
基于改进极限学习机的电力需求预测研究∗
2019-05-07 02:32伟鲍毅戴波卢君波王
计算机与数字工程 2019年4期
孙 伟鲍 毅戴 波卢君波王 昆
(1.杭州天丽科技有限公司 杭州 310051)(2.国网浙江省电力公司信息通信分公司 杭州 310007)
1 引言
电力需求预测对电力公司的战略目标有着重要影响,预测的准确与否,对于电力行业的健康发展和经济的节约与否都有至关重要的作用,在国民经济中占有重要地位。所以,对于电力需求进行预测是十分必要的[1]。
针对电力需求预测,已经有部分学者进行了相关的研究。于松青等提出了采用系统动力学对山东的电力需求进行了分析,构建了相应的数学模型,并通过算例仿真,验证了此模型的有效性,并给出了对应的建议[2]。傅守强等将电力需求预测模型分解成三个方面,并采用VAR,GM等建立预测模型,通过马尔可夫和残差均方根来建立优化模型,并针对实际案例,验证此方法的准确性[3]。曾波采用改进的灰色预测模型对电力需求进行预测,将该方法在某市的电力需求上进行预测,预测效果良好,表明了此方法的有效性[4]。龙禹等将电力数据按阶段进行划分,采用熵权法求取每个阶段的不同权重值,在负荷预测中,预测精度较高[5]。于松青等采用偏最小二乘法原理,对山东的电力需求进行预测,预测精度高达98.09%[6]。
虽然上述对电力需求侧的预测较多,且成果也很显著,但是,由于各个地区的经济、气候、环境等的不同,预测方法也不是通用的,所以,本文提出了基于改进极限学习机的电力需求侧预测模型,该模型将历史数据进行数据处理后,将对电力需求有影响的因子作为模型的输入,将需求侧的负荷作为输出,这样的模型简便且可移植性较高,在不同地区的电力需求预测中,只要采集的数据可靠,则均可实现可靠的电力需求预测。
2 电力需求侧分析
2.1 电力需求的特点
对电力需求的特征和走势进行分析,对于有效预测电力需求具有重要意义。为此,本文将对电力需求预测的分为以下几点进行研究。
1)工业用电
其特点是用电量大且稳定。据统计,我国目前的工业用电占所有用电量总和的75%左右。而工业用电的行业不同,由于生产过程的特征和工艺不同,用电量的大小也不一样。比如,冶炼行业用电量大且稳定,负荷不高。同一种设备如果连续进行作业的用电量会超过采用倒班制度下进行作业的用电量,同样也使负荷率增大,倒班次数多的用电量又会低于倒班次数低的用电量[7]。但是各个工业不同行业所用的月,年等总用电量呈现平稳的形式。大部分行业的工业用电与季节无关,除非是某些特殊的行业需要在特定的季节进行生产。由于工业生产用电的上述特点,就保证了我们对电力需求进行预测的可行性以及可靠性。
2)农业用电
据统计,我国农业用电所占比例不高,4.2%左右。农业用电大都会随着季节的不同而变化。农业用电每天不会发生很大的差异,但是若按月和年来评判,其差异较大。比如说,抽水灌溉用电,在冬季时用电量较低,夏天对电量的需求较大。所以,对农业用电需求进行有效预测,可以降低电量损耗,提高经济效益。
3)交通运输用电
目前,我国交通运输所需要的用电量不是很多,大概为3%左右。在交通运输的用电中,比较稳定的是铁路运输行业,由于铁路运行的规律性,稳定性,其用电需求也比较稳定,而且每日,每月以及每年的用电量相差不大,变化率仅为0.7%左右[8]。其他运输行业的用电量每天的变化较大,但是按月,季,年来计算,则差别不明显。随着我国动车、高铁等项目的逐步推进和发展,铁路行业的用电量会逐年增长。总的来说,交通运输业的用电量比较稳定,不会有大的差异,这就为交通运输业的电力需求预测提供了便利条件[9]。
