
基于集成学习的航空发动机故障诊断方法
2019-05-14 02:42席泽西王雍赟李晓露
中国民航大学学报 2019年2期
徐 萌,席泽西,王雍赟,李晓露
(中国民航大学电子信息与自动化学院,天津 300300)
航空发动机是飞机的心脏,其健康状况直接影响飞机的安全运行,而气路故障占航空发动机故障总数的90%[1],因此,及时准确地诊断航空发动机气路故障显得尤为重要。目前,基于解析模型、专家系统等算法的传统故障诊断方法仍存在较多不足。首先,航空发动机工作环境恶劣,内部结构复杂,难以建立精确的数学模型;同时,航空发动机气路故障中容易存在多重耦合,难以实现准确的故障隔离[2]。机器学习方法可以通过各类算法挖掘大量数据内部的潜在联系,十分适合复杂系统的建模分析[3]。张建等[4]使用支持向量机模型实现了航空发动机故障诊断,然而此类单一机器学习模型的特征空间存在较大局限,难以保证较高的故障诊断精确度。谢晓龙[5]使用随机森林算法实现识别速度更快的航空发动机故障诊断,然而该方法只能集成同类决策树模型,难以融合其他模型的优势特性,较大地限制了故障诊断性能。
针对上述不足,将Stacking集成学习方法应用于航空发动机故障诊断,以国内某航空公司机队的历史运行数据和发动机制造商(OEM,original equipment manufacturer)提供的故障报告为研究基础,从数据处理和模型设计两方面论述建模流程,最后进行仿真实验验证。集成学习是机器学习的一种推广,通过组合多个机器学习模型进一步提升整体性能与泛化能力[6],展现了更为强大的优越性。数据处理方面,首先选择4种关键气路参数,设置飞行循环观测窗口,然后设定训练样本集,并对输入向量做归一化预处理。模型设计方面,建立一种两层结构的Stacking集成学习模型,第1层选择组合RBF支持向量机(RBF-SVM,support vector machine with radial basis function kernel)、神经网络(NN,neural network)、随机森林(RF,random forest)及梯度提升决策树(GBDT,gradient boosting decision tree)4种基模型,集成原则是保证模型整体分类准确性;第2层选择逻辑回归(LR,logistic regression)模型,集成原则是降低过拟合风险,保证模型整体稳定性。仿真实验结果验证了该Stacking集成学习模型能更好地应用于航空发动机故障诊断。
1 Stacking集成学习算法
集成学习是训练一系列基模型,通过某种集成原则将各模型的输出结果进行整合处理,从而获得比单一模型性能更好的一种机器学习方法[7]。根据基模型是否属于同种类型,可分为同质集成模型和异质集成模型。常用的同质集成模型主要包括Bagging和Boosting,基模型常为差异度较大的弱学习器,最佳实现分别是RF和GBDT模型[8]。常用的异质集成模型主要包括多数投票法(MV,majority voting)和Stacking模型,基模型常为差异度较大的强学习器[9]。
Stacking的集成原理是分层组合多种模型,迭代学习上一层模型的分类偏差,提升模型整体性能[10];Stacking模型目前尚无最佳实现,需根据应用场景和实验效果自行设计模型结构。相比Bagging、Boosting等同质集成算法,Stacking算法可集成不同类型的模型,融合各类模型的分类特性,集成效果往往更好[11];同时,Stacking的分层结构可以在第1层基模型的基础上进一步学习,训练元模型,最终输出结果,故性能常优于MV异质集成算法。
