
基于多重智能算法的个性化学习路径推荐模型
2019-05-25 02:29申云凤
中国电化教育 2019年11期
关键词:蚁群算法


摘要:基于多重智能算法的個性化学习路径推荐能够有效解决在线用户学习迷途问题,从而实现对在线用户学习进行动态指导和控制。该文以在线学习行为分析为基础,依据推荐流程,建构出个性化学习路径推荐模型。在尊重学习用户个体化差异前提下,引入人工神经网络分类和蚁群优化路径推荐等多重智能型算法。并且在个性化学习路径推荐实现环节,采用协同过滤推荐和蚁群算法相结合,有效避免了协同过滤推荐的马太效应问题,以便降低不同学习用户群的差距。
关键词:个性化路径推荐;人工神经网络算法;蚁群算法
中图分类号:G434
文献标识码:A
一、引言
随着信息技术的发展,在线学习平台越来越趋向个性化、智能化、精准化服务。面对数据量大、专业性强、知识结构复杂的学习资源,在线用户的学习迷途问题尤为突出,因此在线用户迫切需要个性化学习路径推荐服务,来帮助他们及时准确地发现自己需要的知识信息。个性化学习路径是在线用户学习过程中根据自身的学习偏好、学习风格和学习水平以及环境因素所选择的学习活动路线和知识序列[1]。实践证明,个性化学习路径推荐能够实现在线用户学习行为动态指导和有效控制。
目前,国内外对于个性化学习路径推荐的研究纷纷迭起,通常采用建立用户模型和推荐算法两部分来实现学习路径推荐。在用户模型建立中,Madhour与Forte提出了根据学习者学习目标和学习属性的相似性来建立学习群体模型[2],而Chen等人提出了小组学习中学习成员特征建立模型[3],Lawson根据学习者的学习计划相似性建立学习者模型[4],姜强等提出根据学习者知识目标建立用户模型[5]。在学习路径推荐规划中,通常采用近邻算法、协同过滤算法、基于内容过滤的算法来实现个性化推荐[6]。虽然多种推荐技术结合使用能够解决数据稀疏问题和冷启动问题,但是这种典型的推荐技术只是提供给学习者单个的在线学习资源或是几个连续的学习序列,而忽略了学习者在线学习的连续性和序列性。此外,只是浅表性地提供给学习用户知识项目,难以挖掘出学习者的实际需求。
针对以上问题,本文建构出一种基于多重智能算法的个性化学习路径推荐模型。该模型按照推荐流程包含两个阶段,分别是建立相似学习用户模型和实现个性化学习路径推荐,并且在各阶段分别采用了人工神经网络算法、蚁群算法等智能型算法。考虑到不同在线用户学习水平和学习风格的差异,首先利用人工神经网络算法对在线用户的学习行为进行分析,建立具有相似学习特征的用户模型;然后,根据相似用户学习签到数据区域,网格聚类学习路径,获得相似用户学习路径,进行协同过滤推荐。为了减少个体差异,采用蚁群算法弥补协同过滤推荐算法的不足。学习路径是具有次序性和连续性的知识项目集合,因此在路径推荐中进行了知识项目的关联度计算。
二、研究基础
(一)在线学习行为分析
在线学习行为分析意旨通过对在线用户学习行为数据的挖掘和分析,辨别学习者的认知特征和偏好,为个性化学习的开展提供更科学的预测和干预[7]。
就在线学习环境而言,在线学习用户会在学习平台中留下种种“足迹”,如登录学习平台的时间与时长、不同学习模块的访问频次与停留时长、学习任务的完成与测试成绩、在线交互信息等。在线行为数据反映出了学习用户的学习特征,它包含两方面含义:一是学习成绩数据反映了学习用户的水平,二是学习行为动态数据反映了学习用户认知特征和信息交互特征。
何克抗教授曾指出“学习风格由学习者特有的认知、情感和生理行为构成,它是反映学习者如何感知信息、如何与学习环境相互作用并对之做出反映的相对稳定的学习方式”[8]。由此可见,网络空间中的在线用户的学习行为是其学习风格的具体体现。