4)居民生活用电
随着现代化进程的加速,我国居民用电量逐步提升,但是生活用电所占比例不高,仅为10%左右。与其他用电量较多的国家相比较,有较大差距[10]。
居民用电量的特点是每天的用电量不同,有较大差异。日符合率较低,0.4%左右,但按月来说不会有大的差异。照明和家用电器用电是居民生活的主要电力消耗部分。照明用电每天的差异较大,而且时间集中。而且由于空调的大量使用,使夏季的用电量上升,而冬季主要为照明用电[11]。所以,居民用电要合理进行规划,按其不同阶段所需的负荷不同,进行合理调整。
5)动力用电
动力用电是和用电设备的容量紧密关联的。随着我国自动化水平的逐渐提升,目前的动力电用电量也逐步提升,在我国用电中所占比重逐渐加大。而且用电时间也呈现逐渐增长的趋势。所以要对动力电的用电时间,容量等进行合理统计,以便预测其用电量。
2.2 电力需求预测的原理和过程
2.2.1 电力需求预测原理
电力需求预测就是根据当前生产状况以及行业用电特征,预测其用电量趋势。用电需求预测的基本原理为
1)可知性
对电力需求的预测要确保预测人员对过去,当前,以及将来的用电量是本人们所认可的。
2)可能性
因为电力需求侧存在的各种不稳定性,使电力负荷的预测也存在着各种可能性,在预测的时候,针对各种不同的情况要进行全面的预测[12]。
3)连续性
由于电力负荷的发展是连续的、不间断的过程,所以可以通过对过去现在将来的负荷不同,进行相应的趋势预测[13]。
4)相似性
将电力需求的当前情况,在过去的电力负荷情况当中进行相似案例寻找,从而推导预测当前和未来的电力需求情况[14]。
5)反馈性
当预测的电力负荷与实际的电力负荷存在差别的时候,可以实时调整预测模型,使其更符合实际值[15]。
6)系统性
对电力需求侧的预测要将电力需求侧各个用电环节综合起来,看成一个整体,对每个用电量进行合理的预测指导,掌控其发展动态。这样才能提高预测的精度[16]。
2.2.2 电力需求预测的过程
电力需求预测的过程包括准备、实施、评价等步骤。
1)准备阶段
此阶段的主要内容是收集,整理,分析资料,从而在其中提取出对电力需求预测有用的因素。在本文中要做的工作就是确定预测目标作为输出,找出对预测目标有影响的因素作为输入,整理数据,以表格形式存储[17]。
2)实施阶段
本文选择改进的极限学习机模型作为预测模型,带入整理阶段的输入量和输出量,来预测将来的用电需求。由于电力需求侧的各种影响因素会随着时间发生变化,比如经济、天气等,所以,要求预测人员根据实际情况实时调整模型的参数,从而为准确预测做好准备[18]。
3)评价阶段
对预测出来的结果进行评价,若评价结果误差小于预定的阈值,则判定该评价方案的可行性。在电力需求侧负荷预测的过程中,认为短期预测误差在3%以内,中期在5%以内,长期在15%以内[19]。
3 改进极限学习机模型
3.1 极限学习机(Extreme Learning Machine)
ELM是一种新型的单隐层前馈神经网络(SLF⁃Ns)。典型的ELM是随机获取输入层到隐层神经元之间的权值和阈值矩阵,然后用最小二乘法计算输出权值[20]。
极限学习机的数学模型如图1所示。