Stacking集成学习模型一般为两层结构,如图1所示。第1层组合多个分类性能较高、差异度较大的基模型,在原始数据集上进行训练,输出各个模型的分类结果;第2层将上一层的输出结果组合成新的数据特征,在新构建的数据集上训练单个元模型,输出最终分类结果。Stacking算法的伪代码如下:

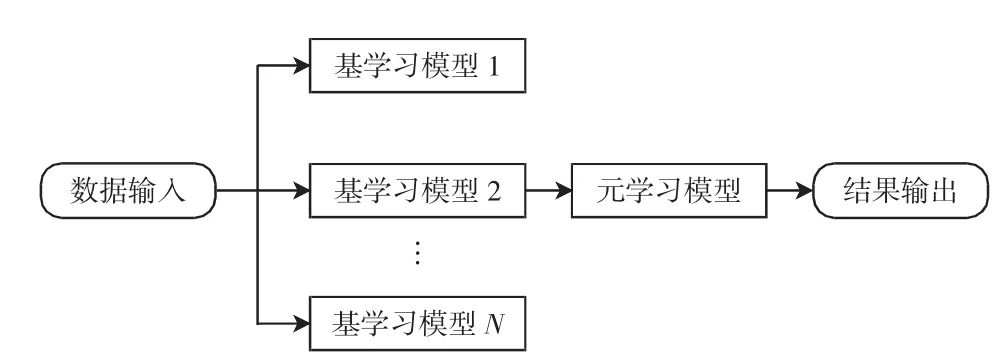
图1 两层Stacking模型结构Fig.1 Structure of two-layer Stacking model
2 航空发动机故障诊断模型特征工程
2.1 特征选择
气路参数在航空发动机状态监控与故障诊断中占有极其重要的地位。气路参数是航空发动机气流通道中的测量参数(如转速、温度等),与内部气动部件的工作特性(如效率、流通能力等)之间存在严格的气动热力学关系[12]。当发动机部件出现故障或性能衰退异常时,气路参数会与正常状态下的基线标准值产生偏差,偏差值的大小可反映当前发动机的性能状态。这种基于偏差值的气路部件分析法应用十分广泛。
发动机数据获取自国内某航空公司机队,型号为CFM56-7B系列,是一种典型大涵道比涡扇发动机。由OEM厂商提供的故障报告可知:排气温度偏差值(ΔEGT,delta exhaust gas temperature)、核心机转速偏差值(ΔN2,delta core speed)以及燃油流量偏差值(ΔFF,delta fuel flow)是监控发动机健康状态的重要偏差值参数;排气温度裕度(EGTM,exhaust gas temperature margin)是表征发动机整体性能衰退程度的重要指标[13]。通过上述4个关键气路参数的联合变化趋势,可评估发动机气路的健康状态,并将故障隔离到单元体。由此,选择 ΔEGT,ΔN2,ΔFF,EGTM 作为发动机气路故障诊断模型的特征参数。
每次飞行任务中,飞机会记录平稳飞行状态下各性能参数的均值,作为本次飞行循环的气路参数值。通常,从故障确认点前的若干飞行循环,气路参数值开始呈现异常趋势,即故障指征。故障程度不同,故障确认点与故障指征点相差的飞行循环间隔也不同,但通常在10个飞行循环之内[14]。为了包含更全面的异常趋势特征,设置观测窗口为10个连续飞行循环,即将每个特征参数扩展为10维的趋势特征向量,整体拼接成40维的发动机状态特征向量,作为模型输入。
以排气温度指示故障为例,图 2 中的(a)、(b)、(c)、(d) 分别为特征参数 ΔEGT,ΔN2,ΔFF,EGTM 在故障点前50个飞行循环内的变化趋势图。其中,P点为OEM厂商测定的故障点,虚线框为上文设定的10个飞行循环的观测窗口。分析图2可知,观测窗口内ΔEGT呈现较明显的上升趋势,EGTM呈现较明显下降趋势,此时ΔN2与ΔFF保持相对平稳趋势,与排气温度指示故障特征参数变化趋势相吻合,如表1所示。此类比照故障特征趋势进行故障识别的方法只能用于定性分析,更精确的故障诊断还需借助数据挖掘方法建立故障诊断数学模型。

图2 排气温度指示故障下特征参数联合变化趋势Fig.2 Joint change trend of characteristic parameters under EGT indication fault
