
基于Spark平台的K-means算法的设计与优化
2019-03-21 11:38王义武杨余旺于天鹏沈兴鑫李猛坤
计算机技术与发展 2019年3期
王义武,杨余旺,于天鹏,沈兴鑫,李猛坤
(1.南京理工大学 计算机科学与工程学院,江苏 南京 210000;2.304兵器厂,山西 长治 046000;3.清华大学 经管学院,北京 100000)
0 引 言
从算法复杂程度看,K-means算法简洁、高效,其他很多算法难以相比,因此其应用愈加广泛,但它也存在固有问题,如聚类中心需人为主观设置,但只有了解数据分布才能掌握相关信息,这与现实相矛盾;聚类效果和中心点选择有关,易陷入局部最优解[1],中心点的不同选择,可能造成结果大不相同;传统K-means需要依序逐个计算数据点之间的距离[2],当数据规模很大时在计算上耗费了大量时间。针对这些固有问题,不断有人提出优化方法,使得K-means算法愈加成熟、多样。
随着分布式系统的出现与完善,传统算法利用分布式计算的优点在聚类效果上得到了不断的优化和提高。文献[3]实现了Hadoop版本的并行处理,提高了算法的吞吐量;文献[4]在Hive平台下实现了K-means的分布式计算且运用简单的类SQL语言即可以实现数据查询;文献[5]利用Canopy优化K-means算法,并在MapRduce框架下实现。在上述研究的基础上,文中提出一种新的OCC K-means算法。不同于传统算法以随机选择的方式产生聚类中心,该算法进行必要的预处理,利用UPGMA和最大最小距离算法对数据点进行筛选,得到可以反映数据分布特征的点,并作为初始的聚类中心,以提高聚类精度。
1 相关工作
1.1 Spark分布式框架
Spark作为一种正兴起的计算框架,建立在弹性分布式数据集基础之上,具有以下特点:
(1)数据分布式存储在多个节点上;
(2)高度抽象化的RDD概念,这也是Spark与Hadoop、Hive最大的不同,RDD是一切计算的基础,这也使得Spark迭代计算、并行计算的能力明显好于其他现存的分布式框架;
(3)不同于Hadoop频繁地在HDFS进行I/O操作,Spark计算时将数据写入内存,有效降低了计算时间,同时当内存不够时,它可以将数据写到磁盘上;
(4)高度的容错性,Spark抽象出RDD并在计算时只记录了各个RDD之间的关联,没有真正地产生相关数据,仅在Action动作时才真正提交作业。
Spark运行模式多样,部署在单机上时可以选用本地模式(local)或者伪分布模式(local cluster);当部署在集群上时可以选用Standalone模式、Mesos模式或者Hadoop YANR模式。这里具体的介绍Standalone模式[6]。
1.2 基本概念
定义1:点Pi和Pj之间采用欧氏距离,定义为:
(1)
其中,Pi,Pj为n维数据。
定义2:簇C的中心定义为C=(C1,C2,…,CN),数据点第n维值为:
(2)
其中,m为数据个数;Xi为第i个数据;n为维度。
定义3:d为数据j距集合i中所有的数据的最小距离。
