
基于朴素贝叶斯的钓鱼网站检测研究
2019-05-07 02:03张双全
通化师范学院学报 2019年4期
黄 炎,张双全
钓鱼网站常常通过电子邮件,仿造和伪造正常网址来对用户进行欺诈.钓鱼网站通常伪造用户心中可信度较高的品牌网站,在欺诈过程中窃取用户的个人信息、银行卡账户及密码等,钓鱼网站的出现不仅对用户的利益造成了损失,也对网络金融和电子商务等领域发展造成了极大影响[1].
目前主要的钓鱼网站检测途径有两种,一种是“黑白名单”检测,就是通过对待测URL与钓鱼网站库进行对比,如果钓鱼网站库存在与待测URL相同的网址,则将该待测URL判定为钓鱼网站,这种方法的时效性极差,钓鱼网站的更新速度极快,且制作成本极低,“黑白名单”检测显然不适合现在的网络环境,另一种就是基于启发式的检测方法,通过对URL进行特征分解,并建立合适的检测模型,通过模型的判定函数来检测待测URL是否为钓鱼网站[2].
2008年,Daisuke Miyamoto等采用9种机器学习方法对钓鱼网站进行分类研究,结果表明AdaBoost分类器在钓鱼网站检测中的效果最好,最小错误率为14.15%.2015年,何禹德等利用决策树和随机森林方法构建钓鱼网站检测模型,实验结果显示随机森林的准确率达到96.5269%[3].本文不仅选取检测准确率和均方根误差等常见指标来对模型进行评估,而且为了检测模型的泛化能力引入了roc曲线,roc曲线是用来评估分类器泛化性能的工具之一,所谓泛化能力,是指通过训练样本得到的分类模型能否很好的适用于测试样本[4]
1 模型介绍
机器学习作为人工智能的一大分支,随着大数据研究的兴起,机器学习成为了人工智能的核心领域.机器学习是指通过算法使机器能够从大量的历史数据中学习到数据本身潜在的规律特征,并能够建立适当的模型,可以用来对未来数据进行预测分析[5].机器学习的这一特点,使得它比“黑白名单”法更适用于钓鱼网站的检测研究.
1.1 KNN模型
K邻近算法(K-Nearest Neighbor algorithm,KNN)是机器学习经典算法之一,Cover和Hart在1968年首次提出,具有精度高和对离群点不敏感的优点.KNN算法的主要思想是通过给定测试样本,寻找与待测样本距离最近的K个训练样本,并根据这K个训练样本的类别,采取“投票法”来决定待测样本的类别[6].KNN算法中常用的距离计算公式一般有三种,分别是曼哈顿距离、欧式距离和闵可夫斯基距离,本文采用的距离计算公式是欧氏距离,假定在n维实数空间中,有样本X个则样本之间距离为其中,t为属性个数t=1,2,…,n,本文选取的最近邻样本的个数K为3.
1.2 朴素贝叶斯模型
朴素贝叶斯算法(Naive Bayes algorithm,NB)自20世纪50年代以来得到了广泛的研究,NB算法与KNN算法一样都是基于样本集来构造判别模型的,NB算法的基本思想是假设样本集中属性与属性之间是独立同分布的[7].根据先验概率与待测样本属于各个类别的条件概率来求得后验概率,选取后验概率最高的类别进行决策.给定n维样本空间X,x∈X,由贝叶斯定理我们可以得到:
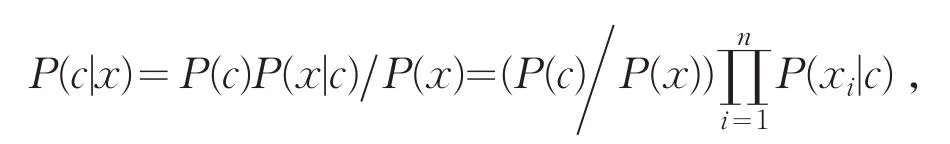
其中,n为数据集中属性个数,xi表示样本x所对应第i个属性上的取值,N为所有可能出现的类别D={c1,c2,…,cN},P(c)表示先验概率,P(xi|c)表示训练样本中不同类别与各个属性组合所出现的概率.对于给定样本x,P(x)与类别标记无关,计算类别标记c的所有可能取值,选择输出概率最大的结果,上述公式可以改写成如下式子
令M表示训练集,Mc表示第c类样本组成的集合,则P(c)的表达式可以写为P(c)=由于本文采用的数据是离散型的,Mc,xi表示Mc中第i个属性取值为xi样本组成的集合,则条件概率P(xi|c)的表达式可以写为
2 钓鱼网站数据说明
2.1 数据来源
本文采用的数据来自于UCI中的Phishing Websites数据集,该数据集由哈德斯菲尔德大学提供,共有11055个网站信息,属性个数为30个,其中正常网站6157个,钓鱼网站4898个.
