
一种自适应子融合集成多分类器方法
2019-05-08 12:58
计算机测量与控制 2019年4期
(1.广西师范学院 计算机与信息工程学院, 南宁 530023;2.广西科技师范学院 数学与计算机科学学院,广西 来宾 546199)
0 引言
模式识别领域中普遍存在的一个问题是,同一个分类方法在不同的应用中分类性能不尽相同。没有哪种分类方法能够普遍适用于所有的分类情况。为了解决这样的问题,分类器融合技术成为了模式识别领域的一个重要技术。当前许多研究表明,多分类器融合技术对于模式识别的性能有较大的提高[1-3]。目前多分类器融合技术已经在很多领域上得到实践,例如图像分类、语音识别、手写技术识别等[4]。模式识别领域统一将分类器技术划分为以下两种形式:分类器动态选择[5]和分类器融合。动态分类器选择方法的核心思想是:预测当前识别任务多分类器系统中识别最准确的基分类器,选择预测的基分类器作为多分类器系统融合决策的输出。而分类器融合方法的核心思想是:全面地考虑每一个基分类器的决策输出,结合每一个基分类器的决策输出作为多分类器的最终决策输出,这种思想会得到更多的决定性决策信息。
基于这两种思想比较,更多的学者致力于研究多分类器融合方法。常规的多分类器融合技术包括多数投票法[6],人工神经网络法,加权平均值法,决策模板[7]和D-S证据理论[8],行为-知识空间方法(BKS)[9]等。存在的问题是,一些基分类器存在实时性能不稳定的情况,所以在使用多分类器融合方法时容易受到这种基分类器的影响而导致性能的不稳定。因此,更多的研究者开始把目光投向基分类器的选择,特别是集成过程中的基分类器选择[10]。这些基于基分类器选择的多分类器系统方法不再局限于基于单个或基于全部基分类器进行融合决策,而是灵活性地组合部分互补性强且对实时样本有较高识别率的基分类器来完成融合决策[11]。
一些研究发现,不同分类器对于分类具有互补性,异分类器的融合能够有效提高分类精度以及推广能力,而提高分类器间相异性的手段之一就是采用具有互补分类信息的多个不同特征集[12-13]。这些不同特征集可以是同一特征集的不同子集,也可以是异类或不同特征空间中的特征子集[13]。
针对上述动态选择基分类器与分类器融合方法存在实时性能不稳定的问题,本文提出一种自适应子融合集成分类器方法,首先通过有放回地随机选择样本完成样本集采样,产生多个不同的训练集,然后通过线性判决思想(Fisher线性判决思想是:一个好的特征应该使类内离散度尽可能小,而类间离散度尽可能大。)在不同训练子集中进行特征提取,并利用简单的分类器对输入的特征变量单独进行分类,最后基于本文提出的一种基分类器选择模型完成实时的子融合系统构建,并在该子融合系统上按分类的结果进行投票,选择得票最多的作为分类结果输出。
1 问题定义
多分类器系统作为一种集成分类算法(Ensemble learning),通过基分类器集合和组合规则或组合算法模型构成。根据基分类器决策输出信息的不同,多分类器系统一般被划分为三个不同的层次[14]:决策层融合(Abstract level),排序层融合(Rank level)和度量层融合(Measurement level)。在决策层融合层次上,各个基分类器的输出为某个确定的类别号;在排序层融合层次上,各个基分类器的输出为测试样本属于各类可能性的一个排序列表;在度量层融合层次上,各个基分类器的输出为测试样本属于各类的后验概率。
