
水下声目标的梅尔倒谱系数智能分类方法
2019-05-22 09:39张少康田德艳
应用声学 2019年2期
张少康 田德艳
(1 海军潜艇学院 青岛 266000)
(2 青岛海洋科学与技术试点国家实验室 青岛 266000)
0 引言
传统水下声目标识别分类方法需要人工提取具有可推广性、泛化能力强的特征数据,其过程繁琐复杂,专业性强,需要人的参与,识别分类过程具有较强的人机交互特性。近几年,随着浮标潜标、水下滑翔机、AUV、UUV 等水下无人潜航器的发展,基于水下无人移动平台的声学探测体系正在不断建立完善。水下声目标识别分类是水声探测的“瓶颈”,同时也是关键技术之一。未来水下无人声学探测预警体系要求潜航器本身具备水下声目标识别分类能力,而传统水下声目标识别分类方法已无法满足此要求,因此研究智能化水下声目标识别分类方法具有重要意义。
一直以来,特征向量提取方法都是水下声目标识别分类的研究重点,基于听觉特征的水下声目标特征提取方法是研究热点之一,其中,基于语音识别方法提取梅尔倒谱系数(Mel frequency cepstrum coefficient, MFCC)进行水下声目标识别是常用的方法之一。如文献[1]介绍了差分梅尔频率倒谱系数的概念和相应的特征提取方法,对水下目标进行了基于MFCC 特征提取方法仿真研究和实验分析;文献[2]将MFCC 特征应用于船舶和鲸类水下声信号的特征提取中,提取了船舶和鲸类声信号的MFCC 特征,通过高斯混合模型对提取的MFCC特征进行训练和识别分类,讨论MFCC维数变化和不同MFCC 特征组合对识别分类性能的影响;另外文献[3–5]也进行了MFCC 特征提取相关方面的研究工作,并取得了一定的研究成果。