2.2 设定样本集
训练样本选取的好坏直接影响模型性能,质量较差的训练样本会降低模型精度,极度不平衡的训练样本甚至会使训练结果不收敛。为保证故障数据均匀分布,从样本机队故障历史记录中剔除发生次数过少的故障,选取57台次发动机故障案例,其中包括4种典型气路故障:排气温度指示故障、燃油流量指示故障、可调放气活门故障、进口总温指示故障。各故障特征参数联合变化趋势[15]与样本数量如表1所示。

表1 航空发动机典型故障样本Tab.1 Typical fault samples of aeroengine
为保证故障数据与历史健康数据的相关性,选择每台发动机故障点前的200个连续飞行循环作为样本数据。已知观测窗口为10个飞行循环,故每个故障发动机数据样例可均匀分割为20个数据样本。选取的57台次发动机总共可切分为1 140个发动机数据样本,其中包括1 083个健康样本,57个故障样本。
3 航空发动机故障诊断模型建模流程
依据Stacking集成学习的数学原理,结合航空发动机气路参数序列的趋势特点,设计了一种两层结构的Stacking集成模型,实现航空发动机典型故障的智能诊断,建模流程如图3所示。
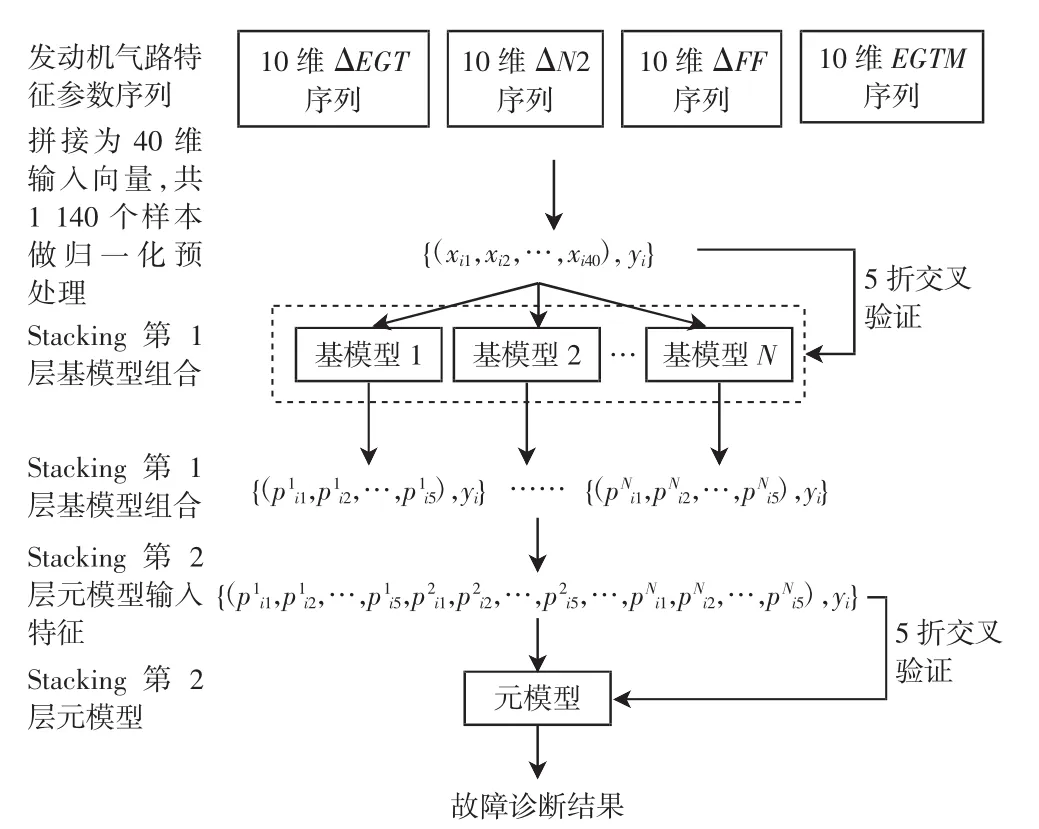
图3 Stacking故障诊断模型算法流程图Fig.3 Flow chart of Stacking fault diagnosis model
具体建模步骤如下:
1)将 ΔEGT,ΔN2,ΔFF 和 EGTM 4 种发动机关键气路参数对应的10个连续飞行循环序列数据,顺序拼接组合为 40 维发动机状态特征向量(xi1,xi2,…,xi40),共可得1 140 个样本,即(i=1,2,…,1140),样本包括5种故障类型(4种典型故障和无故障状态),然后对各输入向量做归一化预处理。
2)使用步骤1)中的912个样本,训练N种已知分类性能较高的典型模型,作为Stacking第1层基模型。每个基模型的输入为40维的发动机状态特征向量{(xi1,xi2,xi3,…,xi40)}及其对应的故障类型 yi,各个基分类器的输出值为样本属于每类故障的概率值(pji1,pji2,…,pji5),其中 i=1,2,…,912,j=1,2,…,N。
3)其余228个样本作为测试集,分别输入步骤2)中训练的N个基模型,从而得到每个样本属于5种故障的概率值(pji1,pji2,…,pji5),其中 i=1,2,…,228,j=1,2,…,N。
4)合并步骤2)得到的N个基模型输出决策值可得{(p1i1,p1i2,…,p1i5,p2i1,p2i2,…,p2i5,…,pNi1,pNi2,…,pNi5),yi},其中 i=1,2,…,912,作为 Stacking 第 2 层元模型的输入向量进行训练,从而可组建两层结构的Stacking集成学习模型。
5)合并步骤3)得到的N个基模型输出值:{(p1i1,p1i2,…,p1i5,p2i1,p2i2,…,p2i5,…,pNi1,pNi2,…,pNi5),yi},其中i=1,2,…,228,输入步骤 4)建立的元模型,得到测试样本的最终诊断类型。
6)依次重复步骤2)~5)共5次,即使用5折交叉验证遍历所有测试集样本,得到更为准确的故障诊断结果。
4 仿真实验及结果分析
