
一种基于深度学习的上帝类检测方法∗
2019-06-11 07:39卜依凡李光杰
软件学报 2019年5期
卜依凡,刘 辉,李光杰
(北京理工大学 计算机学院,北京 100081)
随着产品需求的不断变更,在程序设计之初设计好的代码框架需要不断调整以实现功能的变更.长此以往,程序将逐渐偏离原有的框架,使得整个程序混乱不堪,难以进行扩展和维护.为此,人们提出了软件重构以对此类软件进行优化,在不改变其软件外部特性的情况下提高软件的设计质量,进而提高软件的可维护性和可扩展性[1].多年来,在开发过程中的实践与应用表明[1-3],代码重构在提升程序的可读性和可维护性等方面都有着显著的作用.通过对系统结构的重新整理,开发人员不仅可以改进原有的系统设计、延长软件的生命周期,还能够通过改善代码逻辑来增强代码理解,有助于从中发现程序缺陷[4].
软件重构的关键步骤之一是明确需要重构的代码片段[4].而为了帮助开发人员确定需在程序中的何处进行重构操作,Fowler等人提出了代码坏味(code smell)的概念[4],意指软件系统中影响软件质量的设计问题.Fowler等人一共提出了22种代码坏味,包括克隆代码、特征依恋、长方法等.基于此定义,研究人员提出了一系列自动或半自动的方法,以从代码中检测这些代码坏味[5-8].代码坏味的概念及其检测方法极大地推动了自动化软件重构的应用和推广,成为软件重构领域的重要研究热点和研究难点.
本文针对上帝类进行深入研究,研究其自动化的检测方法.上帝类是一种常见的代码坏味,指的是某个承担了本应由多个类分别承担的多个职责的类[9].上帝类违背了分而治之的基本思想以及单一职责的设计原则,严重影响软件的可维护性和可理解性[4].对于上帝类的出现,Fowler等人推荐使用提取类(extract class)或提取子类(extract subclass)等重构操作,将一个大类拆分为小类,以提取出过大类中的一部分职责.为了提醒程序员及时处理上帝类,研究人员提出了众多检测算法以自动判定某个给定的类是否为上帝类[5-7,10].现有的检测算法主要基于代码行数、圈复杂度、内聚度等常见的软件度量来判定给定的类是否为上帝类[11].不同的检测方法往往采用不同的度量项,使用不同的阈值[12-14],因此,不同检测方法间的检测结果往往存在较大的差异[5].此外,现有检测方法的查全率和查准率偏低,导致程序员这些检测方法和检测工具难以在工业界广泛使用.
为此,本文提出了一种基于深度神经网络的上帝类检测方法.该方法不仅利用了常见的软件度量,而且充分利用了代码中的文本信息,意图通过挖掘文本语义揭示每个类所承担的主要角色.此外,本方法将深度学习技术应用于上帝类的检测.深度学习在计算机视觉、自然语言处理等领域经过广泛的实践,得到了很大的发展.与传统的机器学习相比,深度学习可以更容易地捕捉到输入数据中的深层关联,经过多层映射和抽象,拟合出更符合输入数据分布的模型.本文利用深度神经网络在文本处理方面的特长,将文本信息加入对上帝类的验证中,同时结合与上帝类在耦合度、内聚度、类规模等属性相关的多个度量项,以深度学习善于自动选择原始数据特征的优势,帮助提取出这些度量项之间的相互关联,从而综合评判待检测程序是否应为上帝类代码坏味.
有监督的深度学习通常需要大量的标记数据来作为训练样本,但手工标记上帝类样本数据需要消耗大量的人工,难以收集足够的训练样本.为此,本文提出了一种借助开源项目源码来构建标签数据集的方法.通过预定义的类合并操作,实现上帝类样本的自动生成和标注.考虑到Github,SourceForge等开源网站上有海量开源程序,该方法可以自动构造海量的带标签的正负训练样本,从而为基于深度学习的上帝类检测奠定了基础.
最后,对本文所提出的上帝类自动检测方法进行了实验验证.在第三方开源数据集上的实验结果表明,该方法优于现有的检测方法.在不降低查准率的前提下,较大幅度地提高了上帝类检测的查全率(35.58%=95.56%-59.98%),最终综合提高了上帝类坏味检测的F1值(2.39%=8.15%-5.76%).
本文第1节介绍相关研究的现状,并对此进行总结与分析.第2节具体介绍本文提出的上帝类检测方法.第3节对所提出的方法进行验证与评估.第4节进行总论和展望.
1 相关工作
1.1 上帝类
Fowler等人提出了代码坏味的概念,并列出数十种常见的代码坏味.其中,大类(large class)是承担太多职责而变得臃肿的类.Fowler等人认为,这样的类不仅会增加类中代码的理解难度,同时也容易导致其他代码坏味的出现[1].Brown等人引入了设计反模式(antipattern)的概念来代指在程序设计过程中所出现的设计缺陷[15].Blob Class是典型的反模式.当单个类中包含超过 60个成员变量及方法时,Brown等人认为此类违反了单一职责原则,应该对其进行重构.在此之后,Lanza等人正式提出了上帝类(god class)的概念,表示某些对外部数据操纵过多的类,并指出,这些类通常还会出现类内成员间内聚较低或类内复杂度过高的问题[9].大类、Blob Class以及上帝类本质上类似,都是指某个类承担了过多的职责,从而导致该类过于复杂、缺乏内聚等问题.
研究者们迄今已提出了多种方法来对这样一些在项目中承担过多职责的类进行检测与重构.Marinescu等人提出一种基于度量值指标的方法来确定对包括上帝类在内的 14种代码坏味的检测策略,并将此方法实现为工具 iPlasma[6].他们根据各代码坏味的特征与定义选择不同的度量项组合,以预设阈值的方式为各个坏味确定不同的检测方案.如公式(1)所示,iPlasma将类内圈复杂度(weighted method count,简称WMC)、类内内聚度(tight capsule cohesion,简称TCC)和对外访问数(Access to foreign data,简称ATFD)这3个度量值综合起来以实现对上帝类的判断.
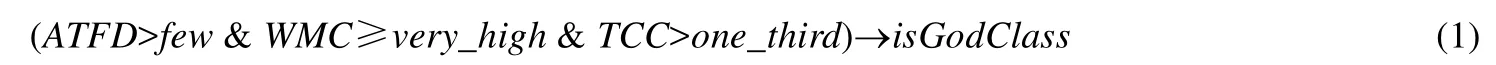
其中,few、very_high以及one_third均为常量.当一个类的3个度量值同时满足上述条件时,iPlasma会将其判定为上帝类.
