
利用LEMNA解释深度学习在网络安全的应用(上)
2019-04-18 09:34郭文博徐军
中国教育网络 2019年3期
文/郭文博 徐军
近年来,深度神经网络在网络安全应用上展现出强大的潜力。截至目前,我们已经看到深度神经网络在恶意软件聚类、逆向工程以及网络入侵检测中取得了很好的效果。尽管如此,由于神经网络的不透明特性,安全从业人员对其使用依旧十分慎重。具体而言,深度神经网络可能是由大量的数据集训练而成并且存在上百万个神经元。 这种高度的复杂性使得我们很难理解神经网络的某些决策,从而导致了诸如无法信任神经网络以及无法有效判断神经网络的错误等问题。
为了增强神经网络的透明性,研究者们已经开始探索新的方法来解读神经网络的分类结果。然而,这些方法难以用于解释在安全领域的深度学习。一方面,已有的方法主要是用于解释深度学习在图像分析领域的应用,被解释的模型通常是Convolutional Neural Networks (CNN)。但在安全应用方面,比如逆向工程和恶意软件分析领域,通常我们使用具有更高扩展性及更强特征关联性的模型,比如Recurrent Neural Networks (RNN)或者Multilayer Perceptron Model (MLP)。到目前为止,没有解释模型可以被用于RNN;另一方面,现有的方法通常有较低的解释精度。对于拥有模糊边界的应用而言,比如图像识别,相对较低的解释精度是可以接受的。但是对于安全应用,比如二进制分析,一个字节的解释偏差也会导致严重的误解或者错误。
在这项工作中,我们尝试构建一种新型的、具有高解释精度的模型用于安全应用。此方法属于黑盒方法,并且通过特殊的设计来解决以上难题。给定一个输入样本x以及一个分类器(如RNN),我们尝试去发现那些对于归类x起重要作用的关键特征。从技术上而言,对于x附近区域的决策边界生成局部拟合。为了提高拟合的精确度,该方法不假设分类器的决策边界是线性的,也不假设不同的特征之间是独立的。相反,我们借用混合回归模型来近似非线性的局部决策边界,同时通过fused lasso来加强解释精度。这样的设计一方面提供了足够的灵活性来优化对于非线性决策边界的拟合,另一方面fused lasso可以很好地抓住不同特征之间的依赖性。为了更加方便的阐述,我们将这个方法称为LEMNA (Local Explanation Method using Nonlinear Approximation) 。

图1 机器学习解释示例
为了验证解释模型的有效性,我们利用LEMNA来解释深度学习在安全方向的两个应用:PDF malware的聚类以及在二进制代码中寻找函数边界。在这两个应用中,聚类器分别是通过10000 个PDF文件以及2200个二进制程序来训练的。它们都达到了98.6%以上的精度。我们将LEMNA用来解释聚类结果并且开发了一系列的指标来验证解释的正确性。这些指标表明在这些分类器以及应用中,LEMNA显著的优于已有的解释方法。在准确度评估之外,我们还展示了安全分析员和机器学习开发者将如何从解释结果中受益。
这项工作主要带来以下几个贡献:
1.设计并且开发了LEMNA, 它是一种专门用于解释安全应用中的深度学习的方法。该方法结合混合回归模型以及fused lasso,提供高精度的解释结果。
2.在两个不同的安全应用上评测了LEMNA,包括PDF恶意软件聚类,以及二进制代码的函数边界确定。我们提出了一系列的指标来评估我们解释结果的精确度。实验显示LEMNA显著优于现有的解释方法。
3.论证了解释模型的实际应用。不论是二进制代码分析,还是恶意软件检测,LEMNA都阐释了为什么聚类器会做出正确的或者错误的决定。同时还开发了一种简单的方法来自动将我们得到的启发变成修正模型错误的可行方案。