近几年来,以深度学习为代表的人工智能算法发展迅速,深度学习是人工神经网络的发展,于2006年被提出[6],目前已发展出自编码器(Auto encode, AE)[7]、深度置信网络(Deep belief networks,DBN)[8]、卷积神经网络(Convolutional neural network,CNN)[9−10]、循环神经网络(Recurrent neural networks, RNN)[11−13]、生成对抗网络(Generative adversarial network, GAN)[14−15]及其相关变种等多种模型,在各个领域得到广泛的应用,其中,长短时记忆(Long short-term memory, LSTM)网络在语音识别领域应用效果显著。
深度学习具备从大量数据中自动学习特征的能力,但其在水下声信号识别分类领域的应用目前还处于起步阶段。区别于语音识别,水下声信号识别分类具有样本量少、数据获取困难等特点,因此有必要首先对其进行特征提取。从当前研究情况来看,采用MFCC特征提取方法对水下声目标信号进行特征提取和识别分类被证明为一种行之有效的手段,但上述方法均采用了传统的BP 神经网络或支持向量机(Support vector regression, SVM)模型作为分类器,相比之下,深度学习方法更具有挖掘深层次数据特征的能力,并更好地解决了模型训练过程中的梯度弥散和数据规模问题。另外,当前研究均针对水面舰船等有人平台的水声目标识别分类问题,而非未来水下无人平台。
未来水下无人平台进行水下目标识别分类的主要任务是能够正确区分水面、水下两类目标。因此,本文以此为研究目的,通过对水上、水下两类水声目标信号进行分析,提取MFCC 特征向量,作为样本有监督预训练长短时记忆网络模型,采用训练好的分类模型,对实际水声信号进行预测分类,验证了模型的有效性。
1 MFCC水下声目标特征提取与智能识别分类
1.1 MFCC水下声目标特征提取
MFCC 特征提取最早应用于语音识别,是一种有效的特征提取方法,其特征提取过程如图1所示[1]。