Moha等人定义了一种领域特定语言(domain-specific language,简称DSL),并利用这种语言对代码坏味检测规则进行定义,以此形成了方法 DÉCOR[7].通过对各类坏味的概念进行文本分析,DÉCOR将代码坏味的定义转化为以这种DSL语言表示的坏味检测算法,在将其给定的算法实现为真正的程序后,便可以完成对于此代码坏味的检测.DÉCOR在利用NMD,NAD和LCOM5等度量项来定义对于上帝类的检测规则的基础上,还综合了一些文本信息来辅助其判断,如当类名中出现“Process”“Control”“Ctrl”等字样时,即说明此类为上帝类的可能性相对较大.
Tsantalis等人提出了一种利用杰卡德距离来衡量两个代码实体之间相似性的方法,并以此方法为基础实现了用于检测代码坏味的工具 JDeodorant.其最初用于检测特征依恋(feature envy)代码坏味并推荐移动方法(move method)的重构方案[8],在之后,则逐步增加了对于另外4种坏味——重复代码(duplicated code)、switch语句(type checking/SwitchStatement)[16]、长方法(long method)[17]以及上帝类[10]——的检测与重构推荐.JDeodorant为类中的每个成员生成与之相关的其他成员集合(entity set),即访问此成员以及被此成员访问的其他成员的集合.他们将两个成员之间的距离定义为其相关成员集合间的杰卡德距离,计算方式如公式(2)所示.

其中,mi为类中所声明的一个成员,Se则为成员e的相关成员集合.基于此距离度量项,JDeodorant可以由此定义一个类内的各个成员之间的节点距离,从而为被检测类构建一个以类内成员为节点的树状图层次结构,再根据所需阈值,对树状图进行横向切割[10].一旦树状图可以被切割为多个节点簇,则说明此类存在进行提取类重构操作的必要性,即可判定此类是一个上帝类.随后,钟林辉等人在 JDeodorant的基础上对杰卡德距离进行了扩展,公式如下.
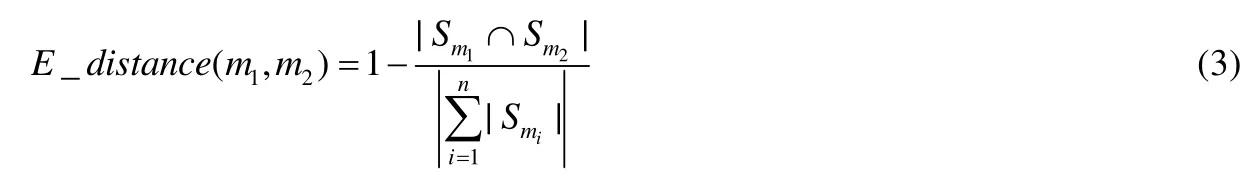
其中,mi为类中声明的第i个成员,n为类中的全部成员个数.他们利用扩展的杰卡德距离实现了一种改进的层次聚类重构方式,以弥补原方法难以衡量全局范围内的成员相似性的缺陷[18].
综上所述,上述检测方法主要依赖于不同的代码度量项(structural metrics)以及相应的阈值来判定某个类是否为上帝类.不同的检测方法往往采用不同的度量项,使用不同的阈值[5,13,14],因此,不同检测方法的检测结果往往存在较大的差异[5].此外,现有检测方法的查全率和查准率偏低,导致这些检测方法和检测工具难以在工业界广泛使用.
1.2 基于机器学习的上帝类坏味检测
随着机器学习的演进与发展,研究者们提出了一批基于各类机器学习算法的代码坏味检测方法.Kreimer在2005年时提出了一种基于决策树(decision tree)的对大类和长方法两种代码坏味的检测方法[19].Khomh等人利用贝叶斯信念网络(Bayesian belief network)实现了对上帝类相关反模式的检测[20].Maiga等人则实现了基于支持向量机(support vector machine,简称SVM)的上帝类检测方法[21].Palomba等人提出了一种基于信息检索技术(information retrieval,简称 IR)来利用程序中的文本信息进行坏味检测的方法[22].类似的,马赛等人尝试了利用潜在语义分析技术来对上帝类进行检测[23].Fontana等人汇总了几种常见的机器学习算法(J48,JRip,ERandom Forest,Baive Bayes,SMO以及LibSVM)来共同检测各类代码坏味,以便比较并总结不同算法在代码坏味检测领域中的表现与差异[24].
有别于基于传统机器学习的坏味检测方法,本文充分利用了最新的深度学习技术,能够学习更加复杂的逻辑关系.此外,本文不仅利用了软件度量信息,也使用了代码中的文本信息以挖掘给定类所承担的角色.最后,在训练集的收集方面,现有方法主要依赖于手工收集训练数据,而本文提出了标签训练数据自动生成方法.
2 上帝类检测方法
为了自动检测上帝类,本文提出了一种基于深度学习的检测方法.第 2.1节给出本文所提出方法的概览介绍,之后的各小节将详细介绍该方法的各个关键步骤.
2.1 方法概述
本文提出的基于深度学习的上帝类检测方法如图1所示.首先,利用大量的开源软件项目工程作为代码语料库,实现了一种可以自动生成标签样本的工具来生成深度学习训练所需的大规模数据集.此工具基于如下假设:若认定开源项目的现有设计合理,那么若将其中的两个类合并为一个类,则可以认为这个大类承担了两个类的职责.因此,本工具在不改变类的外部行为的前提下,通过尽可能多地对源码中的类进行两两合并以形成大类正样本集合,随后,从其余未参加合并的类中随机抽取出相应数目的类作为负样本集合.为了尽可能保留代码中与上帝类代码坏味相关的特征,从正负样本集中分别提取出符合预设输入格式的文本信息与软件度量作为神经网络分类器的输入,分类器的预期输出为样本的标签(即是否为上帝类).经过多次迭代训练后,可以得到最终被训练好的神经网络分类器.对于给定的待测程序,首先提取每个待测试类的文本信息和软件度量.将此信息依次输入训练好的神经网络分类器,得到最终的检测结果.后续章节将依次介绍每个关键步骤的具体细节.
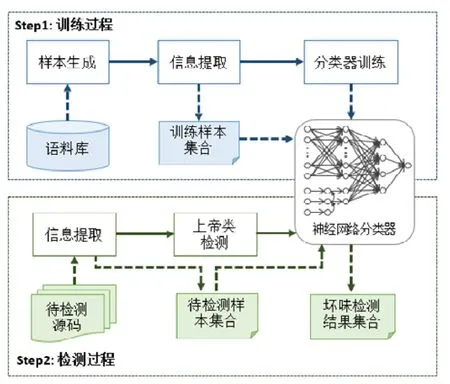
Fig.1 Overview of the god class detection based on deep learning图1 基于深度学习的上帝类代码坏味检测方法概图
2.2 神经网络的输入
由于直接以全部代码文本作为深度神经网络分类器的输入时所要求的模型学习难度过大,我们需要对代码文本进行一部分的预处理操作,从代码文本中提取出与上帝类代码坏味相关的特征集合,并且摒弃一部分就本学习任务而言无价值的无关特征,以便降低模型构建的难度.为了在充分利用代码中的各类特征与信息时避免因特征过多而导致的维度爆炸,我们经过反复考量与对比,选取了数个与上帝类代码结构相关的代码度量项作为神经网络分类器的软件度量特征;同时,从代码中提取了部分相关标识符来作为神经网络分类器的文本信息特征.然而,尽管已剔除了一部分的无关特征与冗余特征,这些原始特征彼此间的相互关联以及输入特征与输出标签间的潜在映射关系依然需要进一步地分析.因此,我们利用了神经网络分类器来对原始特征进行映射与学习,以便最终输出与样本标签所对应的分类结果.