在实际应用中,大部分用于集成的基分类器可以获取类似于后验概率的中间度量值,如k-NN分类器可以利用测试样本到各类中心的最近邻距离来构建函数求取测试样本属于各类的可能性。这种可能性在同质基分类器构成的多分类器系统中可以作为基分类器选择的考虑因素。因此,本文主要研究度量层融合层次之上的多分类器联合方法。
1.1 数学定义
度量层融合层次的多分类器系统问题可以定义如下:
输入:
[e1(x)e2(x) …eK(x)]:各基分类器对样本x的识别输出,其中,ek(x)=[ω(C1)ω(C2) …ω(CM)](k∈{1,2,…,K}),ω(Ci)∈[0,1],ω(Ci)(i∈{1,2,…,M})为后验概率、隶属度或某种模糊测度,说明样本x归属于各类的程度。
输出:
E(x)=Ci:多分类器系统识别样本所归属的类别,其中i∈{1,2,…,M}。
输出结果的获取可以通过多种不同形式实现,常见的有提取最大值、计算平均值和加权平均等。
1.2 相关定义
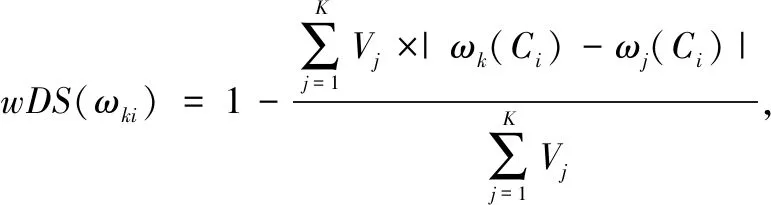
上述定义中,分量ωk(Ci)与ωj(Ci)的距离越小,说明它们之间的决策支持度越大。反之,则说明决策支持度越小。
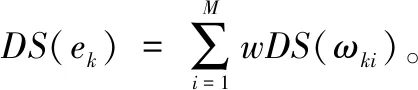
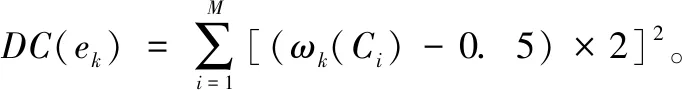
上述定义中,第k个基分类器识别样本x归属于Ci类的程度ωk(Ci)越靠近[0,1]区间中值0.5,其决策置信度越小.反之,则说明决策置信度越大。
2 自适应子融合系统
自适应子融合系统可以针对不同的输入样本,动态挑选出不同数目的基分类器组成子融合系统进行样本识别。根据上述实时决策支持度和实时决策置信度的定义,设计基分类器动态挑选的策略,其过程为:首先提取实时决策支持度最高的基分类器,然后在多分类器系统中将其它基分类器的实时决策置信度一一与该基分类器的实时决策置信度进行比较,动态选择出比该基分类器实时决策置信度高的基分类器,并一起构成子融合系统,最后通过简单多数投票决定输入样本所归属的类别号。
为了提高多分类器系统的泛化能力,自适应子融合系统通过有放回随机选择多个不同的训练集,并在这些训练集上通过线性判决思想随机动态地提取特征构成各基分类器训练的特征子集。自适应子融合系统的方法模型框架如图1所示。训练样本和训练特征集的差异保证了多分类器系统中基分类器的互补性。
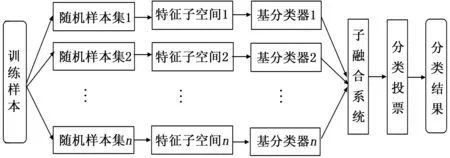
图1 自适应子融合集成分类器方法模型
2.1 特征子集生成
在每个随机训练样本集基础上随机提取有较优线性可分性的特征子集,首先在特征集上随机地限定特征提取范围,该提取范围为随意的部分特征组合,以提高基分类器的差异性。然后,在随机挑选出第一个特征的基础上利用线性判决思想在这些随机提取的特征组合中通过迭代重组出线性可分性较强的特征子集。具体特征子集生成算法如算法1所示。
算法1:特征选择:
Input: 特征集F.
Output: 特征子集S.
