
基于机器学习的工业控制网络异常检测方法*
2019-06-11 08:48邵俊杰
网络安全与数据管理 2019年6期
邵俊杰,董 伟,冯 志
(中国电子信息产业集团有限公司第六研究所,北京 100083)
0 引言
近些年来,工业控制系统(Industrial Control System,ICS)面临的网络威胁日益严重。国内外ICS通信网络被频繁攻击,不仅带来重大经济损失,更严重威胁到国家基础设施和重要生产部门的安全。
2010年,伊朗遭受“震网(Stuxnet)”超级病毒攻击,大量生产核燃料用的离心机遭到破坏,该事件也成为世界上首个“网络超级武器”事件。2012年5月,俄罗斯安全专家发现“火焰(Flame)”电脑病毒,在中东地区大范围传播。据报道,该病毒是中东某国针对另一国实施攻击的高科技网络武器。2018年8月,台积电新竹园区遭受网络病毒攻击,导致生产线全数停摆,造成经济损失约19亿元。类似的工业安全事件与日俱增。
ICS协议设计之初面向相对封闭的系统,并未考虑外界威胁,近些年随着两化融合的发展,ICS逐渐与外网连接,为保护关键基础设施,针对ICS的异常检测技术研究迫在眉睫。
ICS的正常数据、异常数据分布往往呈现出极度不平衡的特点,获取异常样本代价极高,加大了训练出可靠的高精度检测模型的难度,对于建立性能良好的检测模型非常不利。单分类器可以规避上述问题,因此可将异常检测看作单分类问题以无监督方式来解决[1]。作为单分类方法的代表,单分类支持向量机(One-Class Support Vector Machine,OCSVM)被广泛应用于异常检测[2]。
其次,许多工控协议格式并不固定,采用深度包检测(Deep Packet Inspection,DPI)的网络异常检测费时费力。WANG等[3]首次提出PAYL(payload-based anomaly detector)模型,将n-gram算法作为特征工程引入异常检测领域,并用马氏距离衡量新的有效载荷(payload)与已知模型的相似度,从而对网络异常做出识别。采用n-gram算法作为特征工程无需过多的先验知识,近年来,在机器学习领域n-gram算法逐渐成为替代DPI的一种方式;但几乎所有采用n-gram作为特征提取的入侵检测方法均结合马氏距离做出识别,如刘解放[4]等人,而马氏距离主要优点在于不受量纲的影响,排除了变量之间相关性干扰,但其夸大了变化微小的变量的作用,并且不是每次都能顺利计算出结果。
本文不再使用传统PAYL模型,而是将n-gram方法用于特征提取,结合单分类器与集成学习训练出二层分类模型,从而对Modbus网络进行异常检测。
1 Modbus协议简介
Modbus协议是一项应用层报文传输协议,用于互联工控系统各大软硬件。该协议共有两大类实现方式:串行链路上的Modbus协议以及TCP层的Modbus协议。
串行链路上的Modbus协议包含两种传输模式:RTU和ASCII模式。每字节的Modbus RTU报文帧包含两个4位十六进制的字符(0~F),Modbus RTU报文帧由以下几部分组成:循环冗余校验码(Cyclic Redundancy Code,CRC)、设备地址、功能地址、功能码以及数据域。Modbus ASCII模式与其相似,只是报文中的每字节以两个4位的ASCII字符为单位进行传输。Modbus TCP在TCP/IP层上使用了一种专用的报文头来识别MODBUS应用数据单元。将这种报文头称为MBAP报文头,包含单元标识符、事物元标识符、长度以及协议标识符。两种Modbus实现方式如图1所示。

图1 Modbus RTU和TCP报文
2 方法提出
如图2所示,本文异常检测方法简介如下:
(1)使用n-gram(n=1,1.5,2,2.5,3)对训练集样本X1(只含正常数据)进行特征提取,即对每一个Modbus报文帧有效载荷进行五种特征表述。设有X1中有数据xi,则对其进行五种n-gram特征提取后会产生五种不同的词向量xij(j=0,1,2,3,4),对应的数据集记为Xj(j=0,1,2,3,4)。
(2)对5个Xj(j=0,1,2,3,4)分别使用主成成分分析(Principal Component Analysis,PCA)与OCSVM算法,训练出5个不同的OCSVM初级分类器,记为OCi(i=0,1,2,3,4)。
(3)用OCi(i=0,1,2,3,4)对训练集X2(含正常数据与异常数据)进行预测,对每一条数据xi,经过OCj(j=0,1,2,3,4)预测后,会得到中间结果yij(j=0,1,2,3,4),组成下一层的输入向量yi(yi0,yi1,yi2,yi3,yi4,labeli),其中labeli为xi的标签。yi组成的数据集记为X3。
(4)用X3作为第二层分类器的训练集,训练出第二层分类器。
(5)对测试数据,经过上述四个步骤的分析后,即可判定为正常或异常流量。
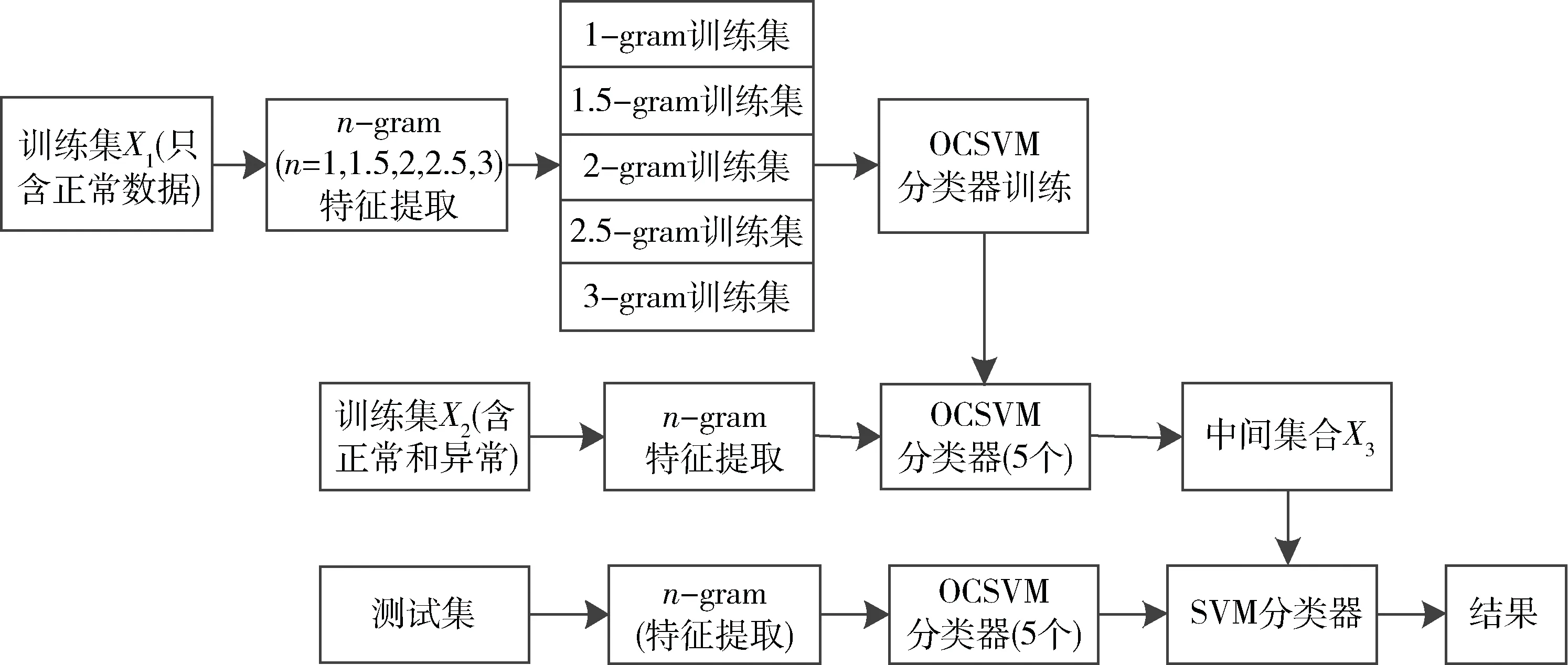
图2 方法架构
2.1 特征工程
2.1.1 n-gram特征提取
特征工程的好坏决定了模型的上限。如何对原始问题进行特征提取在机器学习中至关重要[5]。n-gram算法对连续的n个字节进行分词处理,提取出一组特征,显然该算法具有线性时间复杂度。
在Modbus RTU中每字节由2个4位字符组成,每个字符占0.5字节,所以采用n-gram进行特征提取时,n的最小粒度为0.5字节。对给定数据帧有效载荷进行n-gram特征提取,最多有256n种可能的字符串组合。
本文方法的第一层模型采用单分类器训练模型,只需正常数据即可产生模型轮廓。故对正常数据的payload进行n-gram特征提取,统计每个词出现的次数并进行逆序排列,选出出现次数前90%的词集作为特征,组成词向量x=(x1,x2,…,xn)。该词向量无法作为特征向量直接使用,本文使用报文帧的词向量词频作为特征向量。
对每一个报文帧,令f=(f1,f2,…,fn)作为其特征向量。其中:
其中s(xi)为该报文中xi出现的次数。
2.1.2 PCA降维
2.1.1小节中词向量维度依然较高,数据较为稀疏,会造成训练速度过慢,且存在冗余信息。因此对产生的词向量使用主成分分析(Principal Component Analysis,PCA)方法进行降维分析。
PCA通过找到一个超平面,使得样本在其上的投影方差和最小。假设有总体x={x1,x2,…,xn}。
经过去中心化以及拉格朗日乘子法分析后,原问题转化为求样本协方差矩阵的特征值λ=(λ1,λ2,…,λn)。对λ逆序排列后取前d个λ对应的维度,即将数据降至d维。
2.2 单类支持向量机原理
OCSVM算法作为VC维理论下的算法,以结构风险最小化作为训练原则,在有限样本下仍具有较好的泛化能力。
OCSVM将数据映射到核函数所表示的特征空间中,找出一个距离原点尽可能远的超平面,将原点与样本点尽可能分开,为保证模型泛化能力,引入松弛变量ξi,允许部分点错分在超平面内侧。
假设样本x={x1,x2,…,xl},OCSVM的凸二次规划问题如下:
(1)
s.t.wΦ(xi)≥ρ-ξi,ξi≥0
其中Φ为原特征空间到高维空间的映射函数。w,ρ分别为超平面的法向量和偏移。v∈(0,1)为允许划分到超平面内侧的点的比例。
求解出w,ρ,代入决策面(2)即可对新样本进行判定。
F=sgn((wΦ(xi))-ρ)
(2)
对式(1)引入拉格朗日乘子法,原问题转化为:
L(w,ξ,ρ,α,β)=

(3)
分别对w,ρ,ξi求导并赋值为0得:
(4)
将式(4)代入拉格朗日式子并引入对偶问题,满足KKT条件的情况下,最终将原问题转化为:
(5)