图1 极限学习机的数学模型
ELM可以表示为
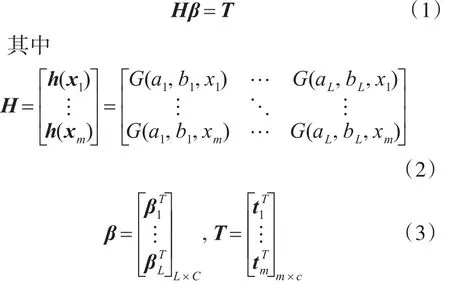
H是隐层神经元输出矩阵,(xi,ti) ∈Rd×Rc代表样本,G(ai,bi,x)表示第 i个隐层神经元的激活函数,如果H不是方阵,那么上述线性系统的最小二乘法基准是:

H†是矩阵H的伪广义逆矩阵的逆。这样,ELM可以概括为如下:
输出:ELM对回归和分类的预测功能。
1)随机产生隐层神经元参数矩阵W∈Rd×L。
2)隐层神经元输出矩阵H=G(W,X)。
3)输出权值向量 β̑=H†T 。
4)决策函数:

3.2 遗传算法
遗传算法(genetic algorithm,GA)的执行过程:
Step1:初始化。
随机产生M 染色体Y(0),交叉、变异值为Pc,Pm,迭代次数N。
Step2:计算个体适应度。
求第t代的适应度函数。种群 f(y),y∈M ,M={y1,…,ym},yi={x1,…,xm}。Oj,Tj为第j个预测输出和实际输出,n是数据总数。

Step3:进化。
选择:在Y(t)中取L个染色体L≥M 。
交叉:取L2对染色体,与剩下的染色体编码部分进行交叉互换[8]。
变异:染色体按Pm进行变异。
Step4:选择子代:进化过后,生成M个染色体记为Y(t+1)。
选择方法——适应度比例法。假设被选择的概率为Pc。
yi为第i条染色体,fit(yi)为其适应度值。
具体步骤:
1)求取没个染色体的适应度值。
2对适应度求和,找出中间值S-mid,累加值sum=∑fit(yi)。
3)设定随机数N,0<N<sum。
4)值等于S-mid的染色体产生变异。
5)重复3)和4)过程。
Step5:终止进化。1)达到终止迭代次数。2)达到设定阈值。取 fit(yi)最大的染色体作为最优解输出。

3.3 遗传算法优化极限学习机
Step1:初始化种群
初始化种群X,包括m个染色体,其中每个染色体xi都包括A·B个输入权值和B个阈值,并把初始群体作为第一代种群:

其中,akg是输入权值,bkh是隐层神经元阈值,初始群体中的权值和阈值是随机获取的。
k=1,2,…,m;g=1,2,…,A;h=1,2,…,B
Step2:计算适应度
xi由输入权值向量ωi和阈值向量bi组成