(二)学习风格理论
国内外的学者从多个角度对学习风格进行描述和分类,Felder-Silverman学习风格模型,因为其描述更为详细和更适于做自适应学习系统而被广泛采用[9]。该模型将学习用户的学习风格设定为四个维度,每个维度的学习风格对应两种偏好:信息加工(活跃型,沉思型)、感知f感悟型/直觉型)、输入(视觉型/言语型)、理解(序列型/综合型)[10]。在线用户对学习材料不同呈现形式、不同内容表现的偏好预示其不同的学习风格。
(三)多重智能推荐算法
1.人工神经网络算法
人工神经网络ANN(Artificial Neural Network)算法是根据行为数据建立人工神经网络模型,对数据进行推断和处理的一种智能技术[11]。数据从输入层进入,经过隐藏层函数处理,最后从输出层输出,实现对学习用户学习行为的线性分类。假定每一神经元对应一种学习行为,人工神经网络是由大量的神经元相互联接而成,学习者的多种学习行为即构成一个自适应非线性的动态系统,利用人工神经网络算法,可以获得学习用户多种学习行为的分类。
2.蚁群算法
蚁群算法(Ant Colony Optimization, ACO)是一种模拟蚂蚁觅食寻找优化路径的概率型算法。是由意大利学者Dorigo M等人于20世纪90年代首次提出[12]。蚂蚁在寻找食物的过程中释放一种“信息素”,标识自己走过的路径,从洞穴到食物源有多条随机轨迹,随着蚂蚁数量的增多,最短路径上蚂蚁留下的信息素浓度最高,通过一段时间的正反馈,蚁群可以寻找到最短达到食物源的路径。
在充分考虑到学习者的个体特征与学习材料之间的关联性前提下,笔者提出利用蚁群算法,迭代计算出概率型优化学习路径TopN-2,对协同过滤推荐路径TopN-1进行补偿性干预。
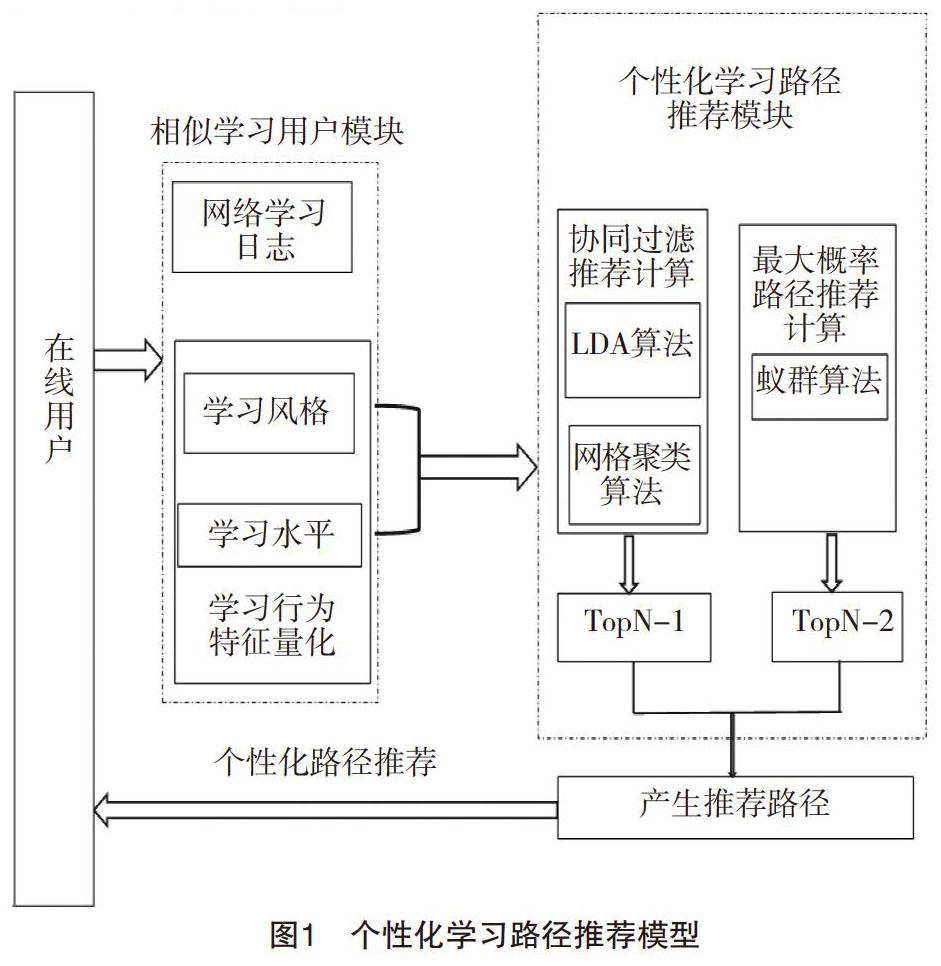
三、个性化学习路径推荐模型框架
本文将在线学习行为分析和学习风格理论引入到个性化学习路径推荐系统中,挖掘在线用户网络日志数据,依据推荐流程,建构出个性化学习路径推荐模型。其中主要考虑3个问题:
第一个问题,如何根据在线学习行为与学习风格理论建构具有相似学习风格和学习水平的用户模型。
第二个问题,如何计算相似学习用户的学习路径,获得协同过滤推荐。
第三个问题,如何优化学习路径进行个性化学习路径推荐。
因此,个性化学习路径推荐模型框架主要由两部分构成:相似学习用户模块和个性化学习路径推荐模块。相似学习用户模块是通过对学习用户学习风格和学习水平相似性计算获得相似学习用户模型。模型框架的另一个核心是个性化路径推荐模块,主要任务是依据相似学习用户签到学习模块进行矢量映射、网格聚类与密度聚类,计算学习路径获得协同过滤推荐TopN-1,进一步通过蚁群算法获得概率优化推荐路径TopN-2,有序合并推荐给学习用户,如图1所示。
(一)相似学习用户模块
学习行为预示着在线用户学习风格和学习水平的个体差异特征,是实现个性化推送的重要依据。因此,相似学習用户模块的建构包含3个步骤:第一,在线用户的学习行为量化;第二,学习风格分类的预定阈值θ (Sjl)的判定与计算;第三,构建相似学习用户模型。
1.在线用户的学习行为量化
在线用户的学习行为数据留存于网络平台日志中,这些学习行为数据是在线用户个性化学习风格的具体体现,通过对学习行为数据的人工神经网络算法分类可以建立不同学习特征用户群。假定学习者所有学习行为的是一组输入变量X={X1,X2,X3……Xm},数据从输入层进入,对其进行权重分析,其权重值与输入变量一起作为输入层数据,进入到隐藏层。在隐藏层中,激活函数g(z),其自变量为学习行为输入变量x和权重w的线性组合s.1_∑WijlX,,其与隐藏层预定阈值θ(s.1)相比较,阈值也即特征值[13]。如果g(z)大于预定阈值θ(Sjl),g(z)为1,我们可以预测学习者具有某种学习风格属性,反之则g(z)为一1,我们可以预测学习者具有相对的学习风格属性,如图2所示。