软件度量信息是代码坏味检测研究中常用的判断依据.我们综合了12个可以在不同方面体现上帝类特征的代码度量项,基本涵盖上帝类代码坏味结构特征的各个方面,以期能够在耦合度、内聚度、复杂度以及代码规模等方面更全面地表示代码的结构特征.表1为所选度量项的详细信息.

Table 1 Metrics表1 度量项
此外,我们收集了被检测类中所声明的各成员标识符来作为输入的一部分.Arnaoudova等人的研究表明,有意义的标识符可以有效揭示代码组件在程序中的角色、行为与功能[25].一个类中的各个成员通过完成各自的功能,共同构成其所在类的对外行为与角色,故可以认为在理想情况下,存在于一个类中的多个成员标识符之间应该存在着语义上的相互关联.因此,我们将这种隐含在标识符内的语义关联作为衡量被检测类内聚度的一个重要依据,并结合上述的软件度量指标,组成了本文所提出方法的输入,如公式(4)所示.

其中,mi为被检测类中声明的第i个方法或属性,name(mi)为mi的标识符,metrics则为12个度量项的集合.
2.3 标识符的表示方式
为了能够挖掘标识符之间的深层语义关联,我们利用Mikolov等人提出的著名词向量化模型Word2Vector将标识符中的词语映射到高纬向量空间[26,27],以词向量在高维空间中的分布来揭示词与词之间的相似性关系.作为自然语言处理领域的重要工具,Word2Vector构建了一个以给定的文本作为输入输出的神经网络.在进行训练之后,可以利用此模型的隐含层将词语转化为稠密向量,实现以向量相似性来表示语义相似性的目的.我们利用大量项目源码作为代码语料库,对Word2Vector模型进行训练,构建了一个针对程序语言的向量空间.随后,根据如下步骤对将作为神经网络分类器输入的各标识符分别进行预处理.
(1) 根据驼峰命名法规则(camel case)和下划线命名法规则对标识符进行分词,将单个标识符拆分为多个逻辑单字.
(2) 利用已训练好的 Word2Vector模型将各逻辑单字分别映射为高维空间中固定长度(200维)的词嵌入向量(word embedding).
(3) 将单个标识符中包含的各分词向量相加后取均值构成一个新的词向量,以作为此标识符在向量空间中的表示[28].
针对训练过程所用的12个项目源码进行的统计分析表明,训练集中95.8%的类中不会声明超过50个成员.因此,出于神经网络的设计需要,我们将神经网络输入中的单个样本的标识符个数固定在 50个,即只针对被检测类中所声明的前50个成员进行预处理,类中成员数少于50个则以全零向量来做补零扩展.
2.4 基于深度神经网络的分类器
本文所提出的基于深度神经网络的分类器结构如图2所示.
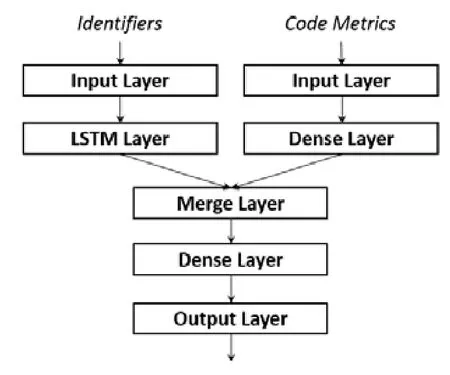
Fig.2 Classifier based on neural network图2 神经网络分类器
如上文所述,此分类器的输入分为文本输入与度量输入两部分.文本输入由类中的成员标识符组成,类中的成员标识符在经过预处理(详见第2.3节)后,已经由文本信息转为数值信息,将以词向量(输入形式为50×200矩阵)的形式经过输入数据屏蔽层(masking,mask_value=0)进入长短时记忆网络(long short-term memory,简称LSTM)中,其中,LSTM 层激活函数为 sigmoid函数,输出维度为 2,并对该层权重做均匀分布(uniform)初始化.长短时记忆网络作为循环神经网络(recurrent neural network,简称RNN)的变体,通过规避梯度消失问题弥补了循环神经网络长期记忆失效的缺陷[29],因而在自然语言处理领域中获得了充分应用.我们希望利用长短时记忆网络善于从长序列中提取关键语义特征的优势来对所输入的多个标识符词向量进行处理,以帮助分类器分析被检测类在语义上的内聚性.度量输入体现了被检测类的结构特征.通过将从类中提取出的12个度量值输入全连接层(dense),分类器可以在有监督的情况下对输入进行迭代训练,逐步调整出与训练集标签最匹配的参数组合,其中,本全连接层激活函数为 tanh函数,输出维度为 12,并对本层权重做均匀分布(uniform)初始化.之后,两部分数据会经由融合层(merge)以向量拼接(concatenate,axis=-1)的形式合并,再由一层全连接层映射到最终的Sigmoid输出层,此间的全连接层激活函数为tanh函数,输出维度为4,权重初始化为全零矩阵(zero);输出层激活函数为sigmoid函数,输出维度为1.最终选取的模型损失函数(loss function)为binary_crossentropy函数,优化器(optimizer)为adam自适应方法,迭代次数(epoch)为10次,批尺寸(batch_size)为5.
2.5 训练集的生成方式
深度神经网络的结构决定了其对于训练样本数量的要求.为了防止出现过拟合现象,我们需要大量的数据样本来帮助提高神经网络的泛化能力.对此,我们提出一种通过合并类操作来自动构建标签样本集的工具来辅助收集上节所述分类器在训练过程中所需的样本集.在项目源码可编译的前提下,我们可以利用本样本生成工具源源不断地生成分类器所需的正负样本,以及从所生成的样本集中提取神经网络分类器所需要的全部特征输入.利用本工具来帮助收集带标签的训练样本集,可以省去人工识别上帝类代码坏味时所需要耗费的大量时间和人力.由于此工具实现了自动的样本生成和特征提取预处理操作,因此只要能够获取到优质的可编译开源项目资源,整个训练样本的生成及特征提取过程均不需要人工干预.在这样的前提下,以互联网中基数庞大的开源项目为基础,原则上我们可以利用此工具获取到足够充足的上帝类标签样本集.