仿真实验的硬件环境为双核CPU(主频2.3 GHz),DDR3内存(4 GB);软件环境为Windows 7操作系统,Python 3.5。该故障诊断任务可看作4种典型航空发动机故障以及无故障状态的多分类问题,应用场景中无故障数据较多,故障数据较少,常用的正确率难以评判模型性能,故模型性能评价标准选择更为普遍适用的精确率(PPrecision)和召回率(PRecall)。精确率表示预测为正的样本中有多少是对的,召回率表示样本中的正例有多少被预测正确,即

其中:TP表示真正例;FN表示伪反例;FP表示伪正例;TN表示真反例。
4.1 典型模型性能对比与分析
对比4种典型机器学习模型(LR、SVM、RBF-SVM和NN)与2种典型集成学习模型(RF和GBDT)在发动机数据样本集上的分类性能,选择性能较好的模型作为Stacking第1层基模型。
超参数选择的好坏直接影响模型性能,采用网格搜索法与5折交叉验证法对各个模型进行参数寻优,从而得到最优训练模型。以RBF-SVM调参为例,该模型最重要的两个超参数为:惩罚系数C和RBF核参数γ。其中:C代表对误差的宽容度,影响模型泛化能力;γ决定数据映射到高维空间的分布,影响模型训练和预测速度。依据调参经验设定C∈[0.001,1 000],γ∈[0.001,1 000],使用网格搜索法遍历该空间内所有参数组合,计算每组参数5折交叉验证得到的平均精确率,选择平均精确率最高时的参数取值。参数寻优热力图如图4所示,即最优超参数为C=1,γ=0.1,此时模型精确率为0.82。

图4 RBF-SVM网格搜索参数寻优Fig.4 Grid search parameter optimization of RBF-SVM
经参数寻优,得到各典型模型分类性能,如表2所示。分析可知:①典型机器学习模型中,LR和SVM性能较差,精确率与召回率均低于0.60;RBF-SVM和NN性能相对上述两个模型有较明显提升,原因在于该故障诊断任务输入向量40维,复杂度较高,LR和SVM此类线性模型难以完成该分类任务;②RBF-SVM是性能最好的典型机器学习模型,精确率达到0.82,召回率达到0.79;③集成学习模型RF总体性能最好,精确率达到0.88,召回率达到0.86,该模型不但训练速度比同为集成学习模型的GBDT快,而且比单一机器学习模型RBF-SVM和NN更快。这体现了RF基于Bagging算法集成多个决策树的高泛化性,以及支持并行计算的高效性。

表2 典型模型分类性能Tab.2 Classification performance of typical model
4.2 Stacking集成学习模型设计与分析
Stacking第1层基模型的选择主要依据2个方面:模型分类性能和模型差异性。根据表2中的性能对比,剔除分类性能较差的LR和SVM 2个线性模型。模型差异性尚无统一规范标准,组合尽量多的不同类别模型,使得组合差异度最大,选择RBF-SVM、NN、RF与GBDT 4种典型模型作为Stacking第1层基模型。分析可知:该组合可融合RBF-SVM在小型数据集上的优良性能和NN的非线性拟合性能以及RF和GBDT通过集成多个决策树模型引入的高泛化性。