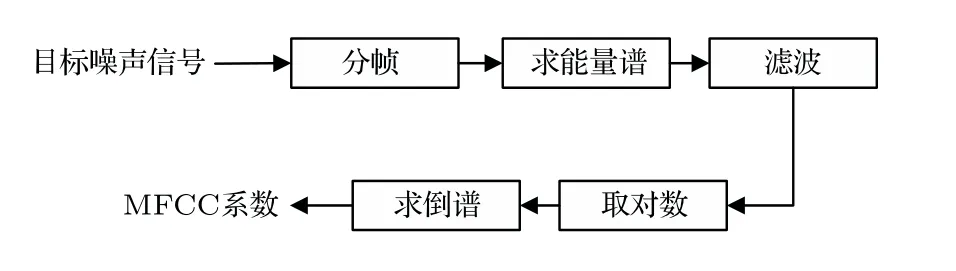
图1 MFCC 特征提取过程Fig.1 Feature extraction process of MFCC
(1)分帧
分帧是语音信号分析中常用的处理过程,由于目标噪声信号本质上是非平稳过程,具有时变特性,因此通常对信号作分帧处理进行短时分析,提取帧特征参数,最后由若干帧特征参数共同组成训练样本特征向量。为保持每帧信号之间的连续性,帧与帧之间存在交叠,称为“帧移”,本文每帧长度取25 ms,帧移取10 ms。
(2)求能量谱
通过快速傅里叶变换得到帧信号频谱,进而得到信号能量谱,其公式可表述为
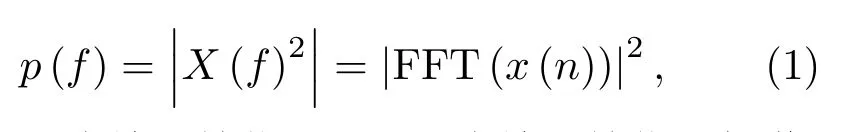
其中,x(n)为输入帧信号,X(f)为输入帧信号频谱。
(3)滤波
将求得的能量谱通过梅尔滤波器组,其公式可表述为
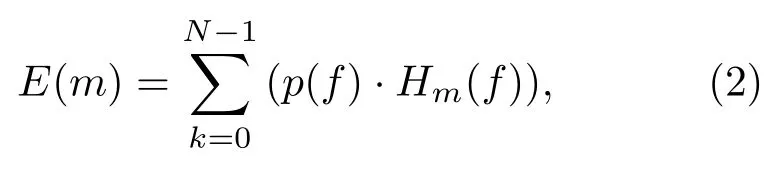
其中,N为各帧信号总点数,Hm(f)梅尔滤波器组系数。
(4)对数运算
将滤波后的能量谱作对数运算,其公式可表述为
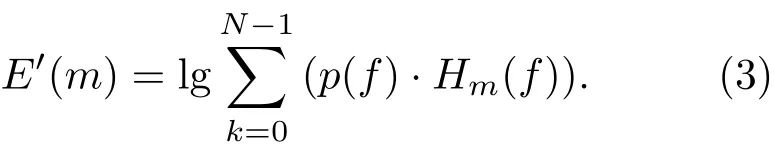
(5)求倒谱
将上述对数能量谱求离散余弦变换,即可得到MFCC参数,其公式表述如下:
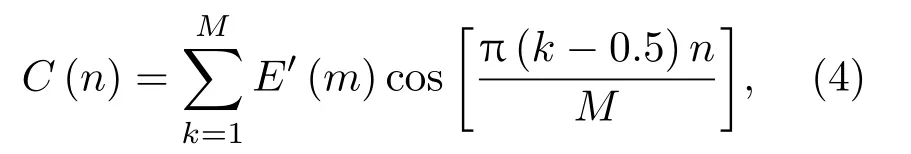
其中,n=1,2,··· ,p,p为MFCC阶数,M为滤波器个数。
通常MFCC参数只表述信号的静态特征,而差分梅尔频率倒谱系数则表征信号的动态特征。一阶差分及二阶差分梅尔倒谱系数计算过程分别如下所示:
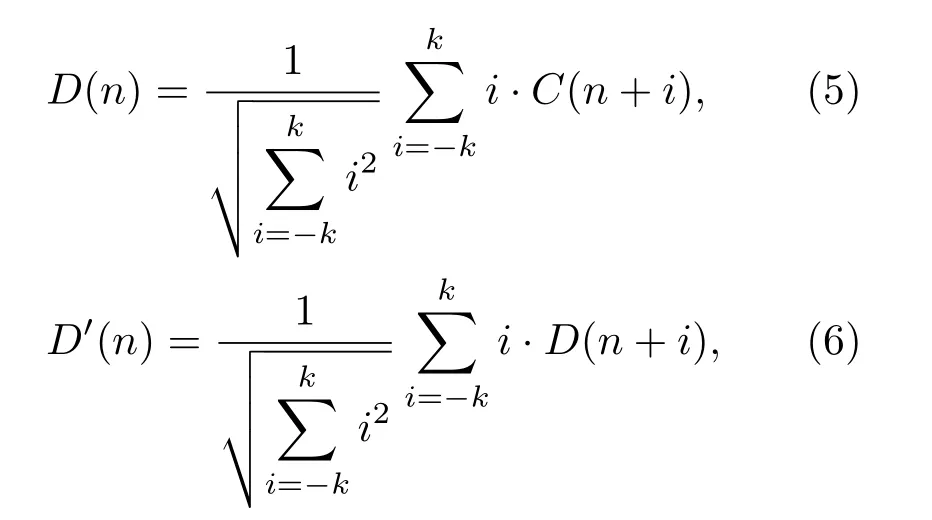