假设某个程序的现有设计是合理的,那么将其中的两个类合并成一个大类则是不合理的.这个合并起来的大类承担本该由多个类一起承担的多个角色,因此是一个上帝类.基于此,我们利用开源的高质量代码自动构造上帝类的正样本.为了保证合并后大类的外部行为与合并之前保持一致,我们会在将两类合并的基础上尽可能不对两类源码进行修改.
如算法 1所示,在获取到可编译的开源项目源码后,为了在最大化节省样本生成时间的基础上秉持多多益善的原则尽可能多地生成训练集正样本,我们会对项目内的各编译单元进行 3次筛选,以确定最终可用于生成训练样本集的编译单元集合.
算法1.类型合并前后的判断逻辑.

3次筛选的具体实现步骤如下.
(1) 第 1次筛选是对单个编译单元中的顶层类进行判断,主要目的是筛选出能够进行合并操作的常规Class类.
(2) 随后,我们将对剩余的编译单元集合进行两两配对并开始第 2次筛选,这次筛选为初步判断配对后的两个编译单元是否可以在不导致语法错误的前提下进行合并,如判断两个类中是否存在成员名冲突,或两个类是否继承于不同的父类.
(3) 一对编译单元如果可以通过上述判断,便对此二者实现合并类操作,以得到最终需要的大类.此时进行第3次筛选,用以确定此次合并类操作没有导致任何的程序错误与外部行为变化.
两个类C1和C2的合并类算法如下.
(1) 生成一个空的新类(NewClass),并C1和C2中的模块导入语句(import statement)以及全部的成员声明语句都迁移至NewClass类内.
(2) 在整个工程中搜索C1和C2以属性类型、方法参数类型、方法返回类型等一系列形式出现在工程中其他类中的情况,将这些类中的C1和C2类型替换为NewClass类型.
(3) 删除工程中的C1和C2类.此时,整个工程中全部与C1和C2相关的代码均已被 NewClass替换,NewClass彻底取代了C1和C2类在此系统中的角色与职责.
我们将通过3次筛选的NewClass定义为人为注入的代码坏味,由此便可以计算NewClass的12个度量值.根据第2.2节中所设计的输入格式收集到所需数据后,我们即可导出以下格式的训练集正样本.

为了获取负样本集合,我们将经过第1次筛选的编译单元集合定义为全集collection,将可成功合并为大类的类的集合定义为集合posCollection,由此可定义posCollection在collection上的补集为negCollection,即
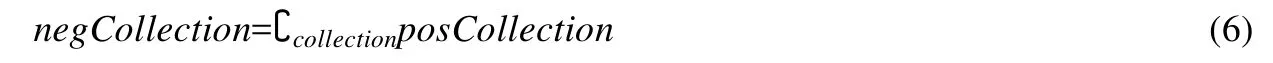
假设某个程序的现有设计是合理的,那么negCollection中任意一个类都是上帝类的负样本.为保证训练效果,我们从每个开源程序中收集的正负样本的比例控制在 1:1.为了保证训练集负样本的典型性以及此样本生成工具设计思路的合理性,我们从negCollection中随机抽取一个与正样本集合样本容量相同的集合,并入最终的带标签的训练样本.
3 实验验证
为了对所提出的方法进行验证,我们收集了12个高质量开源项目源码作为样本生成所需的代码语料库,并以此为基础具体实现了该方法,相关的代码与数据已上传至 https://github.com/bby8808/GodClassDetection.同时,我们以Palomba等人提出的代码坏味数据集作为测试样本[30],对本文所提出的方法进行验证与分析.
3.1 研究问题
在实验验证阶段,我们希望通过分析以下4个问题来对所提出的方法进行评估.
(1) 研究问题1:该方法是否能准确有效地检测出上帝类?其查全率和查准率是否优于现有方法?
(2) 研究问题2:所提出的神经网络分类器中的两个特征输入(代码文本特征与代码结构特征)对最终结果分别有什么影响?即如果只有其中的一个特征输入,分类器的性能会如何变化?
(3) 研究问题3:利用其他网络模型(如卷积神经网络CNN和全连接网络dense)替代神经网络分类器中所使用的长短时记忆网络LSTM,能否进一步提高分类器的性能,如查全率、查准率等?
(4) 研究问题 4:该方法训练一个神经网络分类器的时间需要多久?利用已训练好的分类器进行预测又需要多长时间?
研究问题 1关注的是所提出的方法与当前方法的检测结果在查准率(precision)与查全率(recall)等指标上的区别.为了回答这个问题,我们选择了JDeodorant[10]作为评估阶段的对比实验对象.之所以选择JDeodorant作为参照,是因为 JDeodorant作为知名的代码重构推荐工具,其代码坏味的检测能力已获得了业内的广泛认可[5,23,30].比较新的一些上帝类检测方法,如 TACO[22]和 DÉCOR[7],都没有公开的实现体(源代码或者可执行程序),因此难以与他们在同一数据集上进行实际比较.
研究问题 2关注神经网络分类器输入特征选取的有效性.我们在保持模型其他部分不变的情况下,分别剪除原模型中的度量项代码结构特征输入与标识符代码文本特征输入,将原模型拆分为两个独立的单一输入神经网络并分别加以调优训练.以各分类器在同一测试集上的最优平均F1值作为衡量指标来分析所提出的两个特征分别在整个方法中所起的作用.
研究问题 3主要关注在本方法所构造的神经网络分类器中文本特征的处理方式.我们通过将所提出的网络模型中的长短时记忆网络替换为全连接神经网络和卷积神经网络,并同样以各分类器在同一数据集上的最优平均F1值作为指标来帮助考察和分析在已有的方法架构下3种神经网络对于最终结果的影响.
研究问题 4则关注所提出方法的时间复杂度情况.由于基于机器学习的分类器训练通常都需要在训练过程中花费过多的时间成本,因此对于时间代价的考察也应成为我们对本文所提出方法的一个评估因素.对研究问题 4的考察,可以根据所提出方法在训练过程与预测过程中分别所需花费的时间成本,探讨基于深度学习的本方法在时间性能上的具体表现.
3.2 实验数据
3.2.1 训练数据
我们选择了12个开源项目,以自动构造神经网络的训练数据.表2给出了训练集所用工程各自的名称、版本、类的数量(NOC)、方法数量(NOM)以及代码行数(LOC).为了保证训练集样本的可靠性,我们选取了如下的12个开源项目来帮助神经网络分类器的训练.作为知名的开源项目,这些项目拥有更高的代码质量,因此可以帮助我们获取到更准确的标签样本,从而提高神经网络的训练效率.同时,我们在选取训练样本代码语料库的时候,会刻意参考项目的开发者与项目所涉及的领域.这一筛选条件的目的主要是为了消除特定开发者或特定项目领域可能会引入的特定代码风格倾向,以便保证训练集标签样本的综合性.