d=Min(Dist(Uik-Uj))
(3)
其中,Uik为数据集i中第k个数据;Uj标记数据集j。
定义4:由定义3进一步得出最大最小距离为:
(4)

定义5:最大最小距离算法[7-8]中用于选出分布较远的数据点。
Dimax>θ‖v1-v2‖
(5)
其中,v1,v2为数据集i,j间距离最小的两个数据点;θ为算法参数,值取(0,1)之间。
定义6:算法的收敛判定标准-误差平方和准则函数。
(6)
其中,Mi是簇Ci的中心点;p是簇Ci的数据点元素;k为簇的个数。在给定数据集时,Jc表示将数据集划分为k个簇的总体误差。从式6可以看出,Mi决定了Jc取值大小,Jc值越大表示数据划归的误差越大。因此在聚类过程中应致力于Jc最小化,从而使聚类最优化[9]。
定义7:准确率和召回率。
P(i,j)=precision(i,j)=Nij/Ni
(7)
R(i,j)=recall(i,j)=Nij/Nj
(8)
其中,Nij表示属于类i,但被划归到类j中的数据数;Ni表示类i中全部数据点个数;Nj表示类j中全部数据点的个数。由式7和式8可得F-measure:
F(i)=2P*R/(P+R)
(9)
其中,F(i)结合准确率和召回率,表示相对准确率。
定义8:加速比(sizeup)。
(10)
其中,Ts为一个Worker算法完成时间;Tn为n个Worker算法完成时间。
定义9:扩展比(scaleup)。
(11)
其中,S为加速比;n为Worker节点的个数。
2 OCC K-means并行算法
2.1 算法思想
传统K-means算法对聚类中心过于敏感,这也导致聚类效果上的显著不同,因此文中提出使用UPGMA算法[10]筛选出可以反映数据集整体分布的候选中心,同时被选择的数据点应该是相距比较远的,防止过于集中[11-12],以避免同一个聚类因为参数设置的原因选出了两个聚类中心,这样K-means算法就获得了一个较好的输入,并且在整个执行过程中UPGMA算法和K-means算法两个阶段都是并行的。
UPGMA阶段的执行过程如下:
(1)读入HDFS上将要聚类的数据,初始情况下每一个数据点都看作一个类,并通过Map将其转化为Vector;
(2)Worker节点的各个数据计算距其他数据点的最小欧氏距离,通过Reduce操作将距离最近的两个数据点合并,计算它们的中心作为新的数据点(同时记录这个数据点代表的类所拥有的数据的数目)参与聚类;
(3)若类内的数据大于数据点总数的m%,则将此数据点加入到候选列表,通过Filter操作过滤掉已存在于候选列表中的类中数据;否则重复步骤2;
(4)当无归属的数据点的数目小于总数的m%时,算法停止,输出候选列表作为最大最小距离算法的输入数据;否则一直重复上述过程。
K-means阶段的执行过程如下:
(1)将最大最小距离算法的输出作为K-means算法的输入;
(2)Worker查找距离自己最近的中心点;
(3)将距离同一个初始中心最近的所有数据点通过Iterator对距离全局求和、记录数据个数,然后加入到同一个类中,更新此类的中心;
