
S系列综合保障标准数据模型中的数据元素映射关系研究
2019-03-01 02:00朱兴动范加利
指挥控制与仿真 2019年1期
朱兴动,张 琦,范加利
(1.海军航空大学,山东 烟台 264000;2.海军航空大学青岛校区,山东 青岛 266000)
为了规范对武器装备的综合保障过程,欧洲的S系列综合保障标准在逐渐发展的过程中,内容不断完善,先后出版了规范技术出版物编制的S1000D[1]、规范综合保障物料供应与采购过程数据的S2000M、规范整个综合保障过程及数据的S3000L、规范预防性维修过程及数据的S4000P、规范装备使用过程产生的反馈数据的S5000F,同时,规范训练内容的S6000T也即将出版。各标准规范的信息间存在联系,它们逐渐形成一个涵盖装备综合保障各个方面的一套完整的综合保障标准体系[2],并能互为数据来源。为了将这几个标准的内容串联起来,SX000i应运而生,它提供了上述标准间的内在联系,并衍生出一系列子标准,包括给出综合保障各领域相关名词定义的SX001G,规范S系列标准通用数据模型的SX002D等。因此,S系列标准体系对于我国装备综合保障信息间交互性差,数据重用率低的现状具有借鉴意义。然而SX000i虽给出了各个标准间的关系,但具体的数据元素间的映射关系并未给出,需要进一步寻找。同时,S1000D的数据元素与其他标准的数据元素命名方式不同,加大了寻找映射关系的难度。
编辑距离是衡量两个字符串相似度的有效工具,它通过对其中一个字符串进行删除,增加,修改字符的操作,计算其完全更改成另一个字符串的代价,用于评价两个字符串的相似度[3-4]。它对字符串本身没有限制和要求,适合于两个相似但不完全一样的字符串进行映射关系匹配,给寻找S1000D数据元素与其他标准的数据元素之间的映射关系提供了方法。
1 S系列综合保障标准间数据的内在联系
装备在投入使用前是其研制与设计阶段,这个阶段产生的装备设计数据可以用于S4000P规范的装备预防性维修分析当中,得到产品的预防性维修任务需求(PMTR),而PMTR属于S3000L规范的维修任务需求(MTR)的一部分,MTR的生成能够借鉴PTMR信息[8]。同样,S3000L规范的保障性分析方法描述了如何对装备进行分解并得出分解信息,而S2000M规范的图解零部件目录与物料供应数据的生成能够借鉴装备分解信息,S1000D规范的IETM维修计划与维修任务数据模块的生成能够借鉴S3000L中的MTR信息[5-7]。图解零部件目录信息又可以进一步运用到IETM图解零部件目录数据模块生成及零部件的编码中。S6000T规范的训练任务信息能够借鉴相关的技术出版物信息[9]。
装备投入使用后产生的反馈信息通常是装备使用过程中产生的故障信息。S5000F规范了根据故障信息生成用于传递的故障消息的过程,这些信息的可贵之处在于它们能用来对此类故障事件做出有效的预防工作,因此S4000P规范的预防性维修分析就可以利用这个故障消息,锁定事故发生时装备相关零部件,并分析出可能的故障原因以及对应的预防性维修方法。同样,可以根据得到的事故相关零部件对原有S3000L产品分解信息进行更新,并用新的预防性维修方法更新维修任务需求与分析信息;新的产品分解信息又能用于更新S2000M物理分解树,进而更新图解零部件目录与S1000D的图解零部件数据模块;新的MTR信息也能作为维修计划数据模块、维修任务数据模块的更新参考;新的技术资料又能用于更新S6000T规范的训练任务、目标等信息。整个信息传递流程如图1。最后,更新用于发送给用户的S5000F安全措施信息,维修服务通告和保修信息。
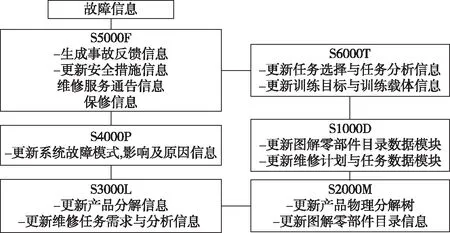