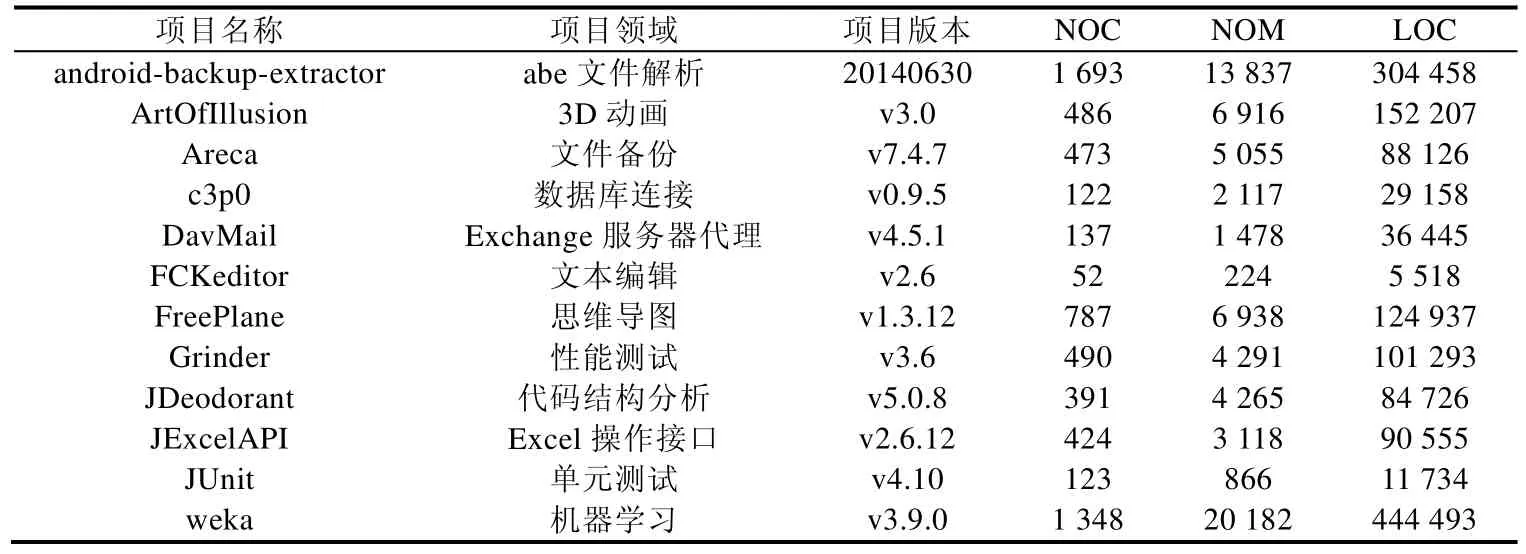
Table 2 Projects for train set表2 训练集所涉项目列表
3.2.2 测试数据
在测试数据的准备方面,我们利用了 Palomba等人提出的一个开源代码坏味数据集来作为评估实验的实验对象,其中的代码坏味记录均经由人工验证[30].之前的代码坏味相关研究通常会综合多个代码坏味检测工具的检测结果作为研究数据的来源[24,31].尽管通过多个工具的互补可能可以获取到不错的检测精度,但人工进行的代码坏味检测依然可以被认为是最为可信的评估参考标准.此数据集中包含了在30个软件项目的395个历史版本中13种代码坏味的检测情况.我们选择包含上帝类而且可以通过编译的13个项目作为测试项目.
表3展示了验证所用的13个开源项目的详细信息,包括其中的正样本(在原有数据集上被标记为上帝类的类)个数(NOPS)与负样本(没有被标记为上帝类的类)个数(NONS).

Table 3 Projects for test set表3 测试集所涉项目列表
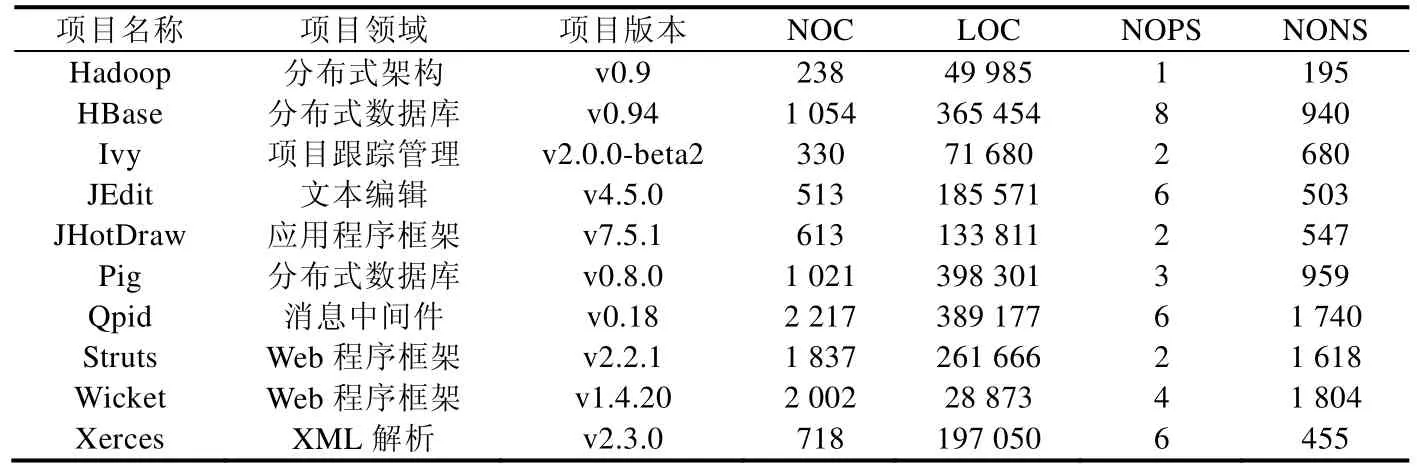
Table 3 Projects for test set (Continued)表3 测试集所涉项目列表(续)
3.3 实验过程
我们以表2中所列出的各开源项目作为代码语料库,利用如前所述的标签样本生成工具(详见第2.5节)逐条生成固定格式的正负样本数据(详见第 2.2节),以构建出神经网络分类器的训练集(其中包括正样本 845条,负样本775条).随后,经过在训练集上的多轮训练,我们可以得到一个以类中成员标识符集合与软件度量值集合为输入的分类器.此分类器能够输出被检测类中存在上帝类代码坏味的概率.
以表3中所列的各项目作为测试项目,我们解析其中的源码并按照神经网络所定义的输入格式从项目中提取数据作为测试样本,由此生成测试集.将测试集输入已训练好的神经网络分类器后,得到的输出集合即为神经网络分类器在此测试集上的预测结果.作为参照,我们在 JDeodorant中同样对此测试集进行上帝类代码坏味检测,同时导出其检测结果以便与本文所提出的方法进行对比.