(4)若算法收敛则停止,否则返回步骤2。
2.2 基于Spark的OCC K-means算法的并行化
2.2.1 UPGMA算法的并行化
使用UPGMA算法主要目的是为了了解数据的分布,找到数据的密集区域,从中选出代表这一区域的数据点。
改进的UPGMA算法的并行化过程如下:
(1)算法输入:待聚类的数据集,m,p,θ;算法输出:初始候选中心集合。
(2)将单个数据作为独立的类。
(3)计算类间彼此距离,合并相距最近的两个类,同时判断剩下数据的总数是否大于等于总数的m%,若不大于等于则转步骤4。
(4)i=0,t=0,t=t+1,forj=i+1...maxcluster do
(5)当子类i和子类j内部的数据个数少于等于总数的m%,且两个类数据元素之和大于总数的m%时,计算两个类之间距离,并加入到距离矩阵中。
(6)合并距离矩阵中最近的类,并且加入到序列Q,转至步骤3。
(7)选取序列Q的前p%,计算中心位置,即为初始候选中心。
m%为类中的数据点占数据总数的百分比,当合并后的类中数据点的个数满足这一比例时才会将其加入到序列Q;最后选取序列Q的前q%。
2.2.2 K-means算法的并行化
经过上面两个过程,K-means算法获得了一个较好的输入,这里主要说明K-means并行化的实现。
Map操作:
输入:待聚类数据集S,初始聚类中心数组Centerlist
输出:已被标记所属聚类的数据集合
(1)while(S!=null),计算P(S中的数据)与Centerlist中第i个数据的距离,记为Dpi,加入集合{Dpi}(i=1,2,…,Centerlist.length),在S中删除P。
(2)找出{Dpi}(i=1,2,…,Centerlist.length)中最小的所对应的中心Dpi,将PMap为(p,i)
Combine操作:
相同i构成的集合(类)对Map产生的数据进行分类、汇总
Reduce操作:
(1)while(C.hasNext()),num=0,double du [demesions],P=C.next(),将数据点P的第i分量值加入du[i]中,num++
(2)输出类中心du[i]/num
每一次reduce操作都会更新一次聚类中心,当前后两次中心的值不发生变化或者变化满足停止条件时说明已经收敛,此时算法停止。
3 实验结果与分析
3.1 实验环境、测试数据集及评价指标
实验是在Spark的Standalone模式下进行的,Spark采用1.4.0版本,Hadoop采用2.6.0版本,Java jdk为1.8,Master和Worker节点的操作系统为ubuntu 14.04 LTSk,其中Worker节点的个数为5。
3.2 实验过程
这里进行了两组实验,使用传统K-means和OCC K-means对三个数据集进行处理。实验中采用的数据集为Iris,Seeds,Dum,OCC K-means算法中的参数依次设置为:(0.8,0.8,0.5)、(0.5,0.8,0.5)、(0.5,0.8,0.5),两组实验结果如表1所示。