图1 装备使用后的综合保障信息关联关系
2 SX002D标准及其在寻找映射关系方面的应用
2.1 SX002D标准内容
数据模型的统一和协调被视为S系列综合保障标准的基本要求,SX002D规范的通用数据模型(CDM)就是一个对多个S系列综合保障标准共有数据元素的概念性描述[10]。SX002D使用UML(统一建模语言)描述这个S系列标准通用数据模型,其内容范围主要包括需要定义的产品区域信息,产品交换及其分解信息和已授权的产品配置信息,还包括首次发布的原函数和复合属性。
SX002D通用数据模型包括以下功能单元(UoF):产品与项目、分解结构、零部件定义、硬件元素、软件元素、聚合元素、区域元素、产品设计配置、更改信息、安全分类、备注、适用性、消息。每个功能单元都使用UML类图表示,包含已经定义好的各种不同类,类的属性以及类之间的关系(如图2)。
2.2 SX002D标准在寻找映射关系方面的应用
已知S2000M,S3000L,S5000F,SX002D的数据模型都由UML类图进行表示,且类与属性的命名方式相同(S4000P与S6000T数据模型官方并未给出,本文不涉及),而S1000D的数据模型由各个数据模块构成,每个数据模块以XML格式进行储存,且数据命名方式与其他模型有些出入。因SX002D的数据模型是整个S系列标准的通用数据模型,所以每个标准规范的数据模型与它的模型取交集就能够得到每个标准与其他标准产生重叠的部分,再具体分离出两两标准间数据重叠的部分。
首先从各个标准的官方网站上下载数据模型,这些模型都是以XML或XSD格式储存的(如图3),用python中的XML解析方法——ElementTree将模型中的数据元素名称,即UML模型中的类名解析出来,按每行一个词的方式储存到文本文档中,每个标准的数据元素名称储存在不同的文档。之后对S2000M,S3000L,S5000F文本中的元素两两取交集,得到除S1000D外其他S系列标准数据模型中的数据重叠部分,将这些记录也储存在文本文档中。
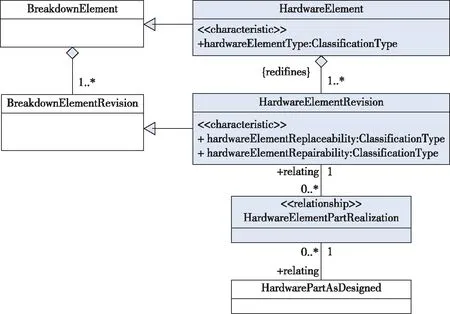
图2 SX002D硬件元素功能单元模块

图3 SX002D数据模型的XML格式节选
3 基于Levenshtein距离的字符串模糊匹配方法
无论是S1000D规范的数据元素还是其他标准的数据元素,它们的名称都是类似“descrForPart”(零部件描述)这样的合成词,寻找一模一样的词匹配几乎是不可能的,但两个意思相同或相关的词在其字符串排序上有一定的相似性,如“name”与“partName”,而且每个标准的数据元素个数都很多,人工寻找过于浪费时间。因此使用字符串模糊匹配的方法具有缩小映射关系寻找范围的作用。
通过计算两个字符串的编辑距离大小来衡量字符串间的相似度方法是一种常用的字符串匹配方法。编辑距离,又称Levenshtein距离,指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。一次编辑操作可以是:将一个字符替换成另一个字符,插入一个字符,删除一个字符。
在数学上,两个字符串a,b(分别为长度|a|和|b|)之间的Levenshtein距离由leva,b(|a|,|b|)表示,公式为:
其中,1(ai≠bj)表示当ai=bj时,值为0,表示不需替换;反之为1,表示需要替换。当两个字符串中没有任何一个相同字符时,公式取max值,反之取min值。min值表达式的第一行代表从a转变成b需要删除字符的次数,第二行代表从a转变成b需要插入字符的次数,第三行代表a转变成b的字符替代次数。