由公式(1)可知,学习风格是由4个维度的一维数组构成即Si={1/-1,1/-1,1/-1,1/-1)分别对应学习风格属性={活跃型/沉思型,感觉型/直觉型,视觉型/言语型,综合型/序列型}。
2.预定阈值θ (Sjl)的判定与计算
隐藏层由若干隐藏节点构成,每个隐藏层节点具有不同的阈值θ,用来标度不同学习行为所对应学习风格。预定阈值θ (Sjl)是对不同学习行为阈值θ的权重,是计算学习风格分类的重要标准,如表1所示。
3.相似学习用户模型的构建
相似学习用户是指同一认识水平和相似学习风格的用户群。我们首先依据测试模块中在线用户的测试成绩划分出同一认知水平学习用户群,然后再计算该用户群学习风格相似度,一般采用改进的Prefix Span算法筛选出具有相似偏好的用户簇。
其中,Simsty(u,v)表示计算用户u和v之间学习风格相似度,Iu∩lv表示用户u和v共同访问资源的集合[14],参照上文Su(j)和S。(j)分别表示两个用户的学习风格标度值,θu(j)和θv(i)分别表示两个用户的学习风格阈值。Prefix Span算法利用两个用户之间的协方差和标准差的商,测得两个用户间的线性相关性。如果商的值在一1到1之间,我们就认为学习用户u和v具有相似性。
(二)个性化学习路径推荐模块
个性化学习路径推荐模块主要任务是计算学习路径,形成了学习路径推荐列表。学习路径的计算分两部分,第一,依据相似学习用户模型形成协同过滤推荐路径TopN-1;第二,通过蚁群算法找到概率优化路径TopN-2,并进行关联度计算形成个性化推荐路径。
1.协同过滤推荐学习路径TopN-1
协同过滤(Collaborative Filtering)推荐是一种最为经典的推荐类型,通过计算相似用户学习路径,把共同选择的知识项目推荐给相似用户的一种算法。相似用户学习路径的实现是一个离线计算过程,依据相似学习用户的签到数据,利用LDA算法投影构建区域图,再运用网格聚类获得相似学习用户学习路径。
(1)相似学习用户签到数据分类
学习路径是学习内容或学习活动的序列,是学习步骤的呈现或指引,体现学习过程的动态信息。签到数据不仅体现了学习用户在线学习的内容语义信息,其呈现的先后次序更体现了签到数据的时序性。因此,学习路径是一串按照时间顺序排列的浏览知识项目数据。我们把知识项目签到数据dji可以用时序数据dji.s、语义数据dji.c和轨迹数据dji.r三个维度来表征。对于时序数据dji.s我们可以通过网格聚类,网格的划分采用横坐标体现数据的位置序列,纵坐标体现数据的次序。语义数据dji.c通过文本语义挖掘计算出主题概率分布,而轨迹数据dji.r是建立区域寻路的基础。
(2)相似学习用户学习路径的获得
首先,对学习模块签到数据按照语义数据dji.c分类,进行文本语义挖掘,利用LDA算法,投影到二维空间中,形成主题概率区域图,如图3(a)所示。
其次,以时序数据dji.s的位置信息作为横轴,次序作为纵轴对学习模块签到数据进行网格划分,通过网格聚类算法对概率主题分布区域和签到数量的密度进行聚类,获得最频繁到达的几块核心,如图3(b)所示。
最后,将核心区域间、高密网格间的轨迹数据dji.r全部找出来,并按照有向图的邻接表形式存储来,建立学习路径,如图3(c)所示。
2.基于蚁群算法的学习路径优化推荐
