值。为此,本文提出了应对易变数据流的系统资源动态配置方法OrientStream+。与文献[6-7] 提出的OrientStream 相比,Orient-Stream+可较好解决易变数据流的资源配置问题,进一步降低流处理系统的查询延迟并提高系统的吞吐率。
针对系统资源动态配置的相关工作可总结为如下3 个方面:
1) 动态加载调度策略。Aeolus[8]是柏林洪堡大学和惠普实验室联合研发的Storm 优化器,用于动态设置算子的并行度和节点内部数据的批量大小。Aeolus 定义了处理单条元组所需时间的代价模型,其中包括元组的传输时间、等待时间、计划处理时间和实际处理时间。依据该模型,针对不同的查询请求和数据流特征(如数据流速、数据分布情况等),Aeolus 可计算出算子并行度和数据批量传输大小的最佳配置样式。为避免资源浪费或无法实时获取正确的查询结果,FU 等[9]设计了基于云环境的大规模数据流管理系统的动态资源调度器。该调度器借助开放排队网络[10]理论来度量已使用资源和查询响应时间的关系、制定最佳资源配置方案以及使用最小开销测量系统的负载等。Aniello 等[11]针对Storm 平台,利用基于拓扑的策略和基于流量的动态调度策略设计了两个调度算法,以降低元组处理的延迟时间和减少多个拓扑节点间的传输流量。然而,Aeolus 和DRS 需要明确每个算子的具体处理时间,并且仅用于固定的查询应用场景。文献[11]仅考虑传输延迟,而未关注资源使用的情况,并且不能对算子的并行度做动态调整。
2) 机器学习技术。文献[12]提出了一种基于混合密度网络[13]的模型来评估数据流处理任务的资源使用情况。该模型可帮助用户判断是否向流处理系统提交新的查询任务。ALOJA 项目[14]针对Hadoop[15]的执行情况开发了开源平台用于预测查询任务的执行时间和异常监控。ALOJA是基于ALOJA-ML[16]设计的框架,ALOJA-ML 利用机器学习技术分析了运行在Hadoop 上的不同查询任务的基准性能数据,并以此支持查询任务的性能调优。Jamshidi 等[17]设计了一种自动优化流处理系统参数配置的贝叶斯优化算法BO4-CO。以MySQL 和Postgres 为实验平台,Otter-Tune[18]利用经验数据的监督学习方法和新搜集信息的非监督学习方法,针对不同查询请求选择出对系统性能影响最大的参数,并通过历史查询任务对新的查询任务进行预测,利用深度学习框架TensorFlow[19]向用户推荐最佳参数配置。然而,文献[12]不能动态改变流处理系统的调度策略和各个算子的并行度,且不可以预测系统资源的使用情况。ALOJA-ML 框架仅可预测Hadoop的处理平台,OtterTune 系统仅可预测数据库管理系统,均不能用于数据流的查询场景。BO4CO 只能以流处理系统的历史数据作为训练集,不能对新收集的性能数据作增量分析。