计算Levenshtein距离的方法如下:如果我们设置一个矩阵来保存第一个字符串某个位置的所有前缀和第二个字符串的某个位置的所有前缀之间的Levenshtein距离,那么可以用自下而上地动态规划方式计算矩阵中的值,从而找到两个完整字符串之间的距离作为输出值。如图4,标记“3”为“Saturday”中的字符串“Sa”转变为“Sunday”中字符串“Sund”的Levenshtein距离。伪代码算法如图5 所示。
之后通过计算出的Levenshtein距离可以轻易得出这两个字符串的相似度,设相似度为sim,两个字符串长度分别为a和b,则计算相似度的公式为:
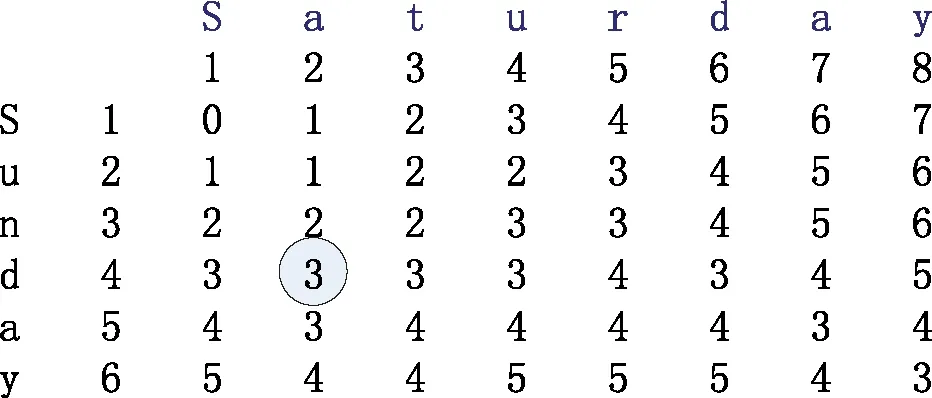
图4 两个字符串任意位置间的Levenshtein距离列表

图5 动态规划计算Levenshtein距离算法
4 S1000D数据元素与其他标准数据元素的映射关系
本文以S1000D的图解零部件目录为例,取出其所有数据元素(命名为1000D),并与S2000M和SX002D的交集(命名为2-002D),S3000L和SX002D的交集(命名为3-002D),S5000F与SX002D的交集(命名为5-002D)两两进行字符串模糊匹配,得到一系列字符串匹配对及相似度。用人工方法检验其中S1000D与S2000M匹配的结果,已知S1000D图解零部件数据模块的数据元素为207个,2-002D的数据元素为56个,共可得到207×56=11592个匹配对。得到的分值代表两个字符串间的相似度,分值越高,相似度越大,例如0.82分的changeAuthority与ChangeAuthorization明显比0.56分的partIdentifier与overlengthPartNumber相似度更高。了解了不同相似度范围内的匹配准确度后,发现相似度在0.50分以上的匹配对共75对,并且包含了全部的15对准确匹配对,因此在之后的匹配过程都只考虑分数大于0.50分的匹配对做进一步的筛选,最后得到S2000M,S3000L,S5000F数据元素与S1000D数据元素之间的全部映射关系,并以S1000D图解零部件数据模块与S2000M数据元素的映射关系为例制作映射关系表(见表1)。

表1 S1000D图解零部件数据模块与S2000M数据元素映射关系表
5 结束语
S系列综合保障标准之中任何一个标准规范的信息都与其他标准的信息存在关联,而集成这些信息能够将各个领域的综合保障信息融合起来,形成一个囊括装备保障领域的综合保障信息体系,使保障信息之间的交互更为方便,有助于装备保障部门对这些信息进行综合利用,同时提升装备的保障性与保障效率。本文借助SX002D规范的S系列通用数据模型找出了除S1000D外其他标准数据模型间的数据映射关系,并以S1000D图解零部件数据模块为例,使用基于Levenshtein距离的字符串模糊匹配的方法找出了其与S2000M数据模型中可能含义相同的数据元素匹配对,并通过筛选最终找出两者间的准确映射关系并制作映射关系表。实验证明,这种字符串模糊匹配的方法对能够很大地减轻人工判断映射关系的工作,并大幅提升匹配效率。
猜你喜欢
现代信息科技(2021年21期)2021-05-07
无线互联科技(2020年11期)2020-12-01
舰船科学技术(2020年2期)2020-04-17
科教导刊·电子版(2016年30期)2016-12-26
群众(2016年11期)2016-11-28
中国新通信(2016年17期)2016-11-17
党政干部学刊(2015年7期)2015-12-24
新财富(2015年8期)2015-11-20
中国信息技术教育(2015年21期)2015-09-10