其中,C(n)为第n帧MFCC 系数,D(n)为第n帧一阶差分梅尔频率倒谱系数,D′(n)为第n帧二阶差分梅尔频率倒谱系数。上述三者共同构成帧特征向量,即
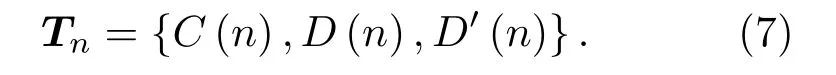
1.2 长短时记忆(LSTM)模型
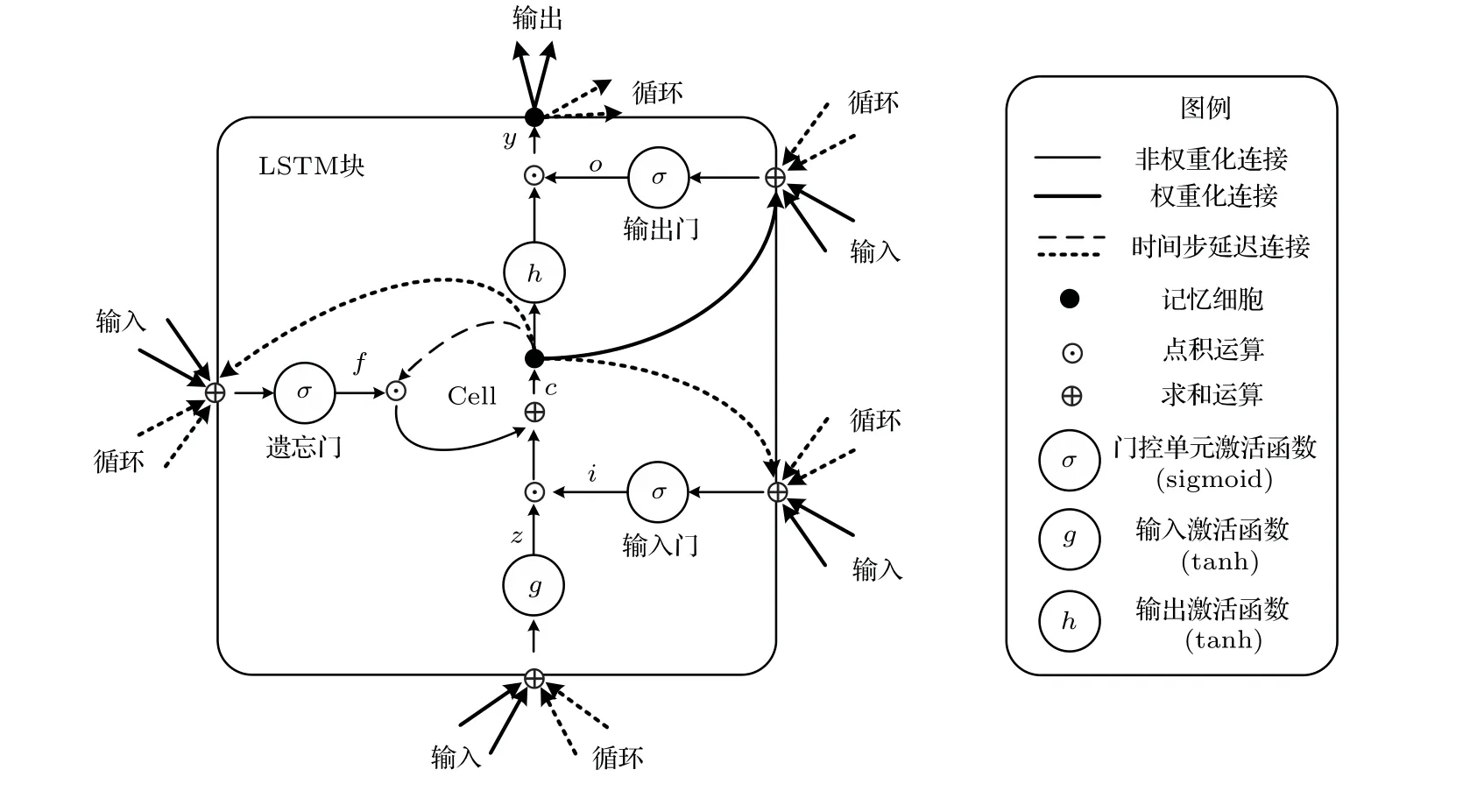
图2 LSTM 基本结构单元Fig.2 Basic structural unit of LSTM
长短时记忆(LSTM)网络[12]是循环神经网络(RNN)的改进形式,其基本单元被称为记忆块,由一个中心节点和3个门控单元组成。中心节点通常被称为记忆细胞,用以存储当前网络状态,3 个门控单元分别被称作输入门、输出门和遗忘门,用以控制记忆块内的信息流动。在前向传播过程中,输入门用以控制输入到记忆细胞的信息流,输出门用以控制记忆细胞到网络其他结构单元的信息流;在反向传播过程中,输入门用以控制迭代误差流出记忆细胞,输出门用以控制迭代误差流入记忆细胞。而遗忘门则用以控制记忆细胞内部的循环状态,决定信息的取舍或遗忘。通过这种门控机制,LSTM网络得以控制单元内的信息流动,使其具备了保存长时间信息的能力,即“记忆”能力,并使其在训练过程中能够防止内部梯度受外部干扰,避免了梯度弥散和梯度爆炸问题,其基本结构单元如图2所示[16]。
设单个LSTM记忆块的输入向量为xt,输出向量为yt,前向传播公式可表述为[17]
(1)长期记忆单元Ct更新过程
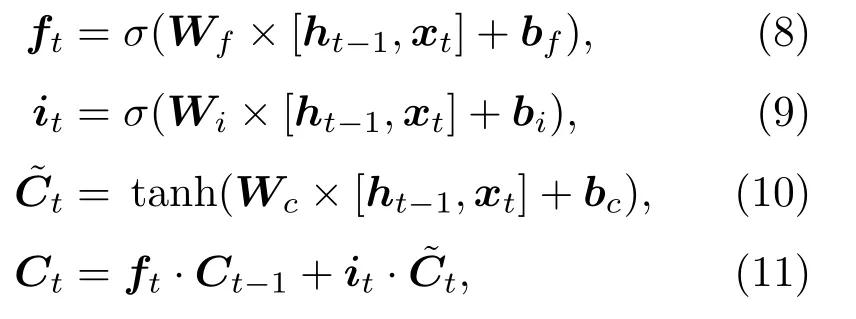
其中,ft代表遗忘门,it代表输入门。在每一个时刻,遗忘门会控制上一时刻记忆的遗忘程度,而输入门则控制新记忆写入长期记忆的程度。ft、it、都是与上一时刻的短期记忆ht−1和当前时刻输入xt相关的函数,其中,σ是sigmoid 函数,取值范围[0,1],tanh 函数取值范围[−1,1]。另外,式(8)∼(10)中Wf、Wi、Wc分别为遗忘门、输入门及Ct更新过程的权重参数,bf、bi、bc分别为这三个过程对应的偏置参数。