所提模型代码基于keras实现.在模型优化阶段,我们以交叉熵作为损失函数,并选择自适应学习率的Adam作为优化算法.同时,为了直观对比不同方法的上帝类代码坏味检测能力,我们利用 Palomba等人提出的代码坏味数据集作为测试样本的正确标签,并以如下方法来分别计算两种检测结果与正确标签之间的查准率、查全率以及F1值:

3.4 实验结果与分析
为了回答研究问题1,我们总结了本方法与JDeodorant在相同测试集上的上帝类检测结果,如下表4所示.其中,第1列显示测试集中的项目名称,第2列~第4列显示我们所提出的方法测试结果的查准率与查全率,第5列~第7列显示JDeodorant的测试结果的查准率与查全率.表中最后一行列出了各方法表现的平均值.
根据表4,我们可以看出:
· 在对于上帝类代码坏味的检测能力上,所提出方法在此测试集中的表现总体上优于 JDeodorant,平均F1值提高了2.39%=(8.15%-5.76%),其中,本方法相对于JDeodorant的优势在查全率上尤为明显,平均提高35.58%=(95.56%-59.98%).
· 尽管所提出方法的平均查准率(4.29%)是高于已有方法的(3.09%),但总体上两种方法的查准率依然都偏低.
针对研究问题2,我们设计了一组对比实验来考察所提出方法中的代码文本特征与代码结构特征分别对于最终上帝类检测结果的影响.通过对比单一的代码文本特征输入、单一的代码结构特征输入和二者综合输入这3种输入方式下的各神经网络分类器在同一数据集上的上帝类代码坏味检测能力,我们可以直观看出所提出方法中的两个输入特征在神经网络中的作用.3种输入方式在测试集上的具体表现见表5.
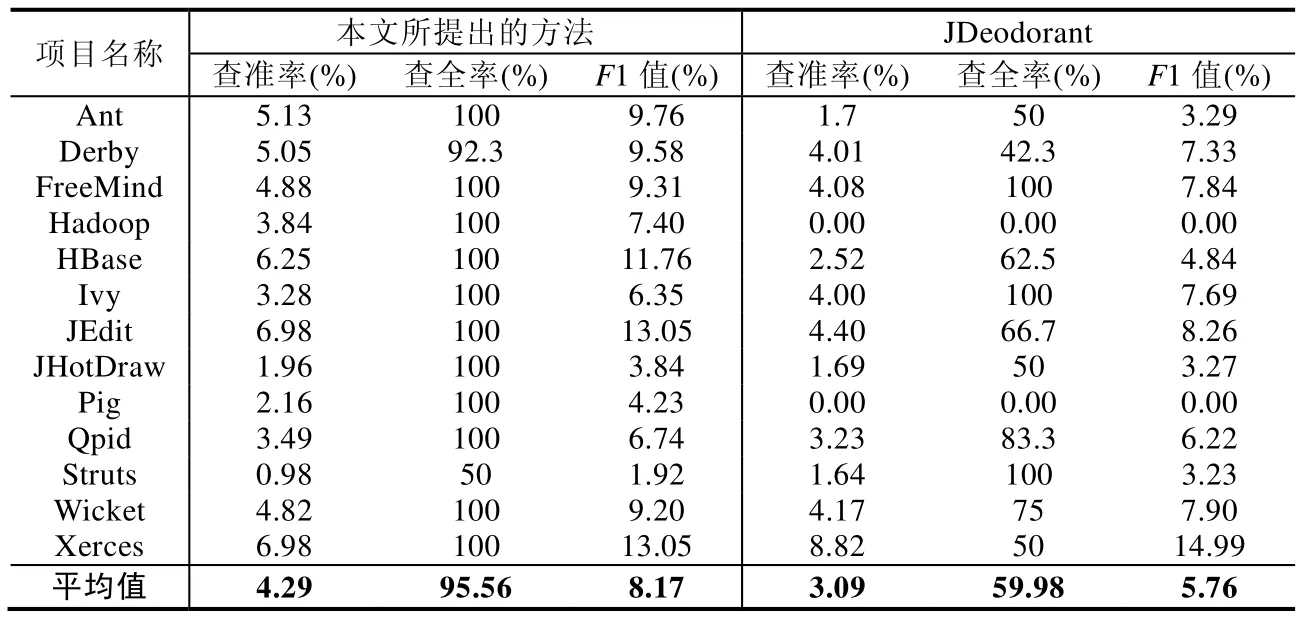
Table 4 Results on god class detection表4 上帝类检测结果
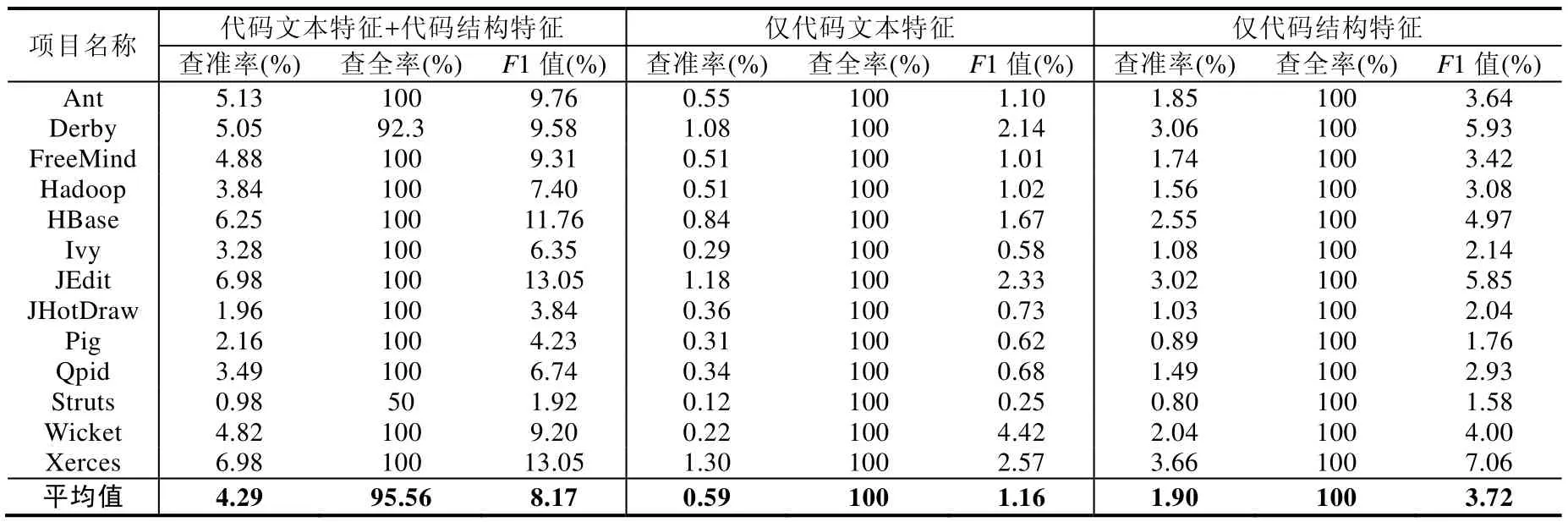
Table 5 Results on god class detection among features表5 不同特征下的上帝类检测结果
由表5可以看出:
· 当代码文本特征与代码结构特征均为神经网络的输入时,分类器在测试集上的综合表现优于任何一种单一输入的神经网络分类器,具体表现为双输入分类器的平均F1值相对于单文本输入分类器和单数值输入分类器分别提高了7.01%=(8.17%-1.16%)和4.45%=(8.17%-3.72%).