3) 针对关系查询系统的资源预测。正如我们所知,关系查询系统往往具有类SQL 的查询接口。因此,有些研究也致力于检测SQL 查询的资源消耗。针对微软的SQL Server 数据库的不同查询请求,Li 等[20]设计了两种特征抽取的机制用于预测SQL 查询的资源消耗情况。两种特征包括粗粒度的全局特征和细粒度的算子特征。Akdere 等[21]为预测不同查询计划的查询性能,构建了3 种层次模型:查询计划层模型、算子层模型和针对嵌套查询的混合模型。然而,模型[20-21]仅考虑了静态特征的选择过程,不能对系统进行动态监控,并且没有考虑位于关系查询系统下面的数据处理系统的有关特征。
本文提出的OrientStream+框架不同于以上工作。OrientStream+构建了以延迟阈值为间隔片段的微批量样式(mini-batch scheme)的数据流传输机制,利用多级别管道缓存计算出精准查询结果,并提出异常检测的增量学习模型ODRegression (outerlier detection regression),可较好解决易变数据流的资源配置问题。
1 基本概念与问题描述
1.1 概念描述
OrientStream+需要实时监控大规模数据流管理系统的查询执行情况,并基于不同的数据流速和参数配置搜集训练数据集。接下来,我们给出形式化的定义。
由于数据流无限的特性,本文采集训练数据集的过程使用窗口模型(见定义1)。
定义1窗口模型。将无限的数据流切分成若干有限子数据流,每次的查询处理仅针对当前窗口内的子数据流。一般可根据用户设定的时间间隔或窗口内元组数量设置窗口大小,并在多查询场景下使用翻转窗口或滑动窗口的语义信息。
在OrientStream+框架中,我们使用基于时间间隔的窗口模型获取训练集。每个具有不同时间间隔的窗口作为一条训练数据。训练样本搜集过程中,时间窗口的下限是30 s,上限是120 s。首先,以初始的参数配置启动查询请求,当窗口大小达到时间间隔约束时,我们采集一条训练数据。接下来,以新的窗口大小和新的参数配置重启查询请求,用于获取下一条训练数据。最后,通过迭代操作,我们可采集到不同窗口大小和配置信息的训练数据集。
定义2算子并行度。构建在分布式集群上的流处理系统往往可同时执行由不同类型算子构成的若干拓扑任务。每个算子可根据不用的查询请求设置不同的并行度,一般以多线程的形式实现。以本文使用的Storm 系统为例,可动态设置数据源部件spout 和查询处理部件bolt 的单元实例task 的并行度。
定义3系统处理延迟。每个数据流元组
被各个查询算子处理延迟的总和。数据源i的处理延迟表示为每个单元实例处理延迟的平均值,形式化定义为