表1 可行方法的必要特征
相关背景
在具体介绍技术细节之前,我们先介绍一些相关的背景知识。首先,对可解释机器学习给出一个定义,并且讨论相关的解释技术。然后,对利用深度学习的关键安全应用进行简介。最后,详细描述为什么已有的解释技术不适用于这些安全应用。
问题定义
可解释机器学习尝试对于分类的结果给出可理解的解释。具体而言,给定一个输入 x 以及一个分类器 C,这个分类器在测试时会给 x 一个标签 y,解释技术的目标是阐释为什么x 被分类成y,通常的做法是标定使得分类器给出决策的关键性特征。如果这些被选择的特征是可以理解的,那么我们就认为这些特征给出了一个解释。图1展示了基于图像分类以及情感分析的例子。我们可以通过选择特征来解释这些分类器的决策(比如,突出关键像素和关键字)。在这个工作中,主要聚焦于解释安全应用中的深度学习。从技术上而言,我们的工作可以归类为黑盒解释方法。

图2 黑盒解释方法原理说明
黑盒解释方法不需要理解诸如网络结构和参数等分类器的内部结构。取而代之的是,它们将分类器视为黑盒子然后通过对于输入输出的观察来进行分析(即模型推断方法)。这个类别里面最有代表性的工作是 LIME 。给定一个输入 x (比如一个图片),LIME系统性的扰动x来从x的邻近特征区域里面获取一系列新的人工样本 (比如图 2中的x ' 和x '' )。我们将这些人工样本放到目标分类器 f(x) 里面去获取相应的样本, 然后用线性回归模型 g(x) 来拟合这些数据。这个 g(x) 试图去模拟f(x)在特征空间中位于输入样本附近区域的决策。LIME假设在输入样本附近的局部决策区间是线性的,因此用线性回归模型来局部代表 f(x) 的决策是合理的。由于线性回归是可自解释的,因此LIME可以基于回归系数来标定重要的特征。
解释安全应用
虽然深度学习在安全应用上已经展现了巨大的潜能,但是却极度缺乏对应的解释模型。其结果是,透明度的缺乏降低了可信度。首先,安全从业者如果不知道关键的决策是怎么做出的可能不能信任深度学习模型。其次,如果安全从业者不能诊断分类器的错误(比如,由于畸形的数据引入的错误),那么这些错误可能在后面的实用中被放大了。接下来,我们介绍两个成功使用深度学习的关键性安全应用,然后讨论为什么已有的解释方法在这些安全应用中不适用。
在此工作中,我们关注两类安全应用:二进制代码逆向和恶意软件聚类。二进制代码分析中的深度学习应用包括寻找函数边界,确定函数类型,以及相似代码定位。比如说,Shin他们用一个双向的RNN来改进函数边界寻找,实现了几乎完美的结果。对于恶意软件分类,现有的工作主要通过使用MLP模型来进行大规模恶意样本聚类。
利用现有的解释方法来解释以上的深度学习应用有极大的挑战。在表1中,我们总结了一个可行方法的必要特征,以及为什么现有的解释技术不适用:
1.大部分的解释方法是为用于图片聚类的CNN而设计的。但是,我们关注的安全应用主要使用的是RNN或者MLP。由于模型上的不匹配,现有的解释方法是不适用的。诸如LIME的黑盒模型不能很好地支持RNN。
2.像LIME这类的黑盒方法假设不同的特征是不相关的,但是RNN跟这个假设是冲突的,因为RNN会明确地捕捉序列数据中的特征依赖。
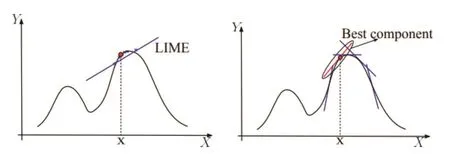
图3
3.大部分的解释方法(比如LIME)假设决策边界是有局部线性特征的。但是,当这些局部决策边界不是线性的(对于大部分复杂网络而言),这些解释方法将导致严重的错误。图3左边中展示了一个相应的例子。这个例子中,x附近的决策边界是高度非线性的。换言之,线性的部分极度地约束于一个非常小的区域内部。我们通常用的取样方法非常容易就会采样到超越线性区域的样本点,从而使得一个线性模型很难拟合 x 附近的决策边界。在实验中发现这样简单的线性拟合会高度降低解释精度。
4.黑盒解释方法对于安全应用而言是非常重要的,因为人们很少使用提供具体网络结构、参数和训练数据的模型。虽然有些白盒解释方法可以强行在黑盒环境下使用,但是他们无可避免的会导致精度的下降。
在此工作中,我们尝试着提供专用于安全应用中的解释方法。我们的方法是一种黑盒方法,同时可以有效支持诸如RNN, MLP和CNN的深度学习模型。更重要的是,该方法实现了一个更高的精度来支持安全应用。
解释模型设计
解释模型LEMNA
为了实现以上的目标,我们设计并且开发了LEMNA。总体而言,将目标聚类器当成一个黑盒子,通过模型拟合来推导解释。为了提供高精度的解释,LEMNA需要一种全新的设计。首先,引入 Fused Lasso 来处理特征间的依赖关系。然后,将Fused Lasso 融入到一个混合线性模型中,以此来拟合局部非线形的决策边界,从而支持复杂的安全应用。接下来,讨论设计背后的原理,将讲述如果将这些设计整合成一个单独的模型,以此来同时处理特征依赖以及局部非线性。最后,介绍如何利用LEMNA来得到高精度的解释。
Fused Lasso是一种通常用来获取特征依赖的惩罚项,能有效处理像RNN一类深度学习中的特征依赖。总体而言,Fused Lasso迫使LEMNA将相关/相邻的特征组合起来产生有意义的解释。接下来介绍具体的细节。
为了从一个集合的数据样本中学习一个模型,机器学习算法需要最小化一个loss function L(f (x),y)。这个函数定义了预测结果和真实结果的不相似程度。比如说,为了从N个样本中学习到一个线性回归模型 f (x)= βx + ϵ,一个学习算法需要使用Maximum Likelihood Estimation (MLE) 来最小化如下的方程式:

其中, Xi是一个训练样本,被表示成一个多维的特征向量(x1, x2, …, xM)T。Xi的标签表示为 yi。向量 β=(β1,β2, …,βM)包含了这个线性模型的系数,而‖ ·‖是L2范式,来度量模型预测和真实结果中间的不相似程度。Fused Lasso是可以作为惩罚项引入学习算法中的任何损失函数。以线性回归为例,Fused Lasso表示为对于系数施加的约束:

当一个学习算法最小化损失函数的时候,Fused Lasso 强制使得相邻特征间的系数之间的差距在一个S范围内。因此,这个惩罚项驱使一个学习算法对于相邻的特征赋予相同的权重。这可以被认为是驱使一个学习算法聚合一组特征,然后根据特征群组来解释模型。安全应用,比如时间序列分析和代码序列分析,通常需要使用RNN来对特征之间的依赖性进行建模,由此得到的聚类器依据特征的共存来做出分类决策。如果我们用一个标准的线性回归模型(比如 LIME)来得到一个解释,将无法正确的拟合一个局部决策边界。这是因为一个线性回归模型将特征独立对待,无法捕捉到特征依赖。通过在拟合局部决策边界的过程中引入Fused Lasso, 我们期待得到的线性模型有如下形式:

在上面的形式中,特征被群组起来。因此,重要的特征有可能被选取成一个或多个群组。具象的对这个过程进行建模的LEMNA可以推导出精确的解释,尤其是RNN所做出的决策。我们通过图1中的情感分析的例子来解释这个思路。通过引入Fused Lasso, 以及一个回归模型考虑相邻的特征(比如,一个句子中的相邻单词),当我们推导解释时,模型不再简单地抓住单词 “not”, 同时我们还能精确的抓住短语“not worth the price”来作为情感分析的解释结果。
Mixture Regression Model 使得我们可以精确的拟合局部非线形决策边界。如图3右边所示,一个混合回归模型是多个线性模型的组合。它使得拟合更加有效:

在上面的公式中,K 是一个超参数,代表着混合模型中线性部件的总个数。πk表示的是对应的部件的权重。
给定足够的数据,不论一个聚类器有着线性的还是非线性的决策边界,该混合模型都可以近乎完美地拟合这个决策边界(使用一个有限集合的线性模型)。因此,在深度学习解释的问题中,这个混合回归模型避免了前面提到的非线性问题,从而得到了更精确的解释。为了更好的阐释这个思路,我们使用图3中的例子。如该图所示,一个标准的线性拟合无法保证输入x 附近的样本仍然在线性局部空间内。这可能轻易导致一个不精确的拟合以及低精度的解释。如图3右边所示,用一个多边的边界来拟合局部决策边界(每一条蓝色的直线代表了一个独立的线性回归模型)。其中最好的拟合是穿过数据点 x 的红线。我们的拟合过程可以产生一个最好的线性回归模型来定位重要的特征。
模型构建
我们把Fused Lasso作为正则项加到mixture regression model中,为了估计模型的参数,需要求解如下的优化方程:
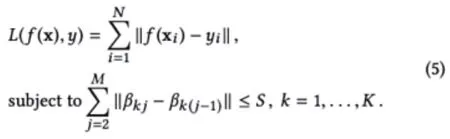
其中f是regression mixture model,β是参数。为了求解这个优化方程,我们需要使用期望最大算法(E-M)。为了使用EM算法,可以把模型等价改写为如下形式:

其中π,β,σ2是需要估计的参数。首先我们随机初始化参数,然后重复进行EM算法的E步和M步直到算法收敛。下面我们简单介绍一下具体算法。
从公式中可以看出,y服从一个由K个Gaussian distribution组成的distribution。每个Gaussian有自己的mean(β)和variance (σ2)。在每一次迭代中首先进行E步,我们把每个样本点分配到一个Gaussian。这里使用的分配方法就是标准的EM算法的E步。完成E步后,根据新的数据分配结果,我们使用每一个Gaussian自己的数据来更新它的mean和variance。更新variance的方法和标准EM相同,但是因为加了Fused Lasso的正则项在mean上,所以更新mean相当于求解如下优化方程:

重复E步和M步直到模型收敛,进而输出模型参数。
如何使用本文提出的模型解释神经网络的结果?具体而言解释过程分为以下两步:近似局部的决策边际和生成解释。
给定一个输入样本,生成解释的关键是近似深度学习模型的局部决策边际,从而获知聚类该样本的重要特征。为了实现这个目的,我们首先生成一组人工样本,然后使用这些数据来模拟目标模型的局部决策边际。有两个可能的方法来实现模拟:第一种是使用一个混合回归模型进行多类分类;第二种是对每一个类使用一个混合回归模型。考虑到计算复杂度,我们使用第二种方法。
如前所述,对于一个给定的样本点,我们的解释是抓取目标模型聚类该样本时依据的重要特征。首先通过上述方法得到一个混合线性回归模型(mixture component)。这个线性回归的参数可以被视为特征的重要性。具体来说,我们把拥有大系数的特征作为重要的特征,同时选择最重要的一小组特征作为解释。
需要注意的是, 虽然LEMNA是为了非线性模型和特征相关性设计的,但这并不意味着LEMNA不能解释其他的深度学习模型(MLP和CNN)。事实上,LEMNA是可以根据所解释的深度学习模型调整的。比如,通过增加fused lasso的超参数S,我们可以放松这个正则项,进而使LEMNA适用于假设特征独立的深度学习模型。
猜你喜欢
故事作文·高年级(2022年2期)2022-02-24
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
中学生数理化·高一版(2021年2期)2021-03-19
现代装饰(2020年4期)2020-05-20
电子技术与软件工程(2019年18期)2019-11-18
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
中国惯性技术学报(2018年4期)2018-11-08
卷宗(2018年14期)2018-06-29