蚁群算法参数与个性化在线学习特征的对应关系,是将蚁群算法用于个性化学习路径推荐的前提。信息素和启发信息作为蚁群算法中最重要参数,其数值确定方式决定着最终推荐结果。
(1)信息素浓度τ ij(t)
蚂蚁通过蚁群在路径上留下的信息素浓度来判断食物的来源,而学习平台中的信息素浓度τ ij(t)可以看成是学习用户签到密度,即知识点t,知识项目i到知识项目i的签到密度。 (2)启发信息ηij(t) 表示从知识项目i转移到知识项目j期望程度。allowedk待选知识项目,初始时刻allowedk中有n-l个知识项目,即排除掉学习用户一开使所在的知识项目,随着时间的推移,待选知识项目越来越少,直到为空,表示遍历完所有知识项目。
(3)优化路径概率推荐
蚁群算法的概率选择是推荐算法的核心内容,知识项目的选择概率为:
Pki.j(t):知识点t,学习用户k从知识项目i向知识项目j转移的概率。信息素因子a为信息素浓度指数,启发函数因子B为启发函数指数,这两个参数分别决定了签到密度与转移期望对于学习用户k从知识项目i转移到知识项目i的可能性重要程度。
四、个性化学习路径推荐的实现
(一)个性化学习路径推荐策略
考虑到协同过滤推荐的马太效应,在协同过滤推荐产生TopN-I基础上,通过蚁群算法迭代计算产生个性化推荐TopN-2。TopN-1与TopN-2中的知识项目具有无序性的弱点,因此对其进行表征关联度计算,形成个性化学习路径推荐。
定义1知识项目表征关联度Q。设学习平台中N个学习模块,每个学习模块含有的知识项目M={K1,K2……KI,KJ),那么推荐项目Ki与所选知识
Q=Rele(Ki)= ∑=SEVk sim(Ki,S)
(4)项目的表征关联度为:
Vk表示历史学习知识项目集,sim()是相似性函数。
(二)学习路径推荐算法描述
背景:某知识点t的知识项目M={Ki,K2-KI,KI),已获得相似学习用户的学习路径TopN-I。
输入:用户的学习风格和认知水平
算法实现过程:
(1)M.={
(2)While M。
(3)m=getchar(tj)
(4)1f is empty(m)==TRUE Then
(5) i=i+1
(6)else;(1)一(6)找到学习用户未选知识项目
(7){Pki.j(t)lm∈Mn,add to Mn0), i=i+l
(8)End if
(9)End while;(7)一(9)计算未选知识项目优化路径概率,直到未选知识项目结束,获得TopN-2。
(10)根据表征度公式,输出个性化推荐路径;
下一知识点t,;
Go to step(2)
Mn={)表示当前某个知识点t,候选知识项目的集合。Mn中知识项目的个数从i到j,从i=l开始寻找知识项目,判定其是否没有被学习用户选中,直到I=J把所有未被学习用户选中的知识项目找到,放入到m中,形成新的知识项目集合,即用公式m=getchar(tj)表示。Pki.j(t)lm∈Mn表示计算未被选中的知识项目的优化概率,并通过addto Mn()命令插入到当前候选集合Mn中,根据表征度公式,排序生成个性化推荐路径TopN-2。
(三)分析讨论
协同过滤推荐是在同一认知水平学习用户中获得相应的推荐知识项目,因此马太效应显著即认知水平高的用户越来越高,认知水平低的用户越来越低,协同过滤推荐更适用于认知水平高的群体。
蚁群算法推荐能够降低个体差异,计算出与学习用户个体特征相关的知识项目最大概率推荐。假定知识项目M={K1,K2...K10,K11),学习用户a的学习路径为fKi,K3,K6,Kg),获得的协同过滤推荐TopN-1:{K8,K9,K10),获得蚁群推荐为TopN-2{K7 85%),根据知识项目表征相似度计算可获得{K1,K3,K6,K7,K5,K9,K10)。