式中:m是数据源(source)节点的并行度。然而,由于查询请求往往涉及到多个数据流,因此,大规模数据流管理系统的处理延迟需要按照每个数据源的最大处理延迟来定义,形式化定义为
式中n是查询请求中涉及到的数据源个数。
定义4参数配置。向流处理系统提交查询任务时,需提前定义进程的内存大小、不同算子的并行度等参数信息。该过程称为系统资源的参数配置。
1.2 问题定义
向大规模数据流管理系统提交查询请求时,往往需要凭借用户的经验和平台的硬件情况动态配置不同的参数。参数配置是否合理将直接影响系统的吞吐率和处理延迟,以及平台的资源使用情况。随着数据流的变化情况,我们需要动态调整参数配置以满足用户对处理延迟和系统吞吐率阈值的要求。但是,流处理系统往往不允许任意调整配置参数。比如,Storm 的“re-balance”机制,仅可降低处理单元的并行度,不能超越用户设定的最大处理单元实例值。
我们需要对任意的参数配置预测资源使用情况、处理延迟和系统吞吐率。根据预测结果,从中选取最优配置。即,在保证处理延迟和系统吞吐率满足用户设定阈值的前提下,尽量减少CPU和内存的资源使用率。该问题可形式化表示为资源使用最优化的问题,定义如下。
令N=(n1,n2,···) 为集群的各个节点集合,每个节点ni关于CPU 使用情况Ucpu和内存使用情况Umemory可用式(3)表示。
式中:α和β分别是CPU 和内存使用率的权重。本文中,α和β均设置为50%。
接下来,令C=(c1,c2,···) 为用户提供的候选配置集合。对整个集群来讲,我们需要预测出最佳的配置copt以实现式(4)的优化目标。



式中:R(latency)和R(throughput)是查询请求的处理延迟和吞吐率;T(latency)和T(throughput)是用户设置的对应阈值。
2 系统设计
2.1 OrientStream+概述
如图1 所示,给出了OrientStream+系统的架构图。该系统主要分为3 个部分:左部是层次性的特征抽取机制,从下向上主要分为3 个部分即硬件集群层特征集、流处理系统算子层特征集,以及流查询系统的查询计划层特征集;中部是对n个数据流以微批量的处理方式,通过模型预测获取m个参数配置,并将相同参数配置的子数据流存放至同一个Kafka[22]消息队列中。右部是查询监视器(query monitor),主要负责采集特征数据并通过增量学习模型预测系统资源的使用情况,可从候选配置项集中预测出最佳配置和异常警告。
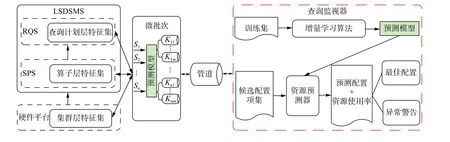
图1 OrientStream+系统架构图Fig.1 OrientStream+ architecture
2.2 微批量数据样式传输
由于频繁设置系统的参数配置会导致处理延迟的不断增加,所以引入Sax 等在文献[23]中提出的批量层次策略,以用户设置的查询延迟阈值为滑动窗口大小,在Storm 系统上使用该策略实现窗格内数据的微批量处理。