(2)短期记忆单元ht更新过程

其中,ot表示输出门,控制着短期记忆如何受长期记忆影响,式(12)∼(13)中Wo、bo分别为输出门的权重和偏置参数。
1.3 MFCC特征智能识别分类
由于门控机制的作用,使LSTM 细胞单元具备“记忆”能力,因此常被用来处理带有时间序列性质的问题,如语音识别、自然语言处理等。水下声目标信号同样带有时间序列特性,另外,经分帧处理获取的MFCC 特征数据之间存在时空连续性。因此,本文将获取的噪声信号MFCC 特征数据作为LSTM输入向量,通过有监督预训练LSTM 模型,得到网络模型参数最优解并保存,用以对未知类别噪声信号进行识别分类,其流程图如图3所示。
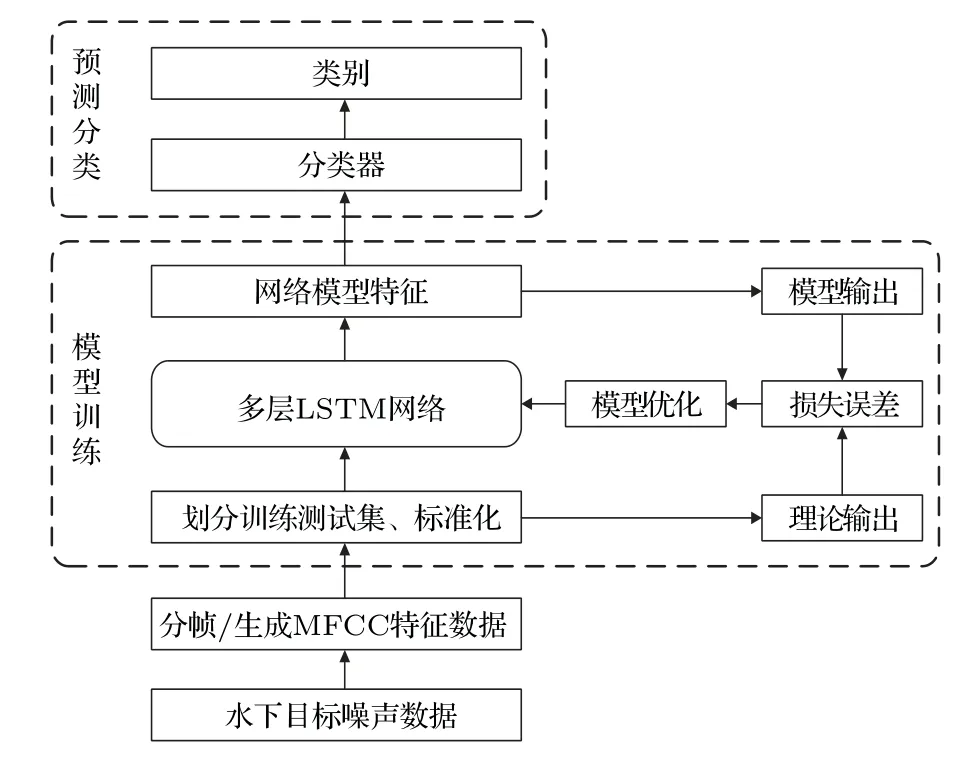
图3 MFCC 智能识别分类流程图Fig.3 Intelligent recognition process of MFCC
对水下声目标信号样本作分帧处理,依据公式(1)∼(7)MFCC 特征提取过程,获取各帧包含36个特征参数的MFCC 特征向量Tn,这36 个特征参数由12 个MFCC 参数、12 个一阶差分梅尔频率倒谱系数和12 个二阶差分梅尔频率倒谱系数共同组成;按各帧时间先后顺序,生成各样本MFCC 特征数据D作为LSTM网络输入向量,
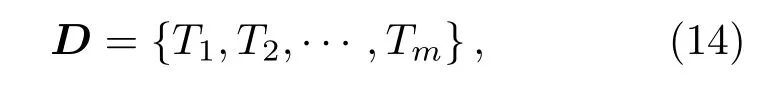
其中,m为帧数。
基于MFCC 特征的智能识别分类方法主要包括数据预处理、模型训练、预测分类几个功能模块。
