
核对齐多核模糊支持向量机
2019-02-27 08:55何强张娇阳
智能系统学报 2019年6期
何强,张娇阳
(北京建筑大学 理学院,北京 100044)
支持向量机(SVM)是Vapnik 等人于1995 年提出,以统计学习理论为基础建立起来的一类新的机器学习算法[1]。它以最小化结构风险[2]为原则来提高学习机泛化能力,实现期望风险的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。SVM 能够很好地解决小样本、非线性、高维度、局部极小等问题,现已被应用到很多领域,如文本分类、语音识别、情感分析、回归分析等。
随着SVM 的不断发展和应用,其部分局限性也逐渐显露出来,在很多方面的研究还有待探索和改进。例如,SVM 易受到噪声和孤立点影响,为解决此问题,Lin 等[3]提出了模糊支持向量机(fuzzy support vector machine,FSVM)的概念,即将模糊隶属度引入到支持向量机中。FSVM 降低了噪声和孤立点对最终决策函数的影响,提高了分类精度,现在也应用到了风险预测、故障诊断、手写字符串识别等领域。
此外,SVM 中核函数和核参数的选择对最终的学习结果有着重要影响,然而目前还没有关于核函数以及核参数选取的有效手段。作为核方法的重要成果,多核学习(multiple kernel learning,MKL)[4-5]近年来已成为机器学习领域广大学者的研究热点。单一核函数往往无法充分刻画数据间的相似性,尤其是复杂数据间的相似性,不同的核函数对应于不同的相似性表示,多核相结合可以较准确的表达数据间的相似性,同时也克服了核函数选择这一难题。受模糊支持向量机和多核学习的启发,为了同时解决这两大问题,本文提出模糊多核支持向量机模型。
本文的主要工作有:1) 将基于核对齐[6]的多核学习方法引入到模糊支持向量机中,提出了基于核对齐的模糊多核支持向量机,同时解决了核函数选择难题和对噪声数据敏感问题;2)利用基于Gaussian 核的模糊粗糙集下近似算子来确定每个样本点的隶属度[7],更有效地减小噪声点和孤立点对分类超平面的影响;3)根据最大化组合核与理想核之间的相似性,计算核权重,使组合核更精确地刻画数据间的相似性;4)实验结果验证了本文所提方法比经典支持向量机(SVM)、模糊支持向量机(FSVM)和多核支持向量机(MSVM)表现更为优异。
1 相关工作
1.1 经典支持向量机
对于给定数 据T={(x1,y1),(x2,y2),···,(xl,yl)},其中xi∈Rn,yi∈{-1,1},i=1,2,···,l。SVM 的目标是得到最优超平面f(x)=ωTx+b,其不仅能将这组数据正确分为两类,同时能够保证两类样本到分类超平面的距离之和最大。根据结构风险最小化原则,可将寻找最优超平面的过程归结为如下的优化问题[1-2]:

式中: ξi为误差项;C为惩罚系数。
利用Lagrange 乘子法,上述优化问题可转化为如下对偶问题:

式中: αi是样本点xi的Lagrange 乘子; 〈·,·〉 表示内积。最终得到的分类决策函数有如下形式:
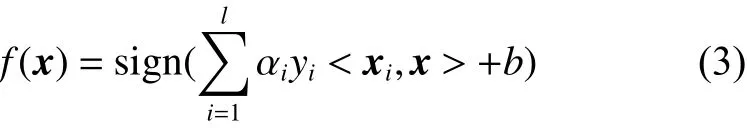
对于线性不可分数据,虽然通过引入误差项ξi可以得到分割超平面,然而其并无法实现对所有样例的正确划分。引入非线性映射 φ :Rn→H,将数据从原空间映射到高维特征空间中,并在该空间中构造最优分割超平面。由SVM 模型可知,只需要计算出 φ (x) 和 φ (x′) 的内积。通过核函数k(x,x′)[2]可以获得两点在特征空间中的内积:
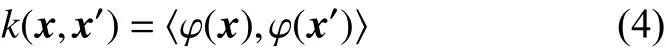
则(2)式可转化为

所以在实际应用中并不需要知道 φ,只通过核函数k(x,x′) 就可以得到相应的决策函数:

常用的核函数主要有线性核、多项式核和Gaussian 核[1-2]。
1.2 模糊支持向量机
在实际问题中,数据易受到噪声等各种因素的干扰,SVM 往往难以获得令人满意的学习效果。为了有效地排除不确定环境中野点(标签错误的训练样本)的干扰,2002 年Lin 将样本隶属度引入SVM,使样本由于隶属度的不同而对超平面有不同的影响,得到模糊支持向量机(FSVM)[3,8]。野点和噪声数据往往被赋予较小的隶属度,从而削弱其对于分类超平面的影响。FSVM 对应如下优化问题:

这 里si是 样 例xi属 于 类 别yi的 隶 属 度 。 显然si对目标函数中的 ξi起加权作用,使得噪声点对最终得到的超平面有较小的影响。该算法增强了SVM 的鲁棒性。
由Lagrange 乘子法可将式(7)转化为对偶形式:

分类决策函数为
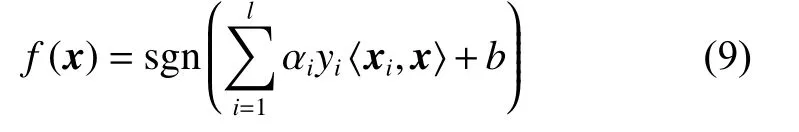
经过不断发展,基于上述FSVM 算法,其他学者也提出了各种模糊SVM 来处理不同的具体问题。这些方法都是针对实际问题中的某种不确定性而提出的,是对传统SVM 的改进与完善。
2 多核学习
在支持向量机处理分类问题时,核函数的选择对分类效果有非常重要的影响。在核函数选择的过程中,普遍采用试算方法,核函数与核参数选择的计算代价较大。多核学习将多个核函数组合在一起,取代了经典支持向量机的单个核函数。多核组合往往能够更加准确地刻画样本间的相似性,从而使得SVM 在相对较小的计算开销前提下,获得了较好的分类性能。
多核支持向量机(MSVM)主要研究问题为核函数的组合方式和相关权系数的计算。目前来说,核函数的组合方式可以分为以下3 种:
1)线性组合方式[9],也是现在使用最广泛的方式,如简单单核相加和加权线性组合:

式中: ηm为核权重, ηm都为1 时即为简单单核相
加;p为核函数个数。
2)非线性组合方式[10],例如乘积、点积和幂:
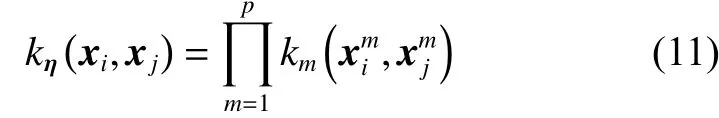
3)数据相关组合方式[11],这种方式会对每个数据样本分配一个特定的权重,这样可以得到数据的局部分布状况,进而根据分布情况对每个区域学习到合适的组合规则。
多核权系数的计算在多核学习研究中是关键问题,目前,相关权系数的计算方式具体来说有以下5 类:固定规则学习方式[12]、启发式学习方式[6,13]、最优化求解方式[14]、贝叶斯学习方式[11]和Boosting 学习方式[15]。
本文中采用启发式学习方式来获得核权重,通过核对齐[6,16-18]的方式计算多核权系数,即计算核函数相应核矩阵之间的相似性来确定权系数。基于训练集T,两个核函数k1和k2对应的核矩阵K1与K2之间的核对齐定义为

多核SVM 的优化问题由(1)转化为

式中:ωη为高维特征空间中分类超平面的法向量,映射 Φη将数据由原空间映射到高维特征空间。分类决策函数变为

3 模糊多核支持向量机
针对核函数选择难题和对噪声数据敏感问题,本文将基于核对齐加权求和多核学习方法引入到模糊支持向量机模型中,并利用模糊粗糙集方法得到样例隶属度,提出了基于核对齐的模糊多核支持向量机(multiple kernel fuzzy support vector machine, MFSVM)。
粗糙集(RS) 是20 世纪80 年代波兰学者Pawlak 提出的一种不确定性数学理论[19],可以对数据进行分析和推理,从中发现隐含的知识。经典的RS 理论建立在等价关系基础上,其只能处理符号数据。作为RS 的推广,模糊粗糙集(FRS)技术可以处理实值数据。FRS 理论最早是由Dubois 和Prade 提出[20-21],之后得到了快速发展。现有的FRS 方法已经被成功应用于很多实际问题。本文中,使用基于Gaussian 核的FRS 的下近似算子来作为事例的隶属度[7,22]。取k(x,x′) 为Gaussian 核函数。对样√例xi∈A, 令si为xi属于A的隶属度,则
本文采用基于核对齐加权求和的多核组合方式,多核组合公式为

式中: ηm是核权重,m=1,2,···,p;Km是一组基础核矩阵,m=1,2,···,p,优化目标为最大化组合核与理想核的相似性,即(可得到如)下公式[6,23]:

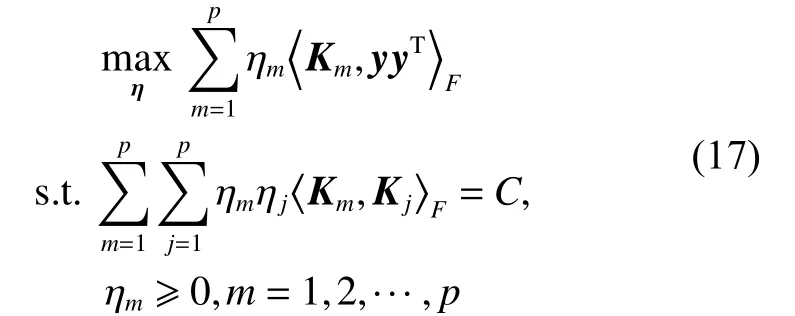
通过Lagrange 乘子法,转化为其对偶问题:

观察式 (18), λ 随着C的变化而变化,根据核对齐的定义,当核权重 ηm做线性变化时,核对齐的值保持不变,所以可考虑λ=1,那么式 (18) 优化问题变为

为了避免核函数在训练集中过拟合,在优化问题中添加对 ηm的约束,即变为


由于式 (21) 是凸二次规划问题,所以可求得 η 的唯一解,代入式(15)后得到合成核,再将其引入到上述基于模糊粗糙集隶属度的模糊支持向量机中,优化问题即变为

引入Langrange 乘子,其对偶问题由式(8)可转化为

决策函数为
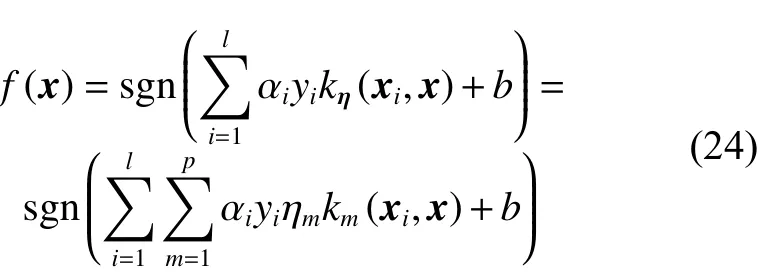
基于核对齐的模糊多核支持向量机的算法实现流程图如图1 所示。

图1 算法流程图Fig.1 Flow chart of algorithm
4 实验仿真
UCI 数据库是加州大学欧文分校提出的用于机器学习的数据库,是常用的标准测试数据库集,为了验证本文所提出方法的可行性与有效性,本文在UCI 中选取了9 个数据集,有关信息如表1 所示。由于本文只考虑两类分类问题,所以对于wine 数据集,将类别2 与3 视为一类处理。