2.3 资源配置策略
2.3.1 多管道数据缓存
根据微批量数据传输模式,我们以用户定义的延迟阈值为微批量传输的窗口大小。如图1 中间部分所示,窗口内的微批量数据首先通过增量学习的模型进行参数配置的预测,依次记录需要调整配置的次数c1、c2、···、cn。针对不同类型的查询请求,现场调整机制下,以文献[7]的实验结果所示,拓扑任务的调整延迟在100~300 ms 之间。本文中,我们以上限300 ms 当作单次调整的延迟,设计了多管道数据缓存算法MPDC(multiple pipeline data cache),如算法1 所示。
算法1MPDC 算法
输入用户自定义阈值Tthreshold;单次调整延迟阈值Lthreshold;
输出多个子管道m。
1)nprediction= 模型预测需要调整配置的次数;
2)nmax=Tthreshold/Lthreshold;
3) if(nprediction>nmax)
4)ndiff= 统计不同的参数配置个数;
5) if(ndiff 6)m=ndiff; 7) else 8)m=nmax; 9) 选取并行度最高的nmax个配置; 10) 随机向m个子管道分发并行度低的ndiff−nmax个子数据流; 11) end if 12) end if 算法1 首先以用户定义的延迟阈值作为微批量传输的窗口大小,在窗口内使用增量学习模型预测出需要调整参数配置的次数nprediction(行1),根据用户定义的延迟阈值和单次调整拓扑结构的最大阈值,我们可计算出数据传输子管道的最大值nmax(行2)。在调整次数nprediction大于子管道最大值nmax的情况下,需要统计出nprediction个调整次数中不同的参数配置个数ndiff(行4)。如果参数配置个数ndiff小于子管道最大值nmax,则根据不同的配置参数,将数据流划分至ndiff个子数据流进行处理(行5~6)。如果参数配置个数ndiff大于子管道最大值nmax,则首选选取并行度最高的nmax个配置参数,并将余下的ndiff−nmax个子数据流随机向nmax个子管道中发送并进行处理(行7~10)。此时,按照并行度高的参数配置策略,在消耗部分过多系统资源的情况下,可满足用户定义的延迟阈值。 2.3.2 精准查询处理 由于我们使用子管道的数据处理方式,数据流通过MPDC 算法后,各个子管道内的数据流并非按照时间顺序排序。因此,我们需要完成原始数据流的精准查询处理。如图2 所示,我们在流处理系统之上构筑基于元组时间戳的映射函数,将不同子管道数据流的处理过程通过哈希映射后,确保输出精准的查询结果。 