通过前期数据预处理过程,获取目标噪声的MFCC 特征向量,采用基于时间的反向传播(Back propagation trough time, BPTT)算法,对LSTM网络展开训练,通过逐步减小模型输出与理论输出误差,得到网络模型参数最优解,最终训练好的网络模型可用于对未知目标噪声的识别分类。该识别分类过程全程不需要人的参与,通过对水下无人平台加装具备MFCC 特征提取及LSTM 识别分类能力的信号处理设备,将声学传感器实时获取的水下声信号进行MFCC 特征提取,获取初始特征向量,作为LSTM 预测分类模型的输入,经模型的预测分类过程,可实时获取所探测目标的类别属性。
2 模型验证
为验证上述模型的有效性,本文使用实际水下声目标信号进行了验证。其中,训练样本时长为1 s,经分帧后获取MFCC特征参数维数为3861,帧长设置为25 ms,帧移为10 ms。本文仅针对水面、水下两类目标进行分类,属于二分类问题,深度学习模型采用LSTM 网络,其相关参数设置如表1所示。
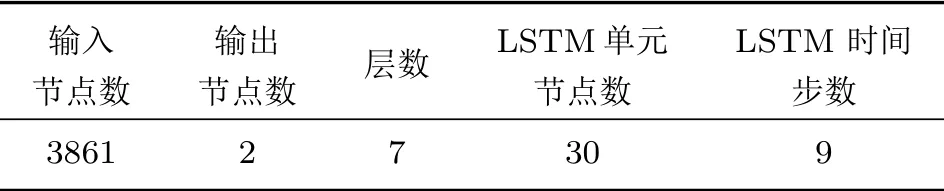
表1 网络相关参数Table1 Related parameters of the network
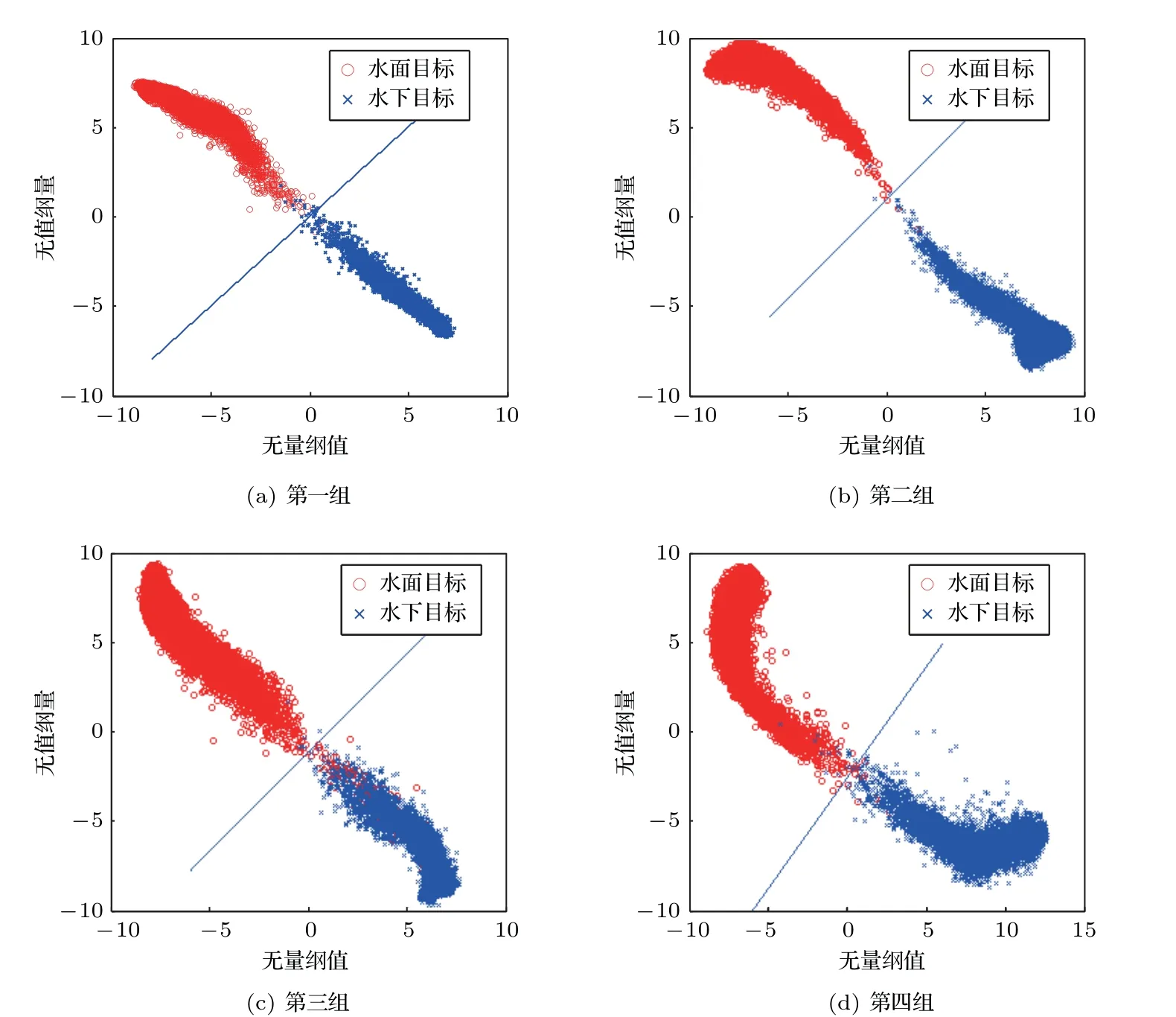
图4 训练数据分类效果图Fig.4 Classification of Training data
模型训练数据库包含各种已知类别的舰船辐射噪声数据近1600条,按1 s 时长进行处理,MFCC特征数据作为LSTM 识别分类模型的样本库数据,样本总数为65284,其中水面目标样本数42375,水下目标样本数22909。为验证模型的有效性,避免因单次结果导致的错误结论,本文采用交叉验证的方式获取训练样本集,即从样本库中随机选取一定比例样本生成多组训练集,通过综合分析多组训练集条件下的模型结果得到可靠结论,本文该比例为4/5。同时,为避免训练样本出现有偏性估计问题,在抽取训练样本时,两类目标训练样本数同样满足此比例,即随机抽取水面目标、水下目标各4/5的样本组成训练集,最终测试结果如表2所示。图4为模型训练完成后,各组训练数据分类效果图。