五、实验研究
(一)实验方案
考虑到个性化学习路径推荐的特点和当前研究现状,本文以本课程组采用JSP+MySQL技术搭建的“大学计算机基础”学习平台为实验对象,对建构的个性化学习路径推荐模型进行实验效果分析。
1.实验背景
“大学计算机基础”网络学习平台由四大模块,分别为学习导航、学习资源、问题的解决与探究、学习的交互模块构成。模块中的知识项目按知识点章节进行分类。其中,资源导航模块由学习目标、知识树、重点难点构成;学习资源模块由视频、电子课件、文本教材构成;问题的解决与探究模块由例题解析、练习、测验构成;学习交互模块由讨论区构成。
2.知识项目映射
为了提高系统对学习用户访问路径的提取与程序编写,需要对原日志数据做进一步優化处理,首先对学习模块下的知识项目重新进行了定义,如表2所示。
(二)实验数据的采集
本文采用网页数据采集器一八爪鱼采集器在网络平台日志中抓取了50名学习用户的学习数据信息。考虑到学习内容对用户选择学习模块范围的限制性,本实验选择学习模块分布全面的“第四章Word应用”作为实验采集区域。获得学习用户节点访问量、学习路径以及测试成绩。其中学习用户节点访问量,是指学习用户对每一知识项目节点的点击量与时长,如下页表3所示。
(三)实验数据处理
依据相似学习用户模型建立方法,对50名学习用户建立了8组相似用户群,并计算出协同过滤推荐TopN-1。根据蚁群算法对参数进行初始化计算,主要包括用户与学习风格相似度值C.、学习用户认知水平与学习材料难度d;所获得的启发信息值ηi,j,以及学习用户评价优化信息值τ ijnew,α信息素因子,β启发函数因子,如下:ηij=0.4 τ,inew=0.4α=3 β =4.5计算获得最大概率化知识项目推荐TopN-2,TopN-I与TopN-2有序合并后,获得个性化推荐路径,如表4所示。
(四)实验评价指标
从个性化学习路径推荐的目标需求出发,我们引入学习效率和学习迷航导控有效性2个性能指标。学习效率表示用户在连续使用一段时间个性化学习路径推荐后,学习成绩的提高比率。学习迷航导控有效性,是学习用户运用了个性化学习路径推荐程序后与以往相比,知识项目签到增加比率来度量,知识项目签到浓度越高,学生在线学习过程中学习迷途问题获得解决的程度越高。
为此,首先引入一个知识量的定义。
定义2:一个在线学习平台是由多个知识节组成的网络系统,每个知识节点由n个知识项目构成。知识节点与知识项目构成了知识量,记作KI.其中,对于某一知识点t学生已签到的知识项目构成的知识量为KI(t),学习用户采用的个性化推荐知识项目构成的知识量为KI(t,s)。因此,迷途导控有效性可以记作:
(五)实验结果分析
在8组相似用户群中各随机抽取5名学习用户,进行个性化学习路径推荐,分别获得个性化学习路径推荐迷途导控率(如表5所示),个性化学习路径推荐前后知识项目签到密度对比(如图4和下页图5所示),以及个性化学习路径推荐后成绩发展趋势(如下页图6所示1。
由数据可知,通过个性化学习路径推荐,对学习用户学习迷途都具有一定的导控性,表现为推荐后学习用户的签到密度明显高于推荐前学习用户签到密度。获得路径推荐后,学习用户成绩都有所提高,特别是对于成绩为60-70及70-80的学习用户,其成绩提高显著。
六、结语