图2 映射过程Fig.2 Mapping process 2.3.3 增量学习模型 利用预测精度最高的4 个模型(贝叶斯模型[24]、Hoeffding 树模型[25]、在线装袋模型[26]和最近邻模型[27]),文献[7] 给出了集成学习方法EDKRegression。但是,在增量学习过程中,由于训练数据的动态变化和分布的不均衡性,导致个别模型的预测精度和实际值偏差较大。为此,本文在EDKRegression 算法的基础上,提出了异常检测回归模型ODRegression (如算法2 所示)。 算法2ODRegression 算法 输入4 个学习模型对样本n的预测值P1、 P2、P3、P4; 输出样本n的预测值 1)E= 模型预测值的均值; 2)δ= 模型预测值的方差; 3) for (i=1;i= 4) if(|Pi-E|>δ) 5) 移除第i个预测模型; 6) end if 7) end for 8) 调用EDKRegression[5]算法计算预测值; 首先,根据4 个预测模型对样本n的预测值P1、P2、P3、P4,算法计算出预测值的均值E和方差δ(行1~2)。然后,如果模型预测值Pi与均值E相差的绝对值大于方差δ时,利用行4 的公式移除偏移较大的预测模型。最后,针对过滤后的预测模型,调用集成回归模型EDKRegression 算法,计算出样本n的最终回归预测值。通过回归模型的异常检测,可进一步提高集成学习模型的预测精度。 1) 实验环境。本文实验平台用1 GB 网络连通14 个物理节点,其中5 个是使用Kafka 的数据发送节点,1 个是Storm 的nimbus 节点,其余8 个是Storm 的supervisor 节点。数据发送与nimbus各节点配置如下:CPU 为Intel E5-2620 2.00 GHz,Memory 为4 GB。supervisor 各节点配置如下:CPU 为两颗Intel E5-2620 2.00 GHz,Memory 为64 GB;操作系统为Ubuntu-14.04.3;Storm 版本0.9.5。 2) 查询任务。我们依据不同的查询特征,分别选取了3 个查询任务。 ① 交通监控(traffic monitoring,TM)。此查询任务的细节请参见第1 节相关内容。 ② 单词计数(word count,WC)。统计不同语句中各个单词的出现频率。该查询任务包含一个将句子切分成单词的处理逻辑,和一个使用哈希映射来统计单词出现频率的处理逻辑。我们使用HiBench[28]提供的单词计数数据集,共涉及300 万个句子和超过3 000 万个单词。 ③ TPC-H(Q3)。TPC-H[29]是一个决策支持基准,其包含的查询和数据具有广泛的行业相关性。为验证多个数据流的查询处理过程,选择Q3 作为第3 个查询任务。Q3 共包括3 个过滤数据源的处理逻辑,两个做等值连接的处理逻辑,一个对连接结果做分组的处理逻辑,以及一个对分组结果进行排序的处理逻辑。