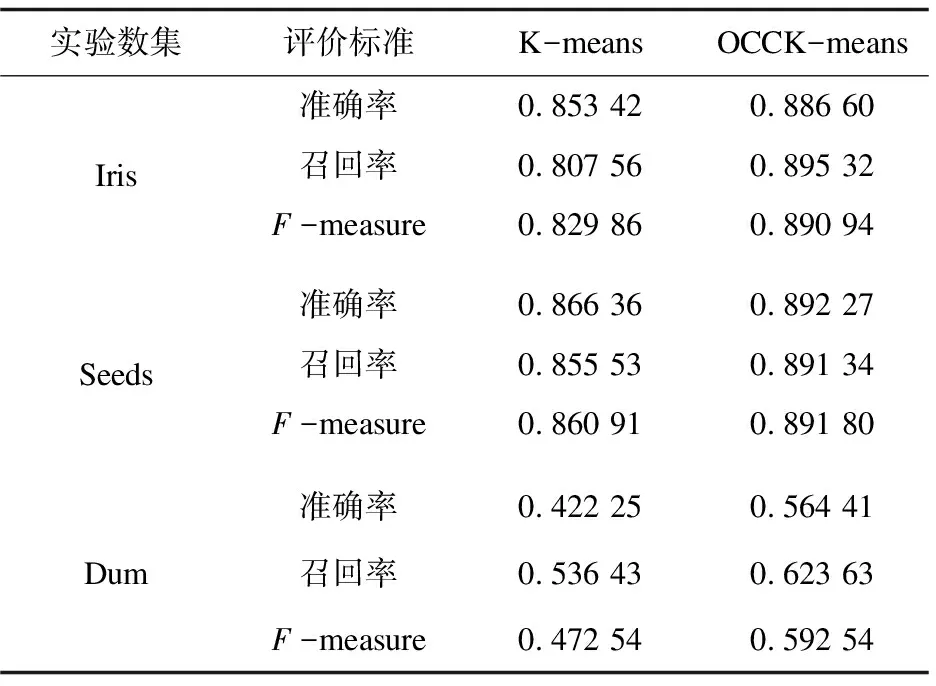
表1 实验结果
效果对比如图1~3所示;OCC K-means算法加速比和扩展比分别如图4和图5所示。

图1 Iris数据集上的效果对比
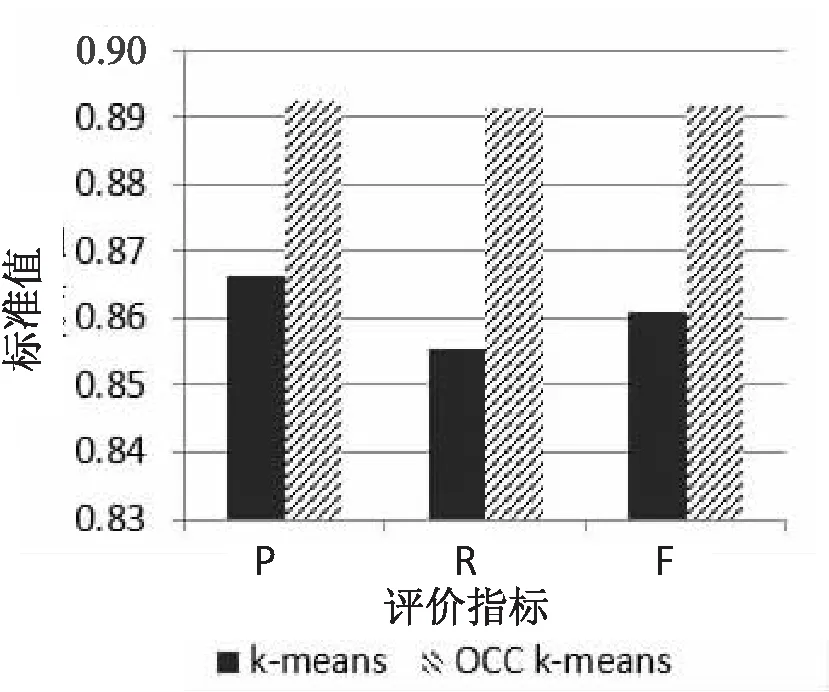
图2 Seeds数据集上的效果对比
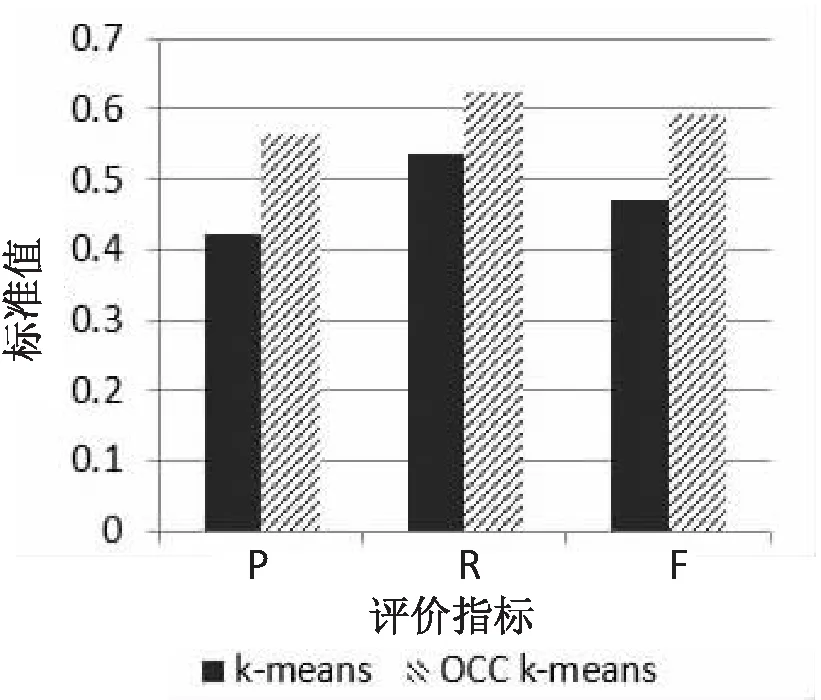
图3 Dum数据集上的效果对比

图4 OCC K-means算法加速比

图5 OCC K-means算法扩展比
可以发现在Iris数据集上,OCC K-means算法相比传统K-means算法在准确率上提高了3.33%,召回率提高了8.78%,F-measure提高了6.11%;在Seeds的数据集上,准确率提高了2.59%,召回率提高了3.58%,F-measure提高了3.09%;在Dum数据集上,准确率提高了14.22%,召回率提高了8.72%,F-measure提高了12.00%,可见改进后的算法在聚类效果上得到了优化[13]。原因在于OCC K-means算法使用UPGMA算法和最大最小距离算法对聚类中心进行了选择优化,这些中心点来自数据密集区域可以很好地代表数据的分布,同时在一定程度上将噪声数据和边缘数据的影响尽可能降低,使得算法体现出更好的准确性和鲁棒性[14-15]。
同时对加速比和扩展比的分析可知,当Worker的节点小于3时,算法的加速比近似于线性上升,但随着节点数增大而增幅出现下降,这是因为虽然硬件资源成倍增加,但它们并没有全部得到使用,反而集群初始化时间,资源调度的代价,节点间通信代价等会增加,这些都会影响算法的并行效果。
4 结束语
从两组实验结果可以得出,基于Spark实现的OCC K-means算法,在准确率、召回率、F-measure上的表现都优于传统K-means,并且在Iris、Seeds、Dum不同数据集上均取得了较好的结果,说明K-means算法在聚类中心选择上得到了一定程度的优化,拥有更好的刻画数据分布特征的能力。同时当工作节点数量小于一定值时,加速比、扩展比可出现理想的变化,说明算法具有较好的并行化能力,但是当工作节点过多或者实验数据集过小时,算法的并行化效果就会受到影响,有待进一步完善。
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
计算机研究与发展(2022年1期)2022-01-19
小学生学习指导(低年级)(2021年9期)2021-10-14
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
小学生学习指导(低年级)(2019年9期)2019-09-25
学生导报·东方少年(2019年27期)2019-01-14
小学生学习指导(低年级)(2018年9期)2018-09-26