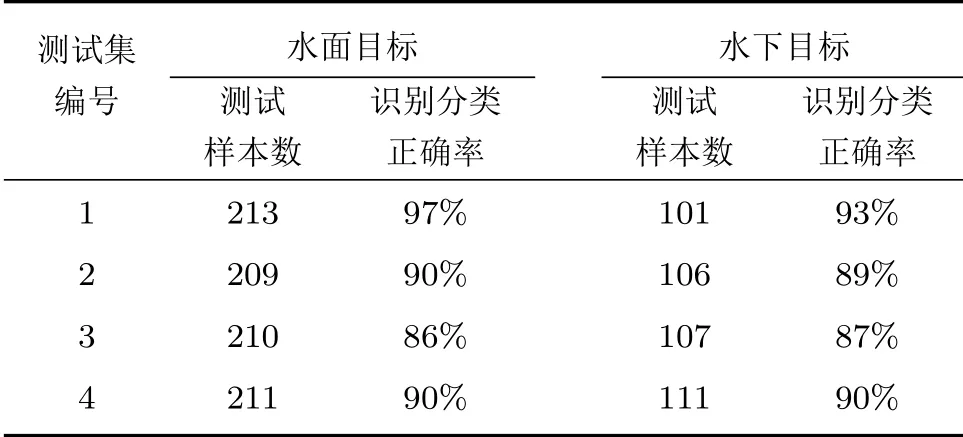
表2 测试结果Table2 Test results
由上述结果可以看出,该水下目标识别分类方法在本文所采用几组测试集条件下,对水面目标的识别分类正确率在86%以上,对水下目标的识别分类正确率在87%以上,说明本文提出的基于MFCC的水下目标识别分类方法是可行的。另外,识别分类过程仅需要输入水下声目标声压数据,其间数据处理、分类识别都不经人工干预,因此该方法可应用于水下无人平台对水下目标进行智能化识别分类。
3 结论
本文针对未来水下无人平台智能化识别分类水下目标的需求,提出了一种基于梅尔倒谱系数特征和长短时记忆网络的水下声目标智能识别分类方法,该方法通过提取水下声目标的MFCC特征系数作为深度学习模型输入向量,有监督训练LSTM模型,以实现对未知目标噪声进行识别分类。经验证表明,该模型能够有效地区分水面和水下两类目标,且具备一定的智能识别分类能力。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子制作(2019年15期)2019-08-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
红领巾·探索(2019年2期)2019-04-19
电子制作(2018年19期)2018-11-14
畅谈(2018年17期)2018-10-28
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
自动化学报(2017年11期)2017-04-04