在查询任务的执行过程中,对每个数据源各取1 500 万个元组。 3) 数据规模。为保证模型预测的准确性,针对每个训练样本,计算窗口时间内CPU 使用率、内存使用率、处理延迟和吞吐率的平均值。对于每个查询任务,通过随机设置数据速率和30~120 s内的动态窗口大小,分别采集3 000 个训练样本。 通过利用微批次的处理方式,OrientStream+应对易变数据流的效果显著,处理数据的延迟和吞吐率情况均优于Storm 和OrientStream。 这里使用3 个不同类型的查询任务,对比了OrientStream+和OrientStream 的延迟与吞吐率。如图3 所示,随着数据流速的频繁变化,由于频繁调整系统的参数配置,OrientStream 的查询延迟不断增加,超过了用户自定义阈值。OrientStream+利用多管道数据缓存的策略确保了查询任务的延迟低于用户自定义阈值。同时,如图4 所示,OrientStream+的系统吞吐率在满足用户定义阈值的前提下,均高于OrientStream 的系统吞吐率。 关于资源使用的回归模型预测,我们使用EDKRegression[7]和ODRegression 两个模型。针对不同的查询任务,表1 和表2 分别给出了使用不同模型的测试结果,包括平均绝对误差值(mean absolute error, MAE)和相对绝对误差值(relative absolute error, RAE)。 图3 不同查询任务的延迟Fig.3 The latency of different workloads 图4 不同查询任务的吞吐率Fig.4 The throughput of different workloads 表1 预测CPU 使用情况的MAE 和RAE 值Table 1 Mean and relative absolute error per method for CPU usage prediction 表2 预测内存使用情况的MAE 和RAE 值Table 2 Mean and relative absolute error per method for memory usage prediction 根据该实验结果,可以得出如下结论: 1)预测内存使用情况的相对绝对误差(RAE)的平均值比预测CPU 使用率的略低,这是因为内存使用率的波动幅度没有CPU 使用率的波动幅度大。 2)在不同查询任务下预测CPU 的使用情况,ODRegression 模型优于EDKRegression,其中,平均绝对误差值(MAE)可降低0.3~0.37,相对绝对误差值(RAE)可降低4.4%~5.8%。