· 与代码文本特征相比,代码结构特征对于分类器的预测成功率起到了更大的作用,尤其在查准率上的影响十分明显,平均查准率高出了1.31%=(1.90%-0.59%).
此外,为了回答研究问题3,我们分别将全连接神经网络、卷积神经网络以及长短时记忆网络这3种网络模型运用于分类器中的文本特征处理环节.各分类器经过调优后在同一测试集上的具体表现见表6.需注意的是,表中3种神经网络分类器除文本特征提取环节所用模型不同外,网络其余部分均保持一致.其中,第2列~第4列数据相关的分类器采用长短时记忆网络处理代码文本特征信息,第5列~第7列所对应的全连接神经网络在文本特征提取部分的隐含层激活函数为sigmoid函数,第8列~第10列相关分类器则采用三层一维卷积神经网络进行文本特征提取.

Table 6 Results on god class detection among approaches to text feature exacting表6 不同文本特征处理方式下的上帝类检测结果
由表6可以看出:
· 在本文所提出方法的架构下,长短时记忆网络的代码文本特征提取能力整体上高于全连接神经网络与卷积神经网络,LSTM 分类器的F1值与另两者相比,分别高出了 0.7%=(8.17%-7.47%)和3.81%=(8.17%- 4.36%).
· Dense分类器的表现在测试集中的不同项目间差异很大,既有不少项目的查准率和F1值均高于LSTM分类器,也出现了检测不出项目中的上帝类代码坏味的情况(FreeMind和Hadoop).
· 针对上述情况,为保稳妥,我们认为,选择长短时记忆网络作为整个神经网络中的代码文本特征提取层时的最终效果较为良好.
针对研究问题 4,我们对所提出方法的时间性能进行了考察.通过在普通配置的个人电脑(16GB RAM,Intel Core CPU i7-6700)上运行所提出方法的全部流程,我们记录了所提出的分类器的整个训练与预测过程的耗时情况.表7列出了训练集所涉各工程提取训练样本数据时所耗的时间(以min为单位).
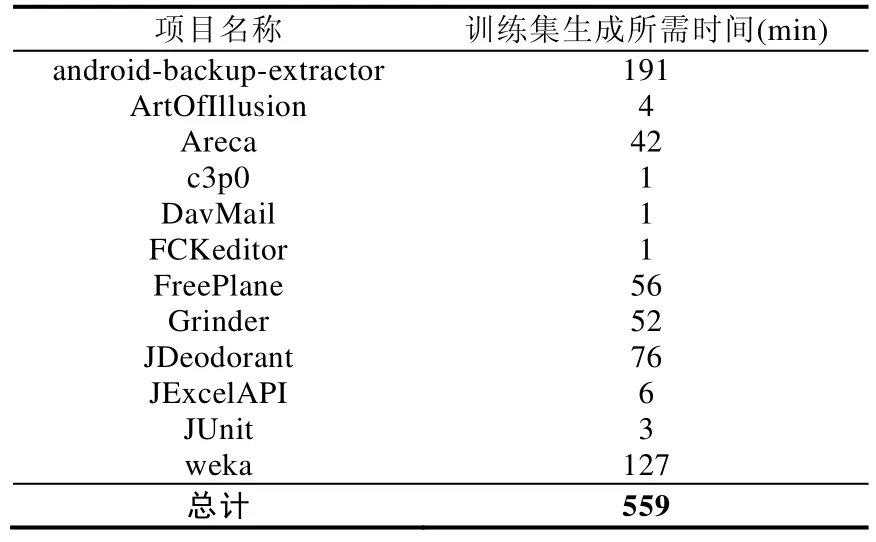
Table 7 Time of train set data generation表7 训练集数据生成所用时间
可以看出,收集样本数据的过程耗时颇久.为从 12个开源项目中提取分类器的训练集,我们累计花费了559min,平均每个项目需要 46.6min.其中,耗时最多的两个项目 android-backup-extractor(LOC=304,458)与 weka(LOC=444,493)花费了超过总时长一半(56.9%=318÷559)的时间.与耗费了近10个小时的训练集生成过程相比,神经网络在12个开源项目上的训练过程仅需46s.在13个开源项目上的测试过程中耗时36′46″(平均每个项目2′50″),其中36′24″均用于从测试项目中提取输入信息,占了总测试时间的99.1%.但是训练集的自动生成是可以提前准备的,并不需要在每次使用该方法进行上帝类检测的时候再次生成训练集.
3.5 有效性威胁
对于评估有效性的第1个威胁在于用来验证实验结果的数据集中只包含了25个开源项目.这些项目的某些特性可能会使结论产生偏差,从而导致所得结论不适用于其他项目.为了减少这一威胁,我们选择的训练及测试项目均出自不同的研究领域及开发人员,以期减少某些项目间的特定关联对于验证结果造成影响.
其次,对于评估有效性的第 2个威胁在于评估所用的测试集中被人工标注的上帝类代码坏味个数普遍较少.在这样的数据集上进行上帝类检测时,很容易出现检测效果两极分化的情况.为了尽可能保证所得出的结论适用于实际应用,我们选择了符合实际开发过程中上帝类出现情况与分布概率的标签数据集作为结果验证的基准.在现实开发场景中,项目中出现上帝类代码坏味的概率平均保持在1.7%左右.
对于评估有效性的第 3个威胁在于所用的开源代码坏味数据集中的上帝类坏味是由开发人员手动标注的.人工标注虽然更符合实际应用场景,但难以避免数据集贡献者在标记时由于个人主观原因而出现判断误差.为了减少这一威胁,我们选择了各类代码坏味数据集中研究人员最常用的开源数据集,希望通过使用经过反复验证的数据集可以更有效地避免主观性标注所带来的影响.