用ELM求输出权值的方法求隐层神经元输出权值β:
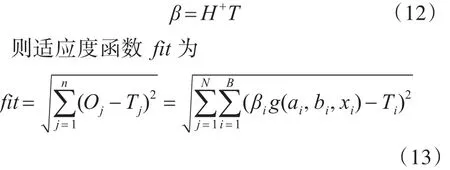
Step3:选择染色体
计算出每个染色体的适应度后,对种群进行选择,交叉,变异等操作,形成新一代种群。继续进行优化运算,直到达到设定的遗传代数,选出此时适应度最高的染色体作为优化后的输入权值和阈值[21]。
3.4 改进ELM预测电力需求的过程
1)采集电力需求侧负荷的数据。
2)对采集到的数据进行处理。
3)将数据按照属性不同分为输入,输出因子,并带入改进的极限学习机模型进行预测。
4)对预测的结果与实际用电需求进行对比,求取误差,调整预测模型。
4 基于改进极限学习机的电力需求预测算例分析
4.1 案例仿真
针对上述所提电力需求侧预测的过程,本章结合实际案例进行仿真分析。
选取某供电企业2015年行业售电量数据以及其他影响因子进行仿真预测分析。
由于大工业,非普工业,商业用电受温度影响较小,所以将上述数据分成两类,受GDP影响而不受温度影响的数据,数据处理后采用改进极限学习机方法进行预测如表2所示。受温度影响较大,GDP影响较小采用改进极限学习机进行预测后的结果如表3、4所示。
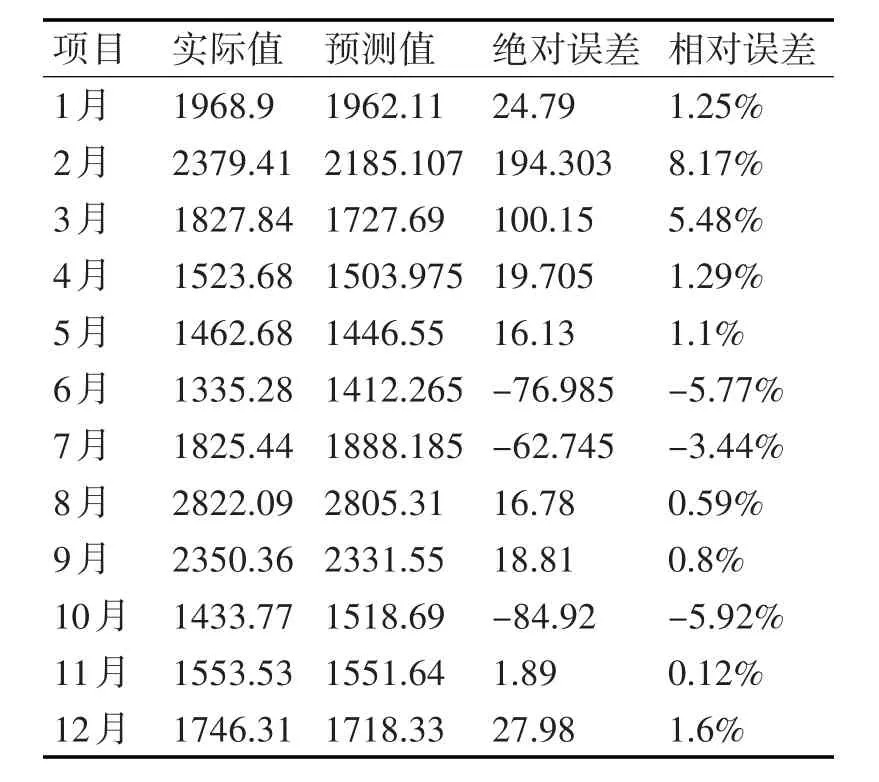
表3 生活用电需求预测分析(单位:万千瓦时)
4.2 结果分析
经过数据预处理之后,对上述电力需求侧用电负荷进行预测。其中大工业用电量,非普工业用电量,商业用电的数据拟合程度较好,精度较高。在居民生活用电的预测上面,只有2月的预测误差较大,达到了8.17%,其余时间段的误差与实际值均比较吻合,还需要进一步改进网络预测模型,以期使预测结果的拟合度更高。非居民生活用电中,预测值与实际值的误差较小,预测较稳定。

表4 非居民生活用电预测(单位:万千瓦时)
在本文所提的基于改进极限学习机的电力需求预测模型中,考虑了GDP,温度,季节等各个方面对电力负荷的影响,使预测模型趋于全面准确地反映实际电力需求量的值。通过对2015年电力需求值进行预测,也证明了本文所提方法的预测精度较高,具有一定的实用性。
但是因为各个电力企业的经济,气候等不同的原因,想要实现精确的预测还有一定的挑战性。本文所提的方法,可以为各地的电力需求预测提供理论指导意见。
5 结语
针对电力需求侧负荷的预测,本文提出了一种改进的极限学习机模型,通过模拟退火算法对极限学习机训练过程中的网络模型进行优化训练,从而得到更优的网络模型。将改进的极限学习机模型应用在电力需求预测上,实际的仿真结果表明,在大工业、非普工业、商业、居民生活用电和非生活用电的预测上面,均具有良好的精度,验证了此方法的适用性,为将来更准确可靠地建立电力需求预测模型提供了有利的依据。
猜你喜欢
矿山安全信息(2022年11期)2022-11-26
电力设备管理(2022年8期)2022-11-25
国企管理(2022年3期)2022-05-17
保健与生活(2022年10期)2022-05-06
文萃报·周五版(2021年30期)2021-09-05
软件(2020年3期)2020-04-20
微电脑世界(2009年3期)2009-04-03