在预测内存使用情况方面,ODRegression 模型也优于EDKRegression,其中,平均绝对误差值(MAE) 可降低0.2 9 ~0.3 3,相对绝对误差值(R A E) 可降低2.5%~5.6%。 根据增量学习模型的预测结果和在线参数配置策略,我们监控了3 个查询任务的整体执行过程。如图5 和图6 所示,相对于固定参数配置的查询过程而言,ORDegression 算法分别可节省10%~16%的CPU 使用率和32%~45%的内存使用率。相对于使用EDKRegression 算法的参数配置策略而言,ORDegression 算法分别可节省1.6%~4.3%的CPU 使用率和4.5%~8%的内存使用率。 图5 CPU 使用率Fig.5 The usage of CPU 图6 内存使用率Fig.6 The usage of memory 为应对易变数据流的查询请求,频繁改变资源配置会导致系统处理的延迟增加,降低系统性能。针对此问题,本文提出了OrientStream+框架。根据用户自定义数据处理的延迟阈值,设定以阈值为间隔片段的微批量样式的数据流传输机制;并利用多级别管道缓存,对相同配置的数据流进行批量处理,再按照数据流的时间戳,获取精准查询结果;根据训练数据的持续增长和动态变化的特性,引入具有异常检测功能的增量学习模型,用于进一步提高OrientStream+的预测精度。最后,我们在Storm 上实现了上述资源配置框架,并进行了大量的实验。实验结果表明,本文所提出的OrientStream+框架可在显著降低系统资源使用的情况下,进一步降低系统的处理延迟并提高系统的吞吐率。 针对窗口内的易变数据流,文本利用多级缓存和增量学习的方法以获取较优解。接下来,根据速率无重复波动的频繁变化问题,我们需要设计更加高效的数据缓存策略,使系统更加稳定和健壮。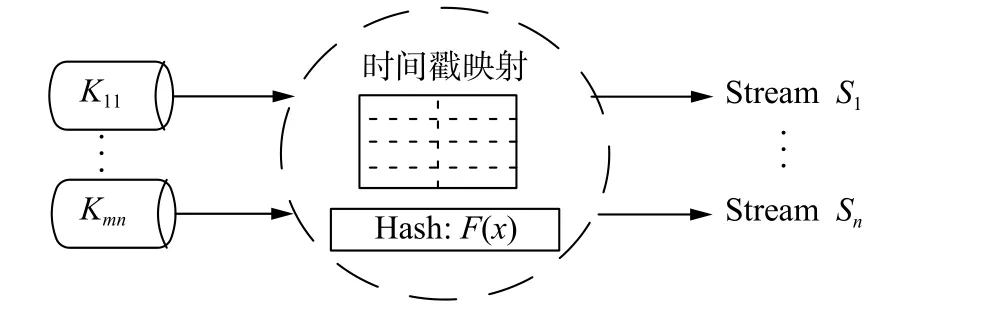
3 实验与结果分析
3.1 实验准备
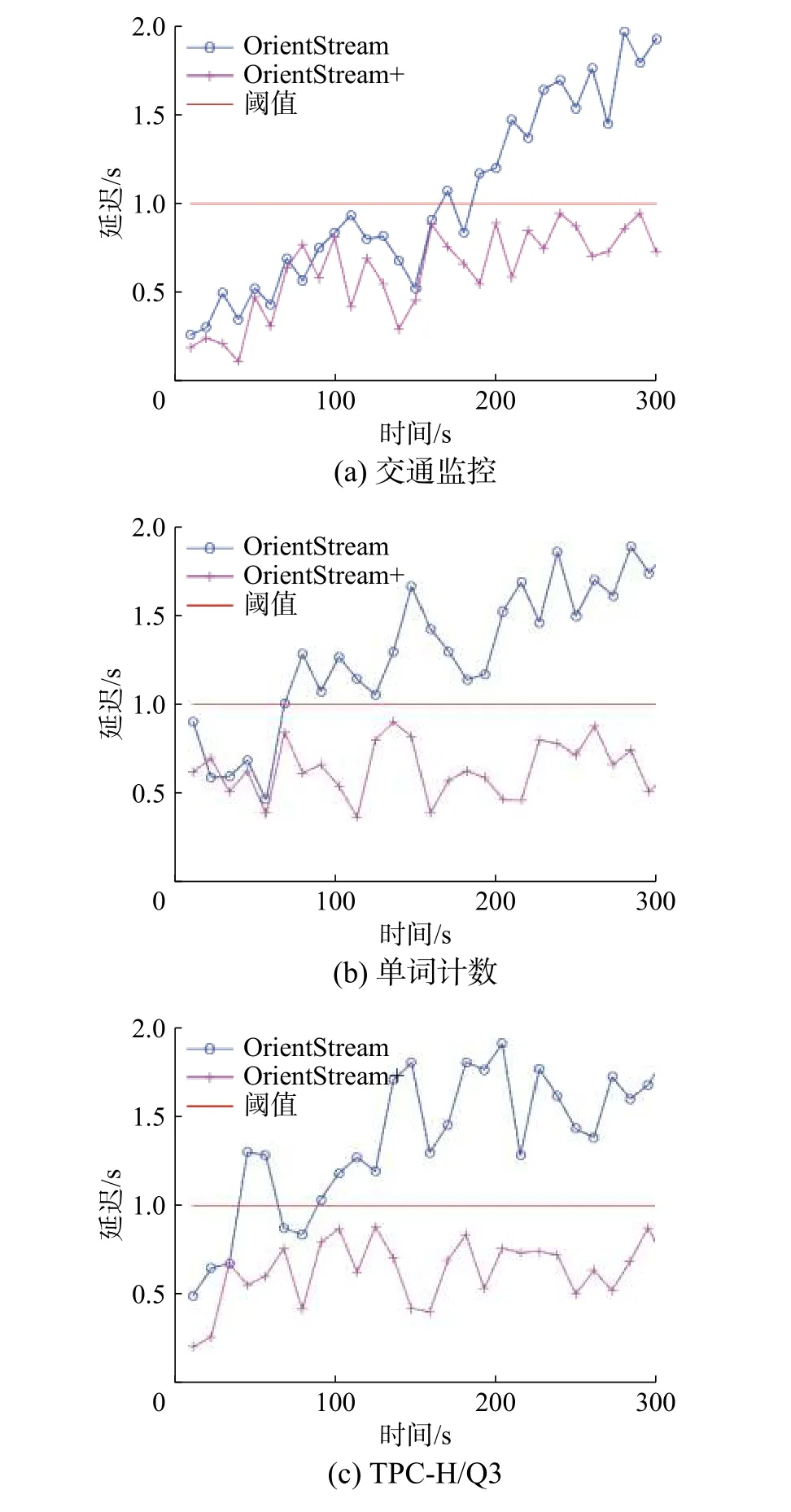
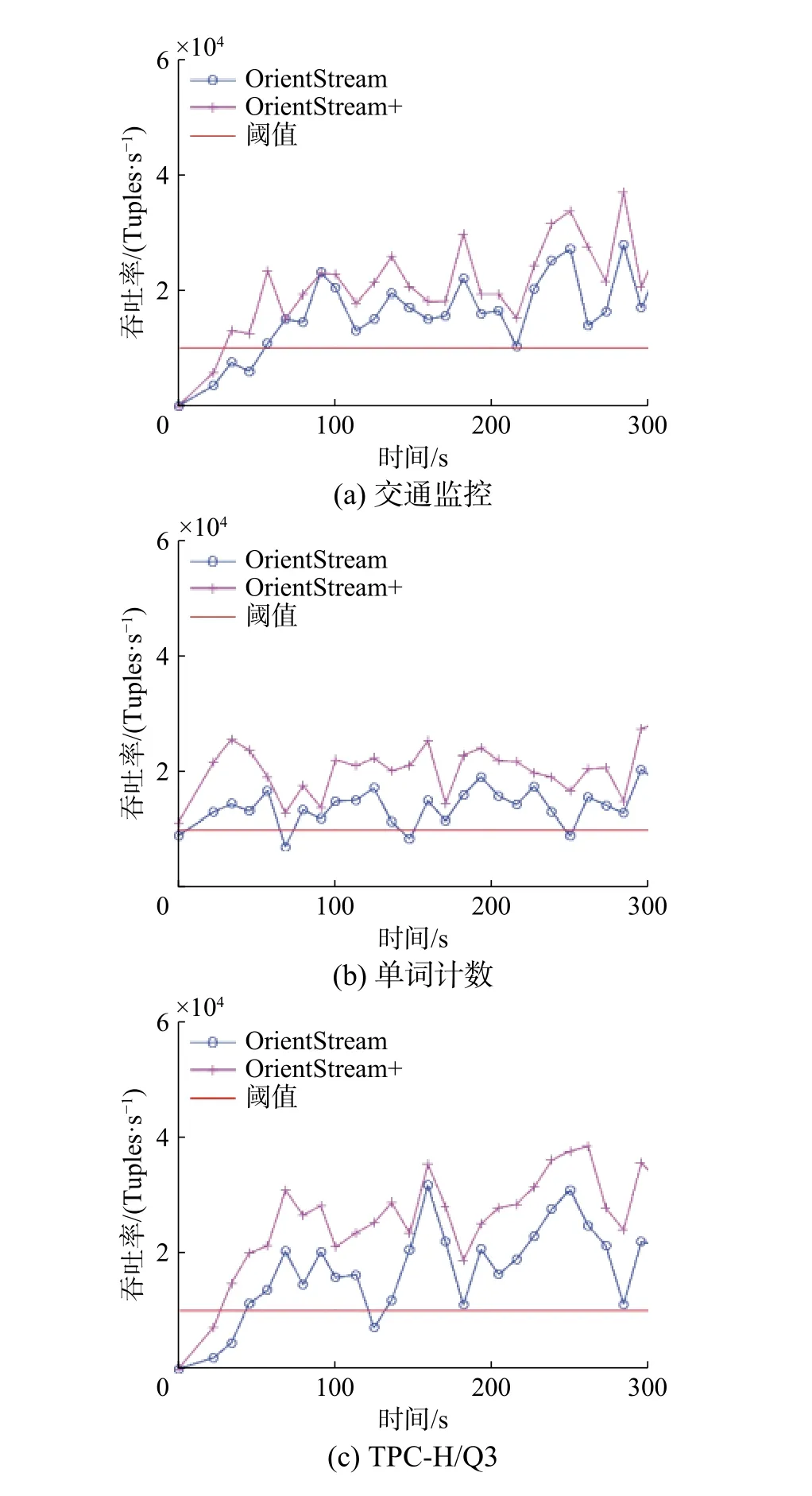
3.2 延迟与吞吐率
3.3 在线资源预测


3.4 动态资源配置


4 结束语
猜你喜欢
黄河之声(2022年10期)2022-09-27中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化·高二版(2022年4期)2022-05-09汽车维修与保养(2020年10期)2021-01-22临床骨科杂志(2020年1期)2020-12-12汽车维修与保养(2020年11期)2020-06-09制造技术与机床(2019年9期)2019-09-10中南大学学报(自然科学版)(2018年7期)2018-08-08探测与控制学报(2015年4期)2015-12-15