设置Stacking模型第1层的4个基模型,选择不同模型作为第2层元模型进行对比,可得不同结构的Stacking模型性能,如表3所示。对比表2、表3可知:相比性能最好的基模型RF,Stacking第2层选择LR或SVM两种线性模型时,模型整体性能有较明显提升;选择RBF-SVM或NN时,整体性能基本保持不变;选择RF或GBDT时,整体性能有较明显下降。说明Stacking第2层选择RF、GBDT等较为复杂的模型时,容易引发过拟合,降低集成模型整体性能。综合上述分析,Stacking第2层应选择结构较简单的模型。仿真实验结果显示,第2层模型选择LR时整体性能最高,此时Stacking模型的精确率为0.93,召回率为0.92。

表3 不同结构Stacking模型分类性能Tab.3 Classification performance of Stacking model with different structures
综合上述仿真实验对比与分析,设计建立两层结构的Stacking集成学习模型,如图5所示。第1层选择分类性能较高且模型差异性较大的4种基模型:RBFSVM、NN、RF与GBDT,第2层选择结构较简单的LR模型,降低模型复杂度,防止过拟合。
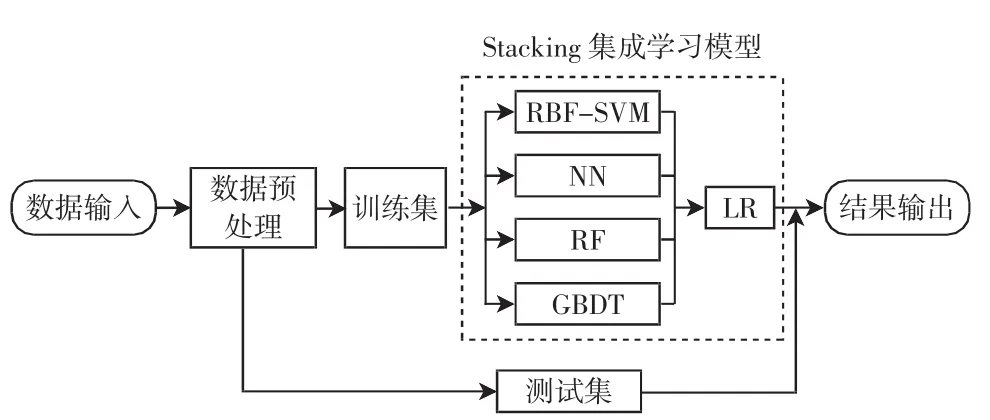
图5 Stacking集成学习模型结构Fig.5 Structure of Stacking ensemble learning model
4.3 Stacking集成学习与典型集成模型对比
将设计的Stacking模型对比同样组合RBFSVM、NN、RF与GBDT 4种基模型的MV多数投票集成模型,以及表2中性能最好的集成模型RF和性能最好的单一模型RBF-SVM,仿真实验结果如表4所示。分析可知:该Stacking模型的分类精确率相比MV提高约3%,相比RF提高约6%,相比RBF-SVM提高约13%;召回率相比MV提高约3%,相比RF提高约7%,相比RBF-SVM提高约16%。仿真实验结果表明该Stacking模型能在原有基模型基础上进一步提升泛化能力,相比已有的典型集成模型和单一模型有更高的分类性能,可以更好地应用于航空发动机故障诊断。
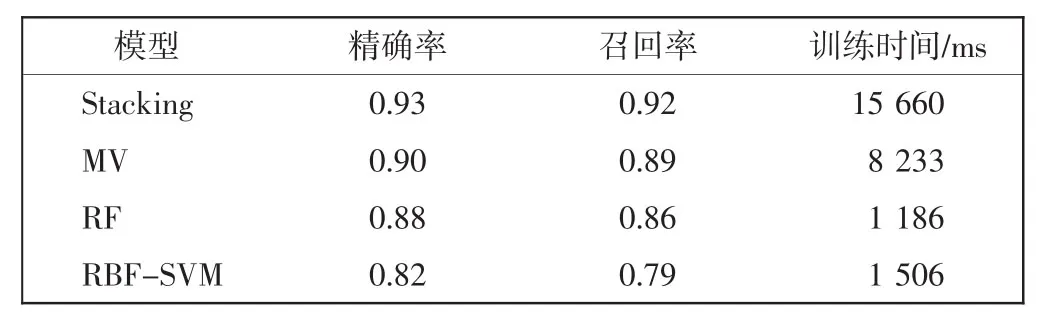
表4 Stacking模型与典型集成模型性能对比Tab.4 Performance comparison of Stacking model and typical ensemble models
5 结语
针对航空发动机结构复杂,难以实现准确故障诊断的问题,提出了一种基于Stacking集成学习的故障诊断方法。仿真结果证明了该故障诊断模型相比现有典型模型的优越性,同时也验证了所提Stacking集成原则的合理性:第1层选择组合精度较高、差异较大的模型,提升模型整体性能;第2层选择结构较简单的线性分类模型,防止模型过拟合。为航空发动机故障诊断提供一种新的思路和方法,也为构建基于Stacking集成学习方法的多分类模型提供设计参考。
猜你喜欢
一重技术(2021年5期)2022-01-18
矿业科学学报(2022年2期)2022-01-11
趣味(作文与阅读)(2021年11期)2021-03-09
趣味(语文)(2021年11期)2021-03-09
科学与信息化(2020年10期)2020-06-19
科学导报·学术(2018年11期)2018-10-21
电子制作(2018年10期)2018-08-04
北京航空航天大学学报(2016年6期)2016-11-16
IT时代周刊(2015年7期)2015-11-11
汽车电器(2014年5期)2014-02-28