表1 实验数据信息Table 1 Data information
实验在一台PC 机(CPU:2.6 GHz,内存4 GB)上进行,操作系统为Windows 8.1,实验工具为Matlab R2014b。实验中将所有数据都做归一化处理,核函数采用的是不同核参数的Gaussian 核。给定惩罚系数C=100,解核对齐优化问题时的参数 δ =102。选择7 个参数 σ 不同的Gaussian 核作为基础核,每个数据集对应的核参数如表2 所示。所有精度都采用10 折交叉验证方式获得,其中单核支持向量机结果为不同参数Gaussian 核精度最大值。实验对本文提出的基于粗糙集隶属度的模糊多核支持向量机(MFSVM)和经典支持向量机(SVM)、模糊支持向量机(FSVM)、多核支持向量机(MSVM)的分类性能进行对比。
无噪声情况下实验结果如表3 所示。从实验结果可以看出,在无噪声的情况下,本文提出的MFSVM 方法在9 个数据集中分类精度最高,其中在lymphography 数据集和wine 数据集中,MFSVM 和MSVM 分类精度一样,并且比SVM 和FSVM 的分类精度高,而且在计算效率方面,MSVM 与MFSVM 比SVM 和FSVM 显著提高。
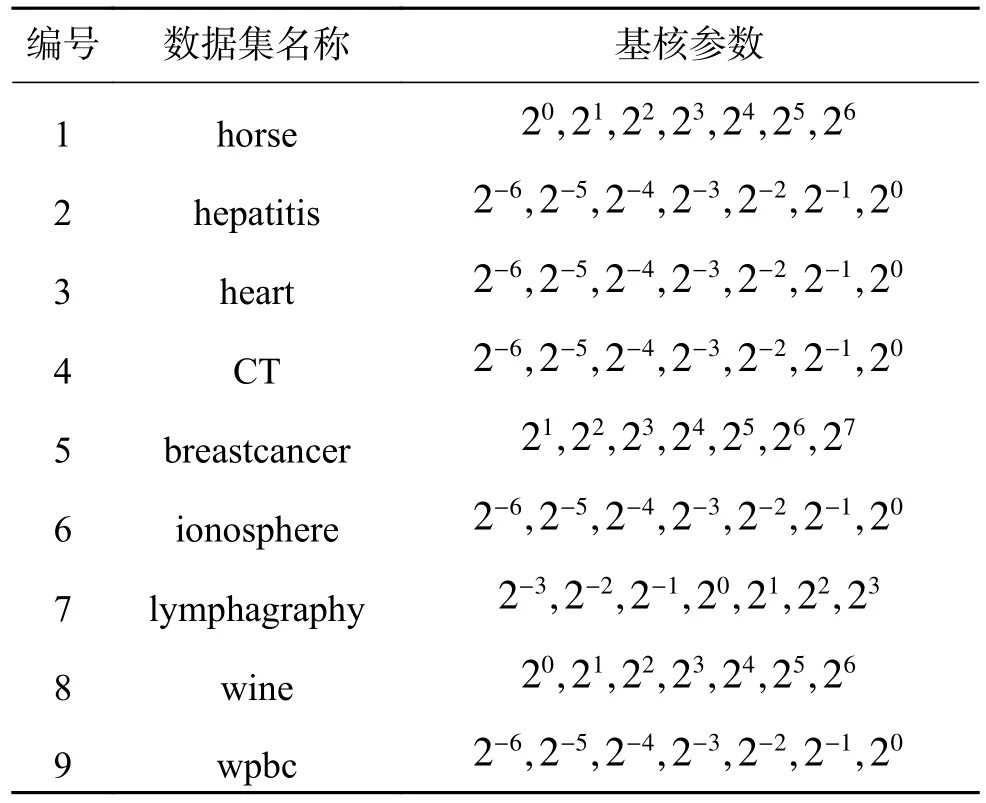
表2 高斯核参数设置Table 2 Parameters setting of base kernel

表3 无噪声情况下分类精度与训练时间比较Table 3 Comparison of classification accuracy and training time without noise
为了进一步验证MFSVM 在噪声环境中的表现,接下来在所有9 个数据集中都随机选择一定比例的分类超平面附近训练样本改变其类标签。通过这样的方式构造了带有10%、20%的噪声水平的数据。表4 和表5 分别是噪声比例为10%和20%时,4 种算法的测试精度比较结果。
从实验结果可以看出,当加入10% 的噪声时,MFSVM 方法在所有9 个数据集中的分类精度均高于其他3 种方法,具有最高的分类精度。在噪声比例为20%的情况下,虽然4 种方法的分类精度较于表4 中都相对变低,但在所有数据库上,MFSVM 都具有最高的分类精度。该结果也进一步验证了,本文所提出的MFSVM 方法在抗噪声能力与计算开销两方面集中了MSVM 与FSVM 的优势,不仅避免了核选择难题,而且具有较强的抗噪声能力。从而MFSVM 不仅可行,且有更广的应用范围。

表4 10%噪声下分类精度与训练时间比较Table 4 Comparison of classification accuracy and training time with 10% noise