信息技术的发展,学习分析与教育的深度融合使得学习平台越来越趋向于精准化和个性化的服务。本文在网络学习行为分析基础上,充分尊重学习用户学习风格、学习水平个体化差异,利用人工神经网络及蚁群概率推荐等多重智能算法为用户开展个性化学习路径推荐。在蚁群推荐过程中充分运用群体对学习路径的评价信息、学习用户签到信息以及学习材料的表征信息,对学生的知识建构与学习能力进行评估,使得学习路径生成更加精准化、个性化,弥补个体差异,进而提高学习效率和学习质量,为教学的智慧性发展提供帮助。
参考文献:
[1]师亚飞,彭红超等.基于学习画像的精准个性化学习路径生成性推荐策略研究[J]中国电化教育,2019,(5):84-91.
[2] Felder R.M.&Spurlin J.Applications. Reliability and Validity of the Index of Learning Styles[J].lnternational Journal of EngineeringEducation.20057(21):103-112.
[3] Chen C M.lntelligent Web-Based Learning System With PersonalizedLearning Path
Guidance[J].Compute Education,2008.5 1(2):787-8 14.
[4] Lawson C,Beer Cetal Identification of' at Risk' Students UsingLeaming Analytics:The Ethical Dilemmas of Intervention Strategiesin a Higher Education Institution[J].Educational Technology Researchand Development.2016.64(5):957-968.
[5][10]姜強,赵蔚等.基于网络学习行为模式挖掘的用户学习风格模型建构研究[J].电化教育研究,2012,(5):55-60.
[6]张志威.个性化推荐算法研究综述[J].信息与电脑,2018.(7):27-29.
[7]赵蔚,李士平.基于学习分析的自我调节学习路径挖掘与反馈研究[J].中国电化教育,20187(10):15-21.
[8]赵晓航.自适应学习系统中学习风格模型的研究[D].长春:东北师范大学,2010.
[9]姜强,赵蔚.基于Felder-Silverman量表用户学习风格模型的修正研究[J]现代远距离教育,2010,(1):62-66.
[11] Nan Y,Mu L基于神经网络的统计机器翻译的预调序模型[J].中文信息学报,2016,30(3):103-110.
[12]沈显君.自适应粒子群优化算法及其应用[M].北京:清华大学出版社.2015.
[13]张龙飞.基于用户频繁访问路径的个性化服务推荐研究[J]科技咨讯,2016,(9):159-161.
[14]赵程玲,陈智慧等.适应性学习路径推荐算法及应用研究[J].中国电化教育,2015,(8):2-6.
作者简介:
申云凤:副教授,硕士,研究方向为教育技术 ( 377345770@qq.com)。
猜你喜欢
山东工业技术(2016年24期)2017-01-12
价值工程(2016年36期)2017-01-11
软件导刊(2016年11期)2016-12-22
软件导刊(2016年11期)2016-12-22
电脑知识与技术(2016年28期)2016-12-21
科技视界(2016年18期)2016-11-03
电脑知识与技术(2016年18期)2016-11-02
电脑知识与技术(2016年22期)2016-10-31
中国市场(2016年16期)2016-05-16
科技视界(2016年4期)2016-02-22