解出α=(α1,α2,…,αl),其中αi>0的对应样本点为支持向量。至此,w,ρ均可由α得出。
2.3 集成策略
集成学习可以解决单个分类器性能不佳的问题,被广泛应用于机器学习领域[6]。次级学习器一般采用逻辑回归模型;SVM与其主要区别在于损失函数的不同,在实践中发现SVM与LR效果相差无几。但SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。因此本文选用SVM作为次级学习器。
3 实验及结果分析
3.1 数据集介绍
本实验采用密西西比州立大学提供的气体管道数据集[7]。数据集作者提供了两套数据集:原始数据集和作者处理过的数据集。在处理过的数据集中作者提出了20个特征,并对原始数据集进行加工后做成新数据集。
本文采用原始数据集,共274 627条数据,包含60 000条不同类型的攻击。该数据集均为Modbus RTU报文帧。
3.2 评价指标
本文选用误报率(False Positive Rate,FPR)、准确率(Precison)、召回率(Recall)、漏报率(False Negative Rate,FNR)作为评价指标。
(6)
(7)
(8)
(9)
一般将异常样本作为正类,正常样本作为负类,式(6)~(9)中TP为异常样本识别为异常样本的数量,FP为正常样本误报为异常样本的数量,FN为异常样本漏报为正常样本的数量,TN为正常样本识别为正常样本的数量。
3.3 实验过程及结果
3.3.1 词向量产生
因本次实验数据集中数据均为Modbus RTU报文帧,其报头仅含地址信息,本文认为与攻击并无关联,故去掉报文帧前1字节与最后2字节(CRC)。本实验完全基于payload对攻击进行识别,对于Modbus TCP报文,可以加上基于报头的特征。
对210 000条正常Modbus RTU帧采用n-gram(n=0,1,2,3,4)特征提取后,对出现的词进行计数,提取出现频率前90%的词分别作为每个n-gram的词向量。对2-gram来说,本文选用的词向量共249维。
3.3.2 初级学习模块
选用100 000条数据对初级学习器进行学习,调节参数后,每个OCSVM分类器性能如表1所示。

表1 不同单分类器性能
3.3.3 次级学习模块
因只有6万条攻击样本,为保证次级学习器样本均衡问题,选择剩余数据的4万条正常和攻击数据,共8万条数据,利用5个初级学习器的输出作为次级学习器的输入,进行次级学习器的学习。
将剩余数据作为测试集,进行测试,最终模型效果如表2所示。

表2 整个模型性能
刘万军[2]等人采用作者进行特征处理后的数据集,其实验结果为:FPR=0.097,FNR=0.067,与本实验模型性能相差无几。但本文方法从Modbus RTU原始报文帧入手,采用词频作为特征,对不同的工控协议移植性较好。
4 结论
本文对ModbusRTU的payload进行了多个n-gram特征提取,产生多个同质单分类器,因n-gram产生的特征向量较为粗糙,单个分类器效果并不理想。故用“学习法”对多个分类器进行结合。实验结果表明,本文的方法在ICS入侵检测领域具有重要的理论和实践意义。
猜你喜欢
汽车电器(2022年9期)2022-11-07
电子技术与软件工程(2022年11期)2022-09-09
电子产品世界(2022年4期)2022-04-21
销售与市场(营销版)(2021年10期)2021-11-21
计算机系统应用(2021年2期)2021-02-23
中国外汇(2019年11期)2019-08-27
销售与市场(营销版)(2019年6期)2019-06-21
计算机测量与控制(2019年4期)2019-05-08
科技视界(2015年24期)2015-08-22
邮电设计技术(2011年8期)2011-07-27