表5 20%噪声下分类精度与训练时间比较Table 5 Comparison of classification accuracy and training time with 20% noise
5 结论
本文是在模糊支持向量机和多核学习的基础之上,通过将基于核对齐的多核方法引入到模糊支持向量机中,提出了基于核对齐的模糊多核支持向量机模型。实验仿真表明此方法综合了模糊支持向量机和多核学习的优点,在分类性能上有一定程度的提升,特别是在有噪声的样本中表现更为突出,证实了本文方法在解决核函数选择难和对噪声数据敏感问题上的可行性和有效性。由于本文方法中涉及到了多核组合和隶属度的计算,因此下一步将进一步研究更优的核组合方式以及如何改进样本隶属度的计算。
参考文献::
[1]VAPNIK V N.The nature of statistical learning theory[M].2nd ed.New York: Springer-Verlag, 1999: 69-110.
[2]邓乃扬, 田英杰.支持向量机: 理论、算法与拓展[M].北京: 科学出版社, 2009: 115-132.
[3]LIN Chunfu, WANG Shengde.Fuzzy support vector machines[J].IEEE transactions on neural networks, 2002,13(2): 464-471.
[4]SIAHROUDI S K, MOODI P Z, BEIGY H.Detection of evolving concepts in non-stationary data streams: a multiple kernel learning approach[J].Expert systems with applications, 2018, 91: 187-197.
[5]GONEN M, ALPAYDIN E.Multiple kernel learning algorithms[J].Journal of machine learning research, 2011,12: 2211-2268.
[6]CRISTIANINI N, SHAWE-TAYLOR J, ELISSEEFF A, et al.On kernel-target alignment[C]//Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic.Vancouver,Canada, 2001: 367-373.
[7]HE Qiang, WU Congxin.Membership evaluation and feature selection for fuzzy support vector machine based on fuzzy rough sets[J].Soft computing, 2011, 15(6):1105-1114.
[8]LIN Chunfu, WANG Shengde.Training algorithms for fuzzy support vector machines with noisy data[J].Pattern recognition letters, 2004, 25(14): 1647-1656.
[9]CRISTIANINI N, SHAWE-TAYLOR J.An introduction to support vector machines and other kernel-based learning methods[M].Cambridge: Cambridge University Press,2000: 1-28.
[10]DE DIEGO I M, MUÑOZ A, MOGUERZA J M.Methods for the combination of kernel matrices within a support vector framework[J].Machine learning, 2010,78(1/2): 137-174.
[11]CHRISTOUDIAS C M, URTASUN R, DARRELL T.Bayesian localized multiple kernel learning.Technical Report No.UCB/EECS-2009-96[R].Berkeley: University of California, 2009: 1531-1565.
[12]BEN-HUR A, NOBLE W S.Kernel methods for predicting protein-protein interactions[J].Bioinformatics, 2005, 21(S1).
[13]QIU Shibin, LANE T.A Framework for multiple kernel support vector regression and its applications to siRNA efficacy prediction[J].IEEE/ACM transactions on computational biology and bioinformatics, 2009, 6(2): 190-199.
[14]VARMA M, RAY D.Learning the discriminative powerinvariance trade-off[C]//Proceedings of 2007 IEEE 11th International Conference on Computer Vision.Rio de Janeiro, Brazil, 2007: 1-8.
[15]杜海洋.简化多核支持向量机的研究[D].北京: 北京交通大学, 2015: 13-25.DU Haiyang.Research of reduced multiple kernel support vector machine[D].Beijing: Beijing Jiaotong University, 2015: 13-25.
[16]WANG Tinghua, ZHAO Dongyan, TIAN Shengfeng.An overview of kernel alignment and its applications[J].Artificial intelligence review, 2015, 43(2): 179-192.
[17]ZHONG Shangping, CHEN Daya, XU Qianfen, et al.Optimizing the Gaussian kernel function with the formulated kernel target alignment criterion for two-class pattern classification[J].Pattern recognition, 2013, 46(7):2045-2054.
[18]刘向东, 骆斌, 陈兆乾.支持向量机最优模型选择的研究[J].计算机研究与发展, 2005, 42(4): 576-581.LIU Xiangdong, LUO Bin, CHEN Zhaoqian.Optimal model selection for support vector machines[J].Journal of computer research and development, 2005, 42(4):576-581.
[19]周炜, 周创明, 史朝辉, 等.粗糙集理论及应用[M].北京: 清华大学出版社, 2015: 57-64.
[20]DUBOIS D, PRADE H.Rough fuzzy sets and fuzzy rough sets[J].International journal of general systems,1990, 17(2/3): 191-209.
[21]DUBOIS D, PRADE H.Putting rough sets and fuzzy sets together[M]//SŁOWIŃSKI R.Intelligent Decision Support: Handbook of Applications and Advances of the Rough Sets Theory.Dordrecht, Netherlands: Springer,1992: 203-232.
[22]CHEN Degang, YANG Yongping, WANG Hui.Granular computing based on fuzzy similarity relations[J].Soft computing, 2011, 15(6): 1161-1172.
[23]CHEN Linlin, CHEN Degang, WANG Hui.Alignment based kernel selection for multi-label learning[J].Neural processing letters, 2019, 49(3): 1157-1177.
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
新高考·高一数学(2022年3期)2022-04-28
计算机应用与软件(2022年2期)2022-02-19
上海理工大学学报(2021年6期)2021-12-29
数学年刊A辑(中文版)(2021年3期)2021-11-05
数学年刊A辑(中文版)(2021年2期)2021-07-17
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
劳动保护(2019年3期)2019-05-16
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