1)获取特征集F的特征个数m;
2)初始化: Lsd=0, max_Lsd=0, first_i=0, S=φ,i=0;
3)随机生成长度为m的二进制字符串a;
4)在a中随机选择值为1的某个位置first_i;
5)S=S∪{F[first_i]};
6)max_Lsd=calculate_Lsd(S);
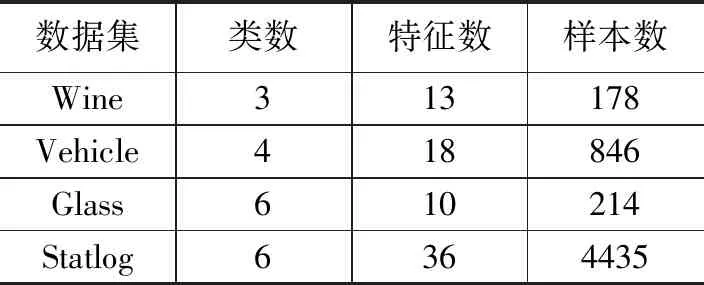
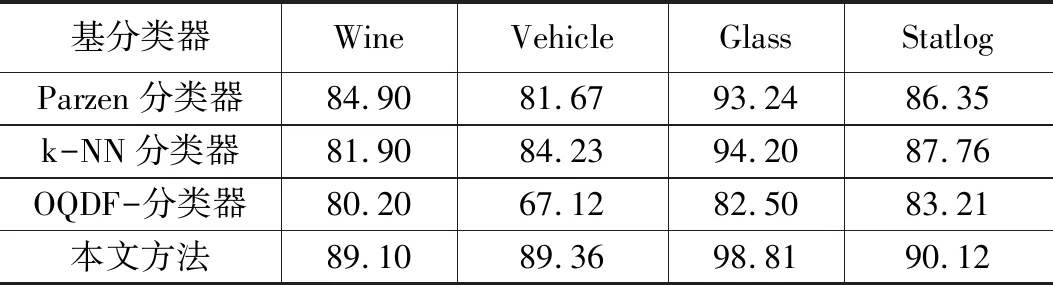
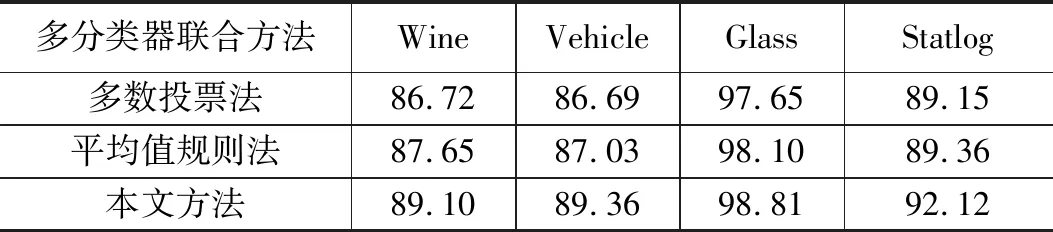
7)while i 8) if (a[i]==1 && i!=first_i) then 9) Lsd=calculate_Lsd(S∪{ F[i]}); 10) if Lsd>max_Lsd then 11) S=S∪{F[i]}; max_Lsd=Lsd; 12) end if 13) end if 14) i++; 15)end while 16)return(S,a). 其中,步骤6)中calculate_Lsd函数为特征集输入参数S在当前随机样本集中的线性可分度,线性可分度Lsd的计算公式如式(1)所示。其中,c为特征集S存在的类别数,Xi为当前随机样本集中属于第i类的样本集合。 (1) 特征子集生成算法在自适应子融合系统中是基于多个不同样本集分别实现的,其实现过程可以并行处理。因此,有可能存在相同的特征子集被不同基分类器提取。本文通过两种不同的策略来优化提取的特征子集,提高基分类器的差异性。这两种策略分别是变异策略和交叉策略,具体方法如下所示: 交叉策略:随机选择一个不同的特征选择向量a2,在a2中随机选择一个交叉区域,将a的相应交叉区域由a2交叉区域代替。 例如,存在相同特征子集的特征选择向量为a=10011100,选择的a2为a2=00100110,交叉区域为0011,则进行交叉操作后有:a=10000110。 通过双重循环将所有生成的特征子集进行比较,存在相同的特征子集进行1次或多次变异和交叉操作,直至得到一个与现有所有特征子集不重复的新特征子集。 在随机样本和特征子空间生成后,分别训练基分类器,因为自适应子融合系统基于1.2节中定义的实时决策支持度和实时决策置信度动态选择集成,所以动态选择基分类器操作在测试阶段进行。 首先通过多分类器系统中的各个基分类器对输入测试样本进行分类识别,然后分别计算各基分类器的实时决策支持度DS,并从中挑选出获得当前实时决策支持度最高的基分类器,将其作为自适应子融合系统的基分类器,并用该基分类器的实时决策置信度与其它基分类器的实时决策置信度进行比较,进一步挑选出实时决策置信度比其高的基分类器作为自适应子融合系统的成员,完成用来融合决策的子系统构建,算法流程如下: 算法2:基分类器动态选择. Input: 分类器集合E. Output: 分类器子集合S. 1)初始化:S=φ; 2)从E中选择当前样本识别中DS最高的基分类器ec; 3)S={ec}; 4)E=E-{ec}; 5)θ=DC(ec); 6)while E!=NULL 7) if DC(E[0])>θthen 8)S=S∪{ei}; 9) end if 10)E=E-{ei}; 11)end while 12)return(S). 该方法对于输出结果带有类似后验概率的分类器进行直接软迭代集成,对于其他输出形式的基分类器需要先将其输出值转化到[0,1]上的可信度,然后再利用算法。