4 讨 论
4.1 样本噪音
由于所提出方法中的样本生成方法(详见第 2.5节)是建立在所涉及的各个类均符合单一职责原则的假设上的,即假设用于构建训练集正负样本的全部类均不存在上帝类代码坏味,且均可独立承担其作为一个类的职责.然而实际上,这样的假设也许并不成立.我们用以构造训练集的项目源码中是可能出现上帝类代码坏味的.因此,这样的样本生成方式可能会导致所生成的训练集中出现噪音——即训练集中有些样本的标签是错误的.为了减少这种噪音对于分类器训练结果的影响,我们尽可能地选取了高质量的项目源码用以构造训练集,以尽量避免设计不够完善的类出现在样本集合中.同时,为了增加神经网络的鲁棒性,在神经网络的设计过程中,我们选择了在自然语言处理领域获得很大成功的长短时记忆网络,并辅以一些防过拟合手段来帮助减少样本噪音对于训练结果的干扰.
4.2 文本预处理
所提出的方法在对神经网络的文本输入进行预处理时(详见第 2.3节),为了将从源码中提取出的标识符以词向量的形式输入到神经网络,我们会以大写字母和下划线为分隔符来对标识符执行分词操作.这种分词方式对于代码中的大部分标识符(如AbstractMethodFragment、text_length)是有效的,但对于由多个大写字母连接组成的词语(如 XMLReader)则并不能完全按照词语语义进行划分.针对这一情况,我们对大量的开源工程源码文本进行类似的分词操作,并将分词后的结果作为 Word2Vector训练的语料库.在这样的语料库下训练出的Word2Vector模型隐含层将既可以为语料库中已出现的词语在高维空间中映射词向量,同样可以为语料库中连续出现的字母序列映射空间距离相近的高维向量.此外,标识符中的缩写词(如,numberOfChildren缩写为numOfChildren)也可能会导致标识符语义上的不准确.为此,我们在对Word2Vector的训练语料库的选取过程中遵循了大规模和高质量两个原则,从而尽量保证完整收集常见缩写词并且避免非常规缩写词的出现.
4.3 过拟合问题
在神经网络的应用过程中,过拟合是最常见的影响网络模型泛化能力的原因之一[32].对此,研究人员提出了降低模型复杂性[32]、添加正则惩罚项(regularization)[33]、增加随机噪声(noise)、随机删除隐层神经元(dropout)[34]以及选择适合的迭代训练次数(early stopping)[35]等多种方法,以提高神经网络的泛化性能.由于本文所提出方法中的神经网络模型参数数量较大,我们也在模型训练过程中加入了一些手段来降低过参数化对网络模型的影响.在尽量减少不必要的神经元和神经网络隐层的同时,我们尝试了上述多种防过拟合手段,最终确定了目前的整体模型.首先,经过实验对比我们发现,相对于添加高斯噪声和正则化参数,随机删除隐藏层内的一部分神经元对于所提出的分类器最终测试效果的提升更为明显.在实际训练过程中,我们将 Dropout的丢弃率设为60%.其次,我们以训练样本集中 10%的随机样本集作为验证集,在每轮迭代后,对权重更新后的网络进行验证,发现经过10次迭代训练后,神经网络的训练结果进入相对稳定阶段,且验证结果数据没有与训练结果数据出现大的偏差,由此确定了神经网络训练的迭代次数为 10次.通过上述消除过拟合的方法和手段,我们最终显著提高了神经网络分类器的泛化能力,所提出的方法在测试集上的平均F1值由之前的 0.18%提高至上文所述的8.17%.
5 总 结
在本文中,我们提出了一种基于深度学习的上帝类代码坏味检测方法.通过分析大量源码的文本信息与软件度量信息,深度神经网络在反复迭代中学习从输入中提取出与上帝类坏味相关的特征,最终生成分类器模型.为了满足深度神经网络训练过程对于大规模样本集的需求,我们还实现了一种可以自动利用开源项目源码来构建上帝类样本的方式来生成大量训练数据的工具.
为了保证实验评估结果的精准可靠,我们利用开源代码坏味数据集来对所提出方法进行验证.我们从12个开源项目中提取训练样本以训练神经网络模型,并在13个人工标记的开源项目上对所生成的网络模型进行测试.实验结果表明,相对于现有方法,本文所提出的上帝类检测方法在测试集上的综合表现更佳,具体体现为F1值平均提升2.39%,查全率和查准率分别提高35.58%和1.20%.
可以看出,尽管所提出的方法在测试集上的查准率较现有方法已有提高,但总体来说依旧偏低,导致所提出的方法可能并不适合直接应用于实际开发场景的完全自动化检测.然而得益于本文所提出方法的查全率有了较大幅度的提高,上帝类的检出成功率得到了更高的保障,被检测程序中的潜在上帝类坏味中的大多数都可由此方法检测出来.因此,本方法可用于实际开发中的上帝类代码坏味辅助检测,通过提供上帝类坏味候选清单,来帮助开发人员缩小人工检测的范围,从而更快地锁定上帝类代码坏味的重构时机.同时,在未来的研究中,我们将针对上帝类代码坏味检测的可用性做进一步改进,以实现完全自动化的上帝类坏味检测.此外,在本文所提出的代码坏味检测的模型基础上,我们也将对基于深度学习的提取类重构操作进行进一步的研究.
上帝类代码坏味属于类级别的代码坏味,因而在本文中,我们的训练样本自动生成工具的合并粒度也在类级别上.同时,由于上帝类是因违反了单一职责原则而引发的代码坏味,因此我们为模拟生成上帝类代码坏味,实现了为单个类中注入多个职责的自动化工具,以此来实现上帝类代码坏味标签样本的自动生成.此外,在开发人员人工判定上帝类代码坏味的过程中,相对于检测数据类等坏味会更偏向于对代码规模和类内内聚度的考察,而相对于长方法等坏味则更偏向于对代码耦合度的考量,因此我们综合了各种与上帝类代码坏味相关的结构特征,以上文中的12个度量项作为神经网络分类器的代码结构特征输入.
然而由于不同的代码坏味的特点不同,在坏味检测过程中所需的文本特征和结构特征也不同.针对除上帝类以外的其他代码坏味,我们可以基于所提出方法的框架模式,通过替换各类坏味所特有的特征表现以及坏味合成方式来实现不同的基于深度学习的坏味检测方法.例如,与上帝类代码坏味在类级别上过于臃肿不同,长方法属于方法级别的代码坏味.因此,若要在本文所提出方法的基础上实现长方法代码坏味的深度学习检测方法,我们可以通过批量调用方法内联(inline method)重构操作来实现长方法坏味样本集的自动构建,并以与长方法相关的几项度量值作为二分类神经网络的输入特征,来实现针对长方法代码坏味的深度学习检测方法.结合以上分析,我们可在未来以本文所提出方法的模式为基础来实现对数据类、长方法等其他代码坏味在不同程序语言中的深度学习检测方法.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
意林·全彩Color(2019年7期)2019-08-13
计算机测量与控制(2019年4期)2019-05-08
初中生世界·八年级(2017年4期)2017-05-03
初中生世界·七年级(2017年4期)2017-05-03
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
太空探索(2016年6期)2016-07-10
股市动态分析(2015年16期)2015-09-10