2.2 主要数据属性说明及规约
钓鱼网站通常与正常网站的网页内容极其相似,但是网站地址中往往存在着钓鱼网站中的某些特征,例如:
(1)是否存在外部链接指向该网站:正常网站通常有2个以上的外部链接.
(2)网站是否能在Google索引中找到:钓鱼网站往往只能在短时间内访问,因此钓鱼网站可能不在Google索引中.
(3)URL地址是否过长:钓鱼网站制造者通常使用长URL来隐藏地址栏中的可疑部分.
(4)网站的重定向次数:正常网站的重定向次数最多为1次,而钓鱼网站的重定向次数往往多于一次.
(5)URL地址中是否存在“@”“//”“-”等符号:正常网站的URL中很少出现这些符号.
数据集中的主要属性说明及规约方式如表1所示.
从表1可以看出,即使钓鱼网站和正常网站的网页内容相似,但钓鱼网站的URL地址与正常网站的地址是有很大区别的,我们可以利用URL地址的某些特征来建模,来对待测网站进行检测.

表1 主要属性说明及规约方式
3 实验结果分析
本文选取90%的数据样本作为训练样本,10%的数据样本作为测试样本,分别使用NB模型和KNN模型进行训练和测试,两种模型的测试结果如表2所示.
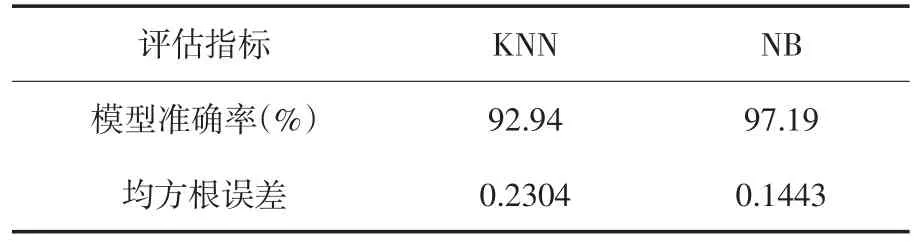
表2 两种模型的测试结果
均方根误差可以用来衡量数据样本待测值与真值之间的偏差,检测模型对于异常数据样本的敏感度,从表2可以看出,NB模型的均方根误差小于KNN模型,NB模型对于异常数据样本的敏感度要弱于KNN模型.NB模型的准确率97.19%也高于KNN模型的92.94%.虽然NB模型和KNN模型在钓鱼网站的检测准确率都高于90%,都可以应用于钓鱼网站检测应用中,但NB模型对于异常数据样本的敏感度要弱于KNN模型,NB模型的准确率也高于KNN模型,NB模型和KNN模型的roc曲线如图1所示.
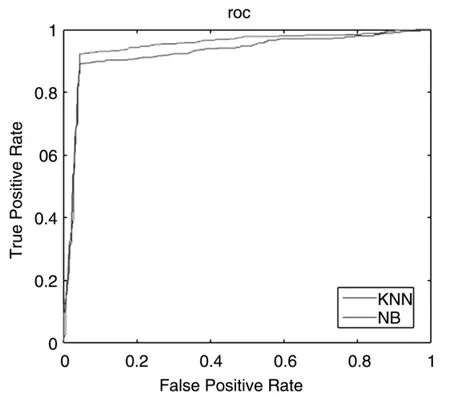
图1 KNN和NB模型的roc曲线
在机器学习中通常使用roc曲线来描述模型的泛化性能,所谓泛化性能是指该模型能否适用具有同一规律的新数据,曲线与横轴围成面积越大说明该模型的泛化性能越优.从图1可以看出,KNN模型和NB模型的roc曲线与横轴所围成的面积都接近于1,都符合优秀分类器的标准,但KNN模型的roc曲线被NB模型roc曲线包裹,这也说明了NB模型的泛化能力要优于KNN模型,更适合对未来钓鱼网站数据进行检测.
4 结论
现今,网络的发展速度日益加快,钓鱼网站的存在影响着金融网络的发展,对人们的财产安全造成了极大的威胁,钓鱼网站更新速度快、制作成本极低,每年都有许多人被钓鱼网站窃取个人信息或个人账户密码,“黑白名单”的检测方法已经不适合现在的网络环境,我们需要时效性和准确性更优的检测方法,本文选取的KNN和NB模型来对钓鱼网站进行检测研究,结果表明NB模型在钓鱼网站检测研究中具有更高的准确性和泛化能力.
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
中学生数理化·高一版(2021年2期)2021-03-19
少儿画王(3-6岁)(2020年4期)2020-09-13
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
小学生导刊(低年级)(2016年8期)2016-09-24
小学科学(2015年6期)2015-07-01
小学科学(2015年6期)2015-07-01
小学科学(2015年5期)2015-06-08
西南学林(2011年0期)2011-11-12