本文定义其输出值转化方法为: ek(x)=[Pk(C1|x),Pk(C2|x),…,Pk(CM|x)] 基于上述方法可以得到多分类器系统的决策矩阵如下: 自适应子融合集成分类方法融合了一系列基分类器的分类结果, 直接采用多数投票法来决定识别结果,让当前被自适应子融合系统选中的基分类器都对输入的特征向量进行投票,汇总各类得票数,找出其中拥有票数最多的类别作为融合系统对该特征向量识别的类别。 本实验使用的是UCI机器学习数据库中的四类数据集进行相关测试。数据集样本如表1所示。实验数据属于多分类样本数据集,需限定使用方法为多分类方法,以保证分类的效果,实验基分类器如表2所示。有效划分训练集与测试集比重往往可以提高分类的效率,参照先验知识且经过多次试验测试集与训练集比例,最终发现30%作为训练集、70%作为测试集的实验效果最好,因此我们将各类数据集分别按照0.3的比例划分。 本文将分类准确率作为衡量融合集成分类器方法识别效果的衡量标准,具体方法是测试集中分类正确数量占总测试集的百分比,公式如式(2): (2) 其中:Nk表示测试集中分类正确的数量,Nc表示测试集的总数。 表2实验结果数据表明,本文提出的自适应子融合集成分类方法与其他基分类器比较,本文方法的识别效果更优,在所用数据集都得到了有效提升。同时,表2也表明了在Vehicle数据集、Glass数据集上一些基分类器识别性能较差的现象。验证了本文前面提到的基分类器实时稳定性差从而导致一些融合方法的性能不稳定的问题。本文提出的自适应子融合集成多分类器方法从表3中明显证明识别性能优于其他两种多分类器融合方法,并且在Wine数据集和Vehicle数据集效果提升稍好于其他两类数据集。通过表2、表3,我们可以得出以下结论:多分类问题,数据类别越多,分类的准确率越高,即分类效果越好。 表1 实验的四类数据集 表2 本文方法与基本分类器识别准确度比较 % 表3 本文方法与其他多分类器联合方法识别准确度比较 % 从图2中,我们可以直观看到各基分类器与多分类器融合方法的分类性能,并且在分类性能上多分类器融合方法普遍优于基分类器方法,本文方法在识别准确率上同样高于所比较的其他分类融合方法。 图2 各基分类器与分类器融合方法性能比较 本文基于Fisher线性判决思想来完成随机特征子集内的特征选择有效提高基分类器的差异性,结合决策支持度DS与决策置信度DC完成基分类器的动态选择,并让每一个被选中的基分类器对输入的特征向量进行投票,计算所有投票数,获取子融合系统中投票数最多的类别作为当前输入样本的分类结果,有效提高了分类器识别性能。实验结果表明,本文研究的度量层融合层次之上的多分类器联合方法能获得较好的识别性能,较单个分类器的识别准确度都有所提高。 我们的工作存在如下不足:在未来的研究中需要解决的问题,如基分类器选择当前实时决策支持度最高者,是否可以通过先验概率或判别函数确定基分类器会有更好的分类效果。
2.2 基分类器动态选择
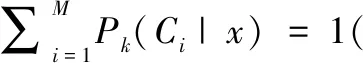
2.3 融合决策过程
3 实验结果与分析

4 结论
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
现代电子技术(2022年15期)2022-07-28
小型微型计算机系统(2022年4期)2022-05-09
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
计算机系统应用(2021年2期)2021-02-23
软件导刊(2017年4期)2017-06-20
中国科技纵横(2016年20期)2016-12-28
数学教学通讯·初中版(2015年5期)2015